







一、Nginx
1、Nginx是什么
Nginx就是反向代理服务器。
Nginx的特点
(1)跨平台:Nginx 可以在大多数 Unix like OS编译运行,而且也有Windows的移植版本。
(2)配置异常简单,非常容易上手。配置风格跟程序开发一样,神一般的配置
(3)非阻塞、高并发连接:数据复制时,磁盘I/O的第一阶段是非阻塞的。官方测试能够支撑5万并发连接,在实际生产环境中跑到2~3万并发连接数.(这得益于Nginx使用了最新的epoll模型)
(4)事件驱动:通信机制采用epoll模型,支持更大的并发连接。
(5)master/worker结构:一个master进程,生成一个或多个worker进程
(6)内存消耗小:处理大并发的请求内存消耗非常小。在3万并发连接下,开启的10个Nginx 进程才消耗150M内存(15M*10=150M)
(7)成本低廉:Nginx为开源软件,可以免费使用。而购买F5 BIG-IP、NetScaler等硬件负载均衡交换机则需要十多万至几十万人民币
(8)内置的健康检查功能:如果 Nginx Proxy 后端的某台 Web 服务器宕机了,不会影响前端访问。
(9)节省带宽:支持 GZIP 压缩,可以添加浏览器本地缓存的 Header 头。
(10)稳定性高:用于反向代理,宕机的概率微乎其微
Nginx的事件处理机制
对于一个基本的web服务器来说,事件通常有三种类型,网络事件、信号、定时器。
首先看一个请求的基本过程:建立连接—接收数据—发送数据 。
再次看系统底层的操作 :上述过程(建立连接—接收数据—发送数据)在系统底层就是读写事件。
1)如果采用阻塞调用的方式,当读写事件没有准备好时,必然不能够进行读写事件,那么久只好等待,等事件准备好了,才能进行读写事件。那么请求就会被耽搁 。阻塞调用会进入内核等待,cpu就会让出去给别人用了,对单线程的worker来说,显然不合适,当网络事 件越多时,大家都在等待呢,cpu空闲下来没人用,cpu利用率自然上不去了,更别谈高并发了 。
2)既然没有准备好阻塞调用不行,那么采用非阻塞方式。非阻塞就是,事件,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事 件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的
小结:非阻塞通过不断检查事件的状态来判断是否进行读写操作,这样带来的开销很大。
3)因此才有了异步非阻塞的事件处理机制。具体到系统调用就是像select/poll/epoll/kqueue这样的系统调用。他们提供了一种机制,让你可以同时监控多个事件,调用他们是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。这种机制解决了我们上面两个问题。
以epoll为例:当事件没有准备好时,就放入epoll(队列)里面。如果有事件准备好了,那么就去处理;如果事件返回的是EAGAIN,那么继续将其放入epoll里面。从而,只要有事件准备好了,我们就去处理她,只有当所有时间都没有准备好时,才在epoll里面等着。这样 ,我们就可以并发处理大量的并发了,当然,这里的并发请求,是指未处理完的请求,线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。这里的切换是没有任何代价,你可以理 解为循环处理多个准备好的事件,事实上就是这样的。
4)与多线程的比较:
与多线程相比,这种事件处理方式是有很大的优势的,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常的轻量级。并发数再多也不会导致无谓的资源浪费(上下文切换)。
小结:通过异步非阻塞的事件处理机制,Nginx实现由进程循环处理多个准备好的事件,从而实现高并发和轻量级。
Nginx的不为人知的特点
(1)nginx代理和后端web服务器间无需长连接;
(2)接收用户请求是异步的,即先将用户请求全部接收下来,再一次性发送后后端web服务器,极大的减轻后端web服务器的压力
(3)发送响应报文时,是边接收来自后端web服务器的数据,边发送给客户端的
(4)网络依赖型低。NGINX对网络的依赖程度非常低,理论上讲,只要能够ping通就可以实施负载均衡,而且可以有效区分内网和外网流量
(5)支持服务器检测。NGINX能够根据应用服务器处理页面返回的状态码、超时信息等检测服务器是否出现故障,并及时返回错误的请求重新提交到其它节点上
Nginx的内部(进程)模型
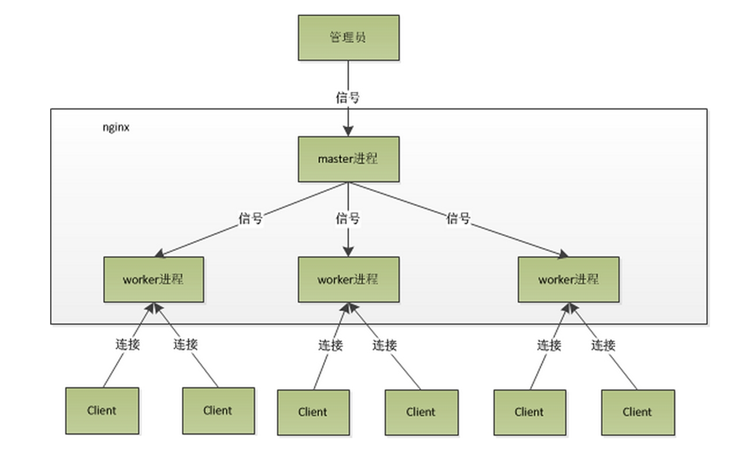
nginx是以多进程的方式来工作的,当然nginx也是支持多线程的方式的,只是我们主流的方式还是多进程的方式,也是nginx的默认方式。nginx采用多进程的方式有诸多好处 .
(1) nginx在启动后,会有一个master进程和多个worker进程。master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控 worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。而基本的网 络事件,则是放在worker进程中来处理了 。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的 。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。 worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的 。
(2)Master接收到信号以后怎样进行处理(./nginx -s reload )?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的进程,并向所有老的进程发送信号,告诉他们可以光荣退休了。新的进程在启动后,就开始接收新的请求,而老的进程在收到来自 master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出 .
(3) worker进程又是如何处理请求的呢?我们前面有提到,worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master 进程fork(分配)过来,在master进程里面,先建立好需要listen的socket之后,然后再fork出多个worker进程,这样每个worker进程都可以去accept这个socket(当然不是同一个socket,只是每个进程的这个socket会监控在同一个ip地址与端口,这个在网络协议里面是允许的)。一般来说,当一个连接进来后,所有在accept在这个socket上面的进程,都会收到通知,而只有一个进程可以accept这个连接,其它的则accept失败,这是所谓的惊群现象。当然,nginx也不会视而不见,所以nginx提供了一个accept_mutex这个东西,从名字上,我们可以看这是一个加在accept上的一把共享锁。有了这把锁之后,同一时刻,就只会有一个进程在accpet连接,这样就不会有惊群问题了。accept_mutex是一个可控选项,我们可以显示地关掉,默认是打开的。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
(4)nginx采用这种进程模型有什么好处呢?采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快重新启动新的worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当前worker上的所有请求失败,不过不会影响到所有请求,所以降低了风险。当然,好处还有很多,大家可以慢慢体会。
(5)有人可能要问了,nginx采用多worker的方式来处理请求,每个worker里面只有一个主线程,那能够处理的并发数很有限啊,多少个worker就能处理多少个并发,何来高并发呢?非也,这就是nginx的高明之处,nginx采用了异步非阻塞的方式来处理请求,也就是说,nginx是可以同时处理成千上万个请求的 .对于IIS服务器每个请求会独占一个工作线程,当并发数上到几千时,就同时有几千的线程在处理请求了。这对操作系统来说,是个不小的挑战,线程带来的内存占用非常大,线程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。我们之前说过,推荐设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效
Nginx是如何处理一个请求
首先,nginx在启动时,会解析配置文件,得到需要监听的端口与ip地址,然后在nginx的master进程里面,先初始化好这个监控的socket(创建socket,设置addrreuse等选项,绑定到指定的ip地址端口,再listen),然后再fork(一个现有进程可以调用fork函数创建一个 新进程。由fork创建的新进程被称为子进程 )出多个子进程出来,然后子进程会竞争accept新的连接。此时,客户端就可以向nginx发起连接了。当客户端与nginx进行三次握手,与nginx建立好一个连接后,此时,某一个子进程会accept成功,得到这个建立好的连接的 socket,然后创建nginx对连接的封装,即ngx_connection_t结构体。接着,设置读写事件处理函数并添加读写事件来与客户端进行数据的交换。最后,nginx或客户端来主动关掉连接,到此,一个连接就寿终正寝了。
当然,nginx也是可以作为客户端来请求其它server的数据的(如upstream模块),此时,与其它server创建的连接,也封装在ngx_connection_t中。作为客户端,nginx先获取一个ngx_connection_t结构体,然后创建socket,并设置socket的属性( 比如非阻塞)。然后再通过添加读写事件,调用connect/read/write来调用连接,最后关掉连接,并释放ngx_connection_t。
nginx在实现时,是通过一个连接池来管理的,每个worker进程都有一个独立的连接池,连接池的大小是worker_connections。这里的连接池里面保存的其实不是真实的连接,它只是一个worker_connections大小的一个ngx_connection_t结构的数组。并且,nginx会通过一个链表free_connections来保存所有的空闲ngx_connection_t,每次获取一个连接时,就从空闲连接链表中获取一个,用完后,再放回空闲连接链表里面。
在这里,很多人会误解worker_connections这个参数的意思,认为这个值就是nginx所能建立连接的最大值。其实不然,这个值是表示每个worker进程所能建立连接的最大值,所以,一个nginx能建立的最大连接数,应该是worker_connections * worker_processes。当然 ,这里说的是最大连接数,对于HTTP请求本地资源来说,能够支持的最大并发数量是worker_connections * worker_processes,而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/2。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
2、部署nginx
安装nginx
sudo apt-get install nginx
#或者
sudo yum install epel-release
sudo yum install python-devel nginx
nginx操作
service nginx start //启动nginx服务
service nginx stop //关闭nginx服务
service nginx restart //重启nginx服务
service nginx status //查看nginx服务状态
测试nginx是否能用
在浏览器输入服务器的IP地址,出现nginx欢迎界面,说明启动成功
配置nginx
默认配置文件是/etc/nginx里的nginx.conf,不用管在/etc/nginx/conf.d下添加一个新的配置文件
cd /etc/nginx/conf.d //进入nginx默认目录
创建项目的config配置文件
server {
listen 80; # 我要监听那个端口
server_name www.cnblogs.com/zzqit; # 你访问的路径前面的url名称ip地址也可以
pid /var/run/nginx.pid; #进程文件
error_log /var/log/nginx/error.log; #错误日志定义等级,[ debug | info | notice | warn | error | crit ]
access_log /var/log/nginx/access.log main; # Nginx日志配置
charset utf-8; # Nginx编码
gzip_types text/plain application/x-javascript text/css text/javascript application/x-httpd-php application/json text/json image/jpeg image/gif image/png application/octet-stream; # 支持压缩的类型
# 指定项目路径uwsgi
location / { # 这个location就和咱们Django的url(r'^admin/', admin.site.urls),
include uwsgi_params; # 导入一个Nginx模块他是用来和uWSGI进行通讯的
uwsgi_connect_timeout 30; # 设置连接uWSGI超时时间
uwsgi_pass unix:///var/www/script/uwsgi.sock; # 指定uwsgi的sock文件所有动态请求就会直接丢给他
}
# 指定静态文件路径
location /static/ {
alias /var/www/orange_web/static/;
}
}
查看nginx配置路径
whereis nginx
测试配置文件是否正确
sudo service nginx configtest
3、问题与解决
nginx域名
在配置文件中的server_name添加了后面两个server_name ip地址 domain.com www.domain.com;
重启nginx就可以用了
二、uWSGI
1、介绍
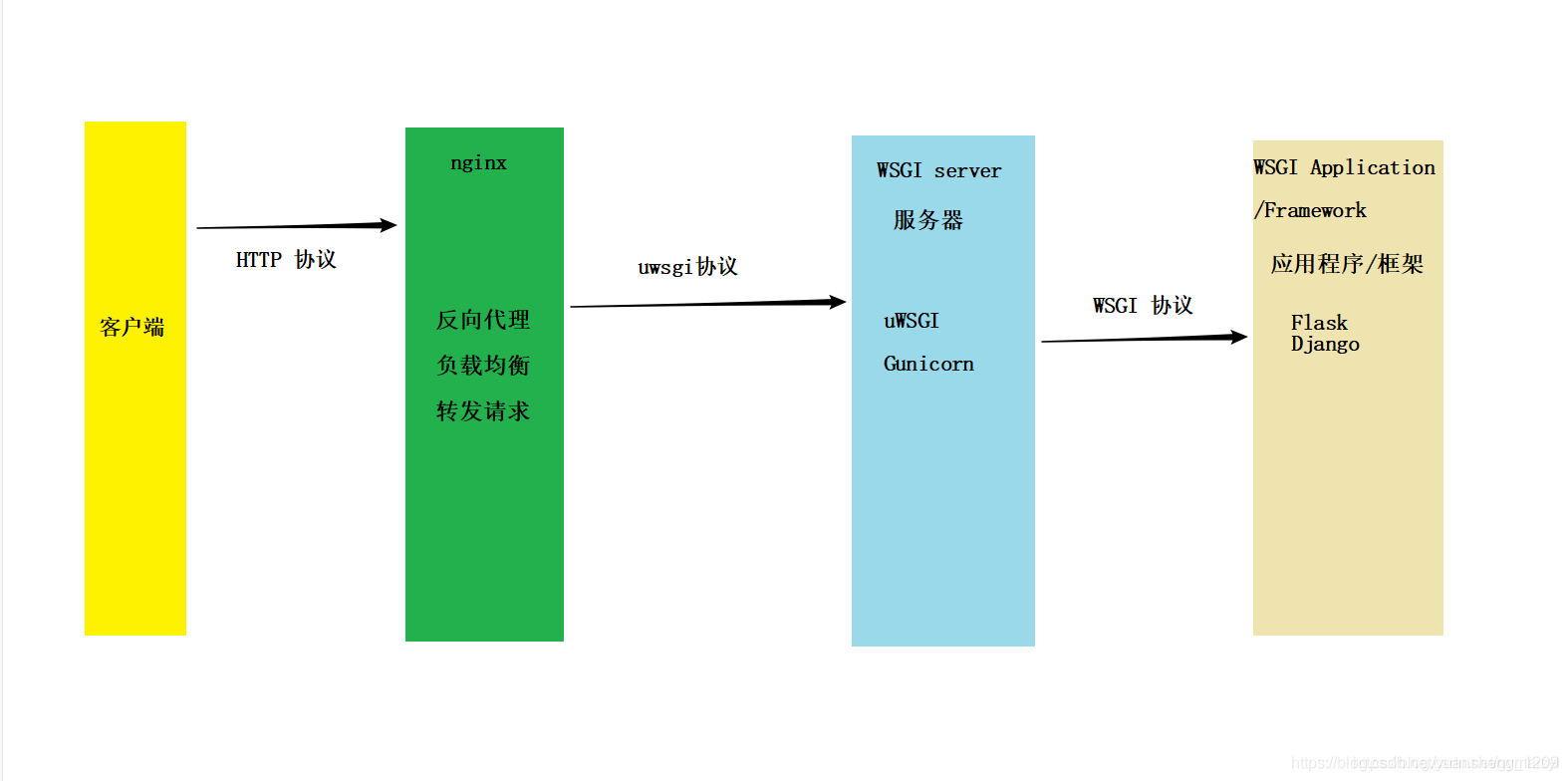
WSGI:
全称是web server gateway interface(web 服务期网关接口),它是一种描述web服务器如何与应用程序(django、flask)通信的规范。
在WSGI中定义了两个角色,web服务器端称为server或gateway,应用程序端称为application或Framework。
server端会先收到用户的请求,然后根据规范要求调用application端,调用的结果会被封装成HTTP响应后再发送给客户端。
应用程序端(application/Framework)的实现一般由python的各种框架完成,例如:django,flask等,框架会提供接口让开发者获取HTTP请求的内容和发送HTTP响应。
Web服务器端(server/gateway)的实现相对复杂一点,主要是因为软件架构。常用的web服务器有:Apache和nginx,但是都没有内置WSGI。而是通过扩展来实现,比如:
Apache服务器,会通过扩展模块mod_wsgi来支持WSGI。Apache和mod_wsgi之间通过程序内部接口传递信息,mod_wsgi会实现WSGI的server端、进程管理以及对application的调用。
Nginx上一般是用proxy的方式,用nginx的协议将请求封装好,发送给应用服务器,比如uWSGI,应用服务器会实现WSGI的服务端、进程管理以及对application的调用。
uwsgi:
与WSGI一样是uWSGI通信的一种协议,用于定义传输信息类型(type of information)。每一个uwsgi packet前4byte为传输信息类型的描述,与WSGI协议是两种东西,据说是fcgi协议的10倍快。
uWSGI:
是一个全功能的http服务器,实现了WSGI规范、uwsgi协议、http协议等。它要做的就是把http协议转化为语言支持的网络协议。比如把http协议转化成WSGI规范,让python可以直接使用。
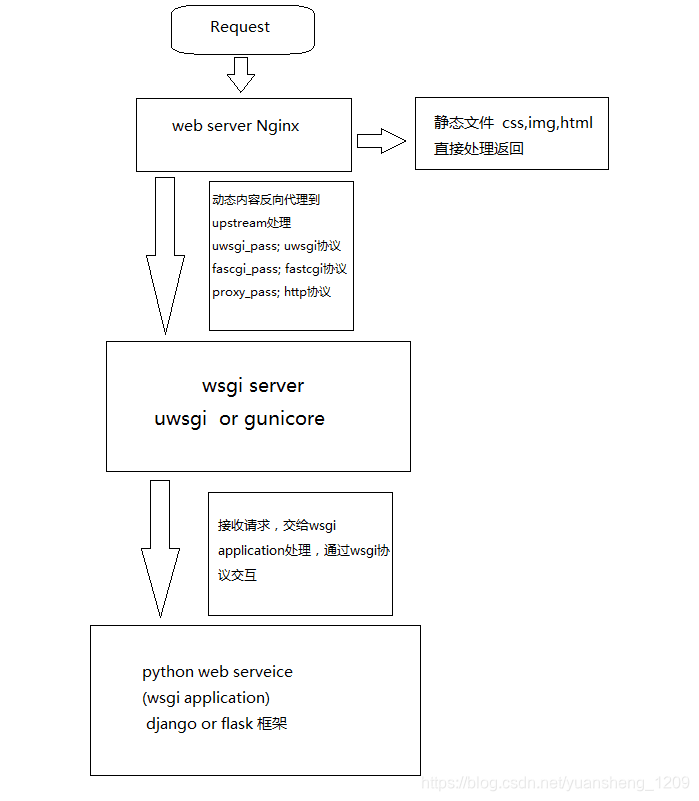
访问过程

2、部署uWSGI
安装uWSGI
pip3 install uwsgi
ln -s /usr/local/python3/bin/uwsgi /usr/local/bin/uwsgi #建立软链接
uwsgi --version #检查安装成功
配置uWSGI
文件放在/etc下
[uwsgi]
#使用nginx连接时使用
#socket=127.0.0.1:8080
#直接做web服务器使用
http=127.0.0.1:8080
#项目目录
chdir=/home/shuan/dailiyfresh
#项目中wsgi.py文件的目录,相对于项目目录
wsgi-file=dailiyfresh/wsgi.py
# 指定启动的工作进程数
processes=4
# 指定工作进程中的线程数
threads=2
master=True
# 保存启动之后主进程的pid
pidfile=uwsgi.pid
# 设置uwsgi后台运行,用uwsgi.log保存日志信息
daemonize=uwsgi.log
# 设置虚拟环境的路径
virtualenv=/home/shuan/.virtualenvs/bj18_py3
配置完成后,可用uwsgi --ini name.ini,运行根据输出检查是否有报错,尽量少配先运行起来。
3、问题与解决
无法启动问题
no python application found, check your startup logs for errors
解决:
需要把wsgi-file这变量修改成项目名/wsgi.py,也就是wsgi.py所以的路劲
CPU使用率100%
在Linux里面看下进程
ps aux | less
发现占用cpu的是一堆uwsgi进程,uwsgi配置文件里processes填的是8
按道理最多只有8个uwsgi进程,但是这有十几个,每个占用率有百分之十几
网上说法
python+supervisor+uwsgi跑web程序时出现uwsgi defunct进程的cpu达到100%问题
这个问题的原因是supervisor中进程退出,而重启进程时的处理有问题
详细情况可以看 https://github.com/unbit/uwsgi/issues/296
问题解决的办法是在uwsgi的配置文件中添加die-on-term = true参数
或者在命令行参数中添加--die-on-term参数
我暂时加了这个参数,不确定有没有用
杀掉之前已经存在的uwsgi进程,一下子cpu占用率就下去了
killall -9 uwsgi
三、Supervisor
1、介绍
是用Python开发的一个client/server服务,是Linux/Unix系统下的一个进程管理工具,不支持Windows系统。它可以很方便的监听、启动、停止、重启一个或多个进程。用Supervisor管理的进程,当一个进程意外被杀死,supervisort监听到进程死后,会自动将它重新拉起,很方便的做到进程自动恢复的功能,不再需要自己写shell脚本来控制。
2、部署
安装Supervisor
sudo pip install supervisor
配置Supervisor
在当前项目下创建一个名为supervisor.conf的配置文件 /etc/supervisord/
# supervisor的程序名字
[program:webnote]
# supervisor执行的命令,注意这里的配置文件名称要与之前创建的一致
command=uwsgi --ini uwsgi.ini
# 项目的目录
directory = /home/xe/Desktop/webnote
# 开始的时等待多少秒
startsecs=0
# 停止的时等待多少秒
stopwaitsecs=0
# 自动开始
autostart=true
# 程序中断后自动重启
autorestart=true
# 配置日志文件
stdout_logfile=/home/xe/Desktop/webnote/supervisord.log
stderr_logfile=/home/xe/Desktop/webnote/supervisord.err
# 设置日志的级别
[supervisord]
loglevel=info
# 配置supervisor服务器
[inet_http_server]
port = :9001
# 用户名和密码
username = admin
password = 123
# 配置supervisorctl,使用supervisorctl的ip和端口
[supervisorctl]
serverurl = http://127.0.0.1:9001
# 配置supervisorctl的用户名和密码
username = admin
password = 123
[rpcinterface:supervisor]supervisor.rpcinterface_factory =supervisor.rpcinterface:make_main_rpcinterface
使用supervisor运行uwsgi
supervisord -c bbs_supervisor.conf
使用supervisorctl管理supervisord
supervisorctl -c bbs_supervisor.conf
常用命令
> status # 查看状态
> start program_name # 启动程序
> restart program_name # 重新启动程序
> stop program_name # 停止程序
> reload # 重新加载配置文件
> quit # 退出当前的客户端
重启supervisor
**systemctl restart supervisord **重启Supervisor
四、Python虚拟环境
1、安装
pip install virtualenvwrapper
pip install virtualenvwrapper-win #Windows使用该命令
2、创建一个文件夹,用来保存虚拟环境目录
cd /workspace/
mkdir python_env
#mac下要给python_env设置权限:
sudo chmod 777 python_env
3、配置环境变量
vim ~/.bash_profile
#添加以下内容,要将具体路径改成自己的路径
export WORKON_HOME=/workspace/python_env
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /Library/Frameworks/Python.framework/Versions/3.6/bin/virtualenvwrapper.sh
PATH="/Library/Frameworks/Python.framework/Versions/3.6/bin:${PATH}"
export PATH
4、具体操作命令
* 列出所有虚拟环境 workon
* 创建基本环境 mkvirtualenv [环境名] (有可能没有生效,用下面的在试试)
或者进入/workspace/python_env目录下,使用mkvirtualenv --python==/usr/local/soft/Python-3.6.4/python.exe django_env创建虚拟环境
* 激活环境 workon [环境名]
* 退出环境 deactivate [环境名]
* 删除环境 rmvirtualenv [环境名]*















 6775
6775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









