







背景
记一次springboot整合es的业务开发
环境
jdk版本: 1.8
springboot: 2.3.4
spring-data-elasticsearch: 4.0.5
es: 7.5.1
版本问题
springboot\spring-data-elasticsearch\es三者的版本需要适配, 具体对应关系见spring官网
大致流程
1\加依赖\写配置
1\创建es索引对应的bean, springboot整合es后, 会通过这个bean自动帮你建立index和mapping
2\添加document
3\条件查询es
4\更新或删除document
配置
主要就是连接es需要几个配置, yaml的格式就不写了
spring.elasticsearch.rest.uris=127.0.0.1:9200
spring.elasticsearch.rest.password
spring.elasticsearch.rest.username
spring.elasticsearch.rest.read-timeout
索引及映射
通过类注解和属性注解, 来配置索引:
官方api文档
参考文章
类注解@Document:
| 属性名 | 解释 |
|---|---|
| indexName | 索引名称,小驼峰,最长255字节 |
| shards | 分片数,默认1.和集群相关, 影响性能. (因为项目的es不是集群, 数据量也小(一个index就几十MB), 就用的默认值) |
| replicas | 副本,也是默认1.(同上,用的默认值) |
| createIndex | 默认为true, 若es中没有这个索引,启动项目时spring会帮你创建index. |
| useServerConfiguration | 默认false, 是否使用服务器的配置创建索引. (没实践过,嗟来之食) |
| … | 其他参数都是Used for index creation.不知道有啥用 |
属性注解
1\ @Field (data.elasticsearch.annotations)
| 属性名 | 解释 |
|---|---|
| name | 设置字段名,不设置的话默认使用bean的字段名 |
| value | name的别名 ,平时都是用的value, 是否value 可以替代name ? |
| type | 字段类型:使用FieldType, 类型很多. 参考 |
| analyzer | 设置使用的分词器, analyzer = “ik_max_word” |
| format | DateFormat format() default DateFormat.none;使用DateFormat, 指定日期格式. 一大堆格式, 自己看文档吧.也可以自定义: 选择DateFormat.custom, 然后通过下面的pattern属性指定格式 |
| pattern | 设置格式, 如: yyyy-MM-dd HH:mm:ss |
| … | 其他属性没用到, 附上官方文档 |
2\ @Id (data.annotation)
指定哪个字段作为id (必须得有id, 否则报错: No id property found for class)
当然, 指定id既可以使用@id注解

, 也可以将属性直接命名为id

分词器
上述说到@Field可以对某一属性指定分词器进行分词, 当然type要求是text, 才能在写入数据的时候对这个字段进行分词. 这里使用了ik和ngram两个分词器
1\ ik分词器:
用于中文内容的分词 ik需要自己安装, 注意要和es版本一致, github下载地址
| 两种分词算法 | |
|---|---|
| ik_max_word | 细粒度: “张三是人"分成了"张三” “三” “三是” “是” “人” |
| ik_smart | 粗粒度: “张三是人"分成了"张” “三是” “人” |
 ik_max_word ik_max_word
|
 ik_smart ik_smart
|
ik分词安装好后就可以直接使用了.
2\ ngram分词器 :
由于要对数字的string字段进行分词, 因此定义了ngram分词. ik对数字的字符串是不分词的
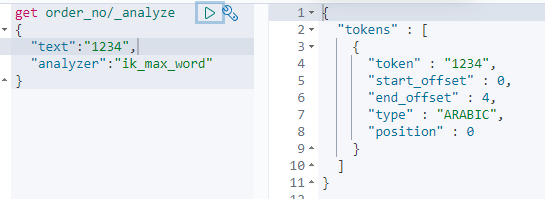 ik分词结果 ik分词结果
|
 ngram分词(min_gram=1, max_gram=2) ngram分词(min_gram=1, max_gram=2)
|
ngram分词器需要在索引的setting中自己配置, 如下是脚本的形式配置. 分词器相关的配置参数可以参考ElasticSearch 解析机制常见用法库 之 Tokenizer常用用法
put students
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 2,
"token_chars": [
"letter", //字符
"digit" //数字
]
}
}
}
}
}
当然java开发肯定要有java代码的形式来写. 这里介绍两种方法:
1、因为setting是要在索引创建的时候设置, 可以通过ElasticsearchRestTemplate来手动创建索引, 这样就可以自定义settings的内容了.注意要在ElasticEntity中注解 @Document(createIndex = false)不自动创建索引
参考博客: springboot2.x 整合 elasticsearch 创建索引的方式
/*
* 实现CommandLineRunner的目的是在项目启动的时候就自动执行, 注意要在ElasticEntity中注解
* @Document(createIndex = false)不自动创建索引
*/
public class EsIndexConfiguration implements CommandLineRunner  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5510
5510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









