







 本文详细介绍了在Windows上安装和运行Kafka的步骤,包括JDK的安装、Zookeeper的配置,以及Kafka的下载、配置和启动。通过一系列的命令行操作,创建主题、生产者和消费者,实现Kafka的基本功能。
本文详细介绍了在Windows上安装和运行Kafka的步骤,包括JDK的安装、Zookeeper的配置,以及Kafka的下载、配置和启动。通过一系列的命令行操作,创建主题、生产者和消费者,实现Kafka的基本功能。
摘要:本文主要说明了如何在Windows安装运行Kafka
一、安装JDK
过程比较简单,这里不做说明。
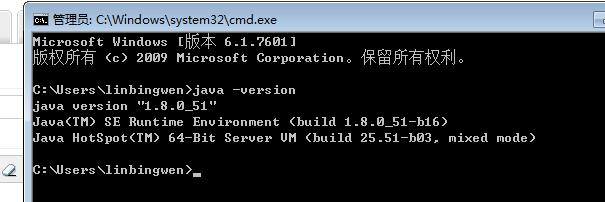
最后打开cmd输入如下内容,表示安装成功
二、安装zooeleeper
下载安装包:http://zookeeper.apache.org/releases.html#download
下载后解压到一个目录:
1.进入Zookeeper设置目录,笔者D:\Java\Tool\zookeeper-3.4.6\conf
2. 将“zoo_sample.cfg”重命名为“zoo.cfg”
3. 在任意文本编辑器(如notepad)中打开zoo.cfg
4. 找到并编辑dataDir=D:\\Java\\Tool\\zookeeper-3.4.6\\tmp
5. 与Java中的做法类似,我们在系统环境变量中添加:
a. 在系统变量中添加ZOOKEEPER_HOME = D:\Java\Tool\zookeeper-3.4.6
b. 编辑path系统变量,添加为路径%ZOOKEEPER_HOME%\bin;
6. 在zoo.cfg文件中修改默认的Zookeeper端口(默认端口2181)
这是笔者最终的文件内容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initia 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









