







 本文详细探讨了C++中switch语句的正向实现和反汇编分析,揭示了其在不同case数量和常量差值下的执行策略。对于少量且连续的case,switch使用大表优化;对于不连续或大量case,可能采用顺序比较。此外,还介绍了大表与小表的生成条件,以及它们如何节省内存和提高效率。通过对反汇编的解析,展示了switch语句在不同场景下的执行流程。
本文详细探讨了C++中switch语句的正向实现和反汇编分析,揭示了其在不同case数量和常量差值下的执行策略。对于少量且连续的case,switch使用大表优化;对于不连续或大量case,可能采用顺序比较。此外,还介绍了大表与小表的生成条件,以及它们如何节省内存和提高效率。通过对反汇编的解析,展示了switch语句在不同场景下的执行流程。
一、switch正向
-
switch语句是特定业务逻辑功能的if语句的简写
if(表达式 == 常量1){ //...代码 } else if(表达式 == 常量2){ //...代码 } else if(表达式 == 常量3){ //...代码 } else{ //...代码 }用switch表示简写为:
switch(表达式){ case 常量表达式1: 语句; break; case 常量表达式2: 语句; break; //break不写功能就变了 case 常量表达式3: 语句; break; case 常量表达式4: 语句; break; default: //可以省略,但是不建议省略 语句; break; } -
switch语句的规范:
- case后面必须是常量表达式
- case后常量表达式的值不能一样
- switch后面表达式必须为整数
-
switch语句的执行顺序:按照正向的角度,我们会以为switch和if else一样,都是一个一个的从上往下比较,但是真的如此嘛???不全是,switch强大的地方,就是在执行的效率。下面我们通过反汇编从底层去看看switch究竟怎么执行的?
-
如果多个分支执行相同的语句,则可以如下定义:
#include "stdafx.h" char x = 'C'; int main(){ switch(x){ case 'A': case 'B': case 'C': case 'D': case 'E': x += 32; break; default: printf("no"); } }
二、switch语句反汇编
1.case数量较少时(和if类似)
这个会比较常见
-
我们先来看看如果需要比较的常量数量较少,而且常量之间的差值不大时,switch的反汇编
#include "stdafx.h" int x = 2; int main(){ switch(x){ //此时只有3个case,且1,2,3这三个常量差值不大 case 1: printf("1"); //不能用单引号! break; case 2: printf("2"); break; case 3: printf("3"); break; default: printf("Error"); break; } }-
可以发现,当case常量数量较少时,switch和if else的逻辑类似,都是顺序比较判断决定是否跳转,只不过switch把所有比较跳转的指令都放在了一起,然后将所有执行的代码指令都放在了一起。所以当判断比较的常量数量较少时switch和if语句的效率差不多

所以通过反汇编就发现了如果switch语句中的case代码结尾不加break,那么相当于就没有
jmp 结束地址这条指令,那么在最开始cmp不断比较,只要有一个满足了,那么就je跳转到对应case中的代码指令中执行,然后依次顺序把下面的case代码和default代码都执行了,最后到switch结束地址
-
-
(补充)如果是下面这种格式的呢?
#include "stdafx.h" char x = 'C'; int main(){ switch(x){ case 'A': case 'B': case 'C': case 'D': case 'E': x += 32; break; default: printf("no"); } }-
这里也比较巧妙的判断了,没有一个一个去比较,而是用一个区间范围去比较,比如先判断x是否小于A,用ASCII码比较的,即如果连41h都没大于,就直接跳到default,如果大于A了,还有比较是否小于
E,即小于E的ASCII码45h,如果大于了45h则也直接跳到default。如果这两个条件都满足,那么就说明x在case常量范围中,则跳转到代码段执行即可最后jmp到switch结束
-
2.case数量大、常量连续(大表)
这种情况是最常见的,因为写正向代码时,使用switch都是这样差值不大且连续的常量(记住这个)
-
如果case常量的数量较多,而且常量是连续的,比如像1,2,3,4,5…;或者101,102,103,104…
不同的编译器对这个临界值的设计不尽相同,VC是4!!!!!
#include "stdafx.h" int x = 2; int main(){ switch(x){ //此时有4个case,且1,2,3,4这四个常量差值不大 case 1: printf("1"); break; case 2: printf("2"); break; case 3: printf("3"); break; case 4: printf("4"); break; default: printf("Error"); break; } }-
可以发现当case数量多了以后而且常量的差值不大时,switch语句的比较跳转的指令逻辑就完全变了:不再是一个一个条件cmp再jcc跳转,即不是通过一个一个判断比较通过jcc指令跳转
-
而是先使用大表将switch中每一个case中代码的的首地址先存储在内存中,且是按照case常量从最小到最大的顺序连续(++)从低地址向高地址排列好,一个地址占4个字节;
-
接着先将switch的表达式x减1:这是因为现在需要得到x是第几个case中的常量,所以用x-第一个case的常量的差值,得到x是第几个case。所以x-1的作用有两个,①第一个是用来判断x是否在case常量的范围内,不在就立即执行到default;②第二个是用在计算得出应该跳转到哪一个case中的代码
-
接着用这个差值与(最大case常量-最小case常量)做比较,如果小于则x就是在最小到最大的case常量的范围内;如果大于,就表示x的数值不在case常量的范围内,那就要执行default中的代码,所以会看到有一个ja跳转到default代码段的首地址。
因为假如现在x=5,那么5 - 1 = 4,4是大于3的,就要执行default中代码。验证就可以发现5确实不在case1,2,3,4中,所以就执行default。x=6也是不在case常量的范围内的。但是x=1,2,3,4减完1就小于等于3,而且确实1,2,3,4都在case1,2,3,4范围内,就不用default
-
如果在最小到最大的case常量的范围内,那么现在就要决定x究竟跳转到哪一个case中的代码执行呢?此处就是switch最强大的地方:switch不再一个一个比较x究竟等于哪一个case的常量,而是直接通过前面计算的差值(有点类似偏移量),去查询内存中存放了4个case代码段起始地址的大表,得到从大表第一个地址加偏移量 * 4的内存中存的地址值,接着直接跳转到那一个case代码段。
因为大表中从低地址0x4010A3往高地址4个字节为单位顺序存储了4个case中的代码段的首地址!所以我们看到指令中有
jmp dword ptr [0x4010A3 + edx * 4]。edx中存放的就是x-1的值,即x是第几个case(或者对应第几个case常量)。如果x = 1,那么x-1 = 0,那么就会根据大表中的0x4010A3内存中存的值0x401049,即case1代码段的首地址,跳转到这个地址继续执行,则表示该执行第一个case1中的代码。如果x=3,那么x-1 = 2,则会查新大表中[0x4010A3 + 4 * 2]这个内存中的地址值,即case3代码段的首地址,则表示该执行第三个case3中的代码,所以最后jmp到这个地址继续执行…
-
-
-
如果现在使用case101,102,103,104,105也是同样的道理
#include "stdafx.h" int x = 2; int main(){ switch(x){ case 101: printf("101"); break; case 102: printf("102"); break; case 103: printf("103"); break; case 104: printf("104"); break; case 105: printf("105"); break; default: printf("Error"); break; } }-
同样也是由大表(内存)记录下五个case代码段的首地址,然后x-101计算是第几个case,并判断是否在case101到105范围内,如果不在则跳转到default代码段继续执行;如果在,则通过大表的第一个内存地址 + 4 * 差值,来决定应该jmp到哪一个case代码段首地址继续执行

-
下面开始就是一些很特殊的情况了,因为没有人闲着写switch的正向代码这么写,很奇怪的,所以一般做逆向都是见不到的!!!
3.case数量大、常量差值小且不连续(大表)
-
如果不是常量的值和顺序都不是连续的,比如case10,case7,case4,case8
#include "stdafx.h" int x = 2; int main(){ switch(x){ case 10: printf("10"); break; case 7: printf("7"); break; case 4: printf("4"); break; case 8: printf("8"); break; default: printf("Error"); break; } }-
可以发现,还是将每一个正向代码中的case代码段的首地址存到了内存中,但是多了default的首地址,是因为现在的case常量已经不连续了,中间空出来很多,那么现在把最小的常量4到最大的常量10挨个按顺序从低地址向高地址存储起来。中间如果没有的比如5,6,9那么这些内存中就存default的首地址,这非常合理
-
所以一共就有10 - 4 + 1 = 7个地址,每一个地址对应一个常量,x-4就是计算x是不是在这七个中,如果偏移量大于6,那么就不属于case4到10这个范围内,所以直接就default根本不用查表;如果偏移量小于6,说明就在表中。那么根据[偏移量 * 4 + 0x4010A3]就可以得到应该是第几个:如果是x=4,4-4就等于0,则偏移量是0就对应表的第一个内存中的地址,所以会跳转到case4的代码段首地址;如果x=6,6-4等于2,则偏移量是2,就对应表的第3个内存中的地址,所以会跳转到default代码段首地址执行

-
4.case数量大、常量差值很大且无规律(和if类似)
-
我们根据上面的三种情况可以发现,在内存中建立的这个大表,是从最小的case常量到最大的常量、且连续的记录,如果有对应的case常量那么此内存中就存储对应case的代码段首地址;如果没有对应的case常量此内存就存储default的代码段首地址。所以如果现在常量的差值很大,比如最小的是1,最大的是10000,而且中间也是零零散散的常量,比如33,57,102,3040,那么大表中还是要记录10000-1+1 = 10000个,但是到多数内存中存的地址都是default代码段的首地址,完全没有意义,效率极低,所以此时还是会用最原始的方法一个一个比较,就不会使用大表
#include "stdafx.h" int x = 2; int main(){ switch(x){ case 102: printf("102"); break; case 3040: printf("3040"); break; case 1: printf("1"); break; case 10000: printf("10000"); break; case 33: printf("33"); break; case 57: printf("57"); break; default: printf("Error"); break; } }
5.case数量大、常量差值小但空缺的常量多(大表与小表)
-
如果现在switch中的分支多,最大和最小差值小,但是中间很多case常量都空缺,比如case1,2,9,10
#include "stdafx.h" int x = 2; int main(){ switch(x){ case 1: printf("1"); break; case 2: printf("2"); break; case 9: printf("9"); break; case 10: printf("10"); break; default: printf("Error"); break; } }-
上述的第3种情况下,编译器也会创建大表,但是当中不光会存储case不同常量的代码段起始地址,还会消耗多个空间存储同样default代码段的起始地址,那么这样就会浪费内存空间,所以在VC6编译器的设定下,只要空间空缺的case常量大于6(一定记住不同编译器这个值是不同的,没必要记住),那么就会在内存中挨着大表创建一张小表,现在来看看小表的作用:如何节省空间?
-
大表中还是从最小的case常量连续存到最大的case常量,但是由于小表的出现,现在会把多个原本存储default的内存空间节省掉,先将case1,2,9,10代码段的起始地址存储完后,最后一个内存就存default代码段的起始地址,即现在将多个存default的内存压缩成了一个来存储。
-
但此时小表中会记录最小case1到最大case10,但是每一个只占1字节:00 01 04 04 … 02 03
-
那么我们看看小表是是如何工作的:
-
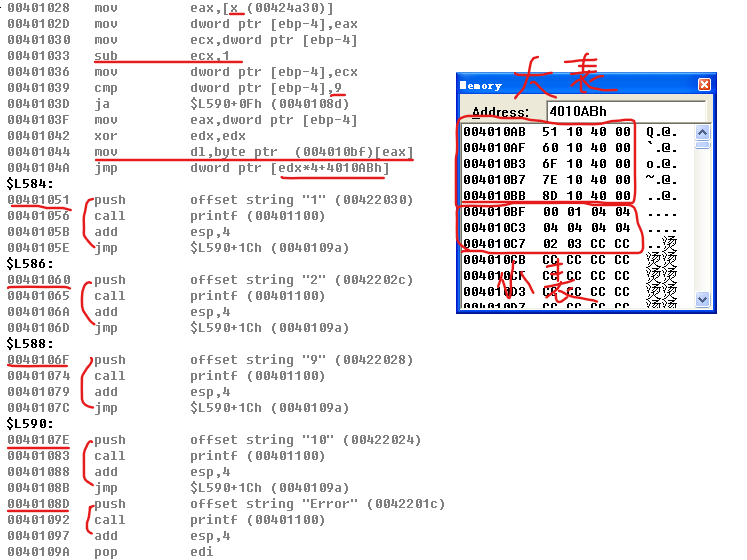
如果判断出x的值在1到10范围内,那么就不会跳转到default,先用
xor edx,edx将edx寄存器中的值清零 -
下面多了一个新的指令
mov dl,byte ptr (0040108d)[eax]这条语句的作用就是eax中存的值如果是1,那么就用0x40108d + 1 * 1(因为byte)将结果存入dl8位寄存器中;如果eax中存的值是2,那么就用0x40108d + 2 * 1…以此类推 -
0x40108d就是小表中的第一个字节数00;eax中的值就是x-最小case常量得出来的差值,那么这个差值决定了在小表中取第几个字节的值。如果差值为0,则dl中的值为0x00,那么最后应该jmp到0x4010AB + 0 * 4,即大表中第一个内存中的地址值—case1代码段起始地址;如果差值为3,则dl中的值为0x04,那么最后应该jmp到0x4010AB + 4 * 4,即大表中的第五个内存中的地址值—default代码段起始地址;如果差值为9,则dl中的值为0x03,那么最后应该jmp到0x4010AB + 3 * 4,即大表中的第四个内存中的地址值—case10代码段的起始地址
-
-
综上就是先查小表,再查大表!小表中的数决定了不同的差值应该读取大表中第几个内存中的地址值,而且小表中数的数量要为最大case常量-最小case常量,即把最大最小之间的所有case常量相对于最小case常量的差值都要表示到;大表中还是从最小到最大依次记录了对应case的代码段的起始地址,只是将本应该有多个default代码段起始地址的内存合并成了一个。所以小表会节省内存空间
-
还是这种情况下如果有一个常量>=256,就不会再生成小表了!
-
而且如果case的数量大于了255个,此时也无法再生成小表了!因为小表一个字节最多表示的数为FF即255,如果case的数量大于255,那么一个字节就没法表示在大表中的偏移了
-
-
三、作业
-
写一个switch语句,不生产大表也不生产小表,贴出对应的反汇编
#include "stdafx.h" int x = 2; int main(){ switch(x){ case 1: x += 1; break; case 2: x += 2; break; default: printf("no"); } }
-
写一个switch语句,只生成大表,贴出对应的反汇编
#include "stdafx.h" char x = 'C'; int main(){ switch(x){ case 'A': printf("A"); break; case 'B': printf("B"); break; case 'C': printf("B"); break; case 'D': printf("B"); break; default: printf("no"); } }
-
写一个switch语句,生成大表和小表,贴出对应的反汇编
#include "stdafx.h" char x = 'C'; int main(){ switch(x){ case 'A': printf("A"); break; case 'B': printf("B"); break; case 'C': printf("C"); break; case 'Z': printf("Z"); break; default: printf("no"); } }
-
为do…while语句生成的反汇编填写注释
void Func(int x,int y){ do{ printf("%d\n",x); x++; }while(x>y); }
-
为while语句生成的反汇编填写注释.
void Func(int x,int y){ while(x<y){ printf("%d\n",x); x++; } }
-
为for语句生成的反汇编填写注释
void Func(int x,int y){ for(int i=x;i<y;i++){ printf("%d\n",i); } }















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









