






通过自学《碱基矿工》
[http://mp.weixin.qq.com/mp/homepage?__biz=MzAxOTUxOTM0Nw==&hid=1&sn=d945cf61bd86e85724e146df42af5bcc&scene=18#wechat_redirect]
下面分别介绍这两种格式
FASTA
FASTA常作为存储有顺序的序列数据的文件后缀,包括我们常用的参考基因组序列、蛋白质序列、编码DNA序列(coding DNA sequence,CDS)、转录本序列等文件。后缀常用.fasta,也有用.fa 或 .fa.gz (gz压缩) 。
FASTA文件主要有两个部分:
-
序列头信息(有时包括一些其他描述信息):头信息独占一行,以(>)开头作为识别标记,除了记录该序列的名字以外,有时还会接上其他信息。
-
具体的序列数据:紧接头信息下一行,直到另外一行碰到另一个(>)开头的新序列或者文件末尾。
( 图为人类名为EGFR基因的部分序列)

FASTQ
这是目前存储测序数据最普遍的一个数据格式,另一种为uBam格式。不同于FASTA的已排列好序列,FASTQ存的是产生自测序仪的原始测序数据,由测序图像数据转换过来。文件后缀通常是.fastq 、.fq或者.fq.gz (gz压缩)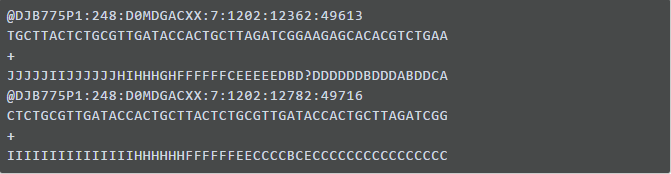
由图可知,它有自己独特的格式:每四行为一个独立单元称作read。具体格式如下:
- 第一行:@开头,是这一条read的名字,它是每一条read唯一标识符
- 第二行:碱基序列,其中,N代表测序时那些无法被识别的碱基
- 第三行:+,现在+之后往往什么都没有
- 第四行:read的质量值,描述碱基的测序准确可靠程度,以ASCII码表示。
这里引出质量值的概念:碱基质量值指用定量描述碱基好坏程度的数值。即用碱基被测错的概率来描述,错误率越低,质量值越高。
之所以使用ASCII码表示,也是为了格式存储和处理时方便,使得第二行的read碱基序列和第四行的每一个ASCII码能够一一对应。不过,值得一提的是,ASCII码虽然能够从小到大表示0-127的整数,但是并非所有的ASCII码都是可见的字符,比如所有小于33的ASCII码值所表示的都是不可见字符,比如空格,换行符等,因此为了能够让碱基的质量值表达出来,必须避开所有这些不可见字符。最简单的做法就是加上一个固定的整数。现在一般都是使用Phred33这个体系,而且33也恰好是ASCII的第一个可见字符(’!’)。
















 2216
2216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









