






LLM有记忆能力吗?有,也没有。
尽管在与ChatGPT对话时,感觉它似乎能记住你之前的发言,但实际上,这些模型在进行推理时并没有真正的记忆能力。
GPT-4o深夜发布!Plus免费可用!![]() https://www.zhihu.com/pin/1773645611381747712
https://www.zhihu.com/pin/1773645611381747712
如何免费使用GPT-4o?如何升级GPT4.0 Turbo?(内附详细步骤教程)
而且,它们在训练过程中的记忆方式也远远没有我们想象的那么简单。
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤
Django创始人解密LLM记忆:无状态却看似有记忆 !
近来,Django框架的联合创始人、西蒙·威利森(Simon Willison)发表了一篇博客,强调了一个核心观点——尽管许多大型语言模型(LLM)看起来有记忆,但实质上它们是无状态函数。

Mozilla和Firefox的联合创始人、JavaScript发明者布兰登·艾奇(Brendan Eich)也在推特上称赞了这篇博客。
从计算机科学的角度出发,LLM的推理过程最好视为无状态函数调用——给定输入文本,它输出接下来应该执行的操作。

然而,那些使用过ChatGPT或Gemini的人会明显觉得,这些模型仿佛能记住以前的对话内容,似乎具备记忆能力。
但这种感知并非源于模型本身。实际上,每当用户提出一个新问题时,模型所接收的提示会包含之前所有的对话内容,这些提示我们称之为「上下文」。
Andrej Karpathy形容上下文窗口为「LLM工作记忆的有限宝贵资源」。
然而,很多方法能为LLM拓展记忆,以满足实际需求。

最简单的方式是将先前对话作为提示,与当前问题一起输入给LLM,但这仍属「短期记忆」,而且扩展上下文长度的成本高昂。
GPT-4免费版支持8k上下文,付费版可达128k,尽管是32k的三倍,仍无法处理单个网页的完整HTML。
推理无记忆,训练有诀窍 !
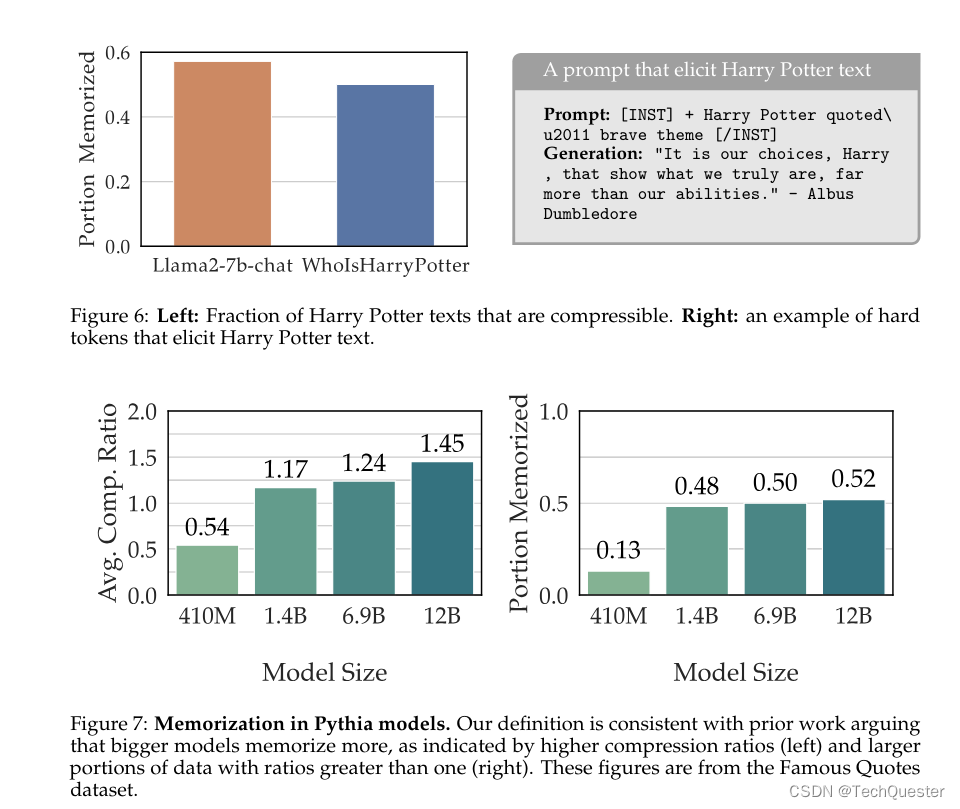
尽管LLM的推理过程相当于「无状态函数」,其训练过程则不同,否则模型无法从语料中汲取任何知识。
关于LLM记忆的分歧在于,它究竟是「机械」地复制了训练数据,还是像人类般通过理解与概括将数据内容融入参数中。
更进一步思考,如果改进LLM的记忆方式,让训练数据以更概括、更抽象的方式存储在参数中,能否带来模型能力的持续提升?
#GPT-5 #GPT #OpenAI #OpenAI GPT #OpenAI GPT
推荐阅读:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









