







 本文详细分析了Linux内核从start_kernel函数开始的启动流程,包括init_task的创建、各系统模块的初始化,如trap_init、mm_init、sched_init等。通过kernel_thread函数启动了1号进程init,以及2号进程kthreadd,最终0号进程转化为idle进程。文章还介绍了0号进程和1号进程的角色和功能,提供了参考资料以深入理解内核启动的复杂性。
本文详细分析了Linux内核从start_kernel函数开始的启动流程,包括init_task的创建、各系统模块的初始化,如trap_init、mm_init、sched_init等。通过kernel_thread函数启动了1号进程init,以及2号进程kthreadd,最终0号进程转化为idle进程。文章还介绍了0号进程和1号进程的角色和功能,提供了参考资料以深入理解内核启动的复杂性。
作者:Sandy 原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ”
实验环境:c+Linux64位 (32位系统可能结果会不同)
依照学术诚信条款,我保证此回答为本人原创,所有回答中引用的外部材料已经做了出处标记。
实验环境:ubuntu14.04操作系统,x86体系结构
实验要求:使用gdb跟踪调试内核从start_kernel到init进程启动
第一步,Linux内核代码结构
本课程提供了一个Linux的内核源码,其结构如下图:
不同的文件夹代表了内核的不同模块,其含义是:
- arch/ 是体系结构相关的代码,其中的/x86 文件夹下的内容是x86体系结构相关代码,是内核分析的重要分析目标。
- init/ 是内核启动相关的代码,是本文的重点分析对象。/init/main.c 文件是内核启动的起点,是分析内核启动流程的首要分析对象。
- fs/ 文件系统(file system?)
- kernel/ 内核相关的代码,一些内核中使用到的结构体、函数等重要对象的定义都在这里面。
- mm/ 内存管理的相关代码(memory managment?)
第二步,Linux内核启动过程分析
/init/main.c 文件中的start_kernel()函数是一切的起点,在这个函数被调用之前都是系统的初始化工作(汇编语言),所以对内核的启动分析一般都从这个函数开始;main.c中没有main函数,start_kernel()这个函数就相当于是c程序中的main函数。下面从这个函数开始对内核的启动流程进行分析。
由于写博文时没有随时保存的习惯,再加上手贱的原因,所以这是重新写的博文,因为时间的原因实验截图就不放上了,直接写一点自己的理会吧
start_kernel()函数的原型是:

这个函数在执行的过程中初始化、定义了内核中一些十分重要的内容,其执行过程几乎涉及到了内核的所有模块;首先,是init_task

init_task的定义在/linux-3.18.6/init/init_task.c
struct task_struct init_task = INIT_TASK(init_task);它其实就是一个task_struct,与用户进程的task_struct一样, task_struct中保存了一个进程的所有基本信息,如进程状态,栈起始地址,进程号pid等;init_task的特殊之处在于它的pid=0,也就是通常所说的0号进程(当然最终会进化成为idle进程,在下面会分析);关于0号进程的重要意义在下面会继续分析,在这里只要记得它是被start_kernel()函数创建的就可以啦。
在创建了0号进程之后,start_kernel()函数继续调用各个系统模块进行各种初始化之类的工作,比如:

- trap_init()是中断向量的相关设置
- mm_init()是内存管理的设置
- sched_init()是调度模块的初始化
至于调用的多少模块以及其相关的功能在这里就不仔细写了(其实因为弄丢了原来的博客来不及重写啊),因为我看到了同样学习了这门课的卢晅同学的博客对这个问题分析的很详细,所以就转载一下吧:
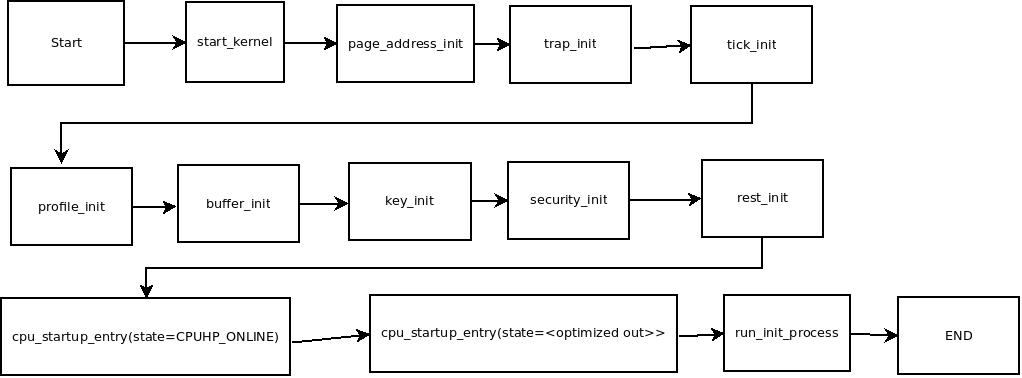
上面这张图片转载自卢晅同学的博客:http://blog.csdn.net/myfather103/article/details/44337461
在执行了上面的各项工作之后,是start_kernel()函数的最后一行代码:
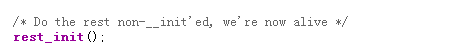
这样子就调用了另一个非常重要的函数rest_init(),它的位置在/linux-3.18.6/init/main.c,其代码如下:
393static noinline void __init_refok rest_init(void)
394{
395 int pid;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









