







一、概要:
必应搜索主页每天都会更新一张1080P的高清背景图片,非常适合用来做电脑壁纸,而每天手动操作去保存图片稍微有点麻烦,因此想到写个爬虫来下载背景图片。
二、页面分析:
进入必应搜索的主页:https://cn.bing.com/,右键选择“检查”来查看页面代码,发现背景图片的链接在页面head下即可找到,如下图所示:
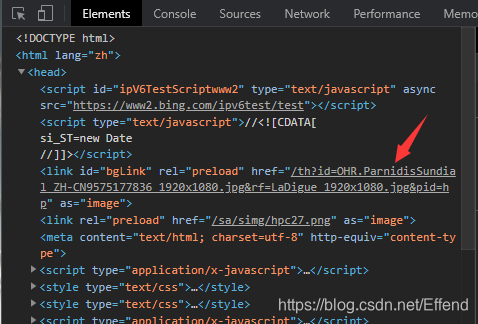
复制出该链接,加上链接头cn.bing.com,即可得到主页背景图片。而且该图片是不含必应水印的图片,相较于直接另存为背景图片更好。由此,目标就是读取网页内容,获得位于head下link标签中的href元素内容,加上链接头,然后下载该图片。
三、代码实现:
在Python下,实现该功能的步骤如下:
(1)使用requests的get方法来获得网页内容;
(2)使用BeautifulSoup来解析页面的html代码;
(3)提取在head下link标签中的href元素;
(4)使用urllib下的urlretrieve方法将图片下载保存在本地。
具体代码实现如下:
# 导入第三方库
import requests
import urllib
from bs4 import BeautifulSoup
import os
# 初始化参数
cnbing="https://cn.bing.com"
# 读取网页数据并获得图片链接
res=requests.get(cnbing)
soup=BeautifulSoup(res.text,'html.parser').select('link')[0]
img_url=soup.get('href')
img_name=img_url.split('.')[1]
img_url=cnbing+img_url
# 将图片保存在本地
path=os.getcwd()+'/'+img_name+'.jpg'
urllib.request.urlretrieve(img_url,path)
其中,使用BeautifulSoup以html.parser方法解析页面数据,并从数据中提取出含有link标签的所有内容,并选择其中的第一个元素。这样做的原因是因为在之前页面分析中可以看到,链接所处的标签位置就是head下的第一个link,因此使用select方法直接提取并得到第一个元素即可。
同时,为了区分每天不同图片,需要给每个图片一个唯一的名称。幸运的是,必应已经提供了唯一的图片链接,且链接内就包含了图片名。只需要直接从href元素内容中提取名称即可。
在代码中,将图片保存在了当前路径下,使用urllib.request.urlretrieve方法,提供图片链接和保存路径来保存内容。
如此一来,便可以使用该代码去爬取背景图片而不用手动操作了。还可以使用定时任务去固定地每天爬一次,这样就不会错过每天更新的背景图了。
–注:本文为原创,未经允许,禁止转载!–














 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









