







1.已知用户好友关系(平均100个好友),设计查看和另一个用户是几度人脉的功能?
在社交网络中,有一个六度分割理论,具体是说,你与世界上的另一个人间隔的关系不会超过六度,也就是说平均只需要六步就可以联系到任何两个互不相识的人。
说明:
一度:A<->B :A和B是直接好友,此时A和B是一度好友
二度:A<->B<->C,A和B是好友,B和C是好友,所以A和C是两度好友
以此类推
思路1:
建立一张用户关系表:(key:维护用户的ID,value维护用户的好友ID集合set)
一度:A<->B , 直接查询用户关系表(可以用缓存优化,key:用户id,value:用户的好友set)
二度:A<->B<->C,首先排除一度的情况,然后拿A的好友和C的好友,两个集合取交集
三度:A<->B<->C<->D,拿A的二度好友(提前计算好的),和D的一度好友,取交集
四度及以上的:显示三度+
思路2:图计算(最短路径)(面试官可能追问图计算怎么实现)
两种算法参考:
(深度优先搜索算法和广度优先搜索算法都是基于“图”数据结构)
1.深度优先搜索算法
2.广度优先搜索算法
2.基于redis设计限流器
需求:限定用户的某个行为在指定时间T内,只允许发生N次。假设T为1秒钟,N为1000次。
思路1:利用 zset实现滑动窗口限流的代码(防止流量突增)
以限制用户行为为例子,比如一秒内进行某个操作50次,这种行为应该进行限制
滑动窗口就是记录一个滑动的时间窗口内的操作次数,操作次数超过阈值则进行限流
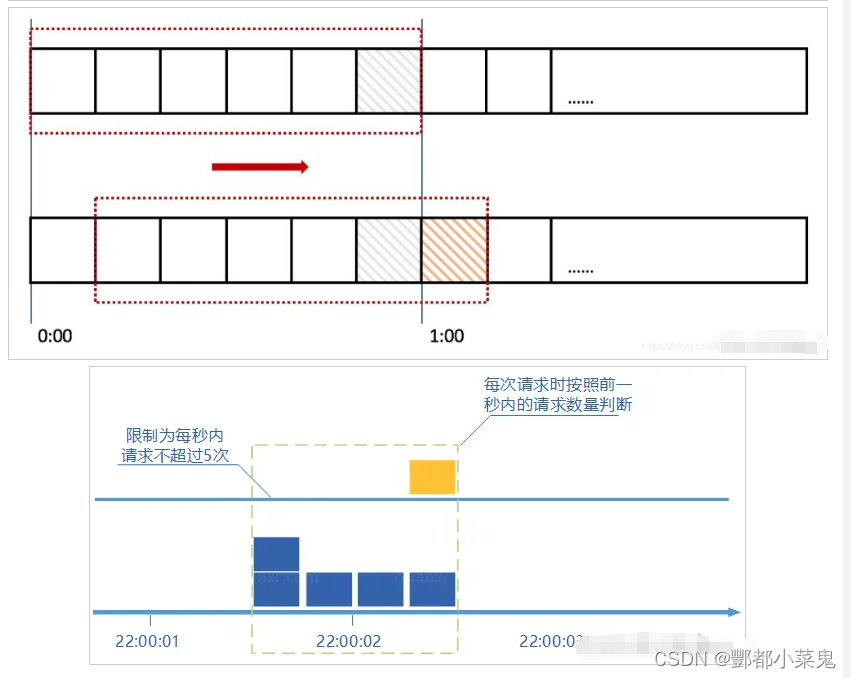
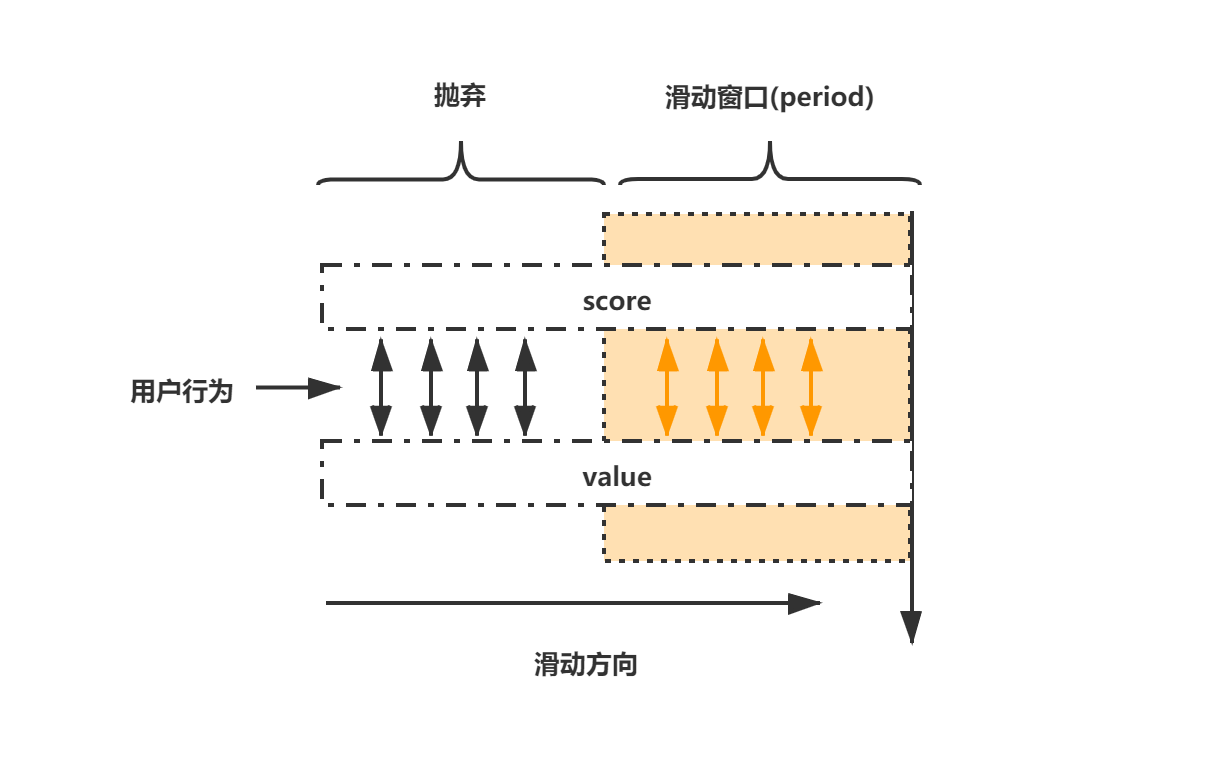
在实际操作zset的过程中,只需要保留在这个滑动时间窗口以内的数据,其他的数据不处理即可。
- 每个用户的行为采用一个zset存储,score为毫秒时间戳,value也使用毫秒时间戳(比UUID更加节省内存)
- 只保留滑动窗口时间内的行为记录,如果zset为空,则移除zset,不再占用内存(节省内存)
Lua脚本实现:
var counterLuaScript = `
-- 记录行为
redis.pcall("zadd", KEYS[1], ARGV[1], ARGV[1]); -- value 和 score 都使用纳秒时间戳,即ARGV[1]
redis.pcall("zremrangebyscore", KEYS[1], 0, ARGV[2]); -- 移除时间窗口之前的行为记录,剩下的都是时间窗口内的
local count = redis.pcall("zcard", KEYS[1]); -- 获取窗口内的行为数量
redis.pcall("expire", KEYS[1], ARGV[3]); -- 设置 zset 过期时间,避免冷用户持续占用内存
return count -- 返回窗口内行为数量`JAVA代码实现:
/**
* redis使用zset实现滑动窗口计数
* key:sliding_window_用户登录名
* value(zset):value=当前时间戳,score=当前时间戳
*
*/
@Component
@Slf4j
public class SlidingWindowCounter {
/**
* redis key前缀
*/
private static final String SLIDING_WINDOW = "sliding_window_";
@Autowired
private RedisTemplate redisTemplate;
* 判断key的value中的有效访问次数是否超过最大限定值maxCount
* 判断与数量增长分开处理
*
* @param key redis key
* @param windowInSecond 窗口间隔,秒
* @param maxCount 最大计数
* @return 是 or 否
public boolean overMaxCount(String key, int windowInSecond, long maxCount) {
key = SLIDING_WINDOW + key;
log.info("redis key = {}", key);
// 当前时间
long currentMs = System.currentTimeMillis();
// 窗口开始时间
long windowStartMs = currentMs - windowInSecond * 1000L;
// 按score统计key的value中的有效数量
Long count = redisTemplate.opsForZSet().count(key, windowStartMs, currentMs);
// 已访问次数 >= 最大可访问值
return count >= maxCount;
}
* 判断key的value中的有效访问次数是否超过最大限定值maxCount,若没超过,调用increment方法,将窗口内的访问数加一
* 判断与数量增长同步处理
* @return 可访问 or 不可访问
public boolean canAccess(String key, int windowInSecond, long maxCount) {
//按key统计集合中的有效数量
Long count = redisTemplate.opsForZSet().zCard(key);
if (count < maxCount) {
increment(key, windowInSecond);
return true;
} else {
return false;
}
* 滑动窗口计数增长
public void increment(String key, Integer windowInSecond) {
long windowStartMs = currentMs - windowInSecond * 1000;
// 单例模式(提升性能)
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
// 清除窗口过期成员
zSetOperations.removeRangeByScore(key, 0, windowStartMs);
// 添加当前时间 value=当前时间戳 score=当前时间戳
zSetOperations.add(key, String.valueOf(currentMs), currentMs);
// 设置key过期时间
redisTemplate.expire(key, windowInSecond, TimeUnit.SECONDS);思路2:令牌桶:计数器,定时往桶里加元素,借助lua脚本判断桶是否满了,取令牌也用lua、
public Map<string, object=""> startLingpaitong(Map<string, object=""> paramMap) {
String redisKey = "lingpaitong";
String token = redisTemplate.opsForList().leftPop(redisKey).toString();
//正常情况需要验证是否合法,防止篡改
if (StringUtils.isEmpty(token)) {
throw new RuntimeException("令牌桶拒绝");
}
Map<string, object=""> map = new HashMap<>();
map.put("success", "success");
return map;
}
@Scheduled(cron="*/1 * * * * ?")
private void process(){
//一次性生产两个
System.out.println("正在消费。。。。。。");
for (int i = 0; i < 2; i++) {
redisTemplate.opsForList().rightPush(redisKey, i);
}
}3.10亿数组去重排序
思路1:分而治之
借助hash算法思想,把一个大文件哈希分割到多个小文件中,而哈希冲突的数字
一定会在同一个小文件中,从而保证了子问题的独立性,然后就可以单独对小文件通过快速排序来去重。
这样就通过分而治之解决了几G数据进行内排序的问题。
虽然哈希分割文件是O(n)的时间复杂度,但总的效率仍是依从快速排序的时间复杂度O(n*logn)。
分而治之有个好处就是借助子问题的独立性可以利用多核来做并行处理,甚至做分布式处理。
思路2:位图bitMap
1G内存可以放多大范围的数据?1GB=10亿字节=80亿bit
如果超过了?用两个bitmap,两个不够用3个,处理完再做合并
bitmap:数据范围已知,并且内存放得下
bitMap介绍:
BitMap,即位图,使用每个位表示某种状态,适合处理整型的海量数据。本质上是哈希表的一种应用实现,原理也很简单,给定一个int整型数据,将该int整数映射到对应的位上,并将该位由0改为1。例如:
// 存在一个int整型数组
int[] arr = new int[]{6,2,7,14,3};arr数组中最大值为14,考虑位的下标从0开始,需要长度为15的bit,因此每个bit代表着0~14的整数,如图所示:

很显然,使用 BitMap 存储这个数组只使用了使用15bit,而使用 HashSet 或 HashMap 的话,一个数组元素会存储为一个int,而一个int占4个byte,即4*8=32bit,这里有5个数组元素则需要5*32=160bit,这样的话,使用 BitMap 存储一个元素则可以节省32倍的内存空间。因此,BitMap 的优势就不言而喻了。
结构决定功能,BitMap非常适合对整型的海量数据进行查询统计、排序、去重;适合对两个集合做交集、并集运算,但不支持非运算,如果需要进行非运算则需要提供一个全量的BitMap才行。
4.100万考生,高考排名怎么做?
思路1:计数排序
假设最高分是700
700,699,698.。。500。。。。4,3,2,1,0
每个分数一个bucket,然后存储分数对应的学生数量
假设我是600分,就统计大于600分的人数总和,600分的排名就是人数总和的后一名
5.游戏top实时排行榜
需求:实时获取游戏等级前100名的用户ID,并进行排序
思路1:小顶堆
6.多租户场景下,分表按照companyId分,会有每张表数据不均匀的情况,怎么处理?
从业务入手,可以建立vip库,分等级,不同级别有不同的维护策略
7.设计微信摇一摇功能(设计微信附近的人功能)
思路1:Geohash
















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











