






【阅读笔记与大致翻译】RadioDiff: An Effective Generative Diffusion Model for Sampling-Free Dynamic Radio Map Construction

摘要
无线电地图(RM, radio map)能仅凭借位置获取路径衰落值,对于减少6G应用中估计路径衰落所需的通信开销有着重要作用。然而,传统的RM构建方法要么是依赖于密集地计算要么依赖于高成本的测量。尽管基于神经网络(NN)的方法能够无测量有效构建RM,其性能还是不够好。这主要是RM构建问题的生成特征(generative characteristics)与现有NN模型使用的识别模型(discrimination modeling)间无法对齐(misalignment)造成的。因此,为提升RM构建性能,本文中将无采样RM构建任务建模成条件生成任务,基于denoised diffusion模型,提出名为RadioDiff的模型实现高质量RM构建。此外,为提升diffusion模型从动态环境中的特征提取能力,使用注意力U-Net和一个适应性FFT模块作为骨干网络。同时,解耦的diffusion模型被用于进一步提升RM的构建性能。此外,从数据特征和NN训练模型的角度,关于“为什么RM构建是一个生成任务”的完整的理论分析被首次提出。实验结果显示所提RadioDiff在准确性、结构相似性(?)、SNR峰值指标下都达到了当前性能水平。代码可从此处获取:添加链接描述
I 引言
在无线网络中,路径衰落量化了一对收发端之间由于自由空间传播损失和无线电波与障碍物之间的交互造成的信号强度的衰落,对于无线资源分配而言非常重要。然而,网络节点与天线的戏剧性增加导致了高维度信号的估计挑战,造成了训练和反馈的高通信开销,以及信号处理的复杂度。这个问题在短信道相关时间的低时延应用高移动性场景中加剧了。同时,即将到来的6G网络将会引入大量的节点类型,包括不能动态传输pilot信号活参与数字信号处理的被动设备比如智能反射面。
这些新场景的出现使得通过易于获取的信息以高效地得到路径衰落而非通过pilot信号传输和信号处理变得很有必要。因此,RM技术得以发展,只需位置即可获取pathloss。传统的RM构建方法能够分成两类:(1)依赖于位置测量采样的方法,然后使用插值或者解特定的最小二乘问题来构建RM(SRM);(2)不采样,使用3D环境建模和电磁射线追踪(ERT)。然而这两种方法都有着他们的固有缺陷。基于采样点方法如果测量过于少或者不准确将会导致构建质量差,大量高精度测量则成本太高。而且此方法不能用于未曾到达过的区域,适用性首先,比如UAV轨迹规划。而环境建模射线追踪方法虽然避免了测量成本,缺负担着高计算复杂度且耗时难以接受。此外,出于其原理,这两种方法都只能用于构建静态RM,没有考虑影响pathloss的因素的实时变化。因此,由因素导致的pathloss的变化(比如汽车运动或者反射直径变化)都不会反映在RM中。而采样方法需要的样本点数使同时采样所有点不可能。此外,不同采样点的时间序列测量也使得实时测量不可能。类似的,本质上基于静态场景的射线追踪的ERT方法通常涉及几分钟的计算,导致其不适合于动态环境特征的RM构建。
为解决这些挑战,大量的研究者将有着快速推理能力的NN用于RM构建。最值得注意的先锋工作是将U-Net用于RM构建的的RadioUNet(U-Net是一个用于图到图任务的经典架构)。尽管有些基于NN的方法展现出了比SPM更好的性能,但尤其是在有着动态障碍物的动态RM细节构建中性能还是很差。因此,大部分基于NN的方法聚焦于静态环境中的RM构建,这主要导致了两个问题:电磁波的多样传输特征以及RM本质特征的复杂性。静态RM构建只关注建筑物和电磁波射线传播(因为所有物体以相同方式影响电磁射线)。而在动态RM构建中,移动物体对于电磁射线的影响必须纳入考虑。与有着大体型和高高度、能够在其表面完全挡住电磁波的静态障碍物不同,动态障碍物高度矮,体积小,不会完全阻碍电磁信号,使得DRM构建和特征比SRM更复杂。此外,现存NN方法有监督训练NN,目标是最小化ground truth和预测RM间的MSE,虽然使用有监督MSE训练能够提升收敛速度,但使NN缺少捕捉数据微妙特征的能力,导致边缘模糊。如图1所示,DRM通常有着丰富纹理特征。
上述挑战的根本原因在于RM构建的生成式问题属性(generative problem attributes)与判别式(discriminant)方法之间的不匹配。RM构建在数据特征和神经网络(NN)训练方法上都表现出生成式问题的特征,而现有的无样本NN方法却采用判别式方法来构建RM,这不可避免地限制了RM的构建性能。具体而言:①在数据特征方面,待预测路径损耗的数值和位置均不存在于输入的环境数据中,因此NN需要从原始数据中生成路径损耗。②由于RM中的元素不是离散值,因此几乎不可能通过划分有限数量的超平面来将环境数据中的元素分类为判别式问题。因此,采用判别式训练方法,通过NN在潜在空间中生成多个超平面来预测路径损耗,将不可避免地导致较差的性能表现。③利用部分掩蔽的数据作为输入来训练NN以预测被掩蔽信息的自监督训练方法,主要用于生成式模型的训练。在RM构建的背景下,表示环境信息的数据可以被视为路径损耗被掩蔽的RM,而基于NN的RM构建方法正是利用这些被掩蔽的RM数据来恢复路径损耗,这正是一种自监督训练方法。综上,RM构建是一个生成问题,需要用生成方法实现,提升NN提取RM纹理特征的能力。
GAN广泛被研究用于RM重建,然而其潜能常常受训练中的极端不稳定的阻碍。地理地图和RM包含丰富的高频尖锐边缘。直接将其输入NN模型会导致不稳定的预测和噪声。但diffusion模型展现出超强的边缘信息捕捉和状况预测能力。为利用生成式NN训练方法的优势实现高性能RM重建,本文中,RM构建问题被建模为条件生成问题,并用生成式diffusion方法来生成。
本文的主要贡献如下:
1)无采样RM构建问题首次被建模为条件生成问题,BS位置和环境特征作为prompt用于条件生成。
2)基于diffusion的生成模型首次被用于RM构建。
3)为提升diffusion模型的动态环境特征提取能力,动静态环境特征有两个矩阵分别表征。adaptive FFT被用于提升diffusion模型的能力来提取由动态环境特征导致的数据中的高频信息。
4)实验结果显示所提RadioDiff在准确性、结构相似性(?)、SNR峰值指标下都达到了当前性能水平。
文章接下来的内容如下组织:首先在II中介绍RM构建相关工作并对diffusion模型进行初步探讨(3页)。然后RM构建问题在III中构建和分析(2页)。第IV部分介绍了所提RadioDiff的细节(5页),第V部分展示实验结果(10页),第VI部分总结全文。
(注:由于本文太长所以后续不再逐字翻译,只翻译大意)
II 前提与相关工作
A.RM构建
RM构建可以被分为基于采样/无采样的两大类。
采样方法通常不需要知道环境细节和BS位置,其中,KNN技术[14]通过加权平均K个最近的pathloss值。此外局部多项式回归[15]也很常用:通过求解含附近pathloss值的最小二乘问题。为提升基于采样的RM构建质量和准确率,引入了kriging插值[16]:把RM构建问题视作随机过程模型以及基于协方差方程预测问题。上述采样方法面临两大挑战:对采样的依赖和低构建精度。
无采样方法需要环境信息辅助(BS、障碍物位置)。代表性方法就是RadioUNet[18],基于经典图-图架构U-Net,使用MSE为loss。基于transformer的Radionet[19]。更复杂的NN,比如有着强特征提取能力的GNN[20]也被用于RM构建。然而这些方法通常将无采样RM构建问题视为识别监督学习任务。
RM-GAN[21]将生成方法引入RM构建,但不是无采样的。
B.Diffusion模型
Diffusion模型是一种基于马尔科夫链的生成模型,利用学习后的降噪过程逐步恢复数据。在多种生成任务(如计算机视觉,自然语言处理)与GAN是强劲的对手。此外,diffusion模型在知觉任务(图像划分,米不爱识别,强化学习)中潜力很强。
diffusion模型中有两个阶段:将原始数据扩散成噪声的前向扩散阶段;以及用NN去除噪声的去噪阶段,从而达到从噪声中生成原始数据的效果。
1)前向扩散阶段:
从概率模型的角度来看,生成模型的本质在于训练它们以生成反映训练数据x∼pt(x)分布的数据x^~pθ(ˆx)。Denoising diffusion probability model(DDPM)使用两条马尔科夫链:一个前向链将数据转化为噪声,一个反向链将噪声转回数据。给定原始数据x0,通过生成一系列随机变量x1,x2…xt来实现前向马尔可夫链的级数,它随着**转换核q(xT|xT-1)**而演化。通过结合概率链规则和马尔可夫性质,可以解构x1,x2,…xt的联合概率分布,给定x0,表示为q(x1,…,xT|x0),转化为适当的阶乘形式。【每一步的转移q(xt|xt-1)仅取决于前一时刻的状态xt-1,并且整个过程可以被视为一个逐步添加噪声的马尔可夫链】
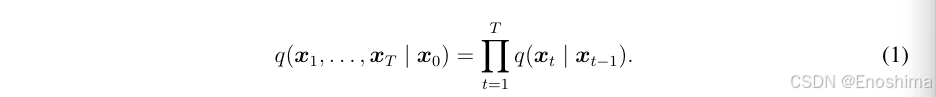
其中,每一步由xt-1生成xt通过加入高斯噪声生成:

因为噪声e~N(0,1),因此可得q(xt|xt-1):
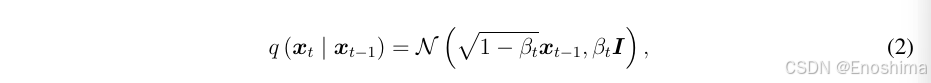
通过连乘可以得到xt和x0转换式:
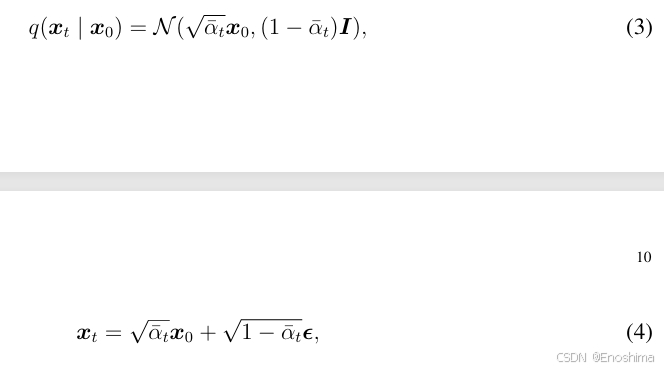
式4中可以看到,生成的噪声xt中,前半部分是原始数据的贡献,后半是噪声的贡献。随t增加,噪声影响逐渐强。
2)反向去噪过程
DDPM最初从先验分布中创建非结构化噪声向量,随后通过以逆时间顺序操作的可学习马尔可夫链去除噪声。
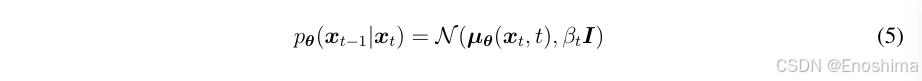
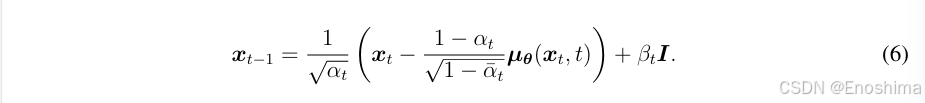
值得注意的是,(6)中的第二项的目的是获得通过去噪获得的xt-1的相同分布,特别是在方差方面,与通过正向扩散得到的分布相同。去掉第二项得到的xt-1恰好等于通过正向扩散得到的均值。
III RM构建问题建
我们将需要构建RM的场景划分成NxN个网格,网格足够小使网格内pathloss为常数,从而RM可以被表示为矩阵P。BS位置用元组R<h,dx,dy>表示。静态障碍物的信息用NxN矩阵Hs表示,其中元素hij=0表示hij不在建筑物内部。动态障碍物的信息用NxN矩阵Hd表示,其中元素hij=0表示车辆不再hij位置处。
本文的目标是训练参数为theta的NN,利用环境特征和BS位置生成预测pathloss矩阵P^,并使与ground truth差距最小。综上构建问题1:
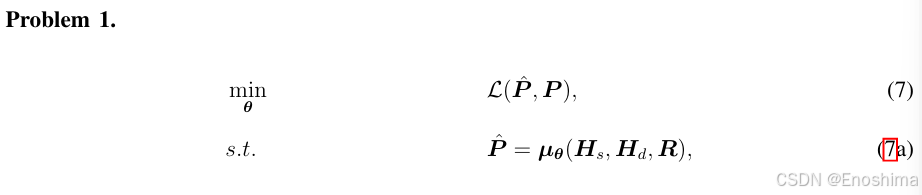
…在RM构建中,环境信息<Hs,Hd>可以被视为pathloss元素被遮蔽的P,NN需要基于<Hs,Hd>预测pathloss。这是一种自监督学习的方式。此外,BS位置R影响pathloss分布,可以被视为自监督学习中的条件。
IV 基于Diffusion的RM构建
因为RM构建是一个生成问题,因而使用当前生成式diffusion模型作为骨干构建RM
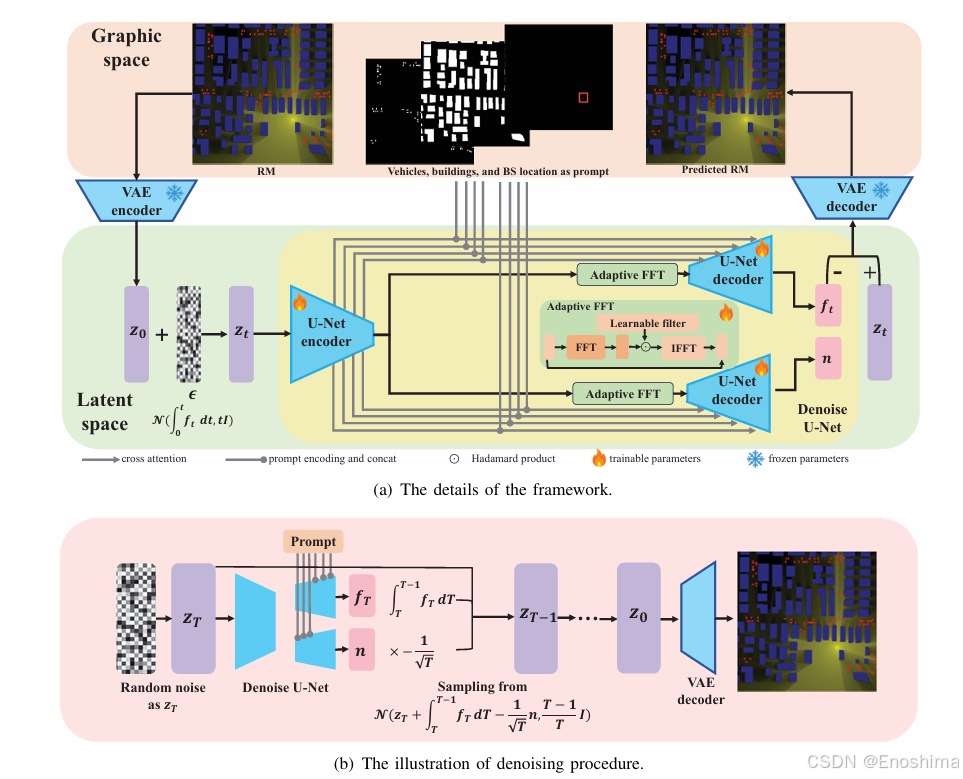
A.初步处理
为了提升收敛速度,pathloss矩阵P通过一系列处理(包括对数标准化(logarithmic scaling),归一化和量化)被编码为灰度矩阵。R也用灰度矩阵表示,只有在相应位置上值为1,其他地方均0.。环境信息从而可被编码为三通道的张量C=[Hs,Hd,R]。
为进一步提升denoise diffusion的训练效率,训练一个VAE用于将原始数据编码到latent space中。VAE的编码器将P编码为z0后按式(3)加入噪声。NN去除噪声后,VAE的解码器从diffusion的预测向量zo^中恢复RM。通过使用VAE,diffusion只需要去除添加到z上的噪声向量而不是直接加到P上的,因而减少输出空间维度以提升效率。值得一提的是,VAE的训练和diffusion相独立:VAE编码器只用P训练,解码器则用自动编码器方式训练。
B.通过解耦Diffusion模型得到RadioDiff
DDM中,从zo扩散到zt被建模为一个两步的连续马尔科夫过程:首先将zo扩散为一个0向量,然后加入噪声来形成zt。zt的分布为如下所示的正态分布:
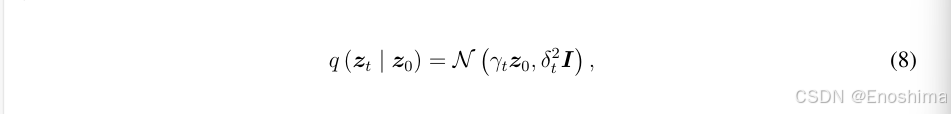
其中γ和δ都是超参数,δ被设定为随时间逐渐增长而γ相反减小。与传统Diffusion模型中直接将噪声加入到zo不同,RadioDiff采用的DDM将此分为两个阶段:①zo首先扩散成0向量,以有效从加入的噪声中解耦出原始输入的贡献。这使得扩散过程更加可控,因为噪声e只在zo被降低成0后被引入。因此DDM减少了早起扩散步骤的多样性以提升训练和推理的稳定性。此外,此解耦架构缓解了传统diffusion的推理时间,使生成更有效率。②施加解耦扩散步骤:
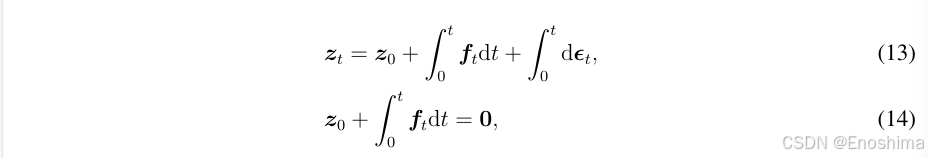
条件分布如下所示:
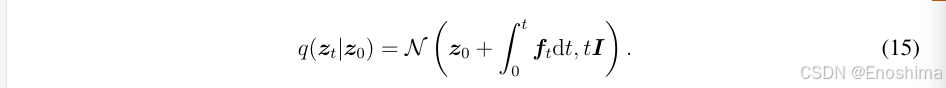
通过使用条件概率公式,可以获得zt-△t:
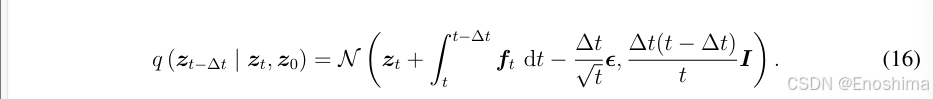
根据式(16),将带噪zt转换为z0,与本文中的特征地图P对应。如图3 所示,两个U-Net分别负责预测ft积分和e,而e是人工添加的因而label直接可获得。然而ft的label必须通过解(14)获取。在训练过程中ground truth通过解下式获取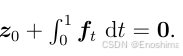
以上都是无约束Diffusion,为使NN基于prompt C生成RM,应用基于注意力的架构实施条件生成模型,使NN输出与注意力K、V值相关联。由于注意力机制无法直接处理二维数据,用到一个提取器NN网络将C映射到嵌入空间,然后通过交叉注意力层将该嵌入映射到U-Net的中间层。loss函数如下所示:
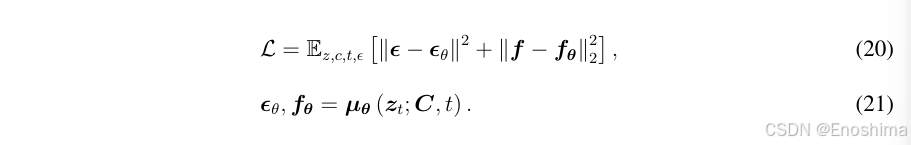
C.Adaptive FFT滤波器用于动态RM提升
RM展现出大量的边缘纹理特征,尤其是动态RM,在频域中产生大量高频信息。尽管U-Net中的传统卷积层能够有效提取特征,但他们很难精准捕捉高频分量,只能输出平滑RM,导致模糊的表达和次优的性能。因此引入Adaptive FFT filter(AFT)以提升模型提取高频特征的能力。
AFT模块转换由encoder用HxW的空间信息和信道数C生成的2D特征图z,利用FFT从空间域到频率域。
为提升模型聚焦于相关频率分量的能力,将一个可学习的权重矩阵w融入AFT。该矩阵通过哈达玛积作用于频域特征zc,调整模型对于不同频率分布的相应(强化重要分量(高频)衰减不相关的)
随后修整过的频域特征会通过IFFT被改回空间域。
为保留关键信息并减少滤波过程中的可能丢失,引入输入出特征图间的残差连接。
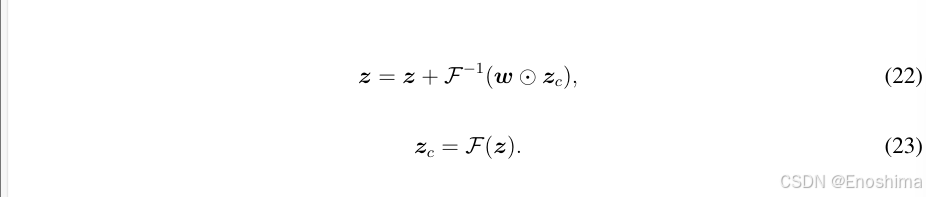
V.实验
A.数据集
使用RadioMapSeer数据集[37],含有700张地图,每个都有独特的地理信息(比如建筑数据,50-150个建筑),每张地图内有80个发射端位置以及对应的真实数据。使用500张地图训练,保留200张用于测试。
城市地图来源于OpenStreetMap,收发端高度均设为1.5m,建筑高度25m。每张地图都被转换为一个256x256的二值图,每个像素点代表1平方米:1表示此地在建筑物内,0表示外。发射端位置也存在类似的二值图中。发射端功率设为23dBm,载波频率为5.9GHz。为获取足够准确的RM作为ground truth,数据集中的RM由麦克斯韦方程组计算得出,pathloss由电磁射线的反射和衍射计算。动静态RM都有。
B.指标
除了前人常用的NMSE和RMSE外,对于RM构建而言细节和结构化信息时很重要的目标,而MSE主要反映的是整体误差,因此提出引入结构性相似序列测量(SSIM)和峰值SNR(PSNR):SSIM评估结构信息的保留以强调结构细节重建的准确性;PSNR评估RM构建的保真性,尤其是边缘信号。
1) MSE
计算ground truth和预测RM每个像素点强度的平均差平方。NMSE就是对其归一化,RMSE就是对其开方。
2) SSIM
受人眼视觉系统启发的评估指标。SSIM聚焦于测量纹理差异,而RM中有大量的高频信息。我们认为信号辐射的亮度应该更加被重视,信号辐射和周边区域的差别,而这与SSIM指标一致:亮度,对比和结构信息:
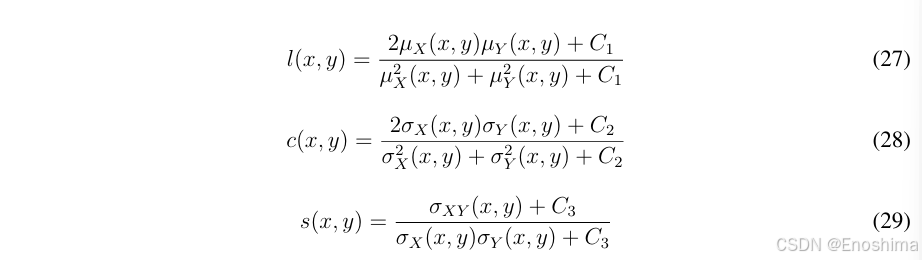
将他们全部连乘起来得到SSIM:
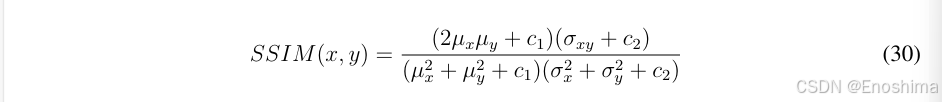
3) PSNR
PSNR定义为信号的最大可能能量和干扰噪声之比,单位为dB,给出了重建质量的大致测量。在图像评估中,PSNR越高通常说明图像质量越好【更清晰,结构边缘更锐利】。而对于RM而言,准确的边缘信息很重要,因此PSNR不仅需要评估整体图像质量,还需要确定边缘细节的质量。
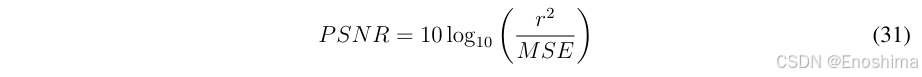
C.实施
基于PyTorch架构实施RadioDiff。训练过程被分为两个阶段,都用AdamW优化器,学习率逐渐下降(510-5–>510-6)。
①首先,VAE autoencoder用来自整个数据集的训练集当做ground truth进行训练,z-channel设为3,embedding维度为128,batch size为2的情况下训练了120h。
②然后训练DDM+U-Net,batch size为64的情况下训练了360h。
虽然更大的batch size能达到更好的训练结果和效率,但①中的输入和输出都是图片,消耗大量的存储;而②中输入的是VAE处理过的latent space数据,不需要那么多存储,所以②能用更大的batch size。这强调了用VAE对数据进行处不处理的重要性。
输入图片尺寸为256x256,扩散500步(训练中是1000),loss函数基于l2目标是预测KC【?】.初始分布为正态分布。
D.与现有方法的比较
与当前用于RM构建任务的深度学习代表性主要架构CNN[18]\GAN[21]\Mamba[38]方法分别单独比较
- RadioUNet:使用卷积U-Net作为骨干,用监督学习方法训练,架构简单有效地学习环境特征。
- UVM-Net:训练方法和设置与RadioNet相同,但是骨干换成SSMs(State Space Sequenc models)。SSM是专门为处理长序列数据而设计的,特别适合对长距离依赖关系进行建模:通过状态空间模型将输入序列映射到隐藏状态并基于该隐藏状态预测输出。我们选用此网络来评估SSM架构与传统卷积网络在无线传播图重建任务重的性能差异。
- RME-GAN:不仅用到环境信息还采样。公平起见,在本文的比较中只使用环境信息做生成
1) 静态RM构建比较:
RadioMapSeer测试集上的定量比较结果见表2,由表可知本文所提模型的误差和结构性指标都比其他模型号,说明本模型的预测和生成RM更加准确。这源于扩散模型对边缘信息高频信号的高度敏感性,而AFT有效地增强和隔离了这些信号。相反的,CNN和mamba对于边缘信息响应较弱。而GAN因为依赖采样,在无采样情况下结果不那么准确。
2) 动态RM构建比较:
尽管相比SRM构建性能有所下降,但RadioDiff还是比所有其他模型表现要好。说明本模型更稳定。
E.消融实验(AFT)
可以看到有AFT时模型对于边缘信号的感知更准确。在数值结果上整体误差更低,结构性也更强。
F.限制与讨论
效率问题。在耗时和存储占用上本模型都比较大。但耗时在1s内,对于动态RM生成而言还是可以接受的。
虽然本文中VAE需要单独训练,但这是因为Latent Diffsion Model首次用于RM重建,在后续的研究中不需要再重新训练。此外,NN压缩技术和效率推理方法比如DDimplicit model能被用于提升效率。
此外,本文和此前的工作多是针对“一个基站到多个接收端”的场景。未来需要“多个基站到多个接收端”,需要任何两点之间的pathloss【指BS多个且位置不固定,位置固定就好说】。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









