




 本文介绍了Meta AI团队的DINOv2模型,它借鉴自然语言处理技术为计算机视觉提供新思路。文中阐述了其数据预处理方式,通过自监督方法从大量未标注数据中检索样本。还分析了代码结构,包括配置、数据和模型组件层。最后利用其预训练模型构建简易图像分类网络。
本文介绍了Meta AI团队的DINOv2模型,它借鉴自然语言处理技术为计算机视觉提供新思路。文中阐述了其数据预处理方式,通过自监督方法从大量未标注数据中检索样本。还分析了代码结构,包括配置、数据和模型组件层。最后利用其预训练模型构建简易图像分类网络。

Title:DINOv2: Learning Robust Visual Features without Supervision
paper: 2304.07193.pdf (arxiv.org)
时隔两年半,Meta AI 团队再度为大家奉上了 DINO 的进阶版——DINOv2!这篇文章主要是借鉴最近在自然语言处理方面的一些技术和进展,如语言模型的预训练,可以使计算机可以更好地理解语言。这些技术相当重要,因为它们为计算机视觉领域的类似技术提供了新的思路和方法。
最近对论文出来不久,对论文和论文的代码进行了大概了解,该模型的创新场景主要还是依赖数据集的来源和大规模算力,所以想复现该模型的训练过程,除非你有很好的实验环境,否则还是调用它的预训练模型进行迁移训练吧。我也是对它的整体进行了浅薄了解,如有出错请指正。
一、数据预处理

本文的主要贡献之一便是创建了一个大规模的数据集——LVD-142M。同以往的人工采集、标注和清洗流程不同,此数据集是通过从大量未标注的数据中检索出与几个经过精心整理过的数据集中存在相似度很高的那部分样本所组成的。主要是进行数据的聚类,数据的重复删除等操作,说是利用了自监督的方法进行了训练,感兴趣的可以去论文详细看下。
二、代码
代码目录
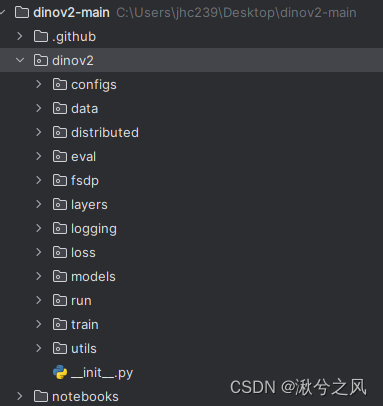
从文件目录可以出meta对于代码的封装还是很好的,我们平时可能不会将模型进行拆分训练。configs: 包含训练和测试的yaml配置文件,以vitg14.yaml为例,其中包含batch_size,GPU参数量,如果你卡多可以试着修改训练。
dino:
head_n_prototypes: 131072
head_bottleneck_dim: 384
ibot:
separate_head: true
head_n_prototypes: 131072
train:
batch_size_per_gpu: 12
dataset_path: ImageNet22k
centering: sinkhorn_knopp
student:
arch: vit_giant2
patch_size: 14
drop_path_rate: 0.4
ffn_layer: swiglufused
block_chunks: 4
teacher:
momentum_teacher: 0.994
optim:
epochs: 500
weight_decay_end: 0.2
base_lr: 2.0e-04 # learning rate for a batch size of 1024
warmup_epochs: 80
layerwise_decay: 1.0
crops:
local_crops_size: 98data:主要包含不同数据集的dataset函数,如果你有自己的训练数据,那么需要加载自己的dataset文件,将训练和测试数据打包成batch输入。
laysers:一个比较重要的模块,其中包含meta在dinvo2中用的那些模型组件,这是dinvo2论文中没有进行详细简洁的,虽然与vit主要组件相似,但部分细节进行了修改,下面进行详细讲解。
三、Layers
patch_embed
# Copyright (c) Meta Platforms, Inc. and affiliates.
#
# This source code is licensed under the Apache License, Version 2.0
# found in the LICENSE file in the root directory of this source tree.
# References:
# https://github.com/facebookresearch/dino/blob/master/vision_transformer.py
# https://github.com/rwightman/pytorch-image-models/tree/master/timm/layers/patch_embed.py
from typing import Callable, Optional, Tuple, Union
from torch import Tensor
import torch.nn as nn
def make_2tuple(x):
if isinstance(x, tuple):
assert len(x) == 2
return x
assert isinstance(x, int)
return (x, x)
class PatchEmbed(nn.Module):
"""
2D image to patch embedding: (B,C,H,W) -> (B,N,D)
Args:
img_size: Image size.
patch_size: Patch token size.
in_chans: Number of input image channels.
embed_dim: Number of linear projection output channels.
norm_layer: Normalization layer.
"""
def __init__(
self,
img_size: Union[int, Tuple[int, int]] = 224,
patch_size: Union[int, Tuple[int, int]] = 16,
in_chans: int = 3,
embed_dim: int = 768,
norm_layer: Optional[Callable] = None,
flatten_embedding: bool = True,
) -> None:
super().__init__()
image_HW = make_2tuple(img_size)
patch_HW = make_2tuple(patch_size)
patch_grid_size = (
image_HW[0] // patch_HW[0],
image_HW[1] // patch_HW[1],
)
self.img_size = image_HW
self.patch_size = patch_HW
self.patches_resolution = patch_grid_size
self.num_patches = patch_grid_size[0] * patch_grid_size[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.flatten_embedding = flatten_embedding
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_HW, stride=patch_HW)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x: Tensor) -> Tensor:
_, _, H, W = x.shape
patch_H, patch_W = self.patch_size
assert H % patch_H == 0, f"Input image height {H} is not a multiple of patch height {patch_H}"
assert W % patch_W == 0, f"Input image width {W} is not a multiple of patch width: {patch_W}"
x = self.proj(x) # B C H W
H, W = x.size(2), x.size(3)
x = x.flatten(2).transpose(1, 2) # B HW C
x = self.norm(x)
if not self.flatten_embedding:
x = x.reshape(-1, H, W, self.embed_dim) # B H W C
return x
def flops(self) -> float:
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
这就是vit中的图像块映射成序列的功能,patch_size指定图像块分割的大小,embed_dim指定图像块序列的维度,其实就是卷积通道的维度。仔细观察代码,底层还是卷积计算,只不过说最后将feature进行了展平操作,最终成了所说的tokens。
attention
# Copyright (c) Meta Platforms, Inc. and affiliates.
#
# This source code is licensed under the Apache License, Version 2.0
# found in the LICENSE file in the root directory of this source tree.
# References:
# https://github.com/facebookresearch/dino/blob/master/vision_transformer.py
# https://github.com/rwightman/pytorch-image-models/tree/master/timm/models/vision_transformer.py
import logging
import os
import warnings
from torch import Tensor
from torch import nn
logger = logging.getLogger("dinov2")
XFORMERS_ENABLED = os.environ.get("XFORMERS_DISABLED") is None
try:
if XFORMERS_ENABLED:
from xformers.ops import memory_efficient_attention, unbind
XFORMERS_AVAILABLE = True
warnings.warn("xFormers is available (Attention)")
else:
warnings.warn("xFormers is disabled (Attention)")
raise ImportError
except ImportError:
XFORMERS_AVAILABLE = False
warnings.warn("xFormers is not available (Attention)")
class Attention(nn.Module):
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = False,
proj_bias: bool = True,
attn_drop: float = 0.0,
proj_drop: float = 0.0,
) -> None:
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim, bias=proj_bias)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x: Tensor) -> Tensor:
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class MemEffAttention(Attention):
def forward(self, x: Tensor, attn_bias=None) -> Tensor:
if not XFORMERS_AVAILABLE:
if attn_bias is not None:
raise AssertionError("xFormers is required for using nested tensors")
return super().forward(x)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)
q, k, v = unbind(qkv, 2)
x = memory_efficient_attention(q, k, v, attn_bias=attn_bias)
x = x.reshape([B, N, C])
x = self.proj(x)
x = self.proj_drop(x)
return x
从代码中可以看出meta写了两种attention,一个是transformer的多头注意力机制,一个是MemEffAttention注意力。MemEffAttention是pytorch封装的多头注意力,加入了一些GPU的加速功能,时间量上有所下降,但精度只是模拟的拟合。可根据自己的实验环境进行选择。
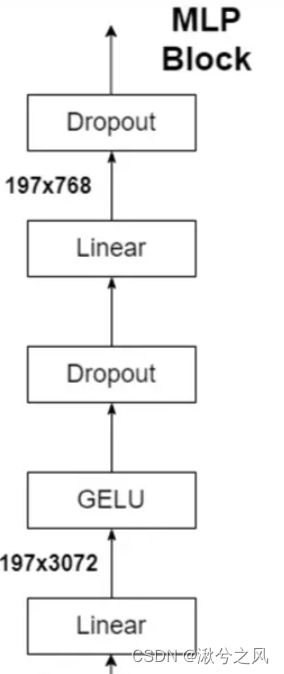
MLP
from typing import Callable, Optional
from torch import Tensor, nn
class Mlp(nn.Module):
def __init__(
self,
in_features: int,
hidden_features: Optional[int] = None,
out_features: Optional[int] = None,
act_layer: Callable[..., nn.Module] = nn.GELU,
drop: float = 0.0,
bias: bool = True,
) -> None:
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features, bias=bias)
self.drop = nn.Dropout(drop)
def forward(self, x: Tensor) -> Tensor:
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
这段代码再熟悉不过了吧,就是简单的MLP层,由全连接映射组成,与vit原始框架组件相同。
Block
我们主要看以下代码:
elif self.training and self.sample_drop_ratio > 0.0:
x = x + self.drop_path1(attn_residual_func(x))
x = x + self.drop_path1(ffn_residual_func(x)) # FIXME: drop_path2
else:
x = x + attn_residual_func(x)
x = x + ffn_residual_func(x)是不是很熟悉,与vit与swin的写法是类似的,先经过注意力层再经过一个前馈网络。所以dinvo2底层还是基于vit进行的小改装,主要还是数据集的制作、自监督及训练的方式。大致了解网络情况,可以利用已经封装好的网络结构来搭建一个建议的图像分类网络。
四、简易图像分类构建
数据集
CIFAR-10数据集(加拿大高级研究所,10类)是Tiny Images数据集的一个子集,由60000张32x32彩色图像组成。这些图像被标记为10个相互排斥的类别之一:飞机、汽车(但不包括卡车或皮卡)、鸟、猫、鹿、狗、青蛙、马、船和卡车(但不包括皮卡)。每个类有6000个图像,每个类有5000个训练图像和1000个测试图像。
数据集链接:CIFAR-10 and CIFAR-100 datasets (toronto.edu)
网络模型
import torch
from torch import nn
import hubconf
class dinov2Model(nn.Module):
def __init__(self, num_classes=1000):
super(dinov2Model, self).__init__()
self.backBone=hubconf.dinov2_vits14(pretrained=True)
self.linear= nn.Sequential(
nn.Linear(in_features=384, out_features=num_classes)
)
def forward(self, x):
x = self.backBone(x)
return self.linear(x)
def test_output_shape(self):
test_img = torch.rand(size=(1, 3, 227, 227), dtype=torch.float32)
for layer in self.net:
test_img = layer(test_img)
print(layer.__class__.__name__, 'output shape: \t', test_img.shape)
if __name__ == '__main__':
model = dinov2Model()
print(model)
总结
论文刚出来不久,也没有深入了解,但可以利用dinov2的预训练模型,搭建自己所需的图像分类、分割网络等。本文原创,如有错误请大家指正。

















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









