







数据科学案例分析
1. 聚类分析
1.1 K-means
注意处理异常值
不同维度或者变量之间,如果存在数值规模或量纲的差异,则需要先进行归一化或者标准化
1.2 DBSCAN——基于密度的带有噪声的空间聚类
优点:
- 原始数据集的分布规律没有明显要求,对于非凸状、圆环状等异形簇分布的识别较好
- 无需制定聚类数量
- 能够有效应对数据噪点
缺点:
- 对于高维度问题,基于半径和密度的定义是个问题
- 当簇的密度变换太大,聚类效果不好
- 数据量增大时,I/O消耗加大
1.3 MiniBatchKMeans——对于大数据的聚类算法
从不同类别的样本中抽取一部分样本作为代表参与聚类算法
1.4 聚类——重要的中间预处理过程
-
图形压缩
使用较少的数据量来表示原有的像素矩阵的过程,也称图形编码。数字图像的显著特点就是数据量庞大,所以我们需要压缩再进行下一步。
使用聚类算法做图形压缩时,会先定义K个颜色数,颜色数就是聚类类别的数量,K-Means算法会把类似的颜色分在K个簇中,然后每一个簇使用一种颜色来代替原始颜色,那么结果有多少个簇,就生成由多少种颜色构成的图像,由此实现图像压缩 -
图像分割
聚类算法是图像分割方法的一种,其实施的关键是通过不同区域间明显不同的图像色彩特征做聚类,聚类数量就是要分割的区域的数量
1.5 降维、子空间聚类——应对高维数据的聚类
1.6 如何选择聚类方法
- 高维数据,选择谱聚类,子空间聚类的一种
- 数据规模较小(100万条以内)选择K均值算法,超过可以考虑MiniBatchKMeans
- 数据集中存在噪点(离群点),使用基于密度的DBSCAN
- 追求更高的分类准确度,选择谱聚类比K均值准确度会更好
1.7 聚类“准确性”的评估指标
非监督式指标评估
- silhouette_s:轮廓系数,使用平均群内距离和每个样本的平均最近簇距离来计算,最大值为1,最差值为-1, 0附近的值表示重叠的聚类,负值表示样本被分配到错误的集群 >0.5表示聚类效果不错
- calinski_harabaz_s:该参数定义为群内离散与簇间离散的比值
监督式指标评估
为了验证K-Means或其他聚类模型的聚类效果与真实分类的差异,可以选择带有已经标识的label标签的数据集进行训练,通过sklearn.metrics中的一些监督指标做聚类结果评估
- adjusted_rand_score:调整后的兰德指数。取值范围为【-1, 1】,越接近1越好,越接近-1越不好
- mutual_info_score:互信息(MI)互信息是一个随机变量中包含的关于另一个随机变量的信息量,这里指相同数据的两个标签之间的相似度的度量,结果非负
- homogeneity_score:同质化得分,取值范围【0, 1】值越大意味着聚类结果与真实情况越吻合
- completeness_score:完整性得分,同上
- v_measure_score: 同质化和完整性之间的谐波平均值
1.8 案例分析:客户特征的聚类与探索性分析
题目背景:一些关于客户的数据,希望数据部门通过对数据的分析,给业务部门一些启示,或者提供后续分析或业务思考的建议
基于上述场景和需求,我们需要交付:
- 一次探索性数据分析的任务,没有任何先验经验提供
- 分析结果应用于业务的知识启发或后续分析的深入应用
- 多维度数据可视化分析
案例分析思路:
- 观察数据集
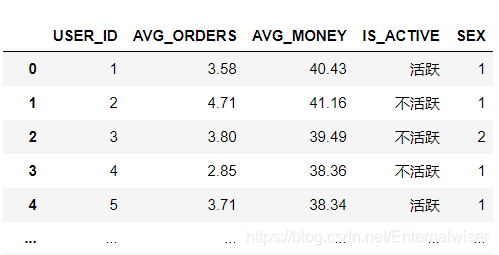
注意到:
- IS_ACTIVE是字符串类型变量
- SEX是分类变量
- 数值变量ORDERS,MONEY的量纲差异
- 分割ID我们不需要ID列进行计算
- 解决思路
我们可以有以下思路对数据进行处理
对于字符串型变量的处理方法有两种:
一、首先进行转换,然后进行OneHotEncoder,这样做相似度计算时可以充分考虑分类特征的不可直接计算性,但是独热编码后的数据会给业务理解和应用带来困难
二、 直接将分类型特征,当作原本的字符串做计算,对于字符串的计算,无法直接通过就相似度的方式,而是计算其聚类类别内的分类特征值的出现频数和频率
三、 对于数值型数据的量纲不一致我们使用模型MinMaxScaler()进行标准化
四、 根据分类的标签对性别和活跃度进行归纳分析
2. 将模型对象保存到硬盘
有些时候,我们需要将算法对象保存到硬盘中,也称对象持久化
优点:
- 将训练好的模型对象保存,方便预测和后期应用时直接调用,避免了重新训练模型并应用的时间延迟问题
- 将训练和应用过程拆分,避免紧耦合带来的系统问题
- 避免内存错误导致训练好的模型对象丢失,即使训练过程中出错,也可以调用最近的一次模型实例
- 方便不同环境的模型对象迁移,这样测试和生产环境可以隔离训练和应用过程
pickle
这里的模型必须是实例化的模型!
dump——用于将python对象进行序列化/持久化
import pickle
pickle.dump(model_name, open("file_name.pkl", "wb"))
load——从本地读取python对象并恢复实例对象
model_name = pickle.load(open("file_name.pkl", "rb"))
3. 回归分析
3.1 如何选择回归分析算法
- 当自变量数量少或经过降维后得到可以使用的二维变量,可以通过散点图发现自变量和因变量的关系,再选择最佳回归方法
- 经过判断发现自变量和因变量有较强的共线性关系,可以使用对多重共线性(自变量高度相关)能灵活处理的算法,如岭回归
- 数据集噪音较多,主成分分析,各个主成分相互正交能够解决多元线性回归中的共线性问题,有效提高模型的抗干扰能力
- 高维度变量,使用正则化回归方法效果更好,例如Lasso, Ridge, ElasticNet或者使用逐步回归中挑选影响显著的自变量建立回归模型
- 使用交叉验证做多个模型的效果对比
- 集成或组合回归方法
3.2 案例分析:大型促销活动前的销售预测
案例背景:大型促销活动的前夜,业务方得到一些数据,想要通过现有数据做回归预测,由于时间紧迫,需要短时间内出结果
可以分析本次数据工作的特点:
- 回归任务,预测数值
- 时间短,无法深入观察、探索性分析,深入的算法选择和参数调优得到最优结果
- 注重结果
具体实施时我们选择常见的、效果好的算法和模型、在特征的预处理和特征工程上不投入过多精力,希望通过模型自身的能力取尽量解决特征存在的隐形问题
具体思路:
- 导入众多回归模型
# 导入库
import pandas as pd
import numpy as np
from sklearn.linear_model import BayesianRidge, ElasticNet# 批量导入要实现的回归算法
from sklearn.svm import SVR # SVM中的回归算法
from xgboost import XGBRegressor
from sklearn.ensemble.gradient_boosting import GradientBoostingRegressor # 集成算法
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import explained_variance_score, mean_absolute_error, \
mean_squared_error, r2_score # 批量导入指标算法
import matplotlib.pyplot as plt # 导入图形展示库
导入多种回归算法,目的是
检验没有先验的条件下,通过多个模型的训练,从中找到最佳拟合算法
-
观察数据

由于没有标签,通过经验我们直到这是一个多变量回归问题,最后一列为因变量,开始划分训练集和测试集 -
初选回归模型
# 初选回归模型
n_folds = 5 # 设置交叉检验的次数
model_names = ['BayesianRidge', 'XGBR', 'ElasticNet', 'SVR', 'GBR']
# 不同模型的名称列表
model_br = BayesianRidge()
# 建立贝叶斯岭回归模型对象
model_xgbr = XGBRegressor(random_state=0)
# 建立XGBR对象
model_etc = ElasticNet(random_state=0)
# 建立弹性网络回归模型对象
model_svr = SVR(gamma='scale')
# 建立支持向量机回归模型对象
model_gbr = GradientBoostingRegressor(random_state=0) # 建立梯度增强回归模型对象
model_list = [model_br, model_xgbr, model_etc,model_svr, model_gbr]
# 不同回归模型对象的集合
pre_y_list = [model.fit(X_train, y_train).predict(X_test) for model in model_list] # 各个回归模型预测的y值列表
- 模型评估 使用回归评估指标
explained_variance_score
mean_absolute_error
mean_squared_error
r2_score
-
可视化选择
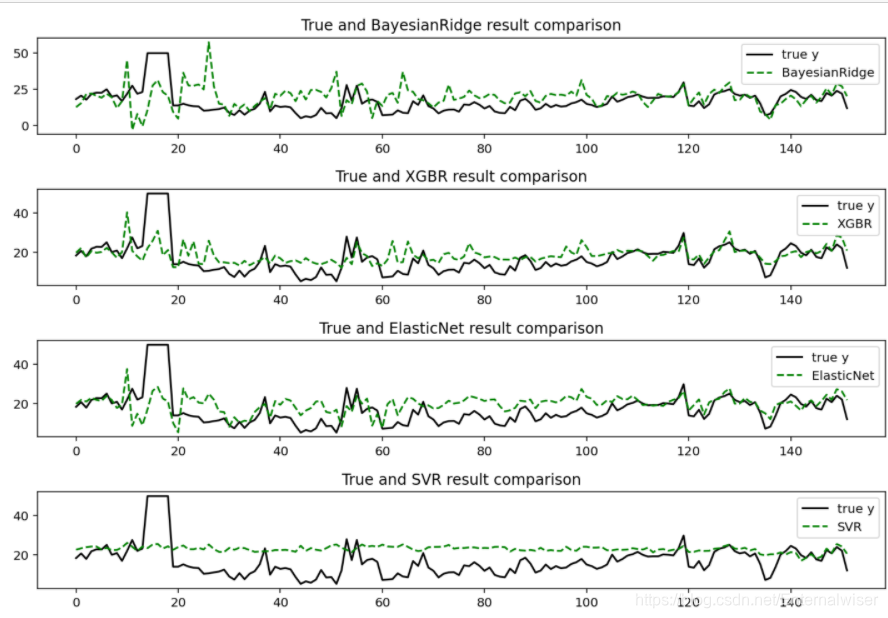
可以得出集成类算法XGBoost和GrantBoosting的效果最好 -
使用模型进行预测
-
提升方法:增加数据集、特征理解和预处理、调参调优
4 分类算法
4.1 过拟合问题
模型过度学习训练集的特征,使得训练集的准确率非常高,但是应用到新的数据集时准确率却很差。
解决方法:
- 使用更多的数据。导致过拟合的根本原因是训练集和新数据集的特征存在较大差异,增加数据后,可能会增加训练集和新数据集的特征相似度,达到更高的效果
- 降维。通过维度选择或者转换的方式,降低参与分类模型的维度数量,能够有效防止原有数据集种的噪音对模型的影响
- 使用正则化方法。正则化通过定义不同特征的参数来保证每个特征有一定的效用,不会使某一特征特别重要。
- 使用组合方法,例如随机森林,adaboost
4.2 如何选择分类分析算法
- 文本分类,大多使用朴素贝叶斯
- 训练集较小,选择高偏差且低方差的分类算法效果更好,比如朴素贝叶斯和支持向量机
- 训练集较大时,不管选择那种方法,都不会显著影响分类准确度
- 重视算法的准确率,那么应该选择算法精度较高的方法,比如支持向量机、GBDT、XGBoost等基于boosting的集成方法
- 注重效果的稳定性或模型鲁棒性,那么应选择随机森林、组合投票模型等基于bagging的方法
- 担心离群点或数据不可分并且需要清晰的决策规则,那么选择决策树
4.3 案例分析
案例背景:对流失用户进行分析,找到流失用户的典型特征
本次数据工作的特点:
- 关于特征提取的分析工作,交付特征的重要性和特征规则
- 由于需要解释规则来进行下一步的业务优化,所以我们可以通过决策树来实现分类
- 需要了解规则的关系,提供规则图
- 数据集大概率出现样本不均衡问题,因为流失用户是少量的
具体思路:
- 观察数据
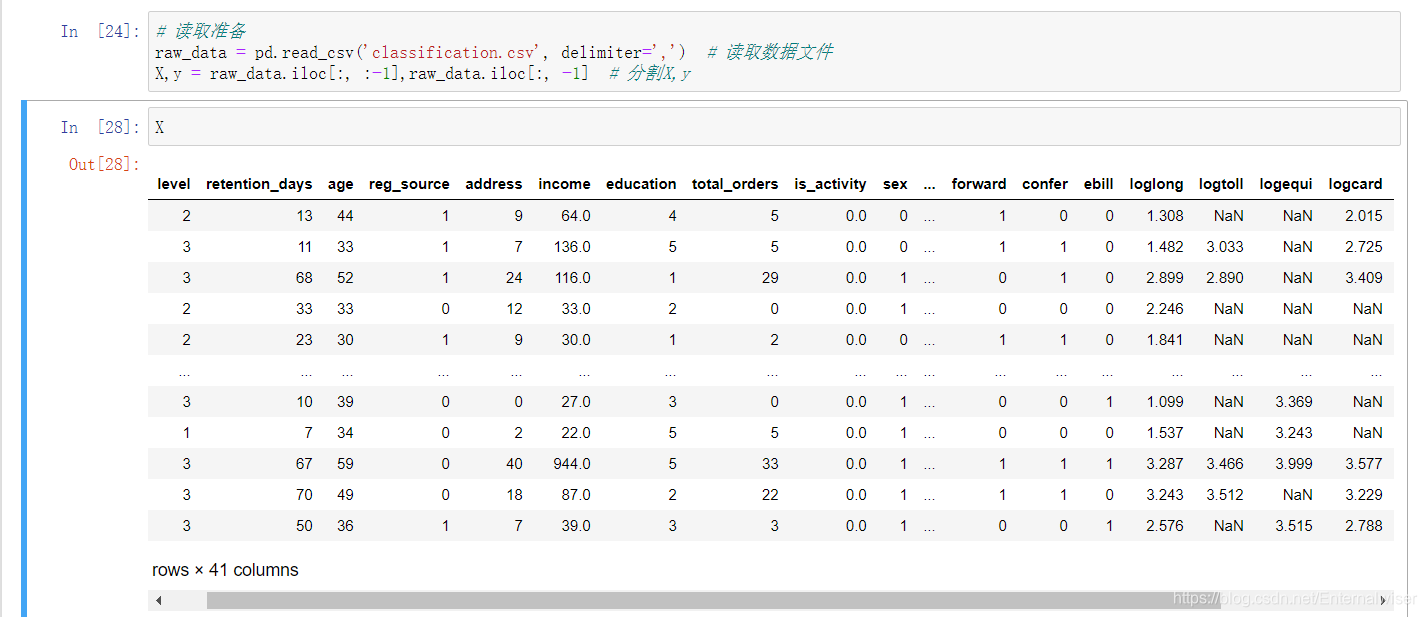
我们可以发现数据存在NaN,样本共有41个特征,这里我们使用XGBoost的分类算法来实现规则提取,选择该模型的理由如下: - XGBoost具有容忍性——即可以不处理NA值
- XGBoost的分类效果较好
- 观察数据可知样本量较少但是特征数量较多,而XGBoost本身能够有效的选择特征并处理,无需做降维处理
导入需要用到的库
import pandas as pd
from sklearn.model_selection import train_test_split # 数据划分
import xgboost as xgb
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score, \
precision_score, recall_score, roc_curve # 导入指标库
import matplotlib.pyplot as plt
from imblearn.over_sampling import SMOTE # 样本均衡处理
- 数据预处理
由于需要处理数据不平衡的问题,我们需要将NA值处理
然后调用imblearn库进行样本平衡处理(注意这里处理后的数据是一个numpy矩阵,我们需要使用pd.DataFrame()建立数据框)
-
对于监督学习,我们需要划分训练集和测试集
-
使用XGBoost进行模型训练
-
分类问题我们使用混淆矩阵来进行效果评估
- 再通过一系列指标评估模型好坏:
- AUC :ROC曲线下的面积,越大越好
- accuracy :准确率,将正例预测为正例,负例预测为负例的比例
- precision : 精确率,将正例预测为正例的比例
- recall :召回率,预测结果被正确预测为正例占总的正例的比例
- f1 :准确度和召回率的调和平均数
- 输出特征重要性
xgb.plot_importance(model, height=0.5, importance_type='gain',
max_num_features=10, xlabel='Gain Split',
grid=False)
model : 树模型对象
height : 条形图的高度
importance_type : 特征重要度的计算分为:
weight :特征在树中的出现次数
gain :使用该特征的平均增益值
cover :使用作为分裂节点的覆盖的样本比例
grid :设置为false不显示网格线
注意需要加载matplotlib库
- 对于给出的规则来确定流失用户的特征



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











