









林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
一、 Quartz存储与持久化
Quartz提供两种基本作业存储类型。第一种类型叫做RAMJobStore,第二种类型叫做JDBC作业存储。在默认情况下Quartz将任务调度的运行信息保存在内存中,这种方法提供了最佳的性能,因为内存中数据访问最快。不足之处是缺乏数据的持久性,当程序路途停止或系统崩溃时,所有运行的信息都会丢失。
比如我们希望安排一个执行100次的任务,如果执行到50次时系统崩溃了,系统重启时任务的执行计数器将从0开始。在大多数实际的应用中,我们往往并不需要保存任务调度的现场数据,因为很少需要规划一个指定执行次数的任务。对于仅执行一次的任务来说,其执行条件信息本身应该是已经持久化的业务数据(如锁定到期解锁任务,解锁的时间应该是业务数据),当执行完成后,条件信息也会相应改变。当然调度现场信息不仅仅是记录运行次数,还包括调度规则、JobDataMap中的数据等等。
如果确实需要持久化任务调度信息,Quartz允许你通过调整其属性文件,将这些信息保存到数据库中。使用数据库保存任务调度信息后,即使系统崩溃后重新启动,任务的调度信息将得到恢复。如前面所说的例子,执行50次崩溃后重新运行,计数器将从51开始计数。使用了数据库保存信息的任务称为持久化任务。
对比
类型 | 优点 | 缺点 |
RAMJobStore | 不要外部数据库,配置容易,运行速度快 | 因为调度程序信息是存储在被分配给JVM的内存里面,所以,当应用程序停止运行时,所有调度信息将被丢失。另外因为存储到JVM内存里面,所以可以存储多少个Job和Trigger将会受到限制 |
JDBC作业存储 | 支持集群,因为所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务 | 运行速度的快慢取决与连接数据库的快慢 |
二、Quartz存储实例
下面开始说实现的步骤吧:
2.1、建立数据存储表
因为需要把quartz的数据保存到数据库,所以要建立相关的数据库。这个可以从下载到的quartz包里面找到对应的sql脚本,目前可以支持mysql,DB2,oracle等主流的数据库,自己可以根据项目需要选择合适的脚本运行。
我的项目是mysql的,就在数据中建立了一个quartz的database,然后执行tables_mysql_innodb.sql脚本建表。其中脚本 文件位于:E:\JarCom\quartz-2.2.1\docs\dbTables(根据你Quartz放置的目录会不同)
然后打开MySql的终端:
先建立一个数据库,名为quartz;
然后执行脚本:

运行结果:
首先会出现如下错误:


这里有四张数据表创建失败。
解决方法:
将tables_mysql_innodb.sql中的TYENGINEPE=InnoDB全部都替换成ENGINE=InnoDB;
再次执行:
表示数据库表创建成功了
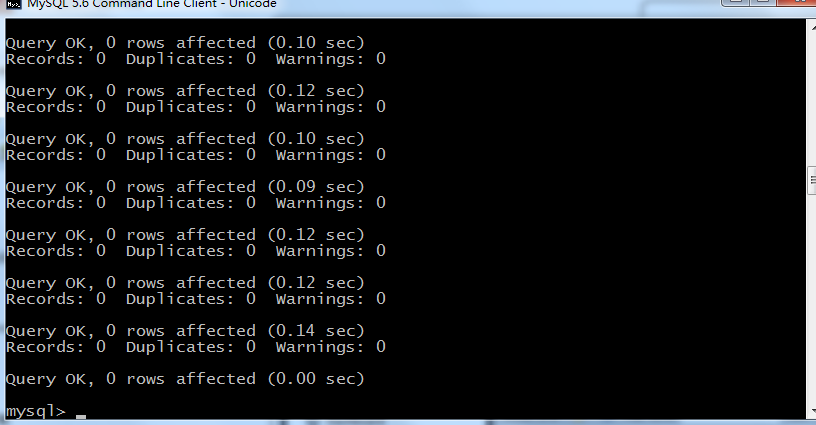
表建立好后可以看到相关的table
+————————–+
| Tables_in_quartz |
+————————–+
| QRTZ_BLOB_TRIGGERS |
| QRTZ_CALENDARS |
| QRTZ_CRON_TRIGGERS |
| QRTZ_FIRED_TRIGGERS |
| QRTZ_JOB_DETAILS |
| QRTZ_LOCKS |
| QRTZ_PAUSED_TRIGGER_GRPS |
| QRTZ_SCHEDULER_STATE |
| QRTZ_SIMPLE_TRIGGERS |
| QRTZ_SIMPROP_TRIGGERS |
| QRTZ_TRIGGERS |
+————————–+
2.2、新建工程并导入包
新建一个java工程,导入相关的jar包
这里我就不多说了,可以到官网上去下载,本文使用的是最新的2,2.1
quartz:http://www.quartz-scheduler.org/
及mySql操作的包,和一个commons-lang包,整个工作最终目录如下:
然后,需要在项目中加上对应的配置。
2.3、首先是quartz.properties的配置
- # Default Properties file for use by StdSchedulerFactory
- # to create a Quartz Scheduler Instance, if a different
- # properties file is not explicitly specified.
- #
- #集群配置
- org.quartz.scheduler.instanceName: DefaultQuartzScheduler
- org.quartz.scheduler.rmi.export: false
- org.quartz.scheduler.rmi.proxy: false
- org.quartz.scheduler.wrapJobExecutionInUserTransaction: false
- org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
- org.quartz.threadPool.threadCount: 10
- org.quartz.threadPool.threadPriority: 5
- org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
- org.quartz.jobStore.misfireThreshold: 60000
- #============================================================================
- # Configure JobStore
- #============================================================================
- #默认配置,数据保存到内存
- #org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore
- #持久化配置
- org.quartz.jobStore.class:org.quartz.impl.jdbcjobstore.JobStoreTX
- org.quartz.jobStore.driverDelegateClass:org.quartz.impl.jdbcjobstore.StdJDBCDelegate
- org.quartz.jobStore.useProperties:true
- #数据库表前缀
- #org.quartz.jobStore.tablePrefix:qrtz_
- #org.quartz.jobStore.dataSource:qzDS
- #============================================================================
- # Configure Datasources
- #============================================================================
- #JDBC驱动
- #org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver
- #org.quartz.dataSource.qzDS.URL:jdbc:mysql://localhost:3306/quartz
- #org.quartz.dataSource.qzDS.user:root
- #org.quartz.dataSource.qzDS.password:christmas258@
- #org.quartz.dataSource.qzDS.maxConnection:10
# Default Properties file for use by StdSchedulerFactory
其中org.quartz.jobStore.class是指明quartz的持久化用数据库来保存,
而org.quartz.jobStore.driverDelegateClass是根据选择的数据库类型不同而不同,我这里的是mysql,所以是org.quartz.impl.jdbcjobstore.StdJDBCDelegate。
Quartz的属性配置文件主要包括三方面的信息:
1)集群信息;
2)调度器线程池;
3)任务调度现场数据的保存。
·调度器属性
第一部分有两行,分别设置调度器的实例名(instanceName) 和实例 ID (instanceId)。属性 org.quartz.scheduler.instanceName 可以是你喜欢的任何字符串。它用来在用到多个调度器区分特定的调度器实例。多个调度器通常用在集群环境中。现在的话,设置如下的一个字符串就行:org.quartz.scheduler.instanceName :DefaultQuartzScheduler实际上,这也是当你没有该属性配置时的默认值。
调度器的第二个属性是 org.quartz.scheduler.instanceId。和 instaneName 属性一样,instanceId 属性也允许任何字符串。这个值必须是在所有调度器实例中是唯一的,尤其是在一个集群当中。假如你想 Quartz 帮你生成这个值的话,可以设置为 AUTO。如果 Quartz 框架是运行在非集群环境中,那么自动产生的值将会是 NON_CLUSTERED。假如是在集群环境下使用 Quartz,这个值将会是主机名加上当前的日期和时间。大多情况下,设置为 AUTO 即可。
·线程池属性
接下来的部分是设置有关线程必要的属性值,这些线程在 Quartz 中是运行在后台担当重任的。threadCount 属性控制了多少个工作者线程被创建用来处理 Job。原则上是,要处理的 Job 越多,那么需要的工作者线程也就越多。threadCount 的数值至少为 1。Quartz 没有限定你设置工作者线程的最大值,但是在多数机器上设置该值超过100的话就会显得相当不实用了,特别是在你的 Job 执行时间较长的情况下。这项没有默认值,所以你必须为这个属性设定一个值。
threadPriority 属性设置工作者线程的优先级。优先级别高的线程比级别低的线程更优先得到执行。threadPriority 属性的最大值是常量 java.lang.Thread.MAX_PRIORITY,等于10。最小值为常量 java.lang.Thread.MIN_PRIORITY,为1。这个属性的正常值是 Thread.NORM_PRIORITY,为5。大多情况下,把它设置为5,这也是没指定该属性的默认值。
最后一个要设置的线程池属性是 org.quartz.threadPool.class。这个值是一个实现了 org.quartz.spi.ThreadPool 接口的类的全限名称。Quartz 自带的线程池实现类是 org.quartz.smpl.SimpleThreadPool,它能够满足大多数用户的需求。这个线程池实现具备简单的行为,并经很好的测试过。它在调度器的生命周期中提供固定大小的线程池。你能根据需求创建自己的线程池实现,如果你想要一个随需可伸缩的线程池时也许需要这么做。这个属性没有默认值,你必须为其指定值。
·作业存储设置
作业存储部分的设置描述了在调度器实例的生命周期中,Job 和 Trigger 信息是如何被存储的。我们还没有谈论到作业存储和它的目的;因为对当前例子是非必的,所以我们留待以后说明。现在的话,你所要了解的就是我们存储调度器信息在内存中而不是在关系型数据库中就行了。
把调度器信息存储在内存中非常的快也易于配置。当调度器进程一旦被终止,所有的 Job 和 Trigger 的状态就丢失了。要使 Job 存储在内存中需通过设置 org.quartz.jobStrore.class 属性为 org.quartz.simpl.RAMJobStore。假如我们不希望在 JVM 退出之后丢失调度器的状态信息的话,我们可以使用关系型数据库来存储这些信息。这需要另一个作业存储(JobStore) 实现,我们在后面将会讨论到。第五章“Cron Trigger 和其他”和第六章“作业存储和持久化”会提到你需要用到的不同类型的作业存储实现。2.4、创建Job类
- package com.mucfc;
- import java.text.SimpleDateFormat;
- import java.util.Date;
- import org.apache.log4j.Logger;
- import org.quartz.Job;
- import org.quartz.JobExecutionContext;
- import org.quartz.JobExecutionException;
- public class MyJob implements Job{
- private static final Logger logger = Logger.getLogger(MyJob.class);
- @Override
- public void execute(JobExecutionContext context)
- throws JobExecutionException {
- System.out.println(”Hello quzrtz ”+
- new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss ”).format(new Date()));
- }
- }
package com.mucfc;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.log4j.Logger;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class MyJob implements Job{
private static final Logger logger = Logger.getLogger(MyJob.class);
@Override
public void execute(JobExecutionContext context)
throws JobExecutionException {
System.out.println("Hello quzrtz "+
new SimpleDateFormat("yyyy-MM-dd HH:mm:ss ").format(new Date()));
}
}
2.5、创建Job的执行类:
- package com.mucfc;
- import java.text.ParseException;
- import java.util.List;
- import org.apache.commons.lang.StringUtils;
- import org.quartz.CronScheduleBuilder;
- import org.quartz.Job;
- import org.quartz.JobBuilder;
- import org.quartz.JobDetail;
- import org.quartz.JobKey;
- import org.quartz.Scheduler;
- import org.quartz.SchedulerException;
- import org.quartz.SchedulerFactory;
- import org.quartz.SimpleScheduleBuilder;
- import org.quartz.SimpleTrigger;
- import org.quartz.Trigger;
- import org.quartz.TriggerBuilder;
- import org.quartz.TriggerKey;
- import org.quartz.impl.StdSchedulerFactory;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.context.ApplicationContext;
- import org.springframework.context.support.ClassPathXmlApplicationContext;
- public class QuartzTest {
- private static SchedulerFactory sf = new StdSchedulerFactory();
- private static String JOB_GROUP_NAME = “ddlib”;
- private static String TRIGGER_GROUP_NAME = “ddlibTrigger”;
- public static void main(String[] args) throws SchedulerException,
- ParseException {
- startSchedule();
- //resumeJob();
- }
- /**
- * 开始一个simpleSchedule()调度
- */
- public static void startSchedule() {
- try {
- // 1、创建一个JobDetail实例,指定Quartz
- JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
- // 任务执行类
- .withIdentity(”job1_1”, “jGroup1”)
- // 任务名,任务组
- .build();
- // 2、创建Trigger
- SimpleScheduleBuilder builder = SimpleScheduleBuilder
- .simpleSchedule()
- // 设置执行次数
- .repeatSecondlyForTotalCount(100);
- Trigger trigger = TriggerBuilder.newTrigger()
- .withIdentity(”trigger1_1”, “tGroup1”).startNow()
- .withSchedule(builder).build();
- // 3、创建Scheduler
- Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
- scheduler.start();
- // 4、调度执行
- scheduler.scheduleJob(jobDetail, trigger);
- try {
- Thread.sleep(60000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- scheduler.shutdown();
- } catch (SchedulerException e) {
- e.printStackTrace();
- }
- }
- /**
- * 从数据库中找到已经存在的job,并重新开户调度
- */
- public static void resumeJob() {
- try {
- SchedulerFactory schedulerFactory = new StdSchedulerFactory();
- Scheduler scheduler = schedulerFactory.getScheduler();
- // ①获取调度器中所有的触发器组
- List<String> triggerGroups = scheduler.getTriggerGroupNames();
- // ②重新恢复在tgroup1组中,名为trigger1_1触发器的运行
- for (int i = 0; i < triggerGroups.size(); i++) {
- List<String> triggers = scheduler.getTriggerGroupNames();
- for (int j = 0; j < triggers.size(); j++) {
- Trigger tg = scheduler.getTrigger(new TriggerKey(triggers
- .get(j), triggerGroups.get(i)));
- // ②-1:根据名称判断
- if (tg instanceof SimpleTrigger
- && tg.getDescription().equals(”tgroup1.trigger1_1”)) {
- // ②-1:恢复运行
- scheduler.resumeJob(new JobKey(triggers.get(j),
- triggerGroups.get(i)));
- }
- }
- }
- scheduler.start();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
package com.mucfc;
import java.text.ParseException;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.quartz.CronScheduleBuilder;
import org.quartz.Job;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.JobKey;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.SimpleTrigger;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.TriggerKey;
import org.quartz.impl.StdSchedulerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class QuartzTest {
private static SchedulerFactory sf = new StdSchedulerFactory();
private static String JOB_GROUP_NAME = "ddlib";
private static String TRIGGER_GROUP_NAME = "ddlibTrigger";
public static void main(String[] args) throws SchedulerException,
ParseException {
startSchedule();
//resumeJob();
}
/**
* 开始一个simpleSchedule()调度
*/
public static void startSchedule() {
try {
// 1、创建一个JobDetail实例,指定Quartz
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
// 任务执行类
.withIdentity("job1_1", "jGroup1")
// 任务名,任务组
.build();
// 2、创建Trigger
SimpleScheduleBuilder builder = SimpleScheduleBuilder
.simpleSchedule()
// 设置执行次数
.repeatSecondlyForTotalCount(100);
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1_1", "tGroup1").startNow()
.withSchedule(builder).build();
// 3、创建Scheduler
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
// 4、调度执行
scheduler.scheduleJob(jobDetail, trigger);
try {
Thread.sleep(60000);
} catch (InterruptedException e) {
e.printStackTrace();
}
scheduler.shutdown();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* 从数据库中找到已经存在的job,并重新开户调度
*/
public static void resumeJob() {
try {
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
// ①获取调度器中所有的触发器组
List<String> triggerGroups = scheduler.getTriggerGroupNames();
// ②重新恢复在tgroup1组中,名为trigger1_1触发器的运行
for (int i = 0; i < triggerGroups.size(); i++) {
List<String> triggers = scheduler.getTriggerGroupNames();
for (int j = 0; j < triggers.size(); j++) {
Trigger tg = scheduler.getTrigger(new TriggerKey(triggers
.get(j), triggerGroups.get(i)));
// ②-1:根据名称判断
if (tg instanceof SimpleTrigger
&& tg.getDescription().equals("tgroup1.trigger1_1")) {
// ②-1:恢复运行
scheduler.resumeJob(new JobKey(triggers.get(j),
triggerGroups.get(i)));
}
}
}
scheduler.start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.6、执行:
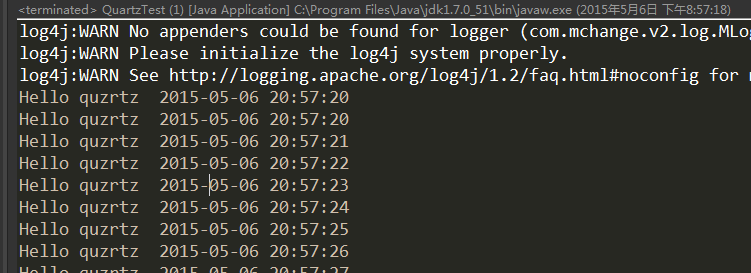
然后打开数据库,输入
- use quartz;
- select* from QRTZ_SIMPLE_TRIGGERS
use quartz;
select* from QRTZ_SIMPLE_TRIGGERS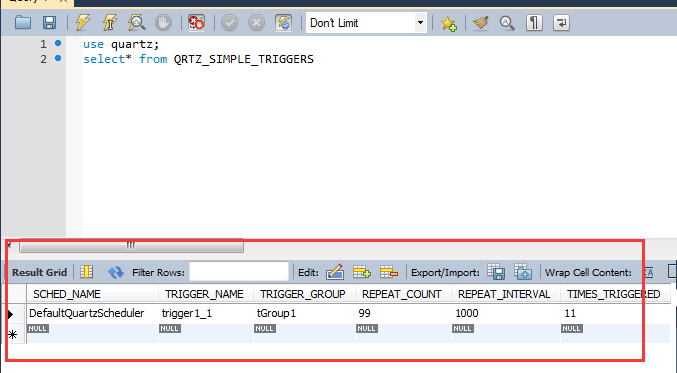
然后把上面的程序停了,点击右上角的红框框

把主代码改成:
- public static void main(String[] args) throws SchedulerException,
- ParseException {
- //startSchedule();
- resumeJob();
- }
public static void main(String[] args) throws SchedulerException,
ParseException {
//startSchedule();
resumeJob();
}输出结果:
同时,查找数据中的表:
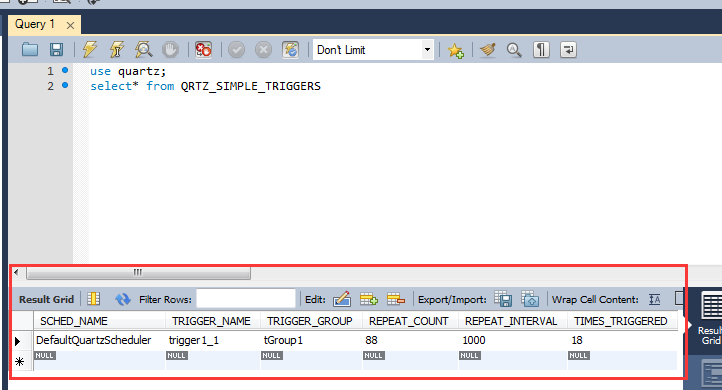
发现有变化 了。。TRIGGER_GROUP表示的执行的次数,TRIGGER_GROUP表示被激发的次数
来回的不断停止程序再重新开始程序,结果如下。
重新停止再打开后,TRIGGER_GROUP变为39,他会减去上一次运行中TRIGGER_GROUP的次数,TRIGGER_GROUP每次运行都会从0开始计算


然后等100次执行完后,这个调度就会从数据表中删除:
结果如下:

这时,该表中的记录已经变空。
值得注意的是,如果你使用JDBC保存任务调度数据时,当你运行代码
- startSchedule();
- //resumeJob();
startSchedule();
//resumeJob();- startSchedule();
- //resumeJob();
startSchedule();
//resumeJob();时,系统将抛出JobDetail重名的异常:Unable to store Job with name: ‘job1_1’ and group: ‘jGroup1’, because one already exists with this identification.因为每次调用Scheduler#scheduleJob()时,Quartz都会将JobDetail和Trigger的信息保存到数据库中,如果数据表中已经同名的JobDetail或Trigger,异常就产生了。
这里再次运行应该这样做:
- //startSchedule();
- resumeJob();
//startSchedule();
resumeJob();三、一些说明
一些相关的意义:
- QRTZ_CALENDARS 以 Blob 类型存储 Quartz 的 Calendar 信息
- QRTZ_CRON_TRIGGERS 存储 Cron Trigger,包括Cron表达式和时区信息
- QRTZ_FIRED_TRIGGERS 存储与已触发的 Trigger 相关的状态信息,以及相联 Job的执行信息QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的 Trigger组的信息
- QRTZ_SCHEDULER_STATE 存储少量的有关 Scheduler 的状态信息,和别的Scheduler实例(假如是用于一个集群中)
- QRTZ_LOCKS 存储程序的悲观锁的信息(假如使用了悲观锁)
- QRTZ_JOB_DETAILS 存储每一个已配置的 Job 的详细信息
- QRTZ_JOB_LISTENERS 存储有关已配置的 JobListener的信息
- QRTZ_SIMPLE_TRIGGERS存储简单的Trigger,包括重复次数,间隔,以及已触的次数
- QRTZ_BLOG_TRIGGERS Trigger 作为 Blob 类型存储(用于 Quartz 用户用JDBC创建他们自己定制的 Trigger 类型,JobStore并不知道如何存储实例的时候)
- QRTZ_TRIGGER_LISTENERS 存储已配置的 TriggerListener的信息
- QRTZ_TRIGGERS 存储已配置的 Trigger 的信息
QRTZ_CALENDARS 以 Blob 类型存储 Quartz 的 Calendar 信息
QRTZ_CRON_TRIGGERS 存储 Cron Trigger,包括Cron表达式和时区信息
QRTZ_FIRED_TRIGGERS 存储与已触发的 Trigger 相关的状态信息,以及相联 Job的执行信息QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的 Trigger组的信息
QRTZ_SCHEDULER_STATE 存储少量的有关 Scheduler 的状态信息,和别的Scheduler实例(假如是用于一个集群中)
QRTZ_LOCKS 存储程序的悲观锁的信息(假如使用了悲观锁)
QRTZ_JOB_DETAILS 存储每一个已配置的 Job 的详细信息
QRTZ_JOB_LISTENERS 存储有关已配置的 JobListener的信息
QRTZ_SIMPLE_TRIGGERS存储简单的Trigger,包括重复次数,间隔,以及已触的次数
QRTZ_BLOG_TRIGGERS Trigger 作为 Blob 类型存储(用于 Quartz 用户用JDBC创建他们自己定制的 Trigger 类型,JobStore并不知道如何存储实例的时候)
QRTZ_TRIGGER_LISTENERS 存储已配置的 TriggerListener的信息
QRTZ_TRIGGERS 存储已配置的 Trigger 的信息 - 表qrtz_job_details:保存job详细信息,该表需要用户根据实际情况初始化
- job_name:集群中job的名字,该名字用户自己可以随意定制,无强行要求
- job_group:集群中job的所属组的名字,该名字用户自己随意定制,无强行要求
- job_class_name:集群中个notejob实现类的完全包名,quartz就是根据这个路径到classpath找到该job类
- is_durable:是否持久化,把该属性设置为1,quartz会把job持久化到数据库中
- job_data:一个blob字段,存放持久化job对象
- 表qrtz_triggers: 保存trigger信息
- trigger_name:trigger的名字,该名字用户自己可以随意定制,无强行要求
- trigger_group:trigger所属组的名字,该名字用户自己随意定制,无强行要求
- job_name:qrtz_job_details表job_name的外键
- job_group:qrtz_job_details表job_group的外键
- trigger_state:当前trigger状态,设置为ACQUIRED,如果设置为WAITING,则job不会触发
- trigger_cron:触发器类型,使用cron表达式
- 表qrtz_cron_triggers:存储cron表达式表
- trigger_name:qrtz_triggers表trigger_name的外键
- trigger_group:qrtz_triggers表trigger_group的外键
- cron_expression:cron表达式
- 表qrtz_scheduler_state:存储集群中note实例信息,quartz会定时读取该表的信息判断集群中每个实例的当前状态
- instance_name:之前配置文件中org.quartz.scheduler.instanceId配置的名字,就会写入该字段,如果设置为AUTO,quartz会根据物理机名和当前时间产生一个名字
- last_checkin_time:上次检查时间
- checkin_interval:检查间隔时间
表qrtz_job_details:保存job详细信息,该表需要用户根据实际情况初始化
job_name:集群中job的名字,该名字用户自己可以随意定制,无强行要求
job_group:集群中job的所属组的名字,该名字用户自己随意定制,无强行要求
job_class_name:集群中个notejob实现类的完全包名,quartz就是根据这个路径到classpath找到该job类
is_durable:是否持久化,把该属性设置为1,quartz会把job持久化到数据库中
job_data:一个blob字段,存放持久化job对象
表qrtz_triggers: 保存trigger信息
trigger_name:trigger的名字,该名字用户自己可以随意定制,无强行要求
trigger_group:trigger所属组的名字,该名字用户自己随意定制,无强行要求
job_name:qrtz_job_details表job_name的外键
job_group:qrtz_job_details表job_group的外键
trigger_state:当前trigger状态,设置为ACQUIRED,如果设置为WAITING,则job不会触发
trigger_cron:触发器类型,使用cron表达式
表qrtz_cron_triggers:存储cron表达式表
trigger_name:qrtz_triggers表trigger_name的外键
trigger_group:qrtz_triggers表trigger_group的外键
cron_expression:cron表达式
表qrtz_scheduler_state:存储集群中note实例信息,quartz会定时读取该表的信息判断集群中每个实例的当前状态
instance_name:之前配置文件中org.quartz.scheduler.instanceId配置的名字,就会写入该字段,如果设置为AUTO,quartz会根据物理机名和当前时间产生一个名字
last_checkin_time:上次检查时间
checkin_interval:检查间隔时间 配置quartz.properties文件:
- #调度标识名 集群中每一个实例都必须使用相同的名称 org.quartz.scheduler.instanceName:scheduler
- #ID设置为自动获取 每一个必须不同 org.quartz.scheduler.instanceId :AUTO
- #数据保存方式为持久化 org.quartz.jobStore.class :org.quartz.impl.jdbcjobstore.JobStoreTX
- #数据库平台 org.quartz.jobStore.driverDelegateClass:org.quartz.impl.jdbcjobstore.oracle.weblogic.WebLogicOracleDelegate#数据库别名 随便取org.quartz.jobStore.dataSource : myXADS
- #表的前缀 org.quartz.jobStore.tablePrefix : QRTZ_
- #设置为TRUE不会出现序列化非字符串类到 BLOB 时产生的类版本问题org.quartz.jobStore.useProperties : true
- #加入集群 org.quartz.jobStore.isClustered : true
- #调度实例失效的检查时间间隔 org.quartz.jobStore.clusterCheckinInterval:20000
- #容许的最大作业延长时间 org.quartz.jobStore.misfireThreshold :60000
- #ThreadPool 实现的类名 org.quartz.threadPool.class:org.quartz.simpl.SimpleThreadPool
- #线程数量 org.quartz.threadPool.threadCount : 10
- #线程优先级 org.quartz.threadPool.threadPriority : 5
- #自创建父线程org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
- #设置数据源org.quartz.dataSource.myXADS.jndiURL: CT
- #jbdi类名 org.quartz.dataSource.myXADS.java.naming.factory.initial :weblogic.jndi.WLInitialContextFactory#URLorg.quartz.dataSource.myXADS.java.naming.provider.url:=t3://localhost:7001
- 【注】:在J2EE工程中如果想用数据库管理Quartz的相关信息,就一定要配置数据源,这是Quartz的要求。
#调度标识名 集群中每一个实例都必须使用相同的名称 org.quartz.scheduler.instanceName:scheduler
林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
本文工程免费下载














 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









