







| Patient | Headache | Temperature | Lymphocyte | Leukocyte | Eosinophil | Heartbeat | Flu |
|---|---|---|---|---|---|---|---|
| x 1 x_1 x1 | Yes | High | High | High | High | Normal | Yes |
| x 2 x_2 x2 | Yes | High | Normal | High | High | Abnormal | Yes |
| x 3 x_3 x3 | Yes | High | Highl | High | Normal | Abnormal | Yes |
| x 4 x_4 x4 | No | High | Normal | Normal | Normal | Normal | Yes |
| x 5 x_5 x5 | Yes | Normal | Normal | Low | High | Abnormal | Yes |
| x 6 x_6 x6 | Yes | Normal | Low | High | Normal | Abnormal | Yes |
| x 7 x_7 x7 | Yes | Low | Low | High | Normal | Normal | Yes |
写出本例中的 U , C , D \mathbf{U}, \mathbf{C}, \mathbf{D} U,C,D 和 V \mathbf{V} V. 注:
最后两个属性为决策属性. I I I 是怎么表示的?
14.5 作业
定义一个标签分布系统, 即各标签的值不是 0/1, 而是 [0,1] 区间的实数, 且同一对象的标签和为 1.
首先解释一下分布系统,即满足概率分布,也就是说这个系统同一对象的所有决策标签的和要为 1. 根据这个想法写一下定义:
A multi-label distribution system is a tuple
S
=
(
X
,
Y
)
S = (\mathbf{X}, \mathbf{Y})
S=(X,Y) where
X
=
[
x
i
j
]
n
×
m
∈
R
n
×
m
\mathbf{X} = [x_{ij}]_ {n \times m} \in \mathbb{R}^{ n \times m }
X=[xij]n×m∈Rn×m is the data matrix,
Y
\mathbf{Y}
Y is the label array, and
∀
y
i
k
∈
[
0
,
1
]
,
∃
∑
k
=
1
l
y
i
k
=
1
s
t
.
Y
=
[
y
i
k
]
n
×
l
∈
[
0
,
1
]
n
×
l
\forall y_{ik} \in [0, 1], \exist \sum_{k=1}^{l}y_{ik} = 1 st. \mathbf{Y} = [y_{ik}]_{n \times l} \in [0, 1]^{n \times l}
∀yik∈[0,1],∃∑k=1lyik=1st.Y=[yik]n×l∈[0,1]n×l,
n
n
n is the number of instances,
m
m
m is the number of features.
15.3 作业
找一篇你们小组的论文来详细分析数学表达式, 包括其涵义, 规范, 优点和缺点.
感恩老师分享了她的论文给我们做表达式分析的范本~~ 【Noise label learning through label confidence statistical inference】
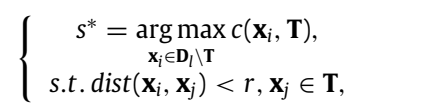
首先,
x
i
∈
D
l
∖
T
\mathbf{x}_i \in \mathbf{D}_l \setminus \mathbf{T}
xi∈Dl∖T 说明对象
x
i
\mathbf{x_i}
xi 是训练数据集
D
l
\mathbf{D}_l
Dl 减去已知对象集合
T
\mathbf{T}
T 所表示的集合中的某个元素.
c
c
c 表示为置信度的函数关系 (the instance confidence function. 不知道具体是不是这么翻译的~ ),
c
:
D
l
∖
A
×
2
A
→
[
0
,
1
]
c : \mathbf{D}_l \setminus \mathbf{A} \times 2^{\mathbf{A}} \to [0, 1]
c:Dl∖A×2A→[0,1], 这个函数关系我理解为是将除了
A
×
2
A
\mathbf{A} \times 2^{\mathbf{A}}
A×2A 的训练数据集
D
l
\mathbf{D}_l
Dl 映射到 0 到 1 的范围里, 这里的
A
×
2
A
\mathbf{A} \times 2^{\mathbf{A}}
A×2A,一个对象集合
A
\mathbf{A}
A 与它的幂集
2
A
2^{\mathbf{A}}
2A 进行一个笛卡尔积,我不知道到底该怎么解释。 总之这里的
c
(
x
i
,
T
)
c(\mathbf{x}_i, \mathbf{T})
c(xi,T) 表示
x
i
\mathbf{x}_i
xi 相对于
T
⊆
A
\mathbf{T} \subseteq \mathbf{A}
T⊆A 的置信度.
d
i
s
t
(
x
i
,
x
j
)
dist (\mathbf{x}_i, \mathbf{x}_j)
dist(xi,xj) 表示为
x
i
,
x
j
\mathbf{x}_i, \mathbf{x}_j
xi,xj 之间的距离,
r
r
r 表示这个对象的邻域半径。
s
∗
s^*
s∗ 就是置信度函数
c
(
x
i
,
T
)
c(\mathbf{x}_i, \mathbf{T})
c(xi,T) 在
x
i
∈
D
l
∖
T
\mathbf{x}_i \in \mathbf{D}_l \setminus \mathbf{T}
xi∈Dl∖T 的情况下,取到最大值时的参数。
这个参数
s
∗
s*
s∗ 使得
x
i
,
x
j
\mathbf{x}_i, \mathbf{x}_j
xi,xj 之间的距离要小于邻域半径
r
r
r 。
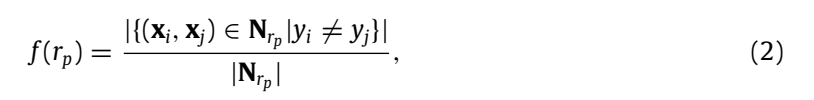
r
p
r_p
rp 为实例对的邻域半径,
N
r
p
\mathbf{N}_{r_p}
Nrp 表示为相对于
r
p
r_p
rp 的实例对邻居,也就是说,
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 之间的距离要小于等于邻域半径
r
p
r_p
rp, 在这个条件下对
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 取样。
y
i
y_i
yi 和
y
j
y_j
yj 表示为
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 的类标签。
f
(
r
p
)
f(r_p)
f(rp) 是实例对标签不一致性统计函数。在函数中表示为,满足实例对类标签不同的情况下的实例对
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 的个数与所有实例对邻居的比值。
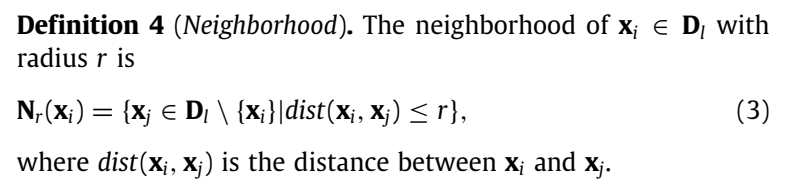
N
r
(
x
i
)
\mathbf{N}_r(\mathbf{x}_i)
Nr(xi) 表示为半径为
r
r
r 的包含在训练数据集中的样本
x
i
\mathbf{x}_i
xi 的邻域。
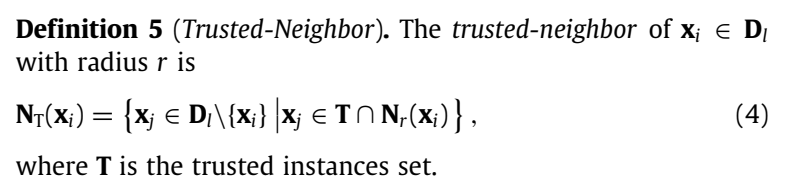
N
T
(
x
i
)
\mathbf{N}_T(\mathbf{x}_i)
NT(xi) 表示为半径为
r
r
r 的包含在训练数据集中的样本
x
i
\mathbf{x}_i
xi 的可信邻域。
x
j
\mathbf{x}_j
xj 既是可信实例集合中的样本, 又是样本
x
i
\mathbf{x}_i
xi 的邻域。

对于要预测的实例
x
i
\mathbf{x}_i
xi,当且仅当
x
j
\mathbf{x}_j
xj 是可信邻域
N
T
(
x
i
)
\mathbf{N}_T(\mathbf{x}_i)
NT(xi) 中的样本,
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 之间的距离取得最大值时,参数值
x
j
\mathbf{x}_j
xj 被称为最近的可信邻域。
这里有一个问题,
x
i
\mathbf{x}_i
xi 之类的样本不是独立集合而且集合中的一个元素,为什么要加粗呢?不知道是我理解的问题还是一些瑕疵?
暂且先写到这些,后面还有一些式子稍微有点难度,慢慢再看~















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









