







Abstract摘要:
主要分享了一套科学且适合实盘的机器学习回测方法。并且提供相关的因子计算代码。代码获取方法于文章结尾。
往期量化文章:
前一段时间我在群里分享了一张图片,是我在当晚做研究时跑出来的一个回测图。

一开始我还吓了一跳,怎么可能会这么丝滑,要真这么牛早发了。
然后我就发到了群里。
但是后来我仔细检查了一下,才发现这个基于机器学习的策略跑出来的回测图大有问题在!简而言之就是不小心涉及到了未来数据。
(狡辩一下,那天真的没有仔细检查~~不小心让标签使用的未来n天数大于了滚动的step的步数)
具体来说就是我一般跑涉及机器学习的策略都用到滚动训练,最后再拼接所有结果并计算回测净值曲线。(为了提高效率,先跑向量化回测,如果觉得向量化回测没问题再使用Veighna的事件驱动开源框架去跑回测)
其中的问题就要涉及到如何给数据打标签那么首先得讲讲有什么打标签方法,如下:
- ①基于未来k个单位数据(单位:天/秒/分等interval)的涨跌幅或者平均价格来打标签。二分类的话就只是打上涨和跌的标签。三分类的话就代表【涨、跌、震荡。比如某篇论文里讲的,就是在高频领域用买一卖一档的中间价来给当前数据打上标签。

- ②基于过去和未来k个单位数据(单位:天/秒/分等interval)来打标签。具体来讲,假设interval为天,该方法就是用过去k天的平均价格【高频领域就用平均中间价】和未来n天的平均价格进行计算,平均价格计算公式如下:

m_(t)代表过去的平均价格,m+(t)代表未来的平均价格。再对两者进行运算得出比较基准 Lt,计算公式如下:

然后设立一个阈值 α,当Lt> α时将此时定义为up涨;当Lt< -α时定义为down跌;-α < Lt< α时定义为震荡。其中 α > 0。

上图中第一幅图是基于方法①打的标签【绿涨/红跌/白震荡】,第二幅图基于方法②打的标签。 可以看到方法①中产生的标签信号并不连续,这在预测时会导致会产生许多redundant trading actions冗余的交易行为,增加交易成本。
- 基于无监督聚类方法来打标签。这种方法是静态的,大多出现在学术论文中,至少我在实盘的时候还挺少用到这个方法的,因为没办法保证每天聚类出来的标签意义跟昨天的是否一样。例如昨天聚类标签1观察出来是涨的,但是今天聚类出来的标签1变成跌了。所以这个方法需要每次聚类完后人工确定每个标签所代表的市场状态,挺麻烦的。(这个可以用滚动去跑聚类实证下)
打标签的代码如下:
def generate_labels(close_prices, day=5):
"""
生成基于收盘价的标签序列。
:param close_prices: numpy.array 股票的收盘价时间序列数组
:return: numpy.array 标签序列数组
"""
# 确保收盘价数组长度至少为5,否则无法生成标签
if len(close_prices) < day:
raise ValueError("收盘价数组长度至少为5。")
# 初始化标签数组,长度与收盘价数组相同,初始值为0
labels = np.zeros(len(close_prices), dtype=int) - 1
# 计算标签,除了最后4个标签强制设置为1
for i in range(len(close_prices) - day):
# 如果5天后的收盘价高于当天的收盘价,则标签为1
if close_prices[i + day] > close_prices[i]:
labels[i] = 1
# 将最后4个标签设置为1
labels[-day:] = 1
return labels
def paper_label(close, k=10, alpha=0.0005):
labels = np.zeros(len(close), dtype=int)
alpha = alpha # 目的是使训练集有一个的分类标签平衡
keys = list(close)
for i, time_key in enumerate(keys):
if i < k or i > len(keys) - k:
continue
last_price = keys[i - k: i]
m_last = sum(last_price) / k
future_price = keys[i: i + k]
m_futu = sum(future_price) / k
Lt = (m_futu - m_last) / m_last
if Lt > alpha:
label = 1
elif Lt <= -alpha:
label = -1
else:
label = 0
labels[i] = label
return labels
y = generate_labels(data['close'], day=5)跑模型训练的方法也有以下:
-
①仅做一次训练然后用该模型跑。这种常见于学术论文,如某个群里的群友分享的论文。这种方法极其不适合实盘,因为如何保证这一区间的训练集能识别出未来长期有效的模式呢?显然是不能的,市场是时变的,人也是终身学习的,更何况机器算法呢。
所以这类型论文的模型基本不能直接拿来跑实盘,拿来跑的话最多有效期不过几个月。
-
②进行滚动训练,根据时间间隔来跑。而滚动的step一般为测试集的长度。

那如果使用的是上述基于未来数据打标签的方法的时候就会出现以下问题:
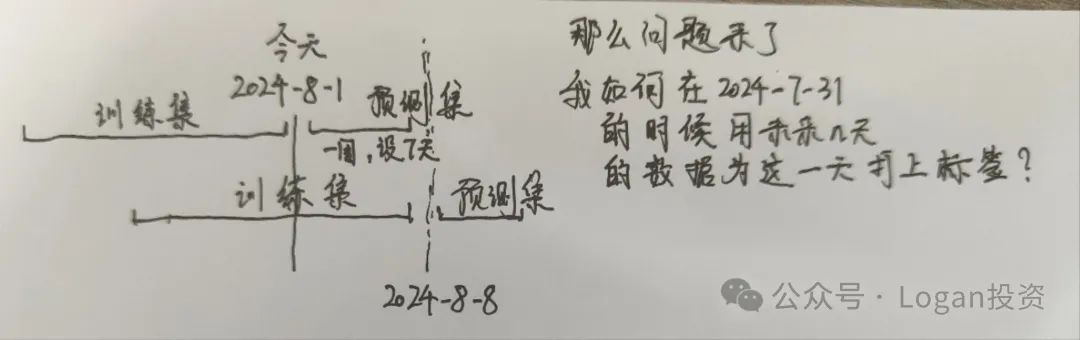
而我那时的参数设置被函数折叠起来了·······又调了另一个参数,进而让标签使用的未来n天数大于了滚动的step的步数,导致滚动的时候有一部分使用了未来数据。(标签我是在训练之前就写好的)
所以基于上面的问题,就会发现其实很多学术论文真的是没法看的,测出来的曲线完全没有以实盘环境为基准
所以得使用更科学的机器学习预测方法才行
而我平时使用的更多是添加了验证集和暂停区间的滚动训练方法。该方法来自知网引用了100+的论文。具体如下。
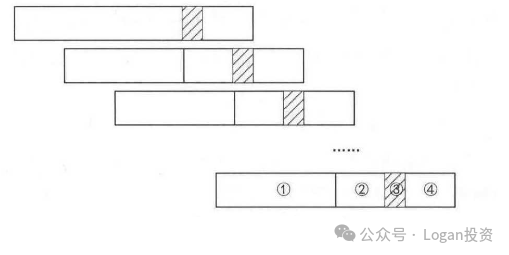
①②③④分别代表训练区间、验证集、暂停区间和测试集。
这种方法与现实中的投资过程一致,而且滚动窗口保留了数据内部时间序列信息,不是随机切分,符合现实,同时暂停区间的存在防止了训练区间的收益率向量使用到测试区间的价格数据而影响预测的准确率(高估,这就是我出现的问题),使用更加有效的模拟实盘过程来进行回测。
(也有人在原始数据集上随机选择数据来构建每次的训练集,但其实这是引入了未来数据的。因为市场风格是时变的,如果随机分的话就相当于将未来的市场风格数据泄露给了当前训练的模型,这一点从逻辑上就得否掉这个做法。所以为了模拟真实情况,还是建议用上述方法,保留数据内部的时间序列信息)
而在论文中,作者还使用了一系列基于量价数据计算的技术因子来训练模型构建策略。文中用了5年846个股票的日频数据,使用了Adaboost、SVM、Nerual Network、OLS、buy and hold(BH)和规则型策略(金叉死叉)。因子为19个技术因子,例如MACD、KDJ等等。
回测考虑了双边万5的交易成本。
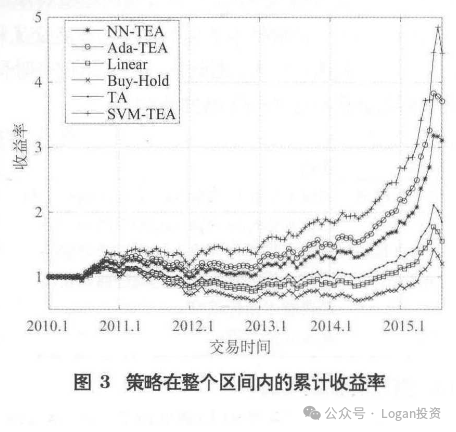
策略回测如上图所示,虽然数据区间存在一段显著的牛熊市,有代表性,但说实话到如今这些因子已经没什么超额能赚了。至少我实证下来感觉一般。下图为策略的超额收益曲线。
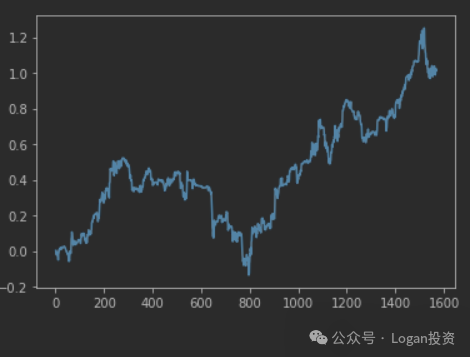
关于这一套技术因子的计算代码我也简单复现了一下,一键生成,需要群友自己去训练了。
TEA = ML_TEA(
np.array(data['open']),
np.array(data['high']),
np.array(data['low']),
np.array(data['close']),
np.array(data['volume'])
)
factor = TEA.get_factor()代码、论文pdf和量化交流群,则需要将推文转发到百人以上的量化交流群,并保持3分钟以上的截图即可gzh后台发我就好。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









