







1、Vue介绍
1.1、Vue概述
Vue.js 是一款流行的** 渐进式 **前端 JavaScript 框架,用于构建交互式的用户界面。它由华裔开发者尤雨溪创建,并于2014年首次发布。Vue 的设计目标是通过简单、灵活的 API 提供更容易上手的开发体验,同时具备高效、可维护的代码结构
渐进式:意味着它可以根据项目的需求逐步引入和使用其功能,而不需要一次性将整个框架引入项目中。这种渐进式的特性使得 Vue.js 非常灵活,能够适应不同规模和复杂度的项目
1.2、Vue的特点
① 响应式数据绑定:Vue 使用了响应式的数据绑定机制,当数据发生变化时,相关的 DOM 会自动更新,这简化了开发过程,提高了开发效率。
② 组件化开发:Vue 鼓励将页面拆分成多个独立的组件,每个组件负责特定的功能。这种组件化的开发方式使得代码更易于理解、维护和复用。
③ 虚拟 DOM:Vue 使用虚拟 DOM 技术来提高性能。它会在内存中维护一份虚拟 DOM 树,然后通过比对虚拟 DOM 和实际 DOM 的差异,最小化页面重绘的开销。
④ 指令:Vue 提供了一系列的指令,用于操作 DOM。其中最常用的包括 v-bind、v-model、v-for、v-if 等,它们使得在模板中直接操作数据和 DOM 变得更加简洁明了。
⑤ 生命周期钩子:Vue 组件生命周期钩子允许开发者在组件的不同阶段执行自定义的逻辑,例如在组件创建前后、更新前后、销毁前等。
⑥ 路由管理:Vue 提供了 Vue Router,用于实现单页面应用(SPA)的路由管理,使得页面之间的跳转更加灵活。
⑦ 状态管理:Vue 通过 Vuex 提供了一种集中式的状态管理方案,用于管理应用中的各种状态,包括数据、状态、组件通信等。
⑧ 简单易学:Vue 的 API 设计简洁明了,学习曲线较为平缓,使得新手能够快速上手。
⑨ 灵活性:Vue 可以与现有项目无缝集成,也可以与其他库和框架搭配使用,非常灵活。
⑩ 社区活跃:Vue 拥有一个活跃的社区,有大量的插件和扩展可供选择,且有丰富的文档和教程可供学习和参考
1.3、配置
编译器:WebStorm 或 VSCode —— 用于写代码
包管理工具:npm(可以下载nodejs,里面有继承的npm)—— 用于下载一些第三方包
浏览器插件:Vue.js devtools —— 用于在浏览器调试 vue 代码
2、Vue相关
2.1、MVC、MVP、MVVM 的发展
Vue 采用了 MVVM(Model-View-ViewModel)架构模式。当谈到软件架构时,MVC(Model-View-Controller)、MVP(Model-View-Presenter)和 MVVM(Model-View-ViewModel)是三种常见的架构模式,它们都旨在将应用程序的不同部分分离开来,以便更容易管理、维护和扩展代码。以下是它们的简要介绍
Tip:MVC、MVP 和 MVVM 都属于一种架构模式(一种思想,是抽象的、需要被实现的),而不是特定的框架(像Flask、Scrapy、Vue这些具体的,能拿来用的),它们是用于组织和管理应用程序代码的通用模式,这些模式旨在将应用程序的不同部分分离开来,以便更容易管理、维护和扩展,尽管 MVC、MVP 和 MVVM 是独立于特定框架的架构模式,但它们经常与特定的框架或库结合使用。例如,MVC 模式经常与 SpringMVC、Angular 等框架一起使用,而 MVVM 模式则经常与 Vue.js 等框架一起使用。这些框架提供了一些工具和机制来实现这些模式,并且简化了开发者在实践中使用这些模式的过程
2.1.1 第一阶段 —— 运维倒拔垂杨柳(开发仅剩的头发)
在 Web 1.0 时代,还没有前端的概念,当时开发一个 web 应用多数采用 ASP.NET / Java / PHP 编写,项目通常由多个 aspx / jsp / php文件构成,每个文件同时包含了 HTML、CSS、JavaScript 的前端代码和 C# / Java / PHP 代码,以 jsp 文件(本质上就是 html 文件中穿插了 java 代码)为例长这样
<!DOCTYPE html>
<html>
<head>
<title>没有使用 MVC 的 JSP 示例</title>
</head>
<body>
<h1>用户管理系统</h1>
<form action="addUser.jsp" method="post">
<label for="username">用户名:</label>
<input type="text" id="username" name="username">
<br>
<label for="password">密码:</label>
<input type="password" id="password" name="password">
<br>
<button type="submit">添加用户</button>
</form>
<%
// 处理表单提交的逻辑
String username = request.getParameter("username");
String password = request.getParameter("password");
if (username != null && password != null) {
// 将用户信息保存到数据库
// 这里假设使用了内联的 SQL 语句进行数据库操作,实际应用中不推荐这样做,容易引发安全问题
Connection conn = null;
PreparedStatement stmt = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "password");
String sql = "INSERT INTO users (username, password) VALUES (?, ?)";
stmt = conn.prepareStatement(sql);
stmt.setString(1, username);
stmt.setString(2, password);
int rowsAffected = stmt.executeUpdate();
if (rowsAffected > 0) {
out.println("<p>用户添加成功!</p>");
} else {
out.println("<p>用户添加失败!</p>");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
%>
</body>
</html>
可想如果篇幅再长一点的 jsp 文件就问你看完想不想晕死过去,怎么又 html 又 java ,可能兴致来了还得来个 sql,一堆乱七八糟整在一个文件里,应届生磕破头拿着100块一天的工资去实习一见代码直接扭头填离职表
在这个时候还没有所谓的前端工程师、后端工程师,只有全栈工程师,毕竟你像写一个 jsp 文件怎么的前后端都得会吧,而且在这个还没有 mvc 概念出现的时候,大家写代码就跟你在写课程设计一样乱 /(ㄒoㄒ)/~~ (如果你是大佬的话当我没讲),想怎么写就怎么写,这里突然需要个数据我直接啪的一下整个三行的 sql 语句就写下去,这里需要个排序我啪的一下就一个java的排序算法写下去,最后一个文件就是臃肿、混乱、想改不知道从哪里改
而整个服务器的运转就是:接收用户的请求 》生成合适的 jsp 文件 》把 jsp 文件在服务端解析成静态文件 》返回给客户端,系统的架构如下,这里全栈工程师要单抡整个系统(APP Server)的代码(这钱就该你赚…)
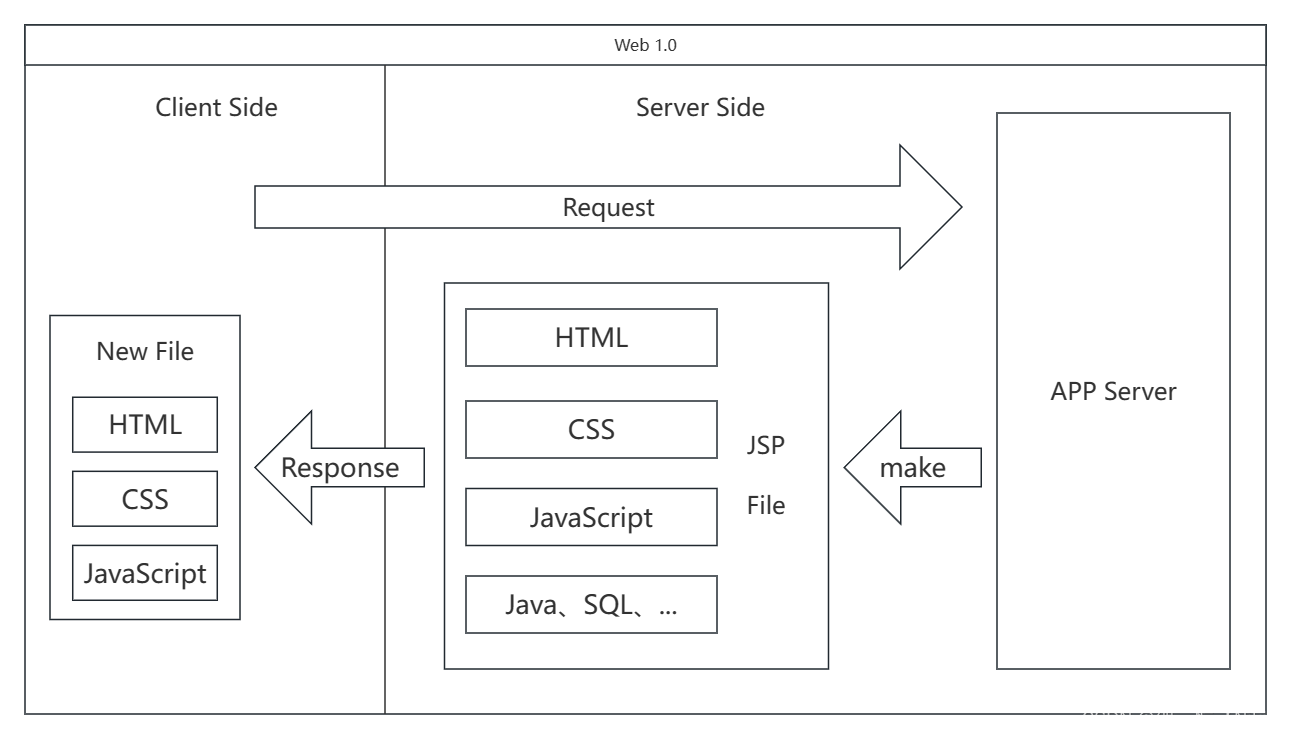
这样的架构好处就是简单快捷,谁写的谁爽,但坏处就是难以维护,谁改的谁骂娘,请脑补一下你的同学把没有用任何框架、设计模式、架构模式的纯原生(山顶洞版)放在你面前让你给他改bug的场景,这时你可能想倒拔他的头
2.1.2 第二阶段 —— 开发快被运维薅秃通宵想出了后端MVC模式
为了让开发更加便捷,代码更容易维护,便衍生出了MVC开发模式和一些对其作实现的框架,典型的框架就是 Spring 、Structs 、Hibernate 等,相对于第一阶段的改动就是将数据的处理、管理和那些前端的代码尽量分开,然后前端代码中需要哪些数据就去调用就行了
例如如果有三个功能模块 / 页面需要用到学生成绩的正序结果的话,在第一个阶段就要在三个 jsp 文件中都写从数据库获取学生的成绩、然后再写个排序算法,代码的重复率就太高了,而且有一天想要变成获取成绩的倒序结果的话,三个 jsp 文件都要改,如果这些代码不是你写的然后让你去改你得找半天是不是
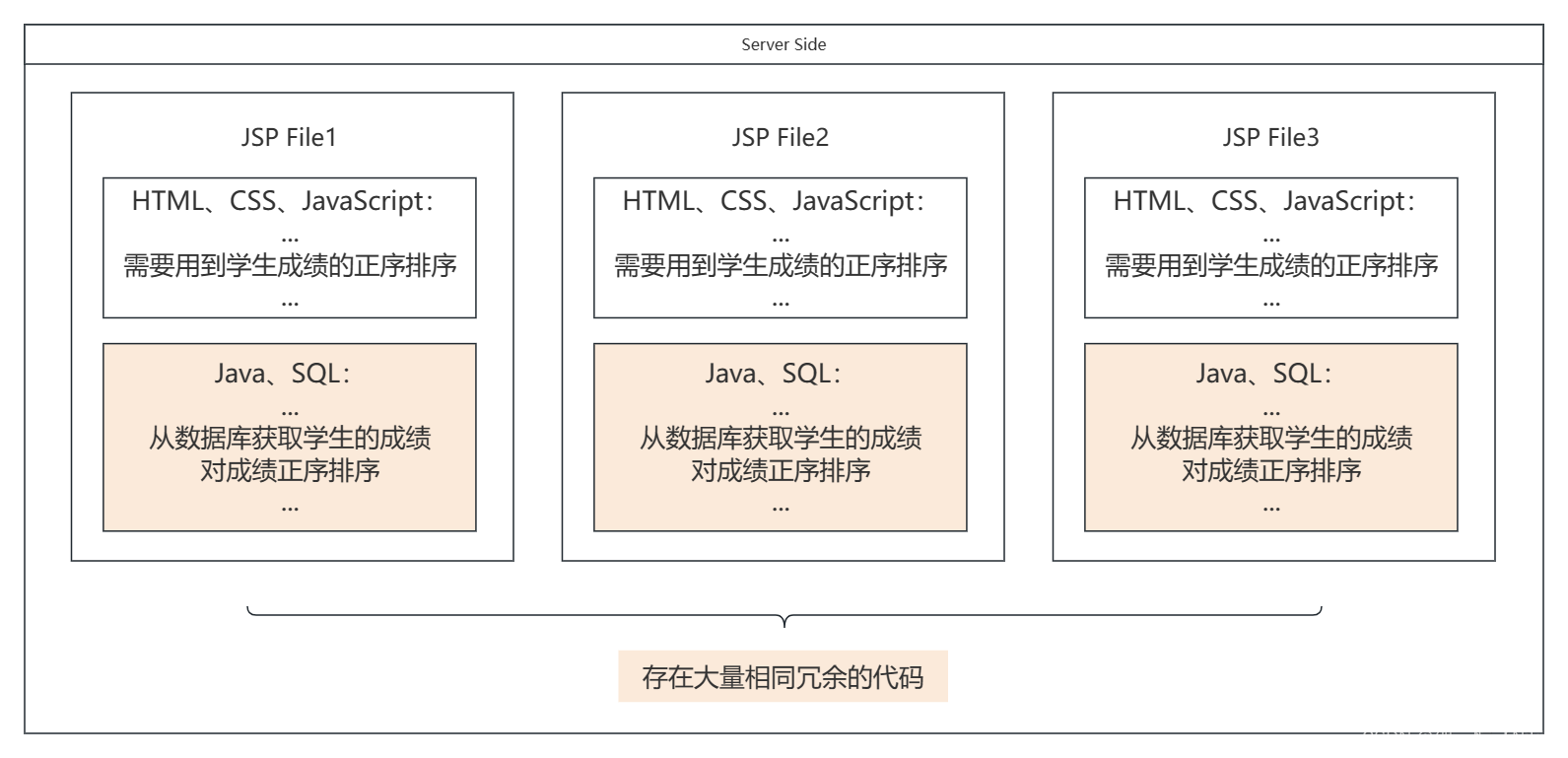
因此我们可以写一个类(Model),用于从数据库增删改查学生的成绩,以及对从数据库中获取的数据进行一些加工操作例如排序,而在 jsp 文件中仅仅需要少量的代码来调用类函数便可以在一定的程度上将前端代码(HTML、CSS、JavaScript)和后端代码(Java、SQL实现数据处理逻辑)给分隔开来,为什么是一定程度,因为在 jsp 中还是要有 java 代码来调用 Model 的数据是不是
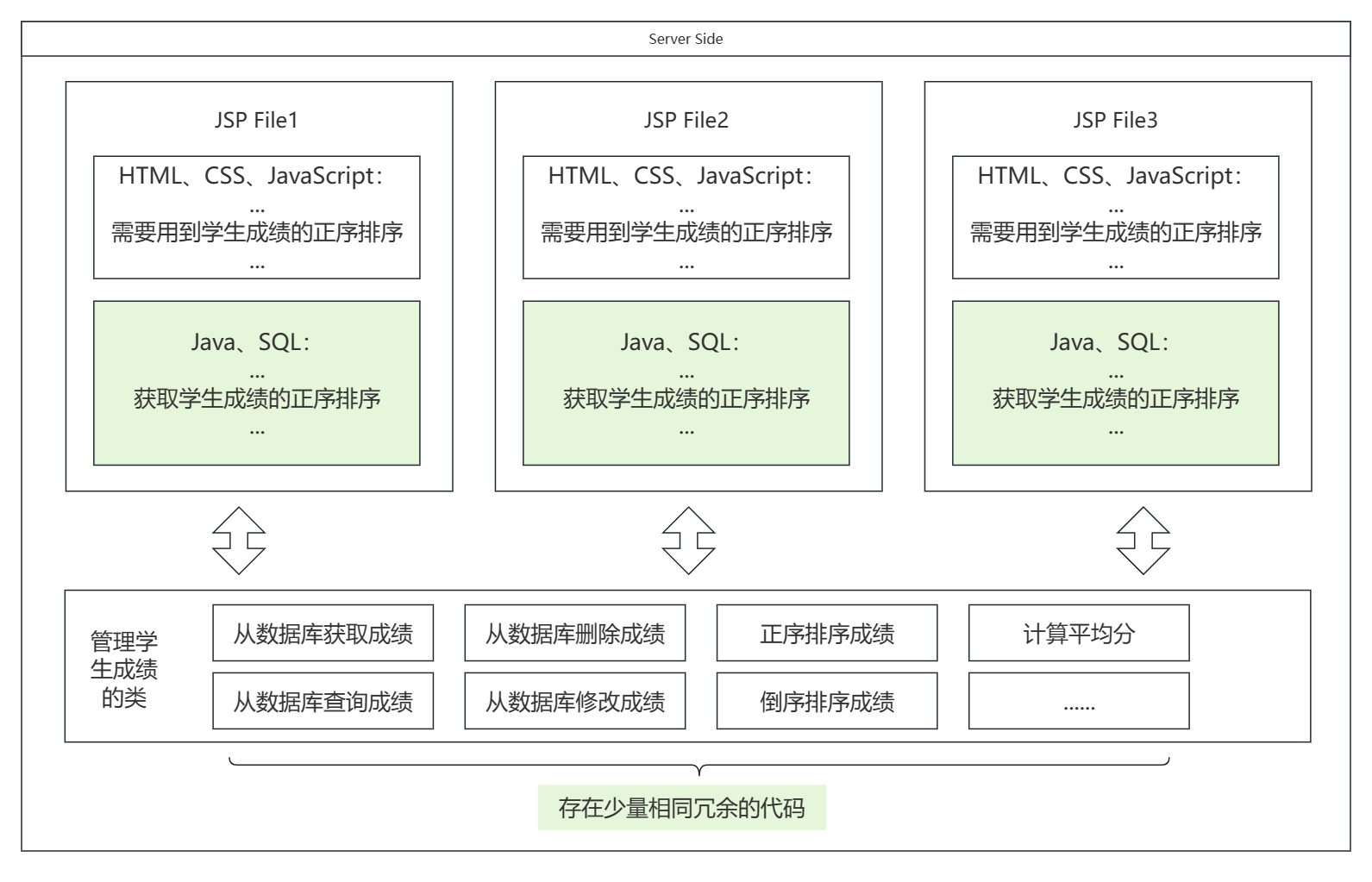
从上面可见基本是将前端三件套和用Java、SQL进行的数据逻辑处理部分分隔开了,这样对于前后端的职责会更加清晰一点,然而客户端传来的要求总是千奇百怪的是不是,可能客户端现在要查询学校的相关讯息,那么是不是又要创建一个用于管理学校讯息数据的类( Model),以及一些用于展示这些数据的页面(View),所以在用于请求的时候我们需要分析一下要满足用户这个请求,我们需要用到什么样的数据(Model),然后填到什么样的 jsp 文件中(View),再返回给用户,这个分析的层就是 Controller,所以现在整个服务器的运转就是:接收用户的请求 》 Controller 层判断要用到什么样的 Model(模型)、什么样的 View(视图) 》将数据填入视图中(变成了第一阶段的第二部:生成合适的 jsp 文件) 》把 jsp 文件在服务端解析成静态文件 》返回给客户端,系统的架构如下
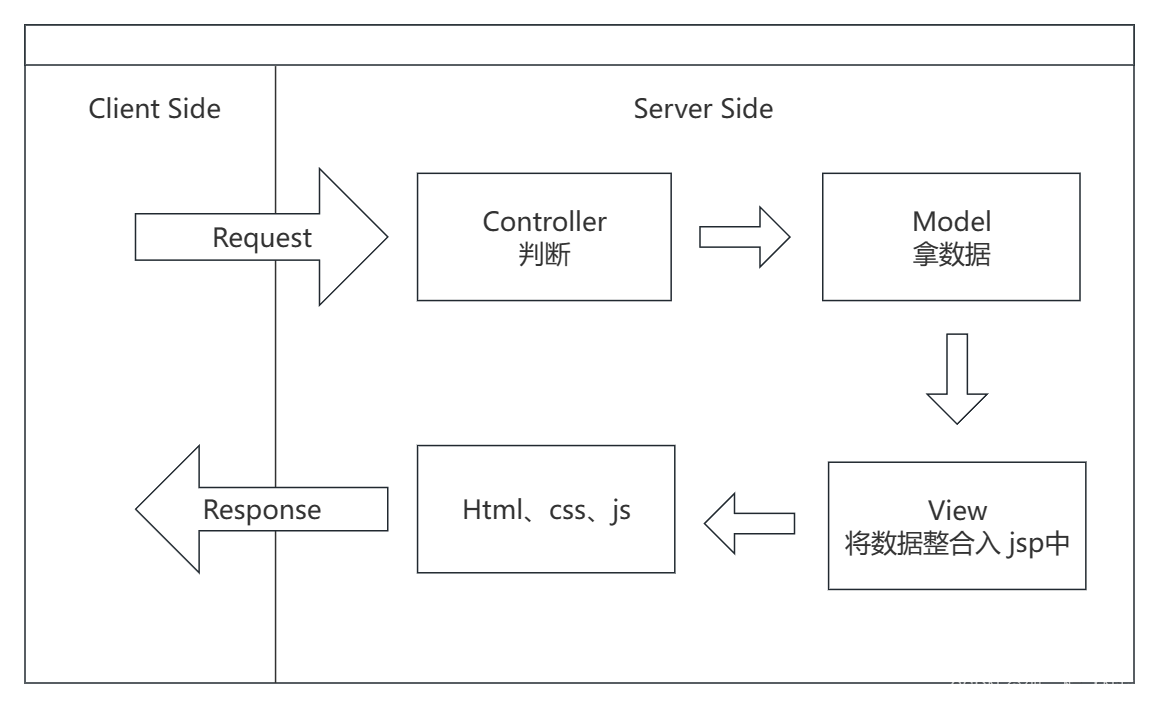
综上,这样的架构好处就是在一定程度能够将前后端分开,同时也提高了代码的复用性
2.1.3 第三阶段 —— 开发分家,前端后端两兄弟被运维一起薅
自从Gmail的出现,Ajax技术开始风靡全球,有了Ajax之后,前后端的职责更加清晰了,因为现在前端的代码里不需要有后端语言,而是通过Ajax向后端请求数据、进行数据交互,现在整体的架构图如下
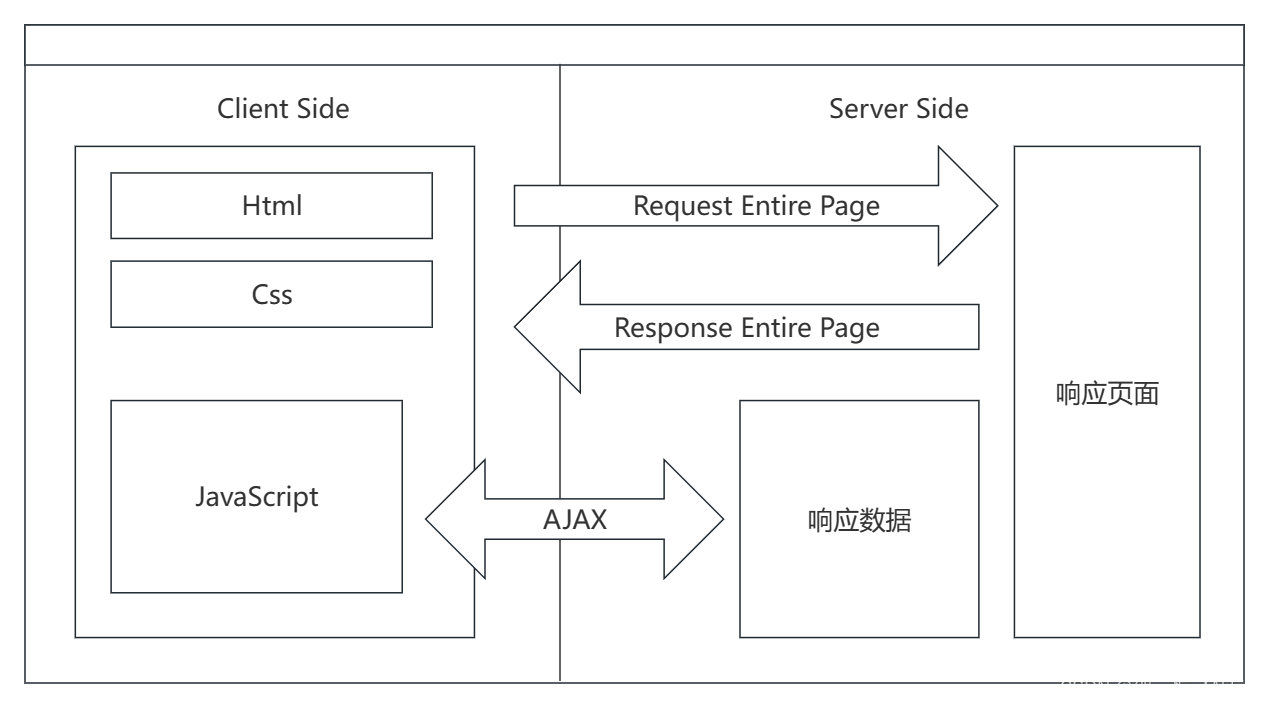
通过AJAX(可以使用JavaScript来使用)与后台服务器进行数据交换,前端开发人员现在只需要编写前端部分的内容即可,而数据交由后台进行加工、提供。并且AJAX可以实现页面的部分渲染刷新,使得相较于之前的阶段,没有必要每次请求服务器都要返回一个完整的静态页面回来,从而减少了流量消耗。此外,请求到的数据传到客户端,在客户端处进行渲染刷新,从而也减小了之前服务端要在自己那里渲染好再发给客户端的渲染消耗,这样用户请求的时候也会越快得到响应从而体验更加
不过这个阶段的问题就是,前端跟第一阶段的后端一样,数据拿到没有进行管理,所以前端的代码会很混乱,重复杂糅的也很多,使得前端不好维护,因此**前端 MVC **应运而生
2.1.4 第四阶段 —— 前端 MVC 腾空出世
前端 MVC 和后端 MVC 十分类似基本一样,都具备 View 、Controller 和 Model 三个板块。 Model 用于管理数据,并与后端数据进行同步;View 负责从 Model 那里获取动态数据,然后结合前端骨架以生成并视图;Controller 负责业务逻辑,根据用户行为对 Model 数据进行修改

举个栗子感受一下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>JavaScript MVC Example</title>
</head>
<body>
<div id="app">
<input type="text" id="input" placeholder="Enter a task">
<button onclick="controller.addTask()">Add Task</button>
<ul id="taskList"></ul>
</div>
<script>
// Model
let model = {
tasks: []
};
// View
let view = {
renderTasks: function() {
let taskList = document.getElementById('taskList');
taskList.innerHTML = '';
model.tasks.forEach(function(task) {
let li = document.createElement('li');
li.textContent = task;
taskList.appendChild(li);
});
}
};
// Controller
let controller = {
init: function() {
view.renderTasks();
},
addTask: function() {
let input = document.getElementById('input');
let task = input.value;
if (task) {
model.tasks.push(task);
view.renderTasks();
input.value = '';
}
}
};
controller.init();
</script>
</body>
</html>
然而前后端 MVC 的不同点在于,如果客户端产生的行为要对 Model 数据做修改,后端MVC是需要:前端发送请求 》后端Controller层 》后端Model层 》对数据进行修改;而前端MVC按理说是:前端发送请求 》前端Controller层 》前端 Model 层 》后端对数据进行修改;后端的 Controller 其实是为了能够解析客户端的请求(例如一个 URL 地址),然后将其映射为要对什么数据做什么操作,起到一个呈接前端和后端的作用;而前端的 Controller 就略显鸡肋了,因为其实没有它,我在 View 层也可以直接使用 js 代码去更改 model 的数据吧,因为 model 数据不也定义在 js 中吗,例如一个点击事件去修改 js 里的某一个变量不是件难事吧。为什么非要纠结这一点,是因为在客户端本来各种各样的行为事件都很多嘛,如果每一个小小的、很简单的事件都要经过这么一个流程,那其实是很不灵活、很鸡肋的,有的时候很希望我能够通过 View 层 直接去改 Model 层的数据,因此在实际应用场景中,往往会看到的是下面这种模式
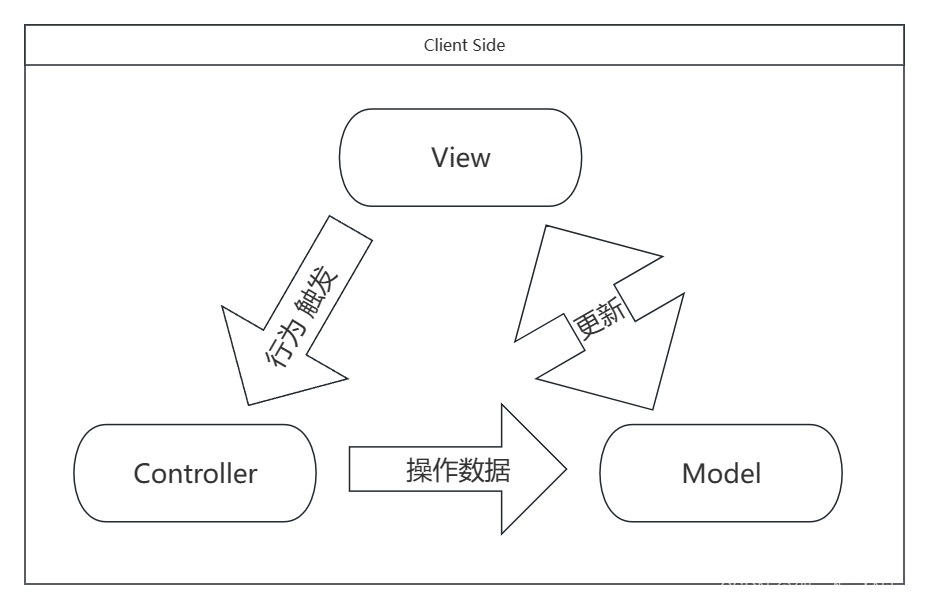
然而这种模式又有新的问题,就是数据流混乱,因为数据流形成回环了,有时候出现了Bug都不知道是哪个层引起的,因此 MVP 应运而生
2.1.5 第五阶段 —— MVP 腾空出世
MVP 和 MVC 依然是很相近的,P(Presenter)可以理解为中间人,现在 Model 和 View 的交互都必须要经过 Controller 来,而不能有直接的连线交流,这样可以避免回环导致数据流混乱,但是相较于之前的模式,Presenter就显得十分的庞大臃肿,因为之前 View 是一块用于从 Model 处取数据,然后进行 DOM 更新操作的代码逻辑,现在这部分的的工作落在了 Presenter 身上,Presenter 需要取出数据之后对 DOM 进行更新操作,而 View 现在变成了被动视图,可以理解为就是 HTML 那部分而已,而不再是一些JS代码了,MVP的模式如下
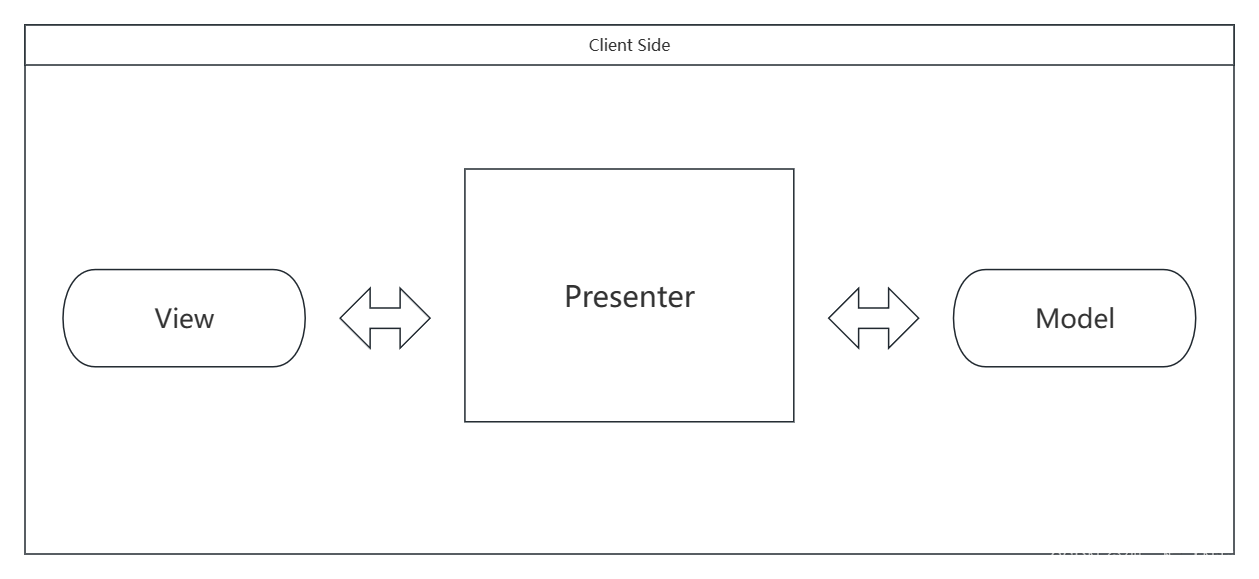
设想一下,如果页面中有十处零零散散的地方都用到了 model 的 A 数据,那么 Presenter 在渲染页面的时候是不是要写十条操作 DOM 的语句来将 A 渲染上去,更无语的是如果 A 要发生改动,又得写十条操作 DOM 的语句来将 A 修改进去,这样除了代码庞大之外,维护也不好维护。因此我们会想到能不能让这些页面上的数据和 model 的数据使用某种机制绑定起来,这样 model 数据更新的时候,不需要去操作 DOM ,页面上的数据会自动更新 —— 数据绑定,而页面上的数据发送变化的时候,model 中的数据也会自动更新 —— 数据监听。于是MVVM应运而生
2.1.6 第六阶段 —— MVVM 腾空出世
MVVM可以分解为Model、View、ViewModel,其实 ViewModel 差不多就是在 Presenter 的基础上实现数据绑定 Data Bindings 和数据监听 DOM Listeners,这样就没有必要在 model 数据发生变化的时候要去写一堆操作 DOM 的语句更新页面上相关的地方,对这种架构进行实现的正如 Vue,在 Vue 中我们在页面中使用的数据(View层)和 vm.data 中的数据(Model层)是可以相互绑定的,Vue 的底层还是离不开操作 DOM,只不过它对这些事情进行了封装之后给我们使用,不然怎么说 Vue 是一种前端框架呢,MVVM的架构如下
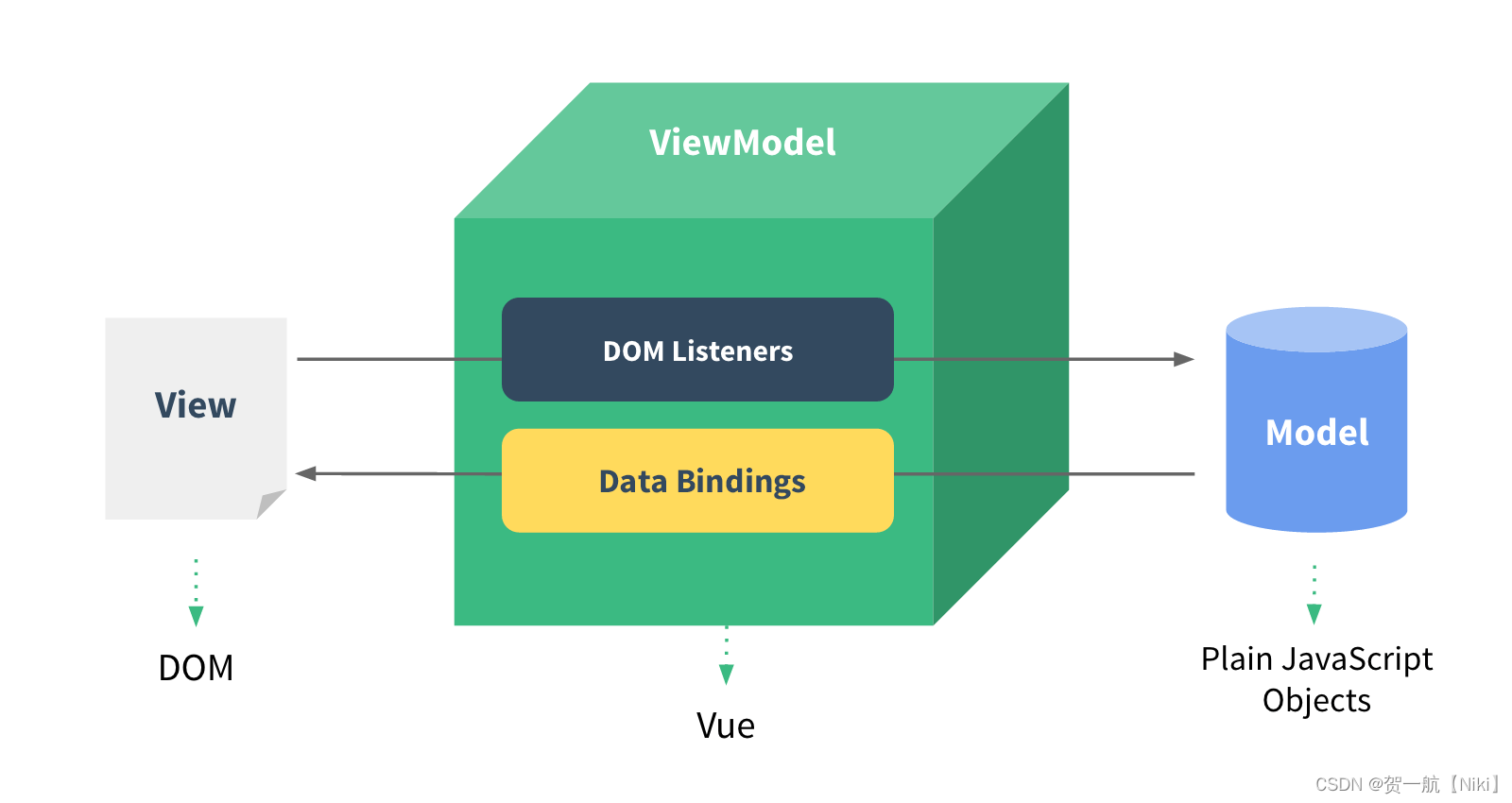 至此,前后端分离的便进化到目前最新 MVVM 阶段了,MVVM 在保持 View 和 Model 松耦合(基于MVP)的同时,还减少了维护它们关系的代码(基于P进阶成VM),使得用户能够更专注于业务逻辑,兼顾开发效率和可维护性
至此,前后端分离的便进化到目前最新 MVVM 阶段了,MVVM 在保持 View 和 Model 松耦合(基于MVP)的同时,还减少了维护它们关系的代码(基于P进阶成VM),使得用户能够更专注于业务逻辑,兼顾开发效率和可维护性
2.2、数据代理
2.2.1 Object.defineproperty 实现数据代理
Object.defineProperty() 是 JavaScript 中一个用来定义或修改对象属性的方法。它允许你精确地控制属性的行为,包括是否可枚举、是否可写、是否可配置等
Object.defineProperty(obj, prop, descriptor)
其中,obj 是要在其上定义属性的对象,prop 是要定义或修改的属性名称,descriptor 是一个描述符对象,用于定义属性的特性
| descriptor | 描述 |
|---|---|
| value | 设置属性的值,默认为 undefined |
| writable | 布尔值,表示属性是否可写,默认为 false |
| enumerable | 布尔值,表示属性是否可枚举,默认为 false |
| configurable | 布尔值,表示属性是否可配置,默认为 false。如果为 false,则属性不能被删除,也不能重新定义 |
| get | 一个给属性提供 getter 的方法,如果不存在 getter,则为 undefined |
| set | 一个给属性提供 setter 的方法,如果不存在 setter,则为 undefined |
与在对象的字面量中直接定义属性大有不同的是,使用defineproperty进行定义的属性可以使用他的get和set方法,设想一下如果在使用字面量定义一个对象的时候,属性值可以从外界引用,但是引用完两者就没联系了
<div id="root">
<button onclick="changnumber()">修改number</button>
<button onclick="showinfo()">展示数据</button>
</div>
<script type="text/javascript">
let number = 18
let person = {
name: 'niki',
gender: 'male',
age: number
}
changnumber = function () {
number = 12
}
showinfo = function () {
console.log(person)
}
</script>
就像这个例子中,person生成过程将number的值传给age,但是当person生成后无论number怎么便,person的age依然会是18,那我们希望age的值能跟number做同步,所以defineproperty的get配置就起到作用了
<div id="root">
<button onclick="changnumber()">修改number</button>
<button onclick="showinfo()">展示数据</button>
</div>
<script type="text/javascript">
let number = 18
let person = {
name: 'niki',
gender: 'male'
}
Object.defineProperty(person, 'age', {
get: function () {
return number
}
})
changnumber = function () {
number = 12
}
showinfo = function () {
console.log(person.age)
}
</script>
defineproperty给person身上安置一个age属性值,并使用get配置来动态地从number身上获取值来赋给age,当我们每次去访问age的时候都能够去调取number的值,这样就能够实现age地值和number的值同步,这便实现了数据监听的效果,让一个对象的属性值能够监听某个值并作出同步的改动
当然我们还可以使用set配置,让对象的属性值发生变化的时候,与其相关的属性也能做出同步的改动,这便实现了数据绑定的效果
<div id="root">
<button onclick="changage()">修改person.age</button>
<button onclick="shownumber()">number值</button>
</div>
<script type="text/javascript">
let number = 18
let person = {
name: 'niki',
gender: 'male'
}
Object.defineProperty(person, 'age', {
get: function () {
return number
},
set: function (value) {
number = value
}
})
changage = function () {
person.age = 12
}
shownumber = function () {
console.log(number)
}
</script>
数据监听和数据绑定能够让我们使用一个属性去代理操作另一个属性,因此我们可以称这种行为为数据代理。最后需要注意的一点是,当我们打印下面代码中的person对象
<script type="text/javascript">
let person = {
name: 'niki',
gender: 'male'
}
Object.defineProperty(person, 'age', {
get: function () {
return number
},
set: function (value) {
number = value
}
})
console.log(person)
</script>
我们将会得到如下结果,可以看到age的值是(…),当我们把鼠标移动到(…)上面的时候会看到“调用属性getter”的提示,点击之后就能显示出其值了,其实当我们点击的时候他会去调用他的get方法,获取到值了之后再返回到控制台上让我们看到,我们也可以看到只有defineproperty定义的age属性在控制台中才有get和set,因此以后打印一个对象如果看到他的属性带有一个get和set方法说明这个属性实现了数据代理
{
name: 'niki', gender: 'male'}
gender: "male"
name: "niki"
age: (…)
get age: ƒ ()
set age: ƒ (value)
[[Prototype]]: Object
2.2.2 vue 实现数据代理
没有学过Vue的盆友可以先听一下下面这段代码是怎么个事,vm = new Vue(…)说明vm是一个Vue类型的实例,它就是要来实现关联View层中的数据(name)和Model层中的数据(data.name),在创建vue实例的时候需要给Vue构造函数传入一个配置对象,el是指要关联哪个id的标签(这个标签中才能使用与之关联的vue实例的数据),接着就是data —— Model层的数据;View层中的{ {…}}是模板语法,会直接从vue实例身上获取相关属性的值,例如{ { name }}就会从相关的vue实例身上获取name属性vm.name
<!-- View层 -->
<div id="root">
<h1>Hello,{
{name}}</h1>
</div>
<script type="text/javascript">
// Vue来实现ViewModel层
const vm = new Vue({
el: '#root',
// Model层
data: {
name: 'niki'
}
})
</script>
然而,当我们在创建vue实例的时候,data的数据其实会被放入到vm._data属性中,而不是直接放在vm身上作为vm的属性,例如上例中定义的name其实要通过vm._data.name才能够访问到,但是我们上面说过了模板语法{
{ }}是要取vm身上的数据,既然{
{ name }}可以访问到正确的数据,就说明vm身上有一个name的属性,我们可以打印vm.name验证一下

既然name其实会被直接映射成vm._data.name,那么vm.name又是算什么,他是怎么来的,他出现的意义是什么呢?其实这里vue就是做了一个数据代理的工作,vue会在实例 vm 身上创建与 vm._data 中属性同名的属性用来代理 vm._data 中属性,通过打印vm实例可以看到name属性的get、set,说明这个属性是用来代理另一个属性的,也就是 vm._data.name,其原理就是基于上一小节说到的defineProperty方法,这样做的好处就是使得我们在使用模板语法的时候能够更加方便地去操作data中的数据

2.3、虚拟 DOM
虚拟 DOM(Virtual DOM)是在内存中的一个虚拟 DOM 树,是由 JavaScript 对象构成的树状结构,用来描述真实界面的 DOM 结构,通常前端框架(如React、Vue.js等)会使用到这项技术,例如对于
<div id="container" class="main-container">
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
</ul>
</div>
这段代码的虚拟 DOM 长下面这样,在 vue 中,每个组件都有一个 render 函数,每个 render 函数都会返回一个虚拟 DOM 树,这也就意味着每个组件都能够对应一颗虚拟 DOM 树,从下面的代码也可以看出其实每个组件(div、ul这些)的结构就是用大括号 { } 括起来的一个 js 对象进行描述,而这个 js 对象就是这个组件对应的虚拟 DOM
{
type: 'div', // 元素类型
props: {
// 属性
id: 'container',
className: 'main-container'
},
children: [ // 子节点
{
type: 'h1',
props: {
},
children: ['Hello, World!'] // 文本节点
},
{
type: 'p',
props: {
},
children: ['This is a paragraph.'] // 文本节点
},
{
type: 'ul',
props: {
},
children: [ // 子节点也可以是其他元素
{
type: 'li',
props: {
},
children: ['Item 1']
},
{
type: 'li',
props: {
},
children: ['Item 2']
}
]
}
]
}
虚拟 DOM 的出现主要是为了优化页面渲染性能和提高开发效率。在传统的前端开发中,直接操作真实 DOM 是一种比较低效的方式,因为每次对 DOM 进行操作都会触发浏览器的重排(Reflow)和重绘(Repaint),从而导致页面性能下降,例如在页面中要使用 appendChild 方法向某个列表添加十个元素
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Append Ten <li> to <ul></title>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









