







1.基本概念
欠拟合:由于样本数据过少过着其他因素,拟合模型在数据预报时会造成偏差。如图中的左和中为求出的回归方程,然而在x的取值和真实差别很大,这个情况叫做欠拟合。
过拟合:简单理解就是训练样本的得到的输出和期望输出基本一致,但是测试样本输出和测试样本的期望输出相差却很大 。
一般情况下:
对于特征集过小的情况,称之为欠拟合(underfitting)
对于特征集过大的情况,称之为过拟合(overfitting)

2.局部加权思路
局部加权回归是指我们在预测一个X所对应的Y值的时候,只采用在X周围的数据进行数据拟合,它不同于我们通常所讲的线性回归拟合。在线性回归拟合中我们尽可能的去减小cost function使得其接近为0,但是我们的样本得到的数据函数图象就可能为上图的左、中,这种情况叫做欠拟合。
即使对于最右边的函数图像中拟合的非常精确,但并不一定能得到正想像某种学习算法产生了一个过拟合的分类器,这个分类器能够百分之百的正确分类样本数据(即再拿样本中的文档来给它,它绝对不会分错),但也就为了能够对样本完全正确的分类,使得它的构造如此精细复杂,规则如此严格,以至于任何与样本数据稍有不同的文档它全都认为不属于这个类别!
当目标假设是线性模型时,使用线性回归自然能拟合的很好,但如果目标假设不是线性模型,比如一个忽上忽下的函数,这时用线性模型就拟合的很差。为了解决这个问题,当我们在预测一个点的值时,我们选择和这个点相近的点而不是全部的点做线性回归。基于这个思想,就有了局部加权回归算法,它的目标函数是加权的最小二乘:
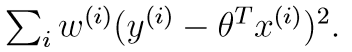
其中,w(i)是权值,它的作用在于根据要预测的点与数据集中的点的距离来
为数据集中的点赋权值一个较好的函数如下:
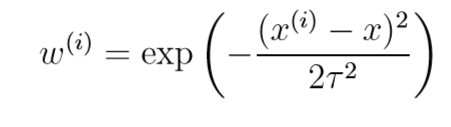
该函数被称为指数衰减函数。其中,��被称为波长参数,它控制了权值随距
离下降的速率。该函数比较像但不是高斯分布(Gaussian Distribution)或正态分
布(Normal Distribution)。
加权规则如下:
a.当某点距离待预测点较远时,其权重较小;
b.当某点距离待预测点较远时,其权重较大。
3.缺点
这个算法的问题在于,对于每一个要查询的点,都要重新依据整个数据集计算一个线性回归模型出来,这样做使得计算代价极高。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









