








GAN(Generative Adversarial Nets)全称为对抗生成网络,其结构主要有两个部分①生成器(Generator)②鉴别器(Discriminator)

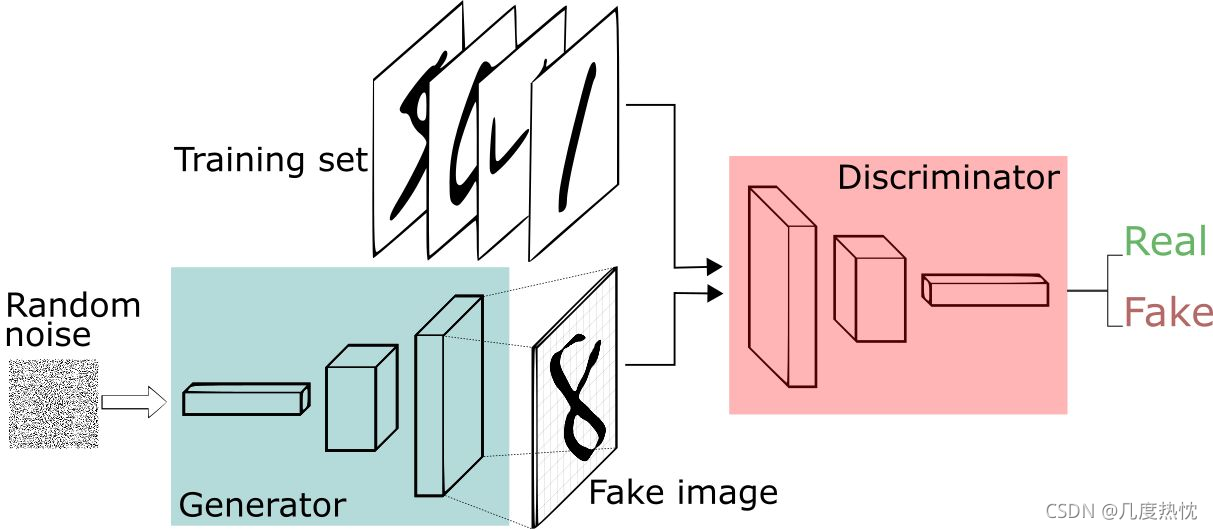 以上图手写数字为例,我们拥有手写数字数据集,希望通过GAN来生成手写数字的图片,达到以假乱真的效果
以上图手写数字为例,我们拥有手写数字数据集,希望通过GAN来生成手写数字的图片,达到以假乱真的效果
生成器G:学习数据分布,生成图像,输入一个向量,输出手写数字的图像
鉴别器D:用于鉴别图片来自于真实数据还是有生成器G生成而来。输入图片,输出为图片的属于真实数据的概率
D(x) 表示 x 来源于真实样本而不是生成样本的概率
下图参考一位博主的相关内容 参考文章见文末
要先训练k次判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够教好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新。

文中提到,禁止在训练的内环中优化D,同时在有限的数据集内训练会引起过拟合。基于以上两点,本文在采用交替完成k次优化D和一次优化G
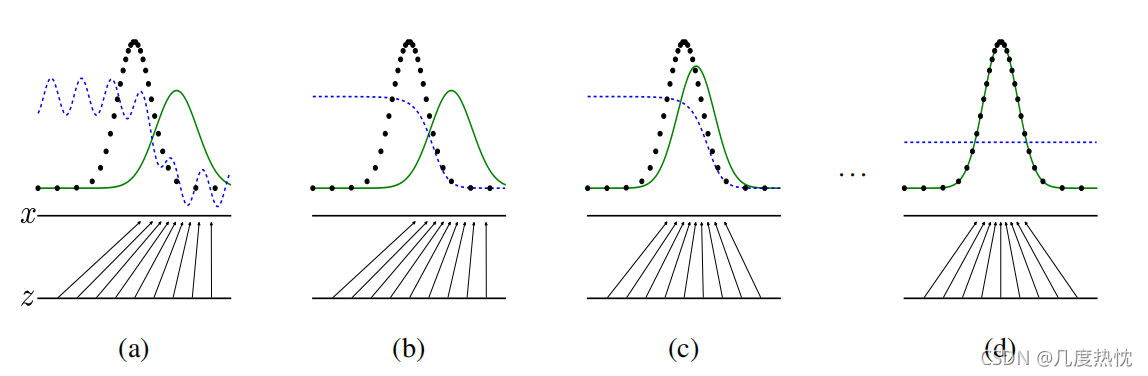
上图中,黑色虚线表示真实样本分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。Z 表示噪声,从Z到x表示通过生成器之后的分布的映射情况 x=G(Z)
(a)图为初始状态,生成器生成的分布与真实分布存在较大差异,鉴别器判别样本的能力不稳定
(b)图经过多次训练鉴别器,鉴别样本的能力显著提高,从而是蓝色虚线较为稳定,生成器的生成能力未发生改变
(c)图经过训练生成器,生成器生成的分布趋近于真实样本分布
(d)图经过反复训练生成器和鉴别器,最终使生成的样本分布拟合于真实样本,同时的鉴别器难以分辨样本来自于真实样本还是有生成器生成,鉴别概率为1/2
公式推导
因为公式推导中需要用到信息论的内容,我们先补充一点相关知识
信息量:信息量的大小可以衡量事件的不确定性或发生的惊讶程度。一个事件发生的概率越小则其所含的信息量越大。
若两事件不相关,信息量满足可加性 f(X,Y):=f(X)+f(Y) 且概率(X、Y均代表概率值)和信息量满足负相关 。
信息量可定义为 f(x):=-log(x) 具体推导请查看文末的参考链接
熵:代表一个系统里的混乱程度,公式如下
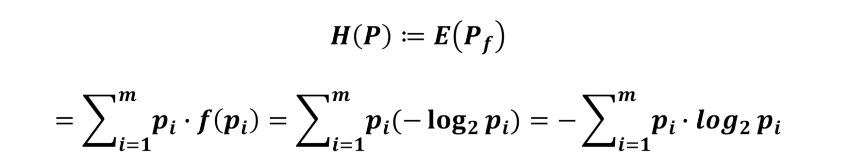
系统P中的熵可以定义为对系统中信息量的期望,对系统中所以可能事件的信息量×该事件发生的概率再求和
相对熵(KL散度):
下图中为相对熵的定义,P和Q代表两个概率系统,fQ(qi) fP(pi)分别代表各自概率系统的信息量
P||Q顺序不能随意调换,P在前代表以P为基准,来考虑Q和P相差多少
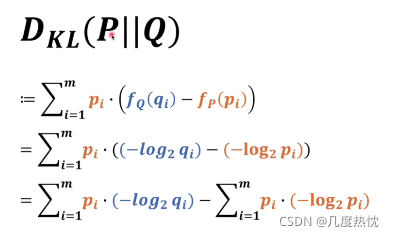
上式最后一行,由于是以P系统为基准是不变的,后面就是P系统的熵

上式的前面部分就是P的交叉熵,用H(P,Q)表示

根据吉布斯不等式证明,KL散度一定大于等于0,当P和Q相等时,KL散度等于0;当P和Q不等时,KL散度大于0。
要让P和Q十分接近,即让相对熵最小,就是让交叉熵最小的值
交叉熵越小,即两个系统模型越接近
交叉熵公式如下
注意:这里的xi是标签,qi是概率
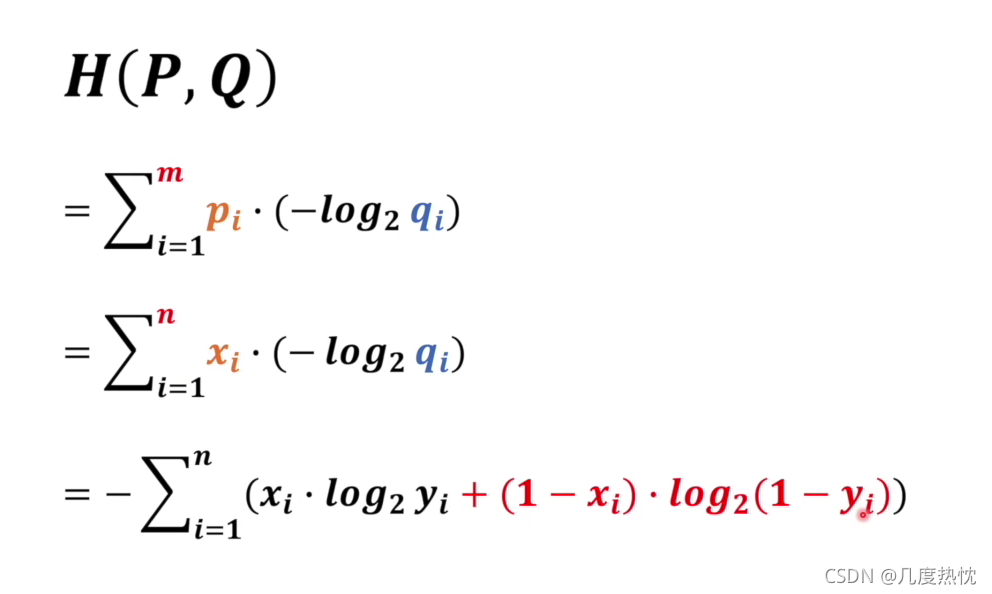
正式公式推导
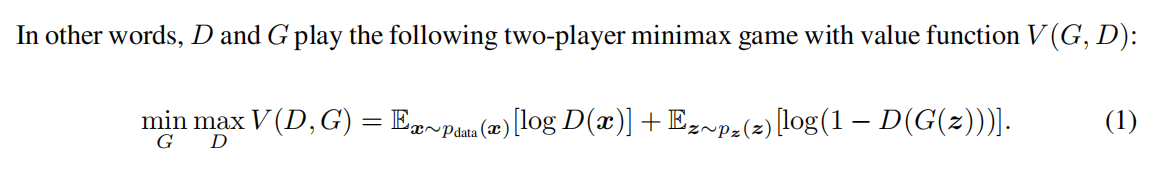

公式中pi和 qi 为真实的样本分布和生成器的生成分布
将上式作为二分类交叉熵展开
注意这里y是标签,D(x)是概率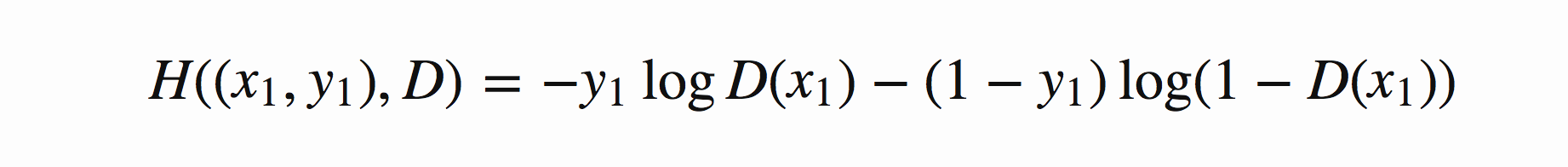

将上式写为期望的形式,同时将yi=1/2,G(z)表示生成样本
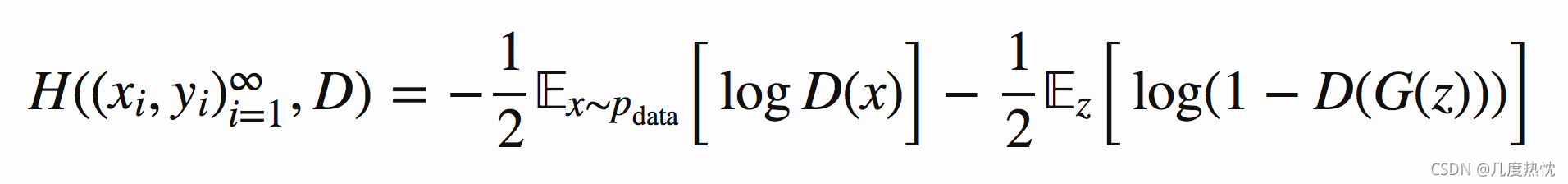
将上式整理可得出下式
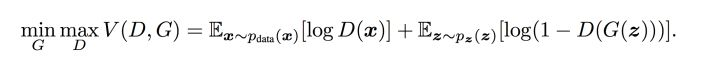

下图是文章中给出的算法流程,有了上面的基础,我们再来理一下

训练流程: 要首先得到一个较好的鉴别器,才能较好的鉴别图像,故先对鉴别器进行k次循环,完成k次优化;之后对生成器进行一次优化。
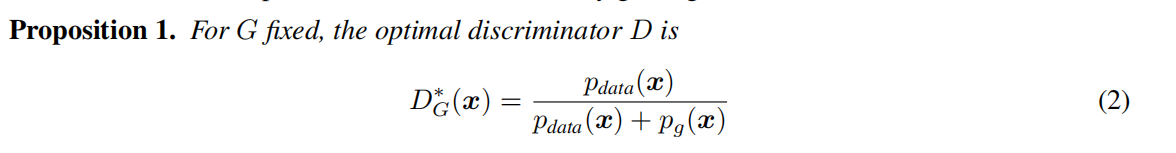
Tips: D(x) 表示 x 来源于真实样本而不是生成样本的概率
上式的意思是 当生成器固定不变,最优的鉴别器为Pdata(x)/[Pdata(x)+Pg(x)]
理解:当生成器G固定时,鉴别器D的作用是使V(G,D)最大,也就是让真实样本和生成样本之间的差异最大,尽最大可能分辨是真实图像还是生成图像。
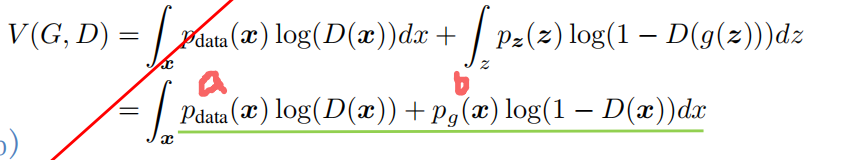
由于期望 E[logP_G(x;θ)] 可以展开为在 x 上的积分形式:∫ P_data(x)logP_G(x;θ)dx
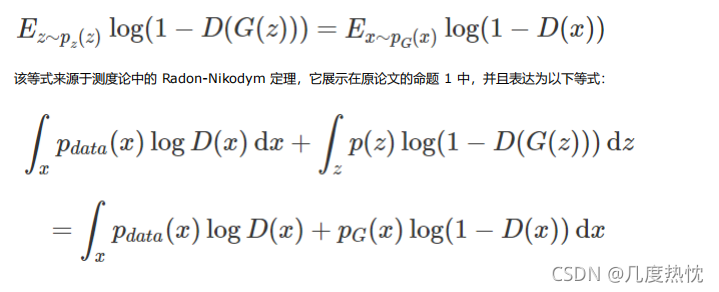
文中将V(G,D)写成了以上形式,并且提到 形如 y→a log(y) + blog(1-y)其最大值对应自变量a/a+b ,而仔细观察上图中的V(G,D)其中Pdata(x)可以看做a Pg(x)可以看做是b 故有G固定时,D极值点为Pdata(x)/[Pdata(x)+Pg(x)]

证明:
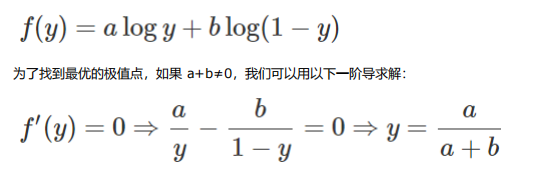

这里的y就是V(G,D)中的D(x),因此D(x)的最优值为Pdata(x)/[Pdata(x)+Pg(x)]
将最优的D代入V(G,D)

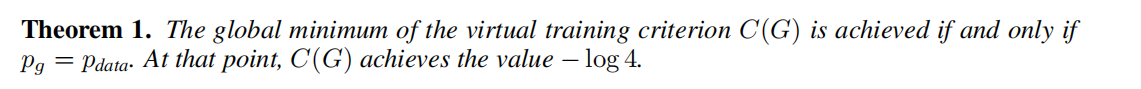
当且仅当 P_G=P_data,训练标准 C(G)=maxV(G,D) 的全局最小点可以达到 等于-log4。
当分布Pdata与Pg很接近时,D(x)=D(G(z))=1/2,既两个分布之间的差异V(G,D)最小 等于-log4
当分布Pdata与Pg相差较大时,D(x)=1,D(G(z))=0,两个分布之间的差异V(G,D)最大,等于0
证明:
放弃 Pg=Pdata 的假设,对任意一个 G,我们可以将上一步求出的最优判别器 D*g 代入到 C(G)=maxV(G,D) 中:
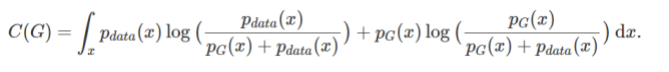
已知-log4=-2log2为全局最小值,在上式中构造含有log2 但不改变值的等式
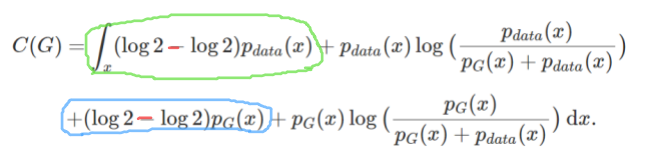
通过化简,构造log2和JS散度的等式
Tips:补充JS散度相关知识
JS散度度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间。
loga+logb=log(ab)

通过化简,将原式写为以下形式
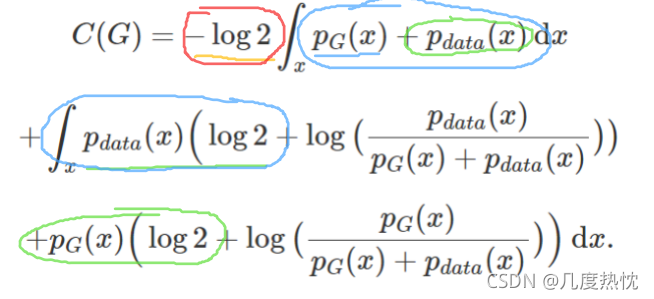

再次给出KL散度的定义
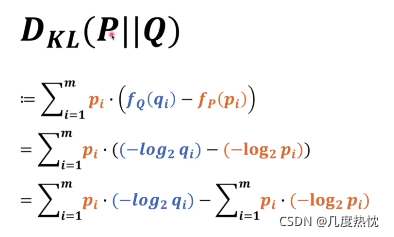


参考文章:
机器之心GitHub项目:GAN完整理论推导与实现,Perfect!
通俗理解生成对抗网络GAN
“交叉熵”如何做损失函数?打包理解“信息量”、“比特”、“熵”、“KL散度”、“交叉熵”




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











