







活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您:
想系统/深入学习某技术知识点…
一个人摸索学习很难坚持,想组团高效学习…
想写博客但无从下手,急需写作干货注入能量…
热爱写作,愿意让自己成为更好的人…
…
欢迎参与CSDN学习挑战赛,成为更好的自己,请参考活动中各位优质专栏博主的免费高质量专栏资源(这部分优质资源是活动限时免费开放喔~),按照自身的学习领域和学习进度学习并记录自己的学习过程。您可以从以下3个方面任选其一着手(不强制),或者按照自己的理解发布专栏学习作品,参考如下:
**
直接上干货
目标爬去网站 胡桃的图片
网站:https://anime-pictures.net/pictures/view_posts/0?search_tag=%E8%83%A1%E6%A1%83&order_by=date&ldate=0&lang=zh_CN
先检索文件图片路径
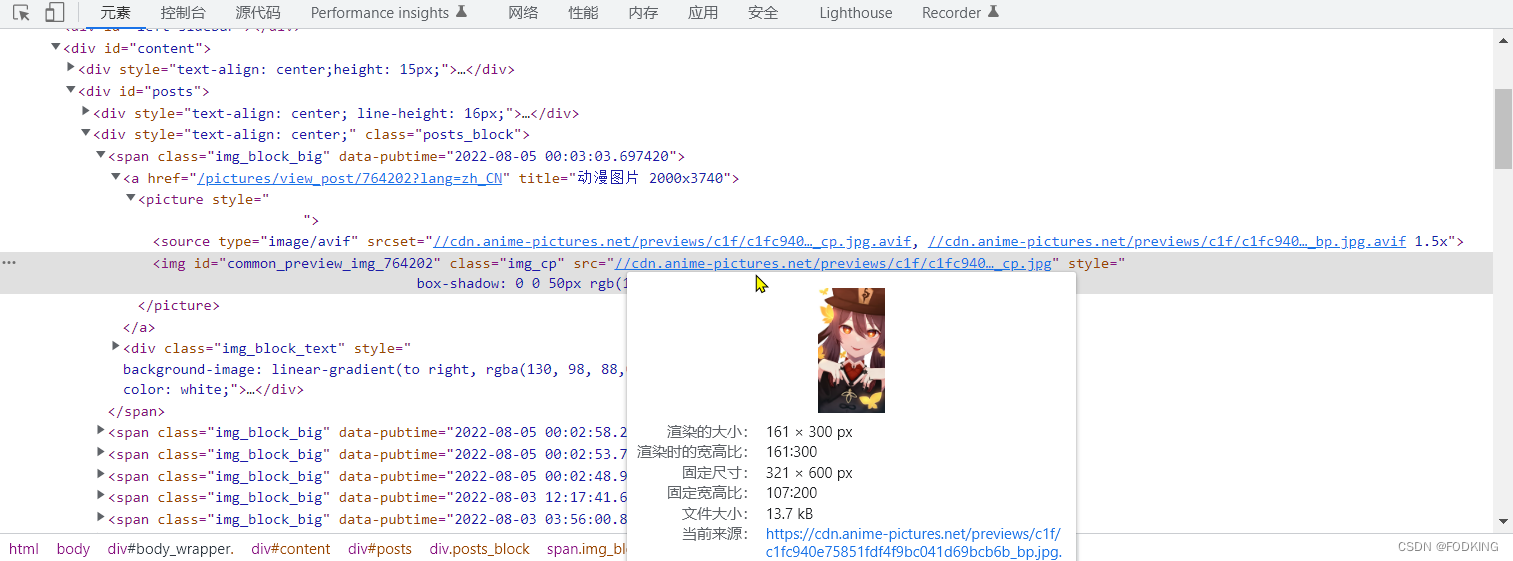
上代码
# -- coding:UTF-8 --
import requests
from bs4 import BeautifulSoup
from lxml import etree
import os
import re
'''
思路:获取网址
通过XPTH获取图片列表
再用xpth筛选有用信息
获取图片地址
爬取图片并保存
'''
# 获取网址
def getUrl(url):
try:
read = requests.get(url) # 获取url
read.raise_for_status() # 状态响应 返回200连接成功
read.encoding = read.apparent_encoding # 从内容中分析出响应内容编码方式
return read.text # Http响应内容的字符串,即url对应的页面内容
except:
return "连接失败!"
def getPic(html):
kl = re.compile(r'src="(.+?jpg)"')
sl = re.findall(kl,html)
for img in sl:
src = 'https:'+img # 获取img标签里的src内容
img_url = src
print(img_url)
root = "D:\hutao" # 保存的路径
path = root + img_url.split('/')[-1] # 获取img的文件名
print(path)
try:
if not os.path.exists(root): # 判断是否存在文件并下载img
os.mkdir(root)
if not os.path.exists(path):
read = requests.get(img_url)
with open(path, "wb")as f:
f.write(read.content)
f.close()
print("文件保存成功!")
else:
print("文件已存在!")
except:
print("文件爬取失败!")
# 主函数
if __name__ == '__main__':
html_url = getUrl("https://anime-pictures.net/pictures/view_posts/0?search_tag=%E8%83%A1%E6%A1%83&order_by=date&ldate=0&lang=zh_CN")
getPic(html_url)
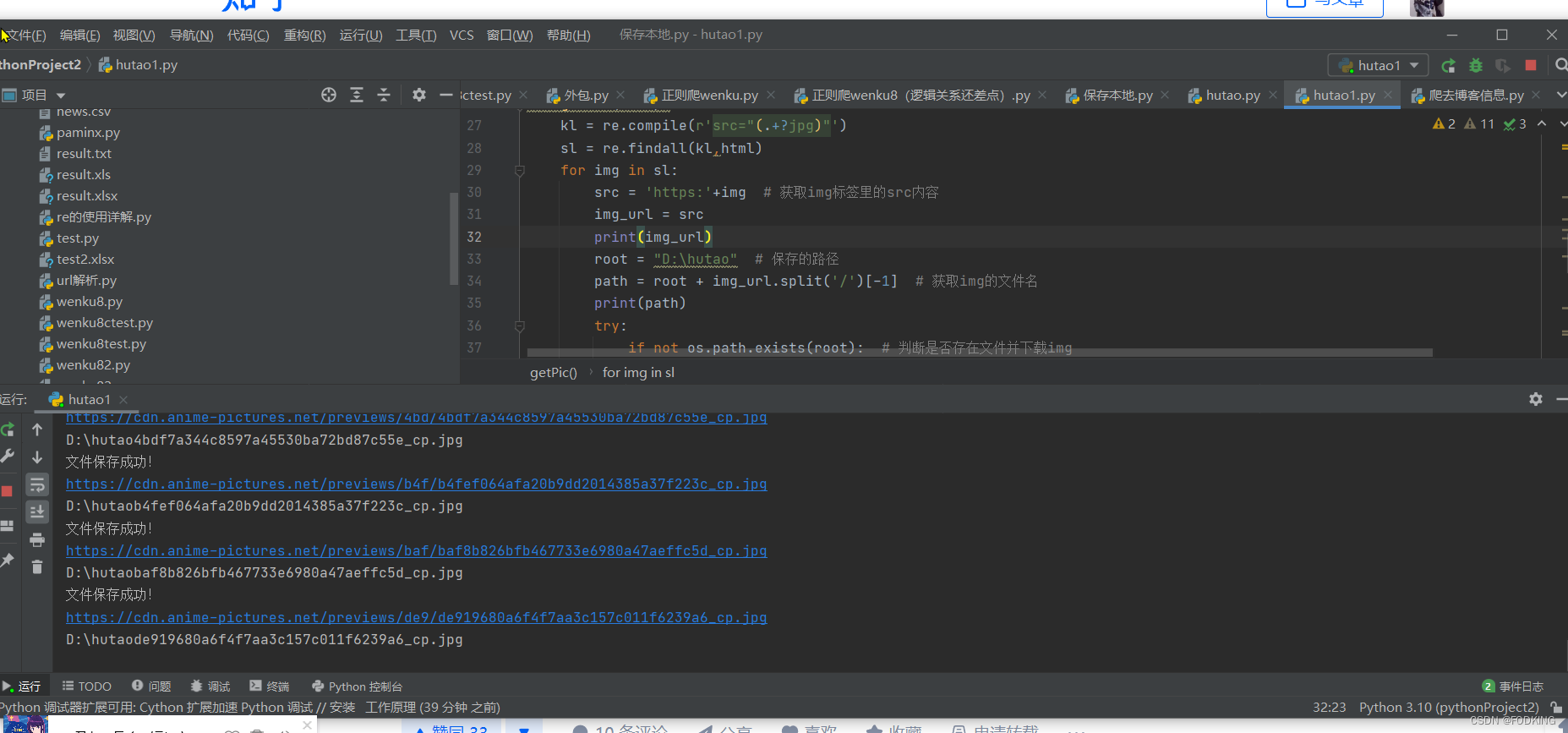
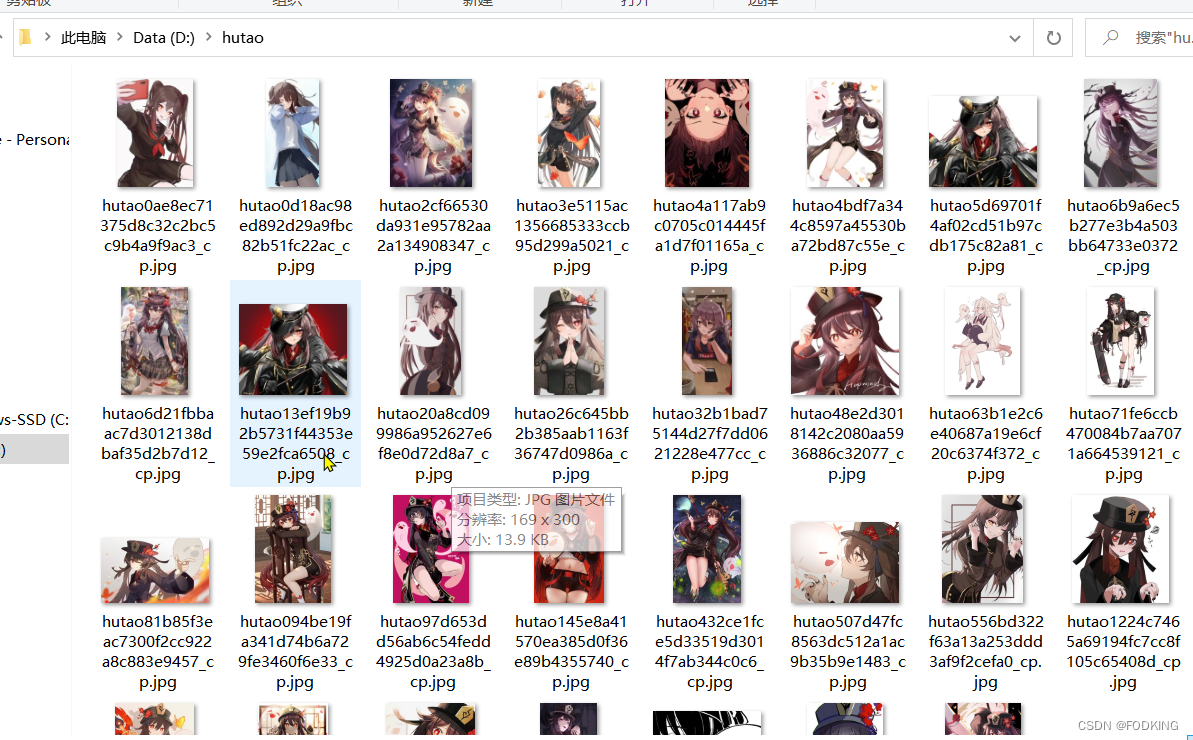

…
提醒:在发布作品前请把不用的内容删掉(活动地址请保留)























 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











