






0 简介
今天学长向大家介绍一个机器视觉的毕设项目
🚩基于大数据的电影数据分析与可视化系统
项目运行效果(视频):
毕业设计 大数据电影评论情感分析
项目获取:
https://gitee.com/assistant-a/project-sharing
1 课题背景
研究中国用户电影数据,有助于窥探中国电影市场发展背后的规律,理解其来龙去脉,获知未来走向。如今互联网上中国用户的电影数据集缺失,缺少如MovieLens、Kaggle等独立机构完成长期收集电影数据工作,研究人员只能自行收集或下载来自国外的公共电影数据集,不具有本地属性。
本项目爬取豆瓣网相关电影信息,建立数据库。并根据此数据库进行了可视化分析,从中提取出大量数据背后信息,多维度分析了电影在公映时间、观众分布、类别占比、各国市场情况的关系,从评论词云、文本情感角度挖掘单部电影呈现的规律。
2 效果实现
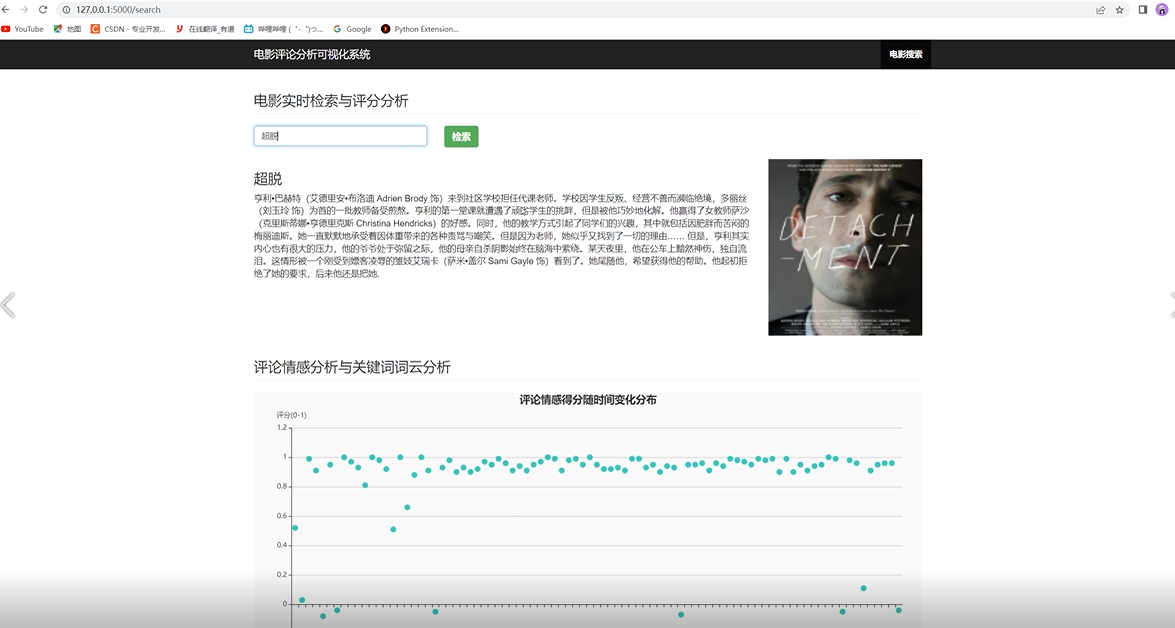
评论情感得分随时间变化情况如下

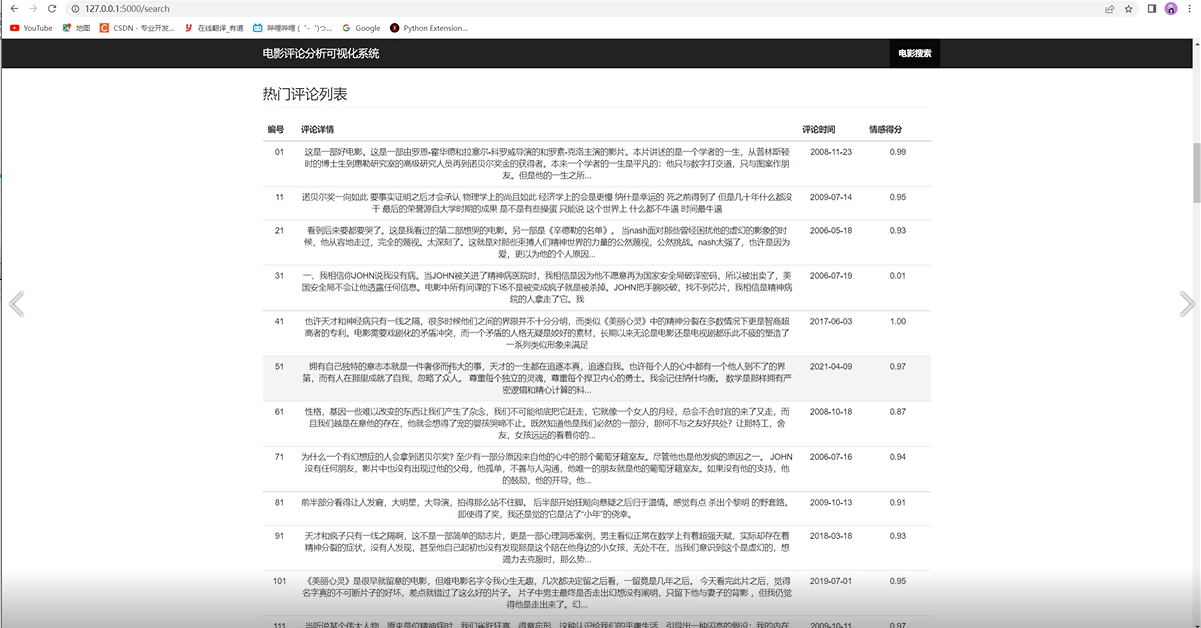
热门评论列表情况如下
3 爬虫及实现
简介
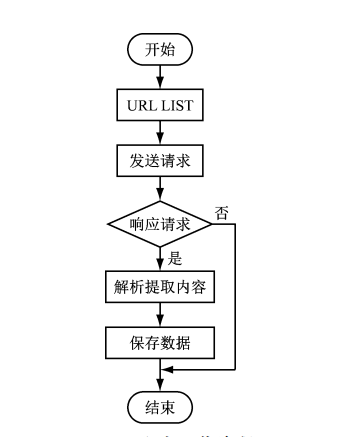
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。
爬虫流程图如下:
部分代码实现
import re
import requests
import json
import time
from openpyxl import load_workbook, Workbook
from requests import RequestException
def get_detail_page(html):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
cookies = {}
response = requests.get(url=html, headers=headers, cookies=cookies)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
print('获取详情页错误')
time.sleep(3)
return get_detail_page(html)
def parse_index_page(html):
html = get_detail_page(html)
html = html[12:-1]
data = json.loads(html)
id_list = []
if data:
for item in data:
id_list.append(item['url'])
return id_list
def parse_detail_page(data):
html = get_detail_page(data)
info = []
# 获取电影名称
name_pattern = re.compile('<span property="v:itemreviewed">(.*?)</span>')
name = re.findall(name_pattern, html)
info.append(name[0])
# 获取评分
score_pattern = re.compile('rating_num" property="v:average">(.*?)</strong>')
score = re.findall(score_pattern, html)
info.append(score[0])
# 获取导演
director_pattern = re.compile('rel="v:directedBy">(.*?)</a>')
director = re.findall(director_pattern, html)
print(director)
info.append(str(director[0]))
# 获取演员
actor_pattern = re.compile('rel="v:starring">(.*?)</a>')
actor = re.findall(actor_pattern, html)
info.append(str(actor[0]))
# 获取年份
year_pattern = re.compile('<span class="year">\((.*?)\)</span>')
year = re.findall(year_pattern, html)
info.append(year[0])
# 获取类型
type_pattern = re.compile('property="v:genre">(.*?)</span>')
type = re.findall(type_pattern, html)
info.append(type[0].split(' /')[0])
# 获取时长
try:
time_pattern = re.compile('property="v:runtime" content="(.*?)"')
time = re.findall(time_pattern, html)
info.append(time[0])
except:
info.append('1')
# 获取语言
language_pattern = re.compile('pl">语言:</span>(.*?)<br/>')
language = re.findall(language_pattern, html)
info.append(language[0].split(' /')[0])
# 获取评价人数
comment_pattern = re.compile('property="v:votes">(.*?)</span>')
comment = re.findall(comment_pattern, html)
info.append(comment[0])
# 获取地区
area_pattern = re.compile(' class="pl">制片国家/地区:</span>(.*?)<br/>')
area = re.findall(area_pattern, html)
info.append(area[0].split(' /')[0])
return info
html = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E5%86%B7%E9%97%A8%E4%BD%B3%E7%89%87&sort=rank&page_limit=20&page_start='
wc = Workbook()
sheet = wc.active
sheet.title = "New"
ws = wc['New']
sheet['A1'] = 'name'
sheet['B1'] = 'score'
sheet['C1'] = 'director'
sheet['D1'] = 'actor'
sheet['E1'] = 'year'
sheet['F1'] = 'type'
sheet['G1'] = 'time'
sheet['H1'] = 'language'
sheet['I1'] = 'comment'
sheet['J1'] = 'area'
ws = wc[wc.sheetnames[0]]
wc.save('豆瓣电影.xlsx')
ti = 1
for i in range(20, 50):
print(i)
html1 = html+str(i*20)
u = parse_index_page(html1)
print(u)
for t in u:
time.sleep(0.5)
b = parse_detail_page(t)
print(b)
ws.append(b)
wc.save('豆瓣电影.xlsx')
ti += 1
4 Flask框架
简介
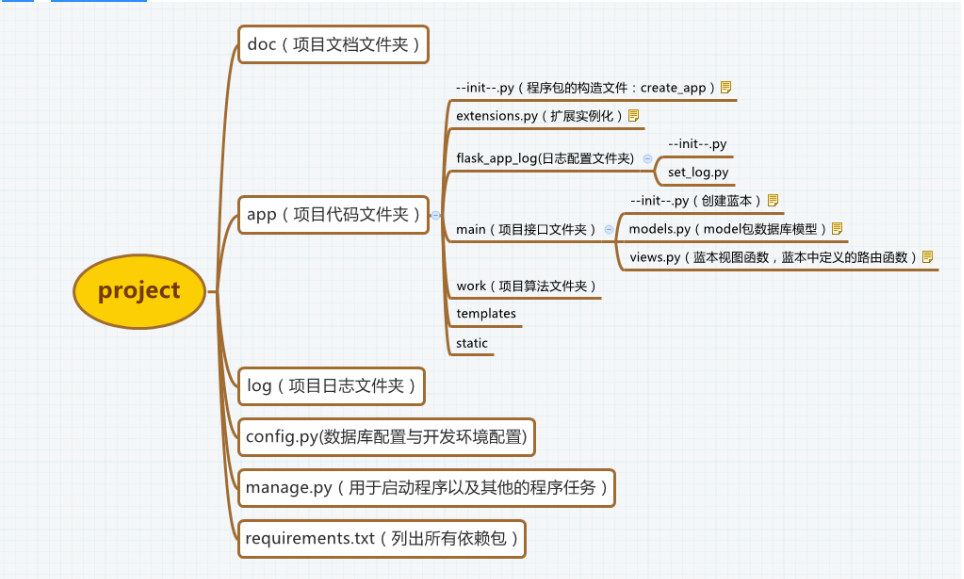
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
Flask项目结构图
部分相关代码
from flask import Flask, render_template, jsonify
import requests
from bs4 import BeautifulSoup
from snownlp import SnowNLP
import jieba
import numpy as np
app = Flask(__name__)
app.config.from_object('config')
# 中文停用词
STOPWORDS = set(map(lambda x: x.strip(), open(r'./stopwords.txt', encoding='utf8').readlines()))
headers = {
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'accept-language': "en-US,en;q=0.9,zh-CN;q=0.8,zh-TW;q=0.7,zh;q=0.6",
'cookie': 'll="108296"; bid=ieDyF9S_Pvo; __utma=30149280.1219785301.1576592769.1576592769.1576592769.1; __utmc=30149280; __utmz=30149280.1576592769.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _vwo_uuid_v2=DF618B52A6E9245858190AA370A98D7E4|0b4d39fcf413bf2c3e364ddad81e6a76; ct=y; dbcl2="40219042:K/CjqllYI3Y"; ck=FsDX; push_noty_num=0; push_doumail_num=0; douban-fav-remind=1; ap_v=0,6.0',
'host': "search.douban.com",
'referer': "https://movie.douban.com/",
'sec-fetch-mode': "navigate",
'sec-fetch-site': "same-site",
'sec-fetch-user': "?1",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36 Edg/79.0.309.56"
}
login_name = None
# --------------------- html render ---------------------
@app.route('/')
def index():
return render_template('index.html')
@app.route('/search')
def search():
return render_template('search.html')
@app.route('/search/<movie_name>')
def search2(movie_name):
return render_template('search.html')
@app.route('/hot_movie')
def hot_movie():
return render_template('hot_movie.html')
@app.route('/movie_category')
def movie_category():
return render_template('movie_category.html')
# ------------------ ajax restful api -------------------
@app.route('/check_login')
def check_login():
"""判断用户是否登录"""
return jsonify({'username': login_name, 'login': login_name is not None})
@app.route('/register/<name>/<pasw>')
def register(name, pasw):
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
pasw CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "INSERT INTO user (name, pasw) VALUES (?,?);"
cursor.executemany(sql, [(name, pasw)])
conn.commit()
return jsonify({'info': '用户注册成功!', 'status': 'ok'})
@app.route('/login/<name>/<pasw>')
def login(name, pasw):
global login_name
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
pasw CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "select * from user where name='{}' and pasw='{}'".format(name, pasw)
cursor.execute(sql)
results = cursor.fetchall()
login_name = name
if len(results) > 0:
return jsonify({'info': name + '用户登录成功!', 'status': 'ok'})
else:
return jsonify({'info': '当前用户不存在!', 'status': 'error'})
5 Ajax技术
Ajax 是一种独立于 Web 服务器软件的浏览器技术。
Ajax使用 JavaScript 向服务器提出请求并处理响应而不阻塞的用户核心对象XMLHttpRequest。通过这个对象,您的 JavaScript 可在不重载页面的情况与 Web 服务器交换数据,即在不需要刷新页面的情况下,就可以产生局部刷新的效果。
前端将需要的参数转化为JSON字符串,再通过get/post方式向服务器发送一个请并将参数直接传递给后台,后台对前端请求做出反应,接收数据,将数据作为条件查询,但会j’son字符串格式的查询结果集给前端,前端接收到后台返回的数据进行条件判断并作出相应的页面展示。
$.ajax({
url: 'http://127.0.0.1:5000/updatePass',
type: "POST",
data:JSON.stringify(data.field),
contentType: "application/json; charset=utf-8",
dataType: "json",
success: function(res) {
if (res.code == 200) {
layer.msg(res.msg, {icon: 1});
} else {
layer.msg(res.msg, {icon: 2});
}
}
})
6 Echarts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
7 最后
项目分享:














 3624
3624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









