







前言
通常,通过基于规则的方法来开发游戏的人工智能。但是,规则在开发、修改和调试的过程是不稳定、昂贵和费时的,并经常导致游戏出现非智能的行为。本文讨论一种新的游戏智能开发方法:基于游戏世界模型的方法——行动、效果和观察。基于模型的方法更稳定,更省时也更经济,并且非常已与修改,这也使游戏所表现的行为更加智能化。
引言
现在的计算机游戏通过综合图形、物理和人工智能的方法来达到游戏的真实感。这通常是指游戏的沉浸感以及游戏中出现的非玩家角色的智能性。在真实感游戏中,游戏中对象的外观和行为与现实中对象的外观和行为非常相似,并且非玩家角色的行为也合乎逻辑。游戏人工智能的目标不是创造一个不可打败的对手,而是通过非玩家角色的智能行为来创造更富有沉浸性更有趣的游戏体验。
目前的游戏人工智能:基于规则
目前的游戏人工智能主要是基于规则的。规则的形式是条件->行动。当条件被满足时,行动就被执行。
判断规则条件是否符合的方法可以有很大的不同。它可以是决策树形式。如下图,这棵决策树包含了条件和与之对应的一组操作。树的非叶子节点对应着当前情况下的一个判断,而叶子节点表示行为。
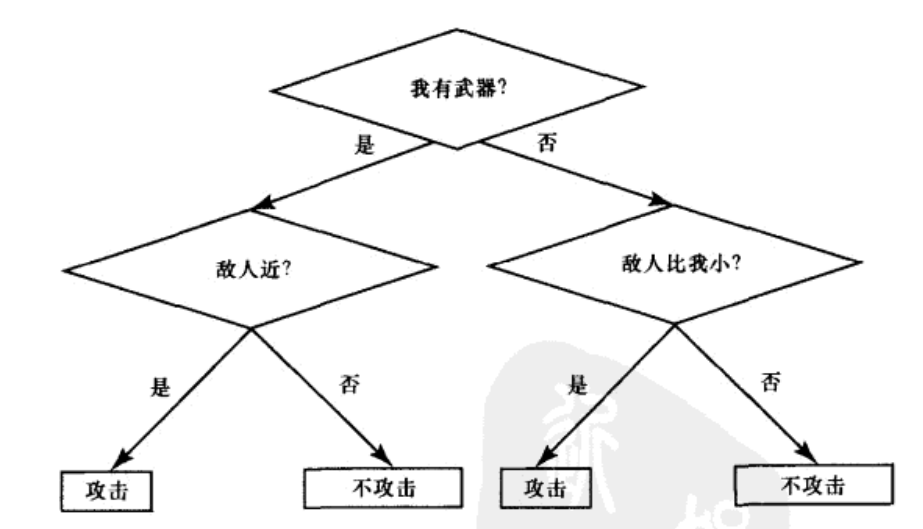
一个简单的决策树
每一条从树根到树叶的路径都代表着一个符合条件->行动形式的规则,路径中的非叶子节点代表一组条件,而路径终点的叶子节点代表行动。尽管决策树能够更加紧凑地归类规则,同时也比一组规则要好维护,但从决策能力来说,他们和标准的规则是等价的。
另一个编码一组规则的方法是有限状态机。一个有限状态机包含一组开发人员定义的状态,这些状态对应着特定的行动。状态间的连线表示状态判断,并且使得状态从一个过渡到另一个。例如下图:

一个典型的有限状态机
与决策树相比,有限状态机相当于一组带标记的规则。标记和状态相对应,标记设置在一个规则的行动部分,也执行相关的行动。尽管有限状态机决策能力并不比标准规则高,然后它在一定程度上更容易维护,因为它并不需要显式地维护标记和其对应的相关状态。
还有一些其他方法也可以编码规则。模糊逻辑可以用来判断条件满足的概率。类似地,神经网络判断条件满足的方法就更加复杂,但是它们的确可以用来编码规则。和标准规则相比,这些方法使得我们可以以更紧凑地方式来表达一个特定的条件。它们也使得通过案例来了解规则成为可能。专家系统包含一系列的规则和一个内置的规则解释器。这个解释器可以添加它自己的内部符号,这样就可以进行更加复杂规则的匹配判断。和其他方法相比,专家系统虽然能有效提高运行时的灵活度,但却相当慢,因此游戏中很少采用。注意:专家系统等价于一组规则,因为解释器可以对其执行的规则进行反向推导:它可以找出对一种情况应用某种规则的最小先决条件,也可以找出一个行动的后续行动。
总而言之,规则可以表现为不同的形式,其中的一些形式比另一些形式要容易修改、维护和理解,但是所有的实现都等价于条件->行动。
规则的缺点
规则经常导致非智能的行为。
规则在度量一个行动的长期后果时存在困难。这是因为有可能需要多个非玩家角色进行前后连续的多个行动后才能发现一开始的行动是错误的。例如:所有玩家都按照最短路径规则靠近目的地,可能导致路径堵塞(所有玩家都走同一条路径)。
规则的开发费时、成本高。
开发者需要透彻地了解游戏,才能找出合适的规则。
基于规则的行为受到游戏开发人员智力的限制。
不通过开发者的艰苦努力,就不会有很好的游戏智能。而且好的开发者不一定总能制作出好的游戏角色。
基于规则的行为会使玩家产生怀疑,因而破坏游戏的沉浸性。
一个游戏是否成功的重要因素是玩家在玩游戏时不产生怀疑。非玩家角色的非理性行为会使玩家产生信任感。非玩家角色越精明反倒会弄巧成拙,这样玩家会时时感受到开发者在背后操纵游戏,这也破坏了沉浸感。
规则是脆弱的,当情况超出规则定义的范围,规则就失效了。
规则难于修改和调试,这导致一种低效的编码-补丁的开发过程。
通常修改一个脆弱不严谨的规则的方法是为了它增加一个例外处理。因此,开发者不得不不断地添加例外代码来处理新出现的情况。
规则永远也没完。
在编码-补丁的过程中添加规则并在不同的条件下测试规则直到它失效,然后再对规则打补丁,以处理使规则失效的特定的情况,这就不可避免地导致了没有完成的人工智能产品(编码-补丁的过程直到开发进度的最后期限还没有完成)。
规则是不可预知的、不稳定的。
反复补丁的规则系统会很迅速地变得不可维护,而且也会变得不可预知。一个没有考虑到的情况可能使系统崩溃,也可能使系统进入死循环或者出现不可预知的奇怪行为。
规则不能适应多非玩家角色的情况。
用规则来控制单个的非玩家角色已经是非常困难了。随着非玩家角色的增加,规则的复杂性和规则失效的可能性就会呈指数级地增加。
基于模型的游戏人工智能方法
按照理性决策模型理论,最好地决策能够最大化预期的结果,这个预期的结果通过计算决策的后续决策序列得到。如下图,它显示了我们可能考虑的两个选择。每一个选择都有两个后续的选择,后续的选择带来结果。图中的结点代表状态或情况;箭头代表将结果移入新的状态。根节点发出的两个箭头代表当前面临的两个选择,下面的箭头代表未来可能的选择。最优的选择是右侧的,因为它最大化了预期结果。

我们把这种方法叫作基于模型的游戏人工智能。因为它包含着系统动态性的高层次的描述:可以做的行为和行为的结果。基于模型的决策可以总结成如下三步。
1.通过构建一棵前瞻树,模拟每一个决策所带来的后果;
2.评估决策树上每一个决策序列的结果;
3.选择预期结果最好的决策。
注意:不要把游戏规则和游戏智能实现的规则方法混淆。游戏智能实现的规则方法用来规定在一个特定情况下应该执行的行为。而基于模型的实现方法则把在特定情况下可以执行的行为描述为一个模型。我们也可以把基于模型的方法看作是非玩家角色行为的高级特性。
对游戏的接口
典型的基于模型的决策产生系统提供给游戏的接口通常是不同的,但是基本的过程是一样的,例如蝗虫游戏引擎中,接口采用了4个步骤:观察、更新、决策、行动。

对游戏世界的接口
观察涉及到感觉信息的获取。更新是这样一个过程:它利用观察得到的信息来更新关于发生了什么的判断(可以简单理解为更新数据)。在一个行动过程中,决策指的是利用当前获得的判断来选择一个行动过程,按照某种标准,这个行动过程有可能在一定程度上改善角色的处境。行动指的是对环境有效地改变。这个接口模型也假设世界的当前状态是为游戏决策生成系统所知道的。例如,它假设决策系统已经知道了所有非玩家角色的当前位置;更新过程考虑了所有的当前状态变化。
观察->更新->决策->行动的循环是无休止的。虚线指出了接口,它把蝗虫引擎和游戏世界实际发生的观察和行动分割开来。也就是说,蝗虫引擎的内部判断结构和决策制定的过程是和游戏世界分割开来的。实际上,它的内部判断结构一般只是游戏世界的近似,同时,它依赖于游戏世界表示的复杂程度。
实时的决策制定是这个模型的一个重要方面。在任何复杂世界中,预先制定一个行动过程来全面地对世界做出反应是不大可能的,因为世界是不可预知的。
决策和观察的交替进行使得决策所产生的效果可以得到监控,这就使得改变一个行动的过程成为可能。这个模型也允许决策制定模块制定一个详细的计划,但是在大多数应用中,这样的计划因为不可预测性的原因不能完全地应用。每一个决策制定模块都会使用一个内部的有关游戏世界的判断模型,这个游戏世界是以特定的参数的形式给出,然后这些参数会根据观察到的信息进行更新。
对游戏人工智能开发者的好处与推论
与常规的基于规则的开发方法相比较,基于模型的游戏人工智能开发方法,至少有以下好处:
使行动变得更智能化。
这是因为它考虑了每一个决策对未来所产生的影响。一个为蝗虫引擎所支持的非玩家角色具有符合逻辑始终如一的一组分值,这些分值刻画了该角色要完成什么。非玩家角色的一次次行动最终导致这些分值的完成。蝗虫人工智能引擎无缝地把短期的战术性的决策和长期的战略性的计划结合了起来,并且引擎还会根据环境和状态的变化来平稳地调整目标的优先级。最终的结果是非玩家角色行为更智能化了。简而言之,基于模型的AI系统会遍历整个前者树,计算每种决策结果效益,最后选择效益最好的决策。(根据游戏需要进行选择,如你的AI希望是个“见识短浅”的无名小卒,则只进行第一层的前瞻寻找;如果你的AI希望是个足智多谋的谋士,则需要好好思考进行选择(深层的前瞻寻找、选择);如果你的AI希望成为一个贪小便宜的商贩,则加大浅层前瞻的权重,减小深层决策的影响来模拟这种性格······)
减少了开发的时间和成本。
用蝗虫游戏引擎的方法,模型可以迅速并相对廉价地建立起来,这个建立过程不需要非常专门的技术和经验。所有需要的仅是行为的描述、行为的效果、行为的效果以及观察是如何与状态相联系的描述。
带来自然的智能行为。
这指的是非玩家角色能够显示出不是游戏开发人员在一开始就设计好智能行为。
创造更好的沉浸性
当非玩家像玩家一样地行动时,真实感就得到了延续。更智能化的行为戏剧性地提高了玩家在游戏中得到的愉悦感。
更稳定可靠。
前瞻比规则更稳定可靠,因为它总是针对情况的,同时也是针对一般目标的。当做一个决策时,蝗虫引擎考虑所有的因素,它总是在给定时间范围内返回一个最好决策。时间越多,返回的决策越好(更多关于决策对未来的影响都被考虑到)。蝗虫引擎也能处理复杂地形,它能够自动创建分级的路径点。
可以应用到多个非玩家角色上。
蝗虫引擎的前瞻算法基于分布式决策技术(可以简单理解为并行计算),这减少了在传统的多个非玩家情况下遇到的问题:分支因素的指数性增长。引擎也可以安装到一个网络的不同机器上(如一台服务器,有多台子计算机分担计算任务)。
使得修改和除错更容易。
如果其他的一些因素需要在非玩家角色的行为过程中被考虑进来,它们可以相对简单地添加。蝗虫引擎更简单并且技术是上下文无关的,这使得维护更容易且查错更迅速。添加和改变行为仅是一个简单的修改非玩家角色的模拟和目标的问题。通过基于模拟的前瞻技术,蝗虫引擎避开了基于规则的实现方法导致的像意大利面条一样的代码。简言之,当模型改变时,由模型导致的决策也就改变了,没有更多的工作要做。
使得特性的移植成为可能。
当一个模型在一个非玩家角色上建立起来,它就能够容易地被移植到一个完全不同的游戏中。就蝗虫引擎而言,我们可以基于角色的行为特点而不是角色的外观实现来建立一个角色库。
可以带来更大的产品规则。
相比基于规则的实现方法,基于模型的实现方法给开发者带来如下优点:开发者可以在较长时间赋予一小群完全独立行动的角色高级行动,设计者也可以控制一大群简单角色在较短时间进行一个低级的联合系统。蝗虫引擎基于模型的控制也可以用来控制低级的移动。群聚和拥挤行为在蝗虫引擎中是最简单的特性,并且这个特性完全是嵌入在目标描述中,而不是在控制规则中。因此,群聚行为是自然发生的而不是预先设计的。
和基于规则的实现方法相比,基于模型的实现方法有两点不足:第一,它需要建立模型。然而,建立模型比建立一组规则要容易,并且也有可能通过交互来建立一个模型(可视化开发功能组件,如果可能的话)。第二,创建前瞻树可能比处理规则要慢。但是,花更多时间得到一个更好的决策时值得的。蝗虫引擎在数毫秒内就可以为多个非玩家角色做出决策。这为游戏的实时响应和变化提供了足够的时间,同时也展示了游戏的智能。
相关工作
Soar的独特性在于它使用规则来进行决策,并且也使用了后向链和子计分来解决前进过程中的僵局以及在有竞争关系的规则中做出选择。因为Soar是一个认知框架,它也包含了人类的记忆模型。相对而言,我们的游戏智能的实现方法更多地关注了性能而不是人类的认知模型。
学习资源
-
- 《游戏编程精粹6》第三章第一节
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









