







一.全文搜索Lucene入门
1. 概念:
狭义的理解主要针对文本数据的搜索。
数据可分为“结构化”数据(关系数据库表形式管理的数据),半结构化数据(XML文档、JSON文档),和非结构化数据(WORD、PDF),通常而言在结构化的数据中搜索性能是比较高的,全文搜索的目的就是把非结构化的数据变成有结构化的数据进行搜索,从而提高搜索效率。
全文搜索引擎 : 就是把没有结构的数据,转换为有结构的数据,来加快对文本的快速搜索,通常而言,有结构的数据的查询是很快的,比如: 有序数组 , 红黑树
2. 全文搜索特点:
- 相比于mysql的lilke匹配来说:搜索的效率高。
- 相关度最高的排在前面。
- 关键词高亮。
- 只处理文本,不处理语义。 以单词方式进行搜索,如:在输入框中输入“中国的首都在哪里”,搜索引擎不会以对话的形式告诉你“在北京”,而仅仅是列出包含了搜索关键字的网页。
2.1 常见的全文搜索
全文搜索工具包-Lucene(核心)
全文搜索服务器 ,Elastic Search(ES) / Solr等封装了lucene并扩展
3. Lucene索引原理:
Lucene的核心分为:索引创建,索引搜索.
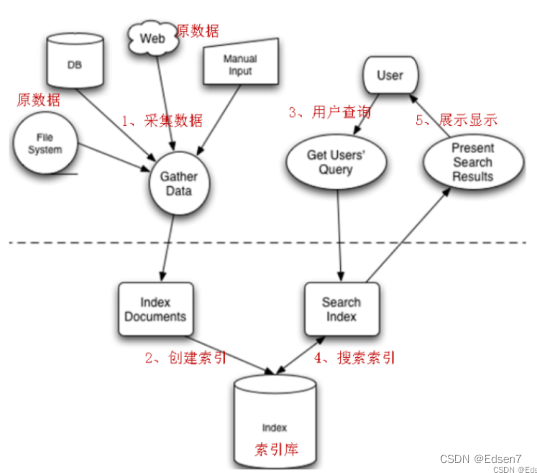
3.1. 索引的创建[重要]
将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
那么索引里面究竟存的什么,以及如何创建索引呢?在这通过下面的例子来解答这个问题。首先构造三个不同的句子,有长有短:

在①处分别为3个句子加上编号,然后进行分词,把被一个单词分解出来与编号对应放在②处;在搜索的过程总,对于搜索的过程中大写和小写指的都是同一个单词,在这就没有区分的必要,按规则统一变为小写放在③处;要加快搜索速度,就必须保证这些单词的排列时有一定规则,这里按照字母顺序排列后放在④处;最后再简化索引,合并相同的单词,就得到如下结果:倒排索引文档:

通常在数据库中我们都是根据文档找到内容,而这里是通过词,能够快速找到包含他的文档,这就是文档倒排链表。以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二元搜索算法快速定位关键词。
3.2. 索引的搜索
就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
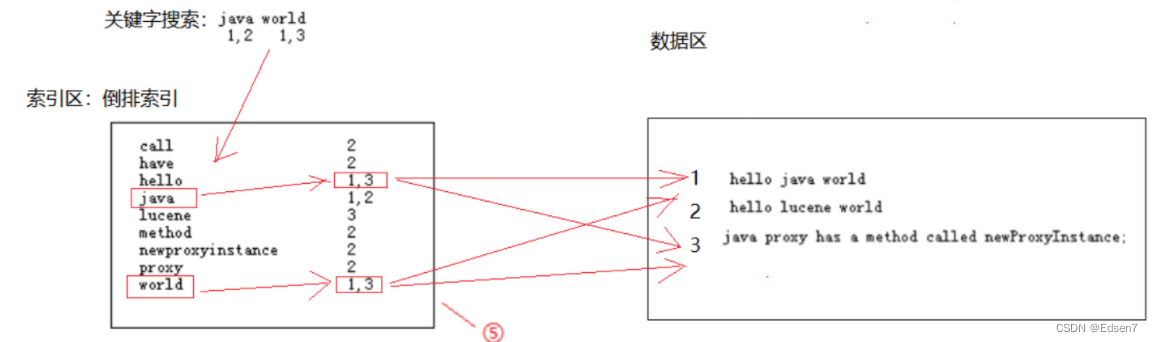
java world两个关键词,符合java的有1,2两个文档,符合world的有1,3两个文档,在搜索引擎中直接这样排列两个词他们之间是OR的关系,出现其中一个都可以被找到,所以这里3个都会出来。全文检索中是有相关性排序的,那么结果在是怎么排列的呢?hello java world中包含两个关键字排在第一,另两个都包含一个关键字,得到结果,hello lucene world排在第二,java在最长的句子中占的权重最低排在结果集的第三。从这里可以看出相关度排序还是有一定规则的。
二.ElasticSearch相关概念
1. 引入
虽然全文搜索领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。三.ES下载和安装
2. 概念
ES是一个分布式的全文搜索引擎,为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐Lucene的复杂性,从而让全文搜索变得简单。
3.ES的特点
-
分布式的实时文件存储
-
分布式全文搜索引擎,每个字段都被索引并可被搜索
-
能在分布式项目/集群中使用
-
本身支持集群扩展,可以扩展到上百台服务器
-
处理PB级结构化或非结构化数据
-
简单的 RESTful API通信方式
-
支持各种语言的客户端
-
基于Lucene封装,使操作简单
4. ES和lucene的区别
- Lucene只支持Java,ES支持多种语言
- Lucene非分布式,ES支持分布式
- Lucene非分布式的,索引目录只能在项目本地 , ES的索引库可以跨多个服务分片存储
- Lucene使用非常复杂 , ES屏蔽了Lucene的使用细节,操作更方便
- 单体/小项目使用Lucene ,大项目,分布式项目使用ES
三.ES下载和安装
1.ElasticSearch安装
1.1. 下载地址:https://www.elastic.co/downloads/elasticsearch
1.2. 安装与启动
解压即可,双击安装目录 bin/elasticsearch.bat即可启动
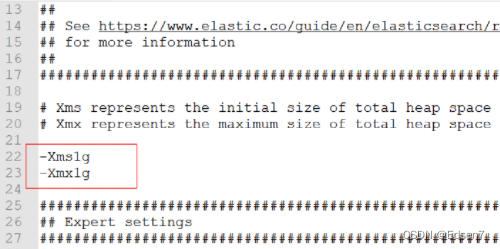
1.3. ES内存配置
修改 jvm.options 文件来修改内存
2.Kibana5安装 (可视化平台和Elasticsearch一起工作)
1.1. 下载地址:https://www.elastic.co/downloads/kibana
2.1. 安装与启动:同上
2.2. Kinbana连接ES配置:
解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
默认情况下,Kibana会链接本地的默认ES http://localhost:9200 ,如果需要修改链接的ES服务器,通过修改安装目录下 config/kibana.yml,将配置项 #elasticsearch.url: "http://localhost:9200" 取消注释即可修改连接的ES服务器地址。
2.4. 测试Kibana
浏览器访问http://localhost:5601 Kibana默认地址
Kibana组件详细说明:
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
四.ElasticSearch基础
1.基本概念
1.1.Near Realtime(NRT)
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
1.2.Index:索引库
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
1.3.Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,·`一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
1.4.Document&field
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
五.DSL查询与DSL过滤
1. DSL查询
1.1.DSL查询
对于简单查询,使用查询字符串比较好,但是对于复杂查询,由于条件多,逻辑嵌套复杂,查询字符串不易组织与表达,且容易出错,因此推荐复杂查询通过DSL使用JSON内容格式的请求体代替。
DSL查询是由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。DSL有两部分组成:DSL查询和DSL过滤。
1.2.DSL过滤
DSL过滤语句和DSL查询语句非常相似,但是它们的使用目的却不同:DSL过滤文档的方式更像是对于我的条件"有"或者"没有"(等于 ;不等于),而DSL查询语句则像是"有多像"(模糊查询)。
1.3.查询与过滤的区别
DSL过滤和DSL查询在性能上的区别:
-
过滤结果可以缓存并应用到后续请求。
-
查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存。
-
过滤语句可有效地配合查询语句完成文档过滤。
总结:需要模糊查询的使用DSL查询 ,需要精确查询的使用DSL过滤,在开发中组合使用(组合查询) ,关键字查询使用DSL查询,其他的都是用DSL过滤。
六. 文档类型映射
1.基本概念
1.1. mysq和ES对比
Mysql创建数据库 -> 创建表(指定字段类型) -> crud数据 而在ES中也是一样,
ES创建索引库 -> 文档类型映射 -> crud文档
1.2.默认的字段类型

七. SpringBoot整合ES
1. 导入依赖
<!--SpringBoot-->
<parent>
<groupId> org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.5.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
2.配置yml
spring:
elasticsearch:
rest:
uris:
- http://localhost:9200
3.启动类
@SpringBootApplication
public class ESApplication {
public static void main(String[] args) {
SpringApplication.run(ESApplication.class,args);
}
}
4.创建对象
注意:如果这个依赖的版本过高,type = "_doc"会报错
<parent>
<groupId> org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.5.RELEASE</version>
</parent>
@Document(indexName = "order",type = "_doc")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class OrderDoc {
@Id
private Integer id;
@Field(type = FieldType.Text ,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String title;
// 订单类型,不分
@Field(type = FieldType.Keyword)
private String type;
@Field(type = FieldType.Double)
private BigDecimal money;
@Field(type = FieldType.Date)
private Date creatTime;
}
5. 建立OrderESRepository接口仓库
@Service
public interface OrderESRepository extends ElasticsearchRepository<OrderDoc,Long> {
}
6. 测试类测试:
@SpringBootTest(classes = ESApplication.class)
@RunWith(SpringRunner.class)
public class ESTest {
@Autowired
private ElasticsearchRestTemplate restTemplate;
@Autowired
private OrderESRepository orderESRepository;
@Test
public void testEs() {
// 创建索引
System.out.println(restTemplate.createIndex(OrderDoc.class));
// 创建映射
System.out.println(restTemplate.putMapping(OrderDoc.class));
}
@Test
public void testEs2(){
for (int i = 0; i < 66; i++) {
OrderDoc orderDoc = new OrderDoc();
orderDoc.setId(i);
orderDoc.setCreatTime(new Date());
orderDoc.setMoney(new BigDecimal(i*3));
orderDoc.setTitle("订单"+orderDoc+"ww"+orderDoc.getMoney()+"钱");
orderDoc.setType(i%2==0?"100w":"5w");
orderESRepository.save(orderDoc);
}
}
@Test
public void testQuery(){
// 创建对象的方法:1. new 2. 通过子类创建 3. build 4.工具类
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// 分页 第一页 每页10条
nativeSearchQueryBuilder.withPageable(PageRequest.of(0,10));
// 排序 根据价格来进行排序
nativeSearchQueryBuilder.withSort(new FieldSortBuilder("money").order(SortOrder.DESC));
// 添加查询条件,查询标题中包含 订单 的
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(new MatchQueryBuilder("title","订单"));
// 过滤
boolQueryBuilder
.filter(new TermQueryBuilder("type","100w"))
.filter(new RangeQueryBuilder("money").gte(30).lte(90));
nativeSearchQueryBuilder.withQuery(boolQueryBuilder);
// 通过builder构建查询对象
SearchQuery searchQuery = nativeSearchQueryBuilder.build() ;
Page<OrderDoc> page = orderESRepository.search(searchQuery);
// 获取总条数
long totalElements = page.getTotalElements();
// 获取所有内容
List<OrderDoc> docs = page.getContent();
System.out.println("条数"+totalElements);
docs.forEach(System.out::println);
}
}















 2766
2766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









