






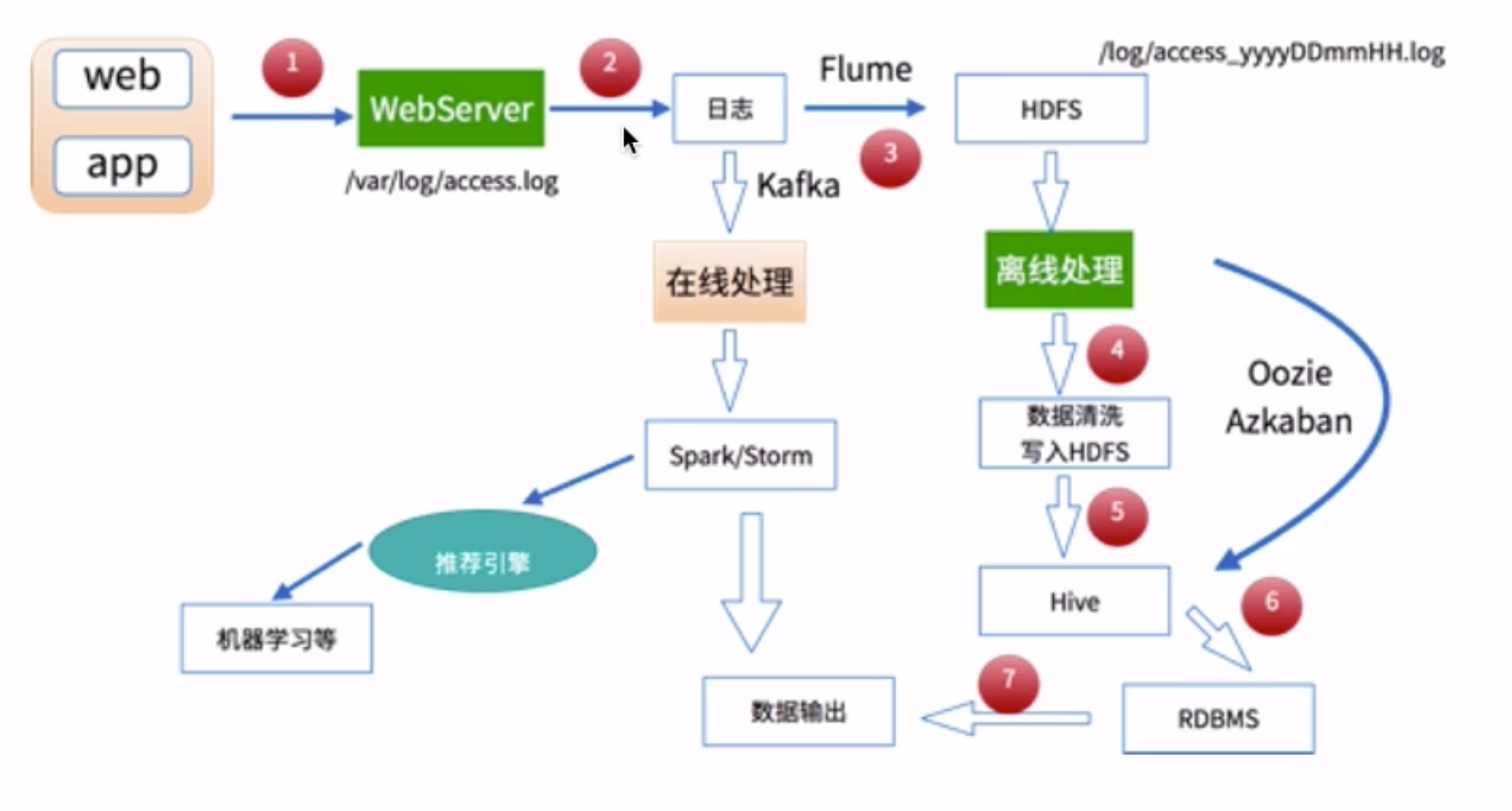
数据处理流程
1)数据采集
Flume: web日志写入到HDFS
2)数据清洗
脏数据
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放在HDFS(Hive/Spark SQL)
3)数据处理
按照我们的需要进行相应业务的统计和分析
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
4)处理结果入库
结果可以存放到RDBMS、NoSQL
5)数据的可视化
通过图形化展示的方式展现出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zeppelin














 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









