







 本文详细记录了在部署Chinese-LLaMA-Alpaca-2过程中遇到的错误,包括transformers版本不兼容、gradio与huggingface-hub的冲突,以及如何调整GPU设置和模型量化。作者提供了必要的环境配置和解决方法。
本文详细记录了在部署Chinese-LLaMA-Alpaca-2过程中遇到的错误,包括transformers版本不兼容、gradio与huggingface-hub的冲突,以及如何调整GPU设置和模型量化。作者提供了必要的环境配置和解决方法。
Chinese-llama-2部署踩坑记录
1. Chinese-LLaMA-Alpaca-2
A. 部署
a. inference_with_transformers_zh
本地命令行方式交互
python scripts/inference/inference_hf.py --base_model meta-llama/Llama-2-7b-chat-hf --with_prompt --interactive --load_in_8bit
报错:
KeyError: 'Cache only has 0 layers, attempted to access layer with index 0'
报错原因:transformers版本不兼容导致 报错版本:transformers版本为4.36.2(在有的环境中不会报错)
transformers的版本改为4.35.0则不会报错(但是随之datasets的版本也要降低)
原生的接口推理速度较慢
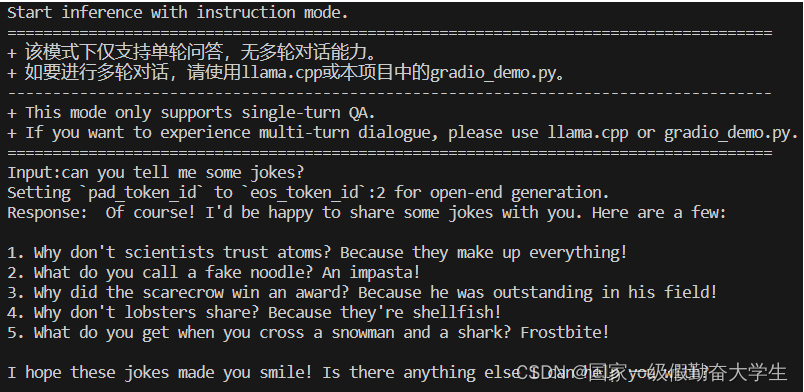
Web图形界面可以在localhost:xxx端口运行
通过gradio构建
pip install gradio
pip install mdtex2html
完整模型加载:
python scripts/inference/gradio_demo.py --base_model meta-llama/Llama-2-7b-chat-hf
冲突:gradio最新版本4.13.0版本依赖的huggingface-hub与tokenizer 0.14.1依赖的huggingface-hub有冲突
加载时报错:
AttributeError: 'Textbox' object has no attribute 'style'
冲突和报错的解决办法:降低gradio的版本
pip uninstall gradio
pip install gradio==3.50.0
pip默认安装最新版本,降低版本即可。
b. text generation webui_zh
./start_linux.sh
由于python版本为3.11.5 而 yaml最多支持到3.8,所以安装失败
要尝试手动安装大概
GitHub上有相关issue
c. api_calls_zh
通过fastapi构建类chatgpt api的效果,可以快速部署
pip install fastapi uvicorn shortuuid sse_starlette
python scripts/openai_server_demo/openai_api_server.py --base_model meta-llama/Llama-2-7b-chat-hf --gpus 0
GPUS设置为多个时可能会报错
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
改为单个GPU即可
发送简单的请求:
curl http://localhost:19327/v1/completions \
-H "Content-Type: application/json" \
-d '{
"prompt": "告诉我中国的首都在哪里"
}'
回复:
{"id":"cmpl-NoAwmqpY9WrdybiAQHTjyr","object":"text_completion","created":1704452701,"model":"chinese-llama-alpaca-2","choices":[{"index":0,"text":"Ah, a great question! China's capital city is none other than Beijing (北京). Located in the northern part of the country, Beijing has a rich history and culture that spans over 3,000 years. It's known for its iconic landmarks such as the Great Wall of China, the Forbidden City, and the Temple of Heaven. Today, Beijing is a bustling metropolis with a vibrant economy, modern infrastructure, and a blend of traditional and contemporary cultures."}]}
d. llamacpp_zh
llamacpp可以使得模型在CPU上进行较快速的推理
复制项目
git clone https://github.com/ggerganov/llama.cpp
make编译
make
该命令可能运行不了,但是不影响推理结果(会影响推理速度)
make LLAMA_CUBLAS=1
将.bin或者.pth的完整模型权重转换为GGML的FP16格式 (不能是软连接)
python convert.py ../llama_from_hf/chinese-alpaca-2-7b/
output:
Wrote ../llama_from_hf/chinese-alpaca-2-7b/ggml-model-f16.gguf
将转换好的FP16格式的gguf量化为4bit的
./quantize ../llama_from_hf/chinese-alpaca-2-7b/ggml-model-f16.gguf ../llama_from_hf/chinese-alpaca-2-7b/ggml-model-q4_0.gguf q4_0
本地使用:
chmod更改文件权限 -x为chat.sh添加可执行权限
chmod +x chat.sh
./chat.sh ../llama_from_hf/chinese-alpaca-2-7b/ggml-model-f16.gguf '请列举5条文明乘车的建议'
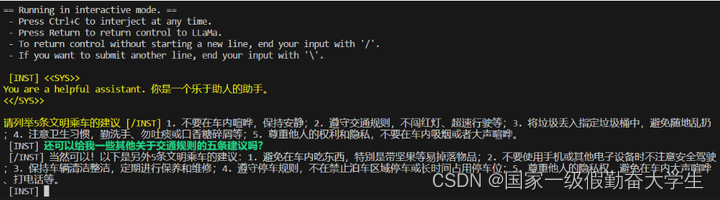
服务器架设
./server -m ../llama_from_hf/chinese-alpaca-2-7b/ggml-model-q4_0.gguf -c 4096 -ngl 1
简单的调用(脚本在Chinese-llama-alpaca-2中)
cd scripts/llamacpp
bash server_curl_example.sh
response:
{"content":" 好的,那我来为您介绍一些有关机器学习的基本概念和应用。\n\n**1.** 什么是机器学习?\n\n机器学习是人工智能的一个分支,通过让计算机自动学习数据并改进其性能来实现目标任务的方法。它使用统计学、模式识别以及优化算法等方法来自动发现数据之间的规律性和关联性。机器学习的目标是开发能够从经验中学习的模型或算法,以便在没有明确编程的情况下自主做出决策和预测结果。\n\n**2.** 常见的应用场景是什么?\n\n1. 图像识别:如人脸识别、车辆检测等;\n2.","generation_settings":{"frequency_penalty":0.0,"grammar":"","ignore_eos":false,"logit_bias":[],"min_p":0.05000000074505806,"mirostat":0,"mirostat_eta":0.10000000149011612,"mirostat_tau":5.0,"model":"../llama_from_hf/chinese-alpaca-2-7b/ggml-model-q4_0.gguf","n_ctx":4096,"n_keep":0,"n_predict":128,"n_probs":0,"penalize_nl":true,"penalty_prompt_tokens":[],"presence_penalty":0.0,"repeat_last_n":64,"repeat_penalty":1.100000023841858,"seed":4294967295,"stop":[],"stream":false,"temperature":0.800000011920929,"tfs_z":1.0,"top_k":40,"top_p":0.949999988079071,"typical_p":1.0,"use_penalty_prompt_tokens":false},"model":"../llama_from_hf/chinese-alpaca-2-7b/ggml-model-q4_0.gguf","prompt":"[INST] <<SYS>>\nYou are a helpful assistant. 你是一个乐于助人的助手。\n<</SYS>>\n\n [/INST]","slot_id":0,"stop":true,"stopped_eos":false,"stopped_limit":true,"stopped_word":false,"stopping_word":"","timings":{"predicted_ms":8846.486,"predicted_n":128,"predicted_per_second":14.469021937071961,"predicted_per_token_ms":69.113171875,"prompt_ms":1689.315,"prompt_n":35,"prompt_per_second":20.71845688933088,"prompt_per_token_ms":48.26614285714286},"tokens_cached":163,"tokens_evaluated":35,"tokens_predicted":128,"truncated":false}
e. privategpt_zh
在本地部署私人GPT
pip 无法直接安装python 3.11.x版本
解决办法:从conda-forge中可以找到
conda create -n gpt11 python=3.11 -c conda-forge
f. langchain_zh
当前主要集成了QA和检索式回答两个功能
环境准备:
pip install langchain==0.0.351
pip install sentence_transformers==2.2.2
pip install pydantic==1.10.13
pip install faiss-gpu==1.7.2
text2vec-large-chinese 和 chinese-alpaca-2-7b 都需要在huggingface上下载
cd scripts/langchain
python langchain_qa.py \
--embedding_path GanymedeNil/text2vec-large-chinese \
--model_path hfl/chinese-alpaca-2-7b \
--file_path doc.txt \
--chain_type refine



















 3855
3855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











