







1.1 Hadoop概述
1.1.1 Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统,简称HDFS。HDFS是针对Google File System的开源实现,有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问文件系统中的数据;MapReduce是针对谷歌的MapReduce的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用MapReduce来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
总的来说,Hadoop是一个可用性强、成本低、性能稳定、可扩展性高的提供数据分布式存储及处理开(mian)源(fei)平台。
1.1.2Hadoop发展简史
• Hadoop最初是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。Hadoop源自始于2002年的Apache Nutch项目——一个开源的网络搜索引擎并且也是Lucene项目的一部分
• 在2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身
• 2004年,谷歌公司又发表了另一篇具有深远影响的论文,阐述了MapReduce分布式编程思想
• 2005年,Nutch开源实现了谷歌的MapReduce
• 到了2006年2月,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎
• 2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用
• 2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒
• 在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准
1.1.3Hadoop的特性
高可靠性:采用冗余数据存储方式
高效性:采用分布式存储和分布式处理两大核心
高可扩展性:可扩展集群计算机数量且硬件门槛较低
高容错性:同可靠性
成本低:对集群中的计算机硬件要求较低,成本很低
运行在Linux平台上:稳定,不解释
支持多种编程语言:在平台上的应用程序可以使用其他语言
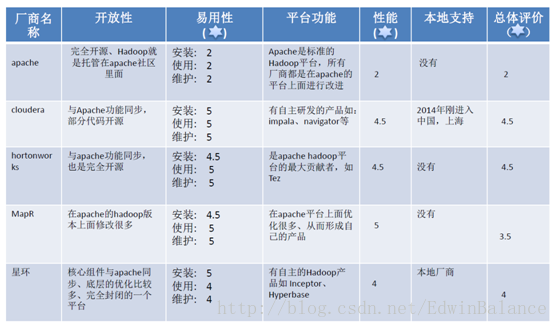
1.1.5Hadoop版本(很混乱 !!!)
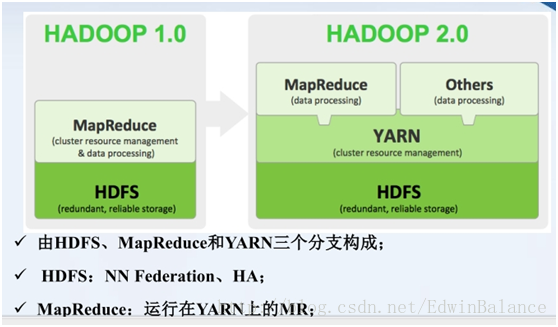
• Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0
• 第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了NameNode HA等新的重大特性
• 第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性
1.2Hadoop生态系统
经过多年的发展,Hadoop生态系统不断能完善和成熟,包含很多子项目。
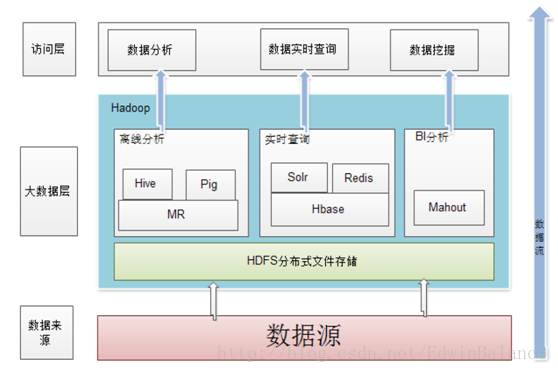
(1)HDFS(Hadoop Distributed Fils System)
HDFS是Hadoop的两大核心之一,具有处理超大数据、流式处理、可以运行在廉价商用服务器上等优点。HDFS设计的初衷就是要以廉价的商用服务器为基础建立大型集群,故而考虑到了硬件存储稳定性较差,所以采用了冗余存储的方式来保证稳定性及可靠性。另外HDFS放宽了一些POSIX约束,从而实现以流的形式访问文件系统中的数据。HDFS在访问应用程序数据时,可以具有很高的吞吐率。
(2)YARN
资源管理和调度器
(3)MapReduce(基于磁盘)
同HDSF,是针对谷歌MapReduce的开源实现。MapReduce是一种编程模型,用于大规模数据集(大于1T)的并行计算,他将复杂的、运行于大规模集群上的并行计算过程高度的抽象到了两个函数上:Map和Reduce。通俗地说,MapReduct的核心思想是“分而治之”,他把输入的数据集切分成若干独立的数据块,分发给一个主节点管理下的各个分节点来共同并行完成,最后,通过整合各个节点的中间结果得到最终结果。
(4)Tez:
把MapReduce的作业处理分析后构成一个又向无环图,相当于一个流程图,大大提高效率。
(5)Spqrk(基于内存)
同做数据处理,由于器在内存中处理数据,故其处理效率比MapReduce高出了一个数量级
(6)Hive
Hadoop平台的数据仓库,支持sql语句,将大量的数据保存在仓库中,建立各种各样的维度,来满足企业的决策性分析。
(7)Pig
轻量级脚本语言,流式处理,简化了MapReduce的开发
(8)Oozie
作业调度系统
(9)Zookeeper
提供分布式协调一致性服务
(10)HBase
Hadoop上的非关系型的分布式数据库 ,具有很好的横向扩展性,可以通过不断增加廉价的商用服务器来增加存储能力。
(11)Sqoop
用于在Hadoop与传统关系型数据库之间进行转换
(12)Storm
流计算框架
(13)Flume
一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 (美团大数据平台使用)
(14)Ambari
Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控
1.3Hadoop的安装
详见http://blog.csdn.net/EdwinBalance/article/details/78640323















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









