






问题 2. 根据附件 2 中某一种药材的中红外光谱数据,分析不同产地药材的特征和差异性,试鉴别药材的产地,并将下表中所给出编号的药材产地的鉴别结果填入表格中。

不同产地中药材差异分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_excel('附件2.xlsx', index_col = 0)
datadf_1 = pd.DataFrame(np.mean(data[data['OP']==1.0].drop('OP', axis=1)))
df_2 = pd.DataFrame(np.mean(data[data['OP']==2.0].drop('OP', axis=1)))
df_3 = pd.DataFrame(np.mean(data[data['OP']==3.0].drop('OP', axis=1)))
df_4 = pd.DataFrame(np.mean(data[data['OP']==4.0].drop('OP', axis=1)))
df_5 = pd.DataFrame(np.mean(data[data['OP']==5.0].drop('OP', axis=1)))
df_6 = pd.DataFrame(np.mean(data[data['OP']==6.0].drop('OP', axis=1)))
df_7 = pd.DataFrame(np.mean(data[data['OP']==7.0].drop('OP', axis=1)))
df_8 = pd.DataFrame(np.mean(data[data['OP']==8.0].drop('OP', axis=1)))
df_9 = pd.DataFrame(np.mean(data[data['OP']==9.0].drop('OP', axis=1)))
df_10 = pd.DataFrame(np.mean(data[data['OP']==10.0].drop('OP', axis=1)))
df_11 = pd.DataFrame(np.mean(data[data['OP']==11.0].drop('OP', axis=1)))
index_0 = range(551, 3999)
plt.figure(figsize=(8, 6), dpi = 300)
plt.xticks(range(551, 3999, 500))
plt.plot(df_1, c = 'r', label = '产地一')
plt.plot(df_2, c = 'b', label = '产地二')
plt.plot(df_3, c = 'k', label = '产地三')
plt.plot(df_4, c = 'y', label = '产地四')
plt.plot(df_5, c = 'g', label = '产地五')
plt.plot(df_6, c = 'm', label = '产地六')
plt.plot(df_7, c = 'c', label = '产地七')
plt.plot(df_8, c = 'tan', label = '产地八')
plt.plot(df_9, c = 'orange', label = '产地九')
plt.plot(df_10, c = 'sienna', label = '产地十')
plt.plot(df_11, c = 'peru', label = '产地十一')
plt.grid(True)
plt.legend(loc='upper left', numpoints=2, ncol=1, fontsize=8, bbox_to_anchor=(1.04, 1))
plt.xlabel('波数(cm^-1)')
plt.ylabel('吸光度(AU)')
plt.title('不同产地药材光谱数据均值曲线')
plt.savefig('不同产地药材光谱数据均值曲线.png')
plt.show()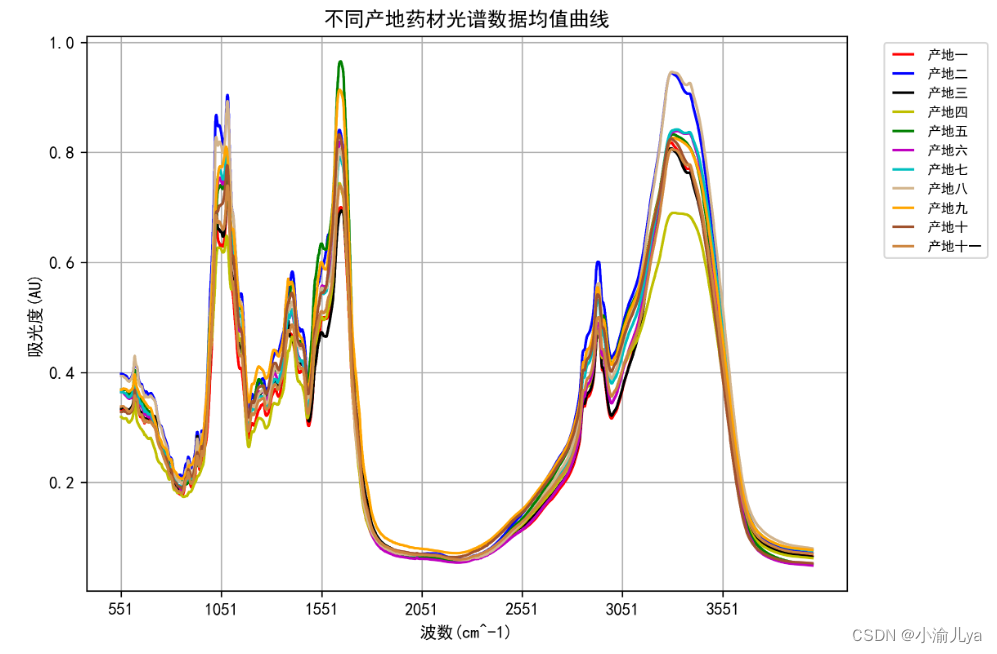
def SID(x, y):
p = np.zeros_like(x, dtype=np.float)
q = np.zeros_like(y, dtype=np.float)
Sid = 0
for i in range(len(x)):
p[i] = x[i]/np.sum(x)
q[i] = y[i]/np.sum(y)
for j in range(len(x)):
Sid += np.sum(p[j]*np.log10(p[j]/q[j]))+np.sum(q[j]*np.log10(q[j]/p[j]))
return Sid# 一/二
SID(df_1.values.T, df_2.values.T)
#一/三
SID(df_1.values.T, df_3.values.T)
#一/四
SID(df_1.values.T, df_4.values.T)
...欧氏距离、支持向量机分类
import numpy as np
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_excel('附件2.xlsx', index_col = 0)
data.shapedata.describe([0.01, 0.25, 0.75, 0.99]).T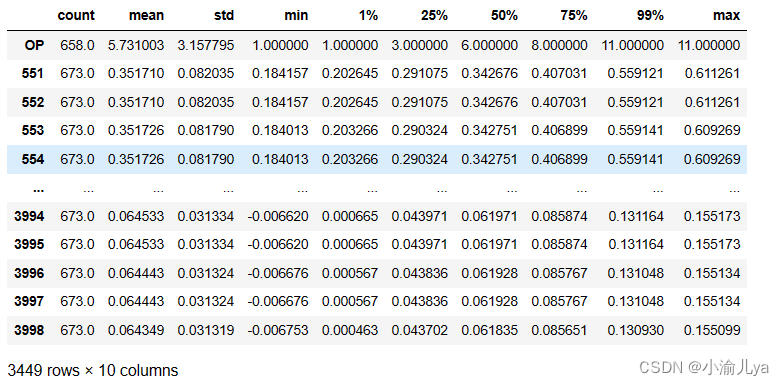
data.info()
data.iloc[:,1].isnull().any().any()![]()
data.iloc[:,0].value_counts().sort_index() # 统计每个产地药材数量并排序
data_X = data.iloc[:, 1:]
data_X = pd.DataFrame(data_X.iloc[:,1:].values-data_X.iloc[:,:-1].values, index = data.index)
data_Y = data.iloc[:,0]
data_Y.fillna(0, inplace = True) #用0填充op空值 未知产地药材
data_Y = data_Y.astype('int')
qsz_index = data_Y[data_Y==0].index #保留缺失值索引
def func_1(x):
plt.plot(x.index, x.values)
def func_2(data):
fontsize = 5
plt.figure(figsize=(8, 6), dpi = 300)
plt.xticks(range(551, 3999, 500), rotation = 45, fontsize = 5)
plt.yticks(fontsize = fontsize)
plt.xlabel('波数(cm^-1)')
plt.ylabel('吸光度(AU)')
plt.grid(True) # 网格线设置
data.agg(lambda x: func_1(x), axis = 1)
plt.show()
func_2(data.iloc[:,1:]) #附件二光谱曲线图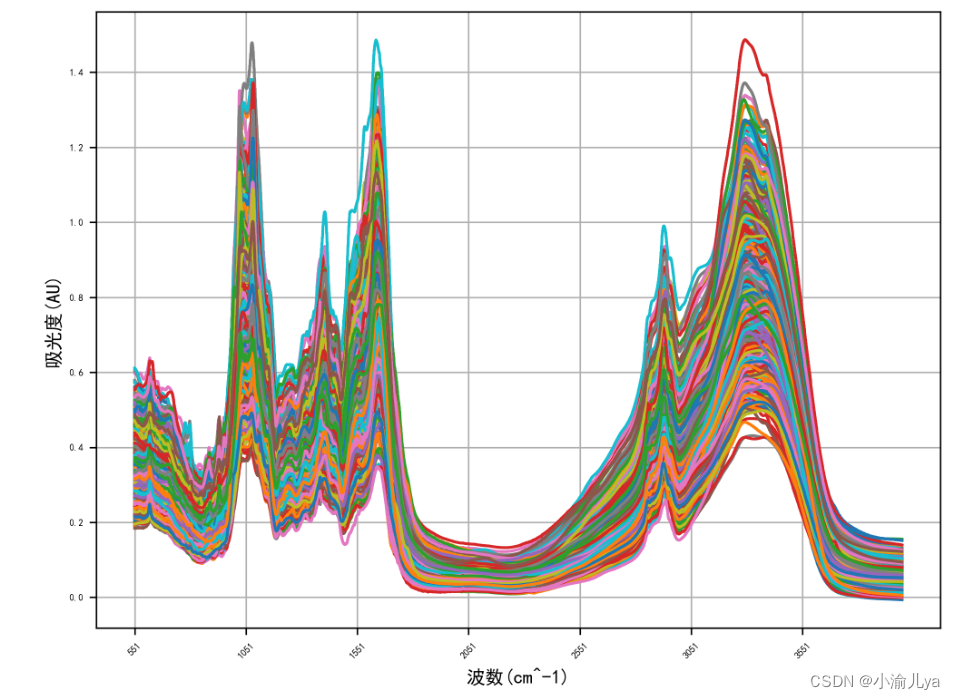
func_2(data_X) #附件二一阶平滑后数据曲线图
max_min = data_X.agg(lambda x:x.max()-x.min()) #计算极差
data1 = data_X.loc[:,max_min>max_min.mean()+0*max_min.std()] # 提取特征区间
data_X_know = data1.drop(qsz_index)
data_X_unknow = data1.loc[qsz_index,:]
data_Y_know = data_Y.drop(qsz_index)
test = pd.concat([data_Y_know, data_X_know], axis = 1)
欧式距离
from scipy.spatial import distance_matrix
dis = pd.DataFrame(distance_matrix(data_X_know.values, data_X_unknow.values), index = data_X_know.index, columns = data_X_unknow.index)
dis_group = pd.concat([data_Y_know, dis], axis = 1)
min_index = dis_group.iloc[:,1:].idxmin()
min_index #返回欧式距离最小的索引
[*zip(qsz_index, dis_group.loc[min_index,'OP'])] #返回待分类药材产地
支持向量机
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from hyperopt import fmin, tpe, hp, rand
from sklearn.metrics import accuracy_score
from sklearn import svm
from sklearn import datasets
print(data_X_know.shape, data_X_unknow.shape, data_Y_know.shape)![]()
parameter_space_svc = {
'C':hp.loguniform(np.log(100),np.log(1000)),
'kernel':hp.choice('kernel',['rbf','poly']),
'gamma':hp.loguniform('gamma',np.log(100),np.log(1000)),
}
Xtrain,Xtest,Ytrain,Ytest = train_test_split(data_X_know, data_Y_know, test_size = 0.3)
#分离训练集和测试集
count = 0
def func(args):
print(args)
clf = svm.SVC(**args)
clf.fit(Xtrain, Ytrain) #训练模型
prediction = clf.predict(Xtest) # 预测测试集
global count
count = count + 1
score = accuracy_score(Ytest, prediction)
print('[{0}], Test acc: {1})'.format(str(count), score))
return -score
best = fmin(func,parameter_space_svc ,algo=tpe.suggest,max_evals=100)
kernel_list = ['rbf', 'poly']
best['kernel'] = kernel_list[best['kernel']]
print('best params:',best)
best_params_ = {'C':831.1011250415439, 'gamma':101.90409101969092}
clf = SVC(C = best_params_['C'], kernel = 'rbf', gamma = best_params_['gamma'],
decision_function_shape = 'ovr', cache_size=5000 # MB
).fit(Xtrain,Ytrain)print(clf.score(Xtrain, Ytrain)) # 训练集![]()
score_r = clf.score(Xtest, Ytest)
print(score_r) # 测试集![]()
clf = clf.fit(data_X_know, data_Y_know)
print(clf.score(data_X_know, data_Y_know))
print(clf.predict(data_X_unknow))![]()
















 3035
3035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











