







文章目录:
-
面试时回答系统设计题的思路
-
系统的一些性能指标
-
经典系统设计题与思路
-
分布式ID生成器
-
短网址系统
-
定时任务调度器
-
最近一个小时内访问频率最高的10个IP
-
key-Value存储引擎
-
Manifest文件
-
Log文件
-
数据流采样
-
基数估计
-
频率估计
-
Top k频繁项
-
范围查询
-
成员查询
-
面试时回答系统设计题的思路
这部分内容主要参考了Github的一个国外的开源项目,写的很好,感兴趣的小伙伴可以去看看:https://github.com/donnemartin/system-design-primer
常见的系统设计题有设计一个秒杀系统、红包雨、URL短网址等,完成一个系统设计题大概需要分为四步。
需要注意的是,在面试过程中是比较紧张的,但遇到这种系统设计题,一定先不要急着回答,一定要先需要设计系统的一些使用场景。
-
第一步:像面试官不断提问,搞清楚系统的使用场景
-
系统的功能是什么
-
系统的目标群体是什么
-
系统的用户量有多大
-
希望每秒钟处理多少请求?
-
希望处理多少数据?
-
希望的读写比率?
-
-
第二步:创造一个高层级的设计
-
画出主要的组件和连接
例如设计一个网络爬虫,这个是个完整的架构图,在这一步只需要画出一个抽象的架构图即可,不需要这么具体。
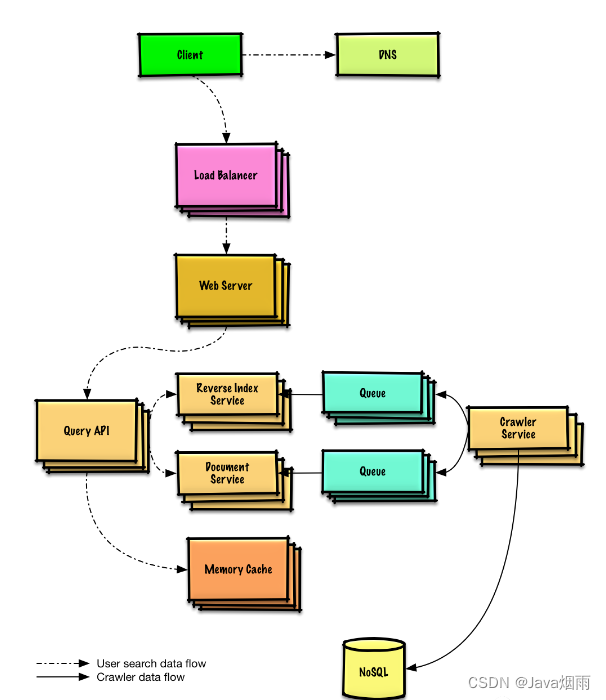
-
-
设计核心组件
对每一个核心组件进行具体地分析。例如,面试官让你设计一个url短网址,你需要考虑这些问题
-
数据库查找
-
MD5和 Base62
-
Hash 碰撞
-
SQL 还是 NoSQL
-
数据库模型
-
生成并储存一个完整 url 的 hash
-
将一个 hashed url 翻译成完整的 url
-
API 和面向对象设计
-
-
对系统进行优化
找到系统的瓶颈所在,对其进行优化,例如可以考虑水平扩展、数据库分片等等。
系统的一些性能指标
-
响应时间
响应时间指从发出请求开始到收到最后响应数据所需的时间,响应时间是系统最重要的性能指标其直观地反映了系统的“快慢”。
-
并发数
并发数指系统能够同时处理请求的数目,这个数字反映了系统的负载特性。
-
吞吐量
吞吐量指单位时间内系统处理的请求数量,体现系统的整体处理能力。
QPS(Query Per Second):服务器每秒可以执行的查询次数
TPS(Transaction Per Second):服务器每秒处理的事务数
并发数=QPS*平均响应时间
-
经常听到的一些系统活跃度的名词
-
PV(Page View)
页面点击量或者浏览量,用户每次对网站中的每个页面访问均被记录一个PV,多次访问则会累计。
-
UV(Unique visitor)
独立访客,统计一天内访问网站的用户数,一个用户多次访问网站算一个用户
-
IP(Internet Protocol)
指一天内访问某站点的IP总数,以用户的IP地址作为统计的指标,相同IP多次访问某站点算一次
IP和UV的区别:
在同一个IP地址下,两个不同的账号访问同一个站点,UV算两次,IP算一次
-
DAU(Daily Active User):日活跃用户数量。
-
MAU(monthly active users):月活跃用户人数。
-
-
常用软件的QPS
通过了解这些软件的QPS可以更清楚地找出系统的瓶颈所在。
-
Nginx:一般Nginx的QPS是比较大的,单机的可达到30万
-
MySQL:对于读操作可达几百k,对于写操作更低,大概只有100k
-
Redis:大概在几万左右,像set命令甚至可达10万
-
Tomcat:单机 Tomcat 的QPS 在 2万左右。
-
Memcached:大概在几十万左右
-
经典系统设计题与思路
这里列举了一些比较经典的系统设计题,并给出了解题思路,该部分内容来源于Gitbook,链接:https://github.com/donnemartin/system-design-primer
分布式ID生成器
如何设计一个分布式ID生成器(Distributed ID Generator),并保证ID按时间粗略有序?
应用场景(Scenario)
现实中很多业务都有生成唯一ID的需求,例如:
-
用户ID
-
微博ID
-
聊天消息ID
-
帖子ID
-
订单ID
需求(Needs)
这个ID往往会作为数据库主键,所以需要保证全局唯一。数据库会在这个字段上建立聚集索引(Clustered Index,参考 MySQL InnoDB),即该字段会影响各条数据再物理存储上的顺序。
ID还要尽可能短,节省内存,让数据库索引效率更高。基本上64位整数能够满足绝大多数的场景,但是如果能做到比64位更短那就更好了。需要根据具体业务进行分析,预估出ID的最大值,这个最大值通常比64位整数的上限小很多,于是我们可以用更少的bit表示这个ID。
查询的时候,往往有分页或者排序的需求,所以需要给每条数据添加一个时间字段,并在其上建立普通索引(Secondary Index)。但是普通索引的访问效率比聚集索引慢,如果能够让ID按照时间粗略有序,则可以省去这个时间字段。为什么不是按照时间精确有序呢?因为按照时间精确有序是做不到的,除非用一个单机算法,在分布式场景下做到精确有序性能一般很差。
这就引出了ID生成的三大核心需求:
-
全局唯一(unique)
-
按照时间粗略有序(sortable by time)
-
尽可能短
下面介绍一些常用的生成ID的方法。
UUID
用过MongoDB的人会知道,MongoDB会自动给每一条数据赋予一个唯一的ObjectId,保证不会重复,这是怎么做到的呢?实际上它用的是一种UUID算法,生成的ObjectId占12个字节,由以下几个部分组成,
-
4个字节表示的Unix timestamp,
-
3个字节表示的机器的ID
-
2个字节表示的进程ID
-
3个字节表示的计数器
UUID是一类算法的统称,具体有不同的实现。UUID的优点是每台机器可以独立产生ID,理论上保证不会重复,所以天然是分布式的,缺点是生成的ID太长,不仅占用内存,而且索引查询效率低。
多台MySQL服务器
既然MySQL可以产生自增ID,那么用多台MySQL服务器,能否组成一个高性能的分布式发号器呢?显然可以。
假设用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,依次类推。前面用一个 round-robin load balancer 挡着,每来一个请求,由 round-robin balancer 随机地将请求发给8台MySQL中的任意一个,然后返回一个ID。
Flickr就是这么做的,仅仅使用了两台MySQL服务器。可见这个方法虽然简单无脑,但是性能足够好。不过要注意,在MySQL中,不需要把所有ID都存下来,每台机器只需要存一个MAX_ID就可以了。这需要用到MySQL的一个REPLACE INTO特性。
这个方法跟单台数据库比,缺点是ID是不是严格递增的,只是粗略递增的。不过这个问题不大,我们的目标是粗略有序,不需要严格递增。
Twitter Snowflake
比如 Twitter 有个成熟的开源项目,就是专门生成ID的,Twitter Snowflake 。Snowflake的核心算法如下:

最高位不用,永远为0,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
Instagram用了类似的方案,41位表示时间戳,13位表示shard Id(一个shard Id对应一台PostgreSQL机器),最低10位表示自增ID,怎么样,跟Snowflake的设计非常类似吧。这个方案用一个PostgreSQL集群代替了Twitter Snowflake 集群,优点是利用了现成的PostgreSQL,容易懂,维护方便。
有的面试官会问,如何让ID可以粗略的按照时间排序?上面的这种格式的ID,含有时间戳,且在高位,恰好满足要求。如果面试官又问,如何保证ID严格有序呢?在分布式这个场景下,是做不到的,要想高性能,只能做到粗略有序,无法保证严格有序。
短网址系统
如何设计一个短网址服务(TinyURL)?
使用场景(Scenario)
微博和Twitter都有140字数的限制,如果分享一个长网址,很容易就超出限制,发布出去。短网址服务可以把一个长网址变成短网址,方便在社交网络上传播。
需求(Needs)
很显然,要尽可能的短。长度设计为多少才合适呢?
短网址的长度
当前互联网上的网页总数大概是 45亿(参考 http://www.worldwidewebsize.com),45亿超过了 2^{32}=4294967296232=4294967296,但远远小于64位整数的上限值,那么用一个64位整数足够了。
微博的短网址服务用的是长度为7的字符串,这个字符串可以看做是62进制的数,那么最大能表示{62}^7=3521614606208627=3521614606208个网址,远远大于45亿。所以长度为7就足够了。
一个64位整数如何转化为字符串呢?,假设我们只是用大小写字母加数字,那么可以看做是62进制数,log_{62} {(2^{64}-1)}=10.7log62(264−1)=10.7,即字符串最长11就足够了。
实际生产中,还可以再短一点,比如新浪微博采用的长度就是7,因为 62^7=3521614606208627=3521614606208,这个量级远远超过互联网上的URL总数了,绝对够用了。
现代的web服务器(例如Apache, Nginx)大部分都区分URL里的大小写了,所以用大小写字母来区分不同的URL是没问题的。
因此,正确答案:长度不超过7的字符串,由大小写字母加数字共62个字母组成
一对一还是一对多映射?
一个长网址,对应一个短网址,还是可以对应多个短网址?这也是个重大选择问题
一般而言,一个长网址,在不同的地点,不同的用户等情况下,生成的短网址应该不一样,这样,在后端数据库中,可以更好的进行数据分析。如果一个长网址与一个短网址一一对应,那么在数据库中,仅有一行数据,无法区分不同的来源,就无法做数据分析了。
以这个7位长度的短网址作为唯一ID,这个ID下可以挂各种信息,比如生成该网址的用户名,所在网站,HTTP头部的 User Agent等信息,收集了这些信息,才有可能在后面做大数据分析,挖掘数据的价值。短网址服务商的一大盈利来源就是这些数据。
正确答案:一对多
如何计算短网址
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









