







MINIST
MNIST数据库(Modified National Institute of Standards and Technology database)是一个大型的手写数字集合。它有一个60,000个样本的训练集和一个10,000个样本的测试集。它是较大的NIST Special Database 3(由美国人口普查局员工编写的手写数字)和Special Database 1(由高中生编写的手写数字)的子集,包含单色手写数字图像。数字已按大小归一化并集中在固定大小的图像中。来自NIST的原始黑白(二值)图像经过大小归一化以适应20x20像素框,同时保持其宽高比。归一化后的图像由于使用了反锯齿技术的归一化算法而具有灰度级别。通过计算像素的中心,图像在28x28的图像中被中心定位,并平移图像以将该点放置在28x28的场的中心

数据链接:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
SVHN
SVHN(Street View House Numbers)是一个数字分类基准数据集,包含60万张32×32的RGB图像,这些图像是从房屋门牌号的照片中裁剪出来的。裁剪后的图像以目标数字为中心,但附近的数字和其他干扰物仍保留在图像中。SVHN有三个集:训练集、测试集和额外集,额外集包含53万张图像,这些图像难度较低,可用于帮助训练过程。
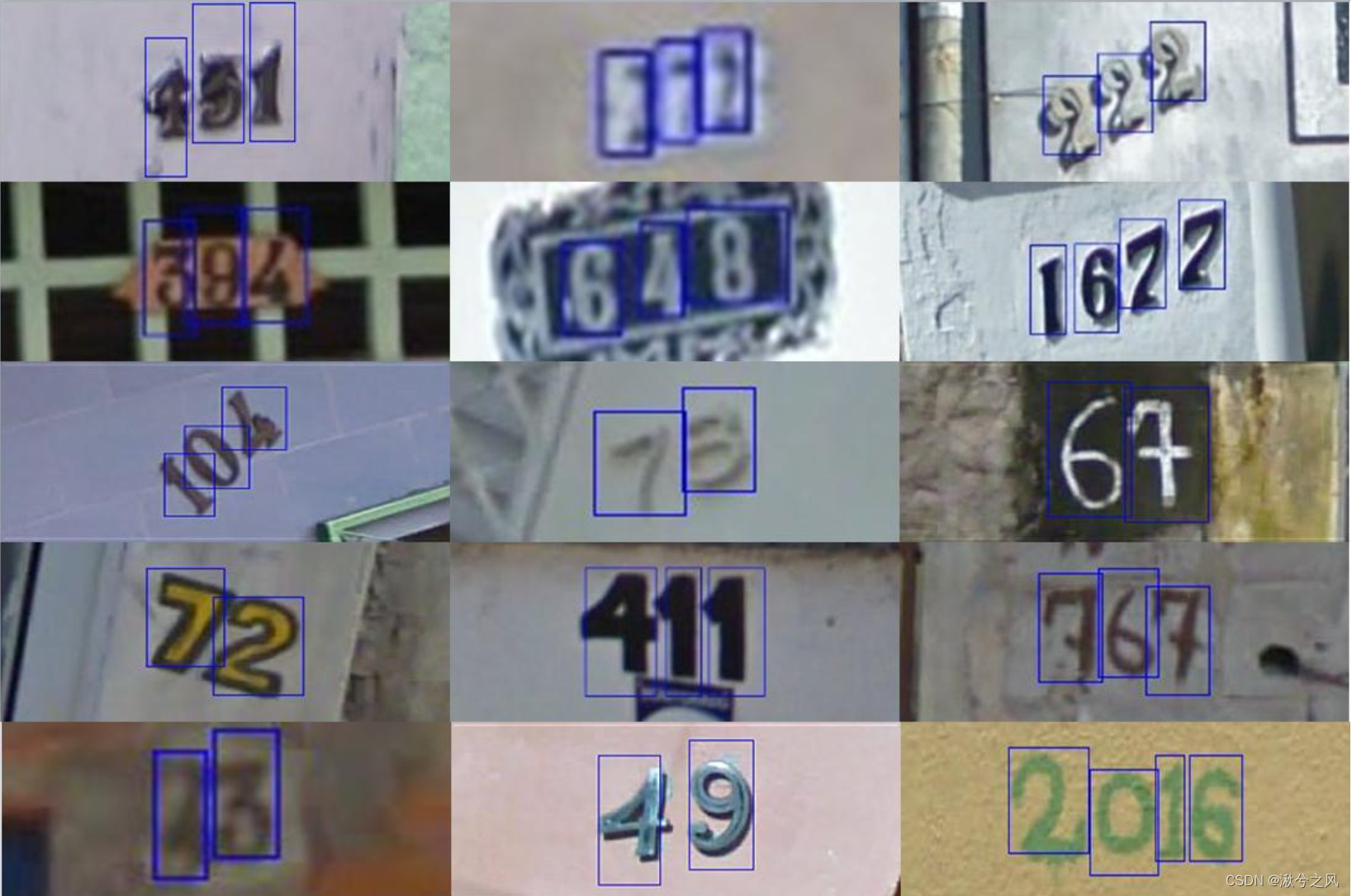
数据链接: The Street View House Numbers (SVHN) Dataset (stanford.edu)
CIFAR-10
CIFAR-10数据集(加拿大高等研究院,10个类别)是Tiny Images数据集的一个子集,由60000个32x32彩色图像组成。这些图像被标记为10个相互排斥的类别之一:飞机、汽车(但不包括卡车或皮卡)、鸟、猫、鹿、狗、青蛙、马、船和卡车(但不包括皮卡)。每个类别有6000个图像,每个类别的训练图像为5000个,测试图像为1000个。
 数据链接:CIFAR-10 and CIFAR-100 datasets (toronto.edu)
数据链接:CIFAR-10 and CIFAR-100 datasets (toronto.edu)
CIFAR-100
CIFAR-100数据集(加拿大高等研究院,100个类别)是Tiny Images数据集的一个子集,由60000个32x32彩色图像组成。CIFAR-100中的100个类别被分为20个超类。每个类别有600张图像。每张图像都有一个“精细”标签(它所属的类别)和一个“粗糙”标签(它所属的超类)。每个类别有500张训练图像和100张测试图像。

数据链接:CIFAR-10 and CIFAR-100 datasets (toronto.edu)
Fashion-MNIST
Fashion-MNIST是一个数据集,包含70,000张时尚产品的28×28灰度图像,分为10个类别,每个类别有7,000张图像。训练集有60,000张图像,测试集有10,000张图像。Fashion-MNIST与原始MNIST共享相同的图像大小、数据格式和训练和测试拆分的结构。

数据链接: github.com https://github.com/zalandoresearch/fashion-mnist
https://github.com/zalandoresearch/fashion-mnist
CUB-200-2011
Caltech-UCSD Birds-200-2011 (CUB-200-2011)数据集是细粒度视觉分类任务中使用最广泛的数据集。它包含11788张属于鸟类的200个子类别的图像,其中5994张用于训练,5794张用于测试。每张图像都有详细的注释:1个子类别标签、15个部分位置、312个二进制属性和1个边界框。文本信息来自Reed等人。他们通过收集细粒度的自然语言描述来扩展CUB-200-2011数据集。每张图像收集了10个单句描述。自然语言描述是通过Amazon Mechanical Turk(AMT)平台收集的,要求至少包含10个单词,而不包含任何子类别和动作的信息。

数据链接:Perona Lab - CUB-200-2011 (caltech.edu)
STL-10
STL-10是一个来自ImageNet的图像数据集,通常用于评估无监督特征学习或自学习算法。除了100,000张未标记的图像外,它还包含来自10个对象类别的13,000张标记图像(如鸟类、猫、卡车),其中5,000张图像被划分用于训练,其余8,000张图像用于测试。所有图像都是96×96像素的彩色图像。

数据链接:STL-10 dataset (stanford.edu)
Oxford 102 Flower
牛津102花是一个图像分类数据集,由102个花类组成。所选的花是英国常见的花。每个类由40到258幅图像组成。图像具有大尺度、姿势和光线变化。此外,有些类别在类别内变化很大,还有一些非常相似的类别。

数据链接:【花卉数据集】-计算机视觉数据集-极市开发者平台 (cvmart.net)
ImageNet
根据WordNet层次结构,ImageNet数据集包含14,197,122幅带注释图像。自2010年以来,该数据集用于ImageNet大规模视觉识别挑战赛(ILSVRC),这是图像分类和目标检测的基准。公开发布的数据集包含一组手动注释的训练图像。还发布了一组测试图像,其中手动注释被保留。ILSVRC 注释分为两类:(1)图像级注释,用于标记图像中是否存在某个对象类别的二元标签,例如“此图像中有汽车”,但“没有老虎”,以及 (2)对象级注释,用于标记图像中某个对象实例周围的紧密边界框和类别标签,例如“有一个螺丝刀,中心位置为 (20,25),宽度为 50 像素,高度为 30 像素”。 ImageNet 项目不拥有图像的版权,因此仅提供图像的缩略图和 URL



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









