






由于复制粘贴会损失图片dpi请移步公众号原文观看获得更好的观感效果(关注公众号获得更多优质文章及数据)
Kolmogorov-Arnold 网络 (KAN) 是多层感知器 (MLP) 的最有可能的替代品,KAN 与 MLP 一样具有强大的数学基础:MLP 基于通用近似定理,而 KAN 基于 Kolmogorov-Arnold 表示定理,KAN 和 MLP 是双重的:KAN 在边缘具有激活函数,而 MLP 在节点上具有激活函数,这个简单的变化使KAN在模型准确性和可解释性方面都比MLP更好(有时要好得多!)具体参考往期文章KAN:Kolmogorov–Arnold Networks分类模型实现,接下来将利用KAN建立回归模型并对该模型进行PDP(部分依赖图)、ICE(个体条件期望)解释,目前并没有相关库支持直接对KAN模型进行相关的解释如SHAP、PDP、ICE解释等,这里将根据PDP、ICE的原理进行实现,具体的原理参考往期文章PDP(部分依赖图)、ICE(个体条件期望)解释机器学习模型保姆级教程
代码实现
数据读取并处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('数据.xlsx')
from sklearn.model_selection import train_test_split
X = df.drop(['price'],axis=1)
y = df['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将 DataFrame 和 Series 转换为 np.array
# 数据集标准化
x_mean = X_train.mean()
x_std = X_train.std()
y_mean = y.mean()
y_std = y.std()
X_train = (X_train - x_mean)/x_std
y_train = (y_train-y_mean)/y_std
X_test = (X_test - x_mean)/x_std
y_test = (y_test - y_mean)/y_std
import torch
X_trai = X_train.to_numpy()
X_tes = X_test.to_numpy()
y_trai = y_train.to_numpy()
y_tes = y_test.to_numpy()
# 转换为pytorch张量
dataset = {}
dataset['train_input'] = torch.from_numpy(X_trai).double()
dataset['test_input'] = torch.from_numpy(X_tes).double()
dataset['train_label'] = torch.from_numpy(y_trai[:, None]).double()
dataset['test_label'] = torch.from_numpy(y_tes[:, None]).double()读取Excel数据,分割数据集为训练集和测试集,将特征和目标变量标准化后,并转换为PyTorch张量,以便于KAN模型的训练
KAN模型建立
from kan import *
# initialize KAN with G=3
model = KAN(width=[8,2,1], grid=3, k=3)
model(dataset['train_input'])
model.plot(beta=100)
这里创建一个KAN:8D输入(自变量),1D输出(因变量),2个隐藏的神经元,三次样条 (k=3),3个网格间隔 (grid=3),读者可以利用网格细化来最大限度地提高 KAN 的拟合功能能力,修改网格间隔得到更细粒度的KAN,以及修改其它参数来增加模型拟合度,这里就不去展示如何去进行模型调参,接下来训练模型
model.train(dataset, opt="LBFGS", steps=20)
model.plot(beta=100)
训练模型后对模型进行可视化,对比模型初始可视化可以发现激活函数明显不一样了,这就是KAN对激活函数学习的一个结果,相应的会在代码文件下生成文件figures,为各个激活函数的详细可视化,这里的坐标为各个激活函数位置存在一一对应的关系,具体参考文末给出的链接,通过这些坐标可以对模型可视化进行修改等

接下来输出这个模型具体的公式
模型公式输出
lib = ['x','x^2','x^3','x^4','exp','log','sqrt','tanh','sin','tan','abs']
model.auto_symbolic(lib=lib)
formula = model.symbolic_formula()[0][0]
formula
模型预测评价
prediction = []
def acc(formula, X):
batch = X.shape[0] # 获取批量大小
for i in range(batch):
subs_dict = {
'x_1': X[i, 0],
'x_2': X[i, 1],
'x_3': X[i, 2],
'x_4': X[i, 3],
'x_5': X[i, 4],
'x_6': X[i, 5],
'x_7': X[i, 6],
'x_8': X[i, 7]
}
# 使用给定的公式对当前样本进行预测,并将结果转换为浮点数
predict = float(formula.subs(subs_dict))
prediction.append(predict) # 将预测结果添加到列表中
return prediction
test_pred = acc(formula, dataset['test_input'])
y_test_h = y_test*y_std+y_mean
pred_test_h = np.array(test_pred)*y_std+y_mean
import seaborn as sns
colors = sns.color_palette("husl", 3)
plt.figure(figsize=(15,5),dpi=300)
plt.scatter(y_test_h, pred_test_h, label='测试集', alpha=0.3, color=colors[2])
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.legend()
plt.tight_layout()
plt.show()
from sklearn import metrics
mse = metrics.mean_squared_error(y_test_h, pred_test_h)
rmse = np.sqrt(mse)
mae = metrics.mean_absolute_error(y_test_h, pred_test_h)
r2 = metrics.r2_score(y_test_h, pred_test_h)
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
mape = mean_absolute_percentage_error(y_test_h, pred_test_h)
print(f"Mean Squared Error (MSE): {mse:.4f}")
print(f"Root Mean Squared Error (RMSE): {rmse:.4f}")
print(f"Mean Absolute Error (MAE): {mae:.4f}")
print(f"R-squared (R2): {r2:.4f}")
print(f"Mean Absolute Percentage Error (MAPE): {mape:.4f}%")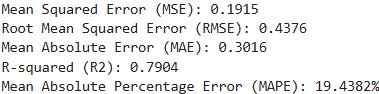
到这一步我们就完成了KAN模型的评价,利用拟合的公式对测试集数据进行预测,并进行真实值、预测值散点可视化,最后输出模型各种评价指标,如果不满这个拟合效果,可以对模型进行参数调整以得到最优模型
PDP部分依赖图绘制
import seaborn as sns
# 定义部分依赖函数
def partial_dependence(feature_idx, feature_values, formula, dataset):
predictions = []
for value in feature_values:
subs_dict = {
'x_{}'.format(i+1): value if i == feature_idx else dataset['test_input'][0, i]
for i in range(dataset['test_input'].shape[1])
}
predict = float(formula.subs(subs_dict))
predictions.append(predict)
return np.array(predictions)
# dataset 是你的数据集,formula 是你的模型公式
# 选择要绘制部分依赖图的特征索引和范围
feature_index_pdp = 0 # 假设选择第一个特征进行 PDP
feature_values_pdp = np.linspace(min(dataset['test_input'][:, feature_index_pdp]), max(dataset['test_input'][:, feature_index_pdp]), num=50)
# 计算部分依赖
predictions_pdp = partial_dependence(feature_index_pdp, feature_values_pdp, formula, dataset)
# 绘制部分依赖图(PDP)
# 设置Seaborn样式
sns.set(style="whitegrid")
plt.figure(figsize=(15, 5))
plt.plot(feature_values_pdp, predictions_pdp, marker='o', linestyle='-', color='b', linewidth=2, markersize=6)
# 添加标题和轴标签,并设置字体大小
plt.title('Partial Dependence Plot (PDP) for Feature {}'.format(feature_index_pdp), fontsize=16)
plt.xlabel('Feature Value', fontsize=14)
plt.ylabel('Average Prediction', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
# 添加背景和框架
sns.despine(left=True, bottom=True)
plt.show()

由于KAN模型没有支持直接绘制PDP的库这里根据原理进行绘制PDP,这里只着重说明参数num=50代表设置分辨率为50,表示在所选特征的范围内均匀生成50个取值点,然后PDP的对象是测试集的第一个特征,其它参数代码均有注释,最后利用KAN拟合得到的公式进行预测并进行可视化,觉得可视化不美观读者可自行调整,要想详细理解这个过程最好还是要理解PDP原理PDP(部分依赖图)、ICE(个体条件期望)解释机器学习模型保姆级教程链接里存在如何解释PDP图这里就不过多阐述
ICE个体条件期望图绘制
# 定义个体条件期望(ICE)函数
def ice(feature_idx, feature_values, formula, dataset):
ice_predictions = []
for i in range(dataset['test_input'].shape[0]):
individual_predictions = []
for value in feature_values:
subs_dict = {
'x_{}'.format(j+1): value if j == feature_idx else dataset['test_input'][i, j]
for j in range(dataset['test_input'].shape[1])
}
predict = float(formula.subs(subs_dict))
individual_predictions.append(predict)
ice_predictions.append(individual_predictions)
return np.array(ice_predictions)
# 选择要绘制个体条件期望(ICE)的特征索引和范围
feature_index_ice = 0 # 假设选择第一个特征进行 ICE
feature_values_ice = np.linspace(min(dataset['test_input'][:, feature_index_ice]), max(dataset['test_input'][:, feature_index_ice]), num=10)
# 计算个体条件期望(ICE)
ice_predictions = ice(feature_index_ice, feature_values_ice, formula, dataset)
# 绘制个体条件期望(ICE)图
plt.figure(figsize=(15, 5))
for i in range(len(ice_predictions)):
plt.plot(feature_values_ice, ice_predictions[i], color='grey', alpha=0.2)
plt.xlabel('Feature Value')
plt.ylabel('Prediction')
plt.title('Individual Conditional Expectation (ICE) Plot for Feature {}'.format(feature_index_ice))
plt.grid(True)
plt.show()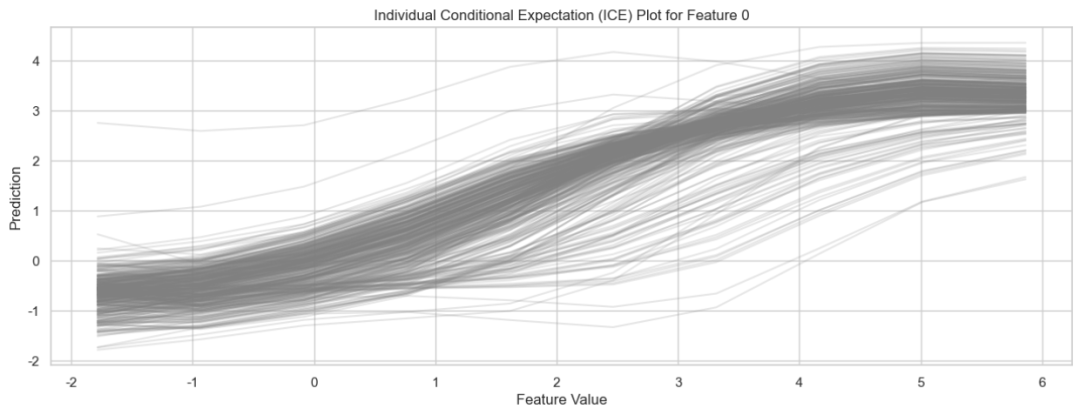
2D PDP绘制
from mpl_toolkits.mplot3d import Axes3D
# 定义二维部分依赖函数
def partial_dependence_2d(feature_idx1, feature_idx2, feature_values1, feature_values2, formula, dataset):
predictions = np.zeros((len(feature_values1), len(feature_values2)))
for i, value1 in enumerate(feature_values1):
for j, value2 in enumerate(feature_values2):
subs_dict = {
'x_{}'.format(k+1): value1 if k == feature_idx1 else value2 if k == feature_idx2 else dataset['test_input'][0, k]
for k in range(dataset['test_input'].shape[1])
}
predict = float(formula.subs(subs_dict))
predictions[i, j] = predict
return predictions
# 选择要绘制二维部分依赖图的特征索引和范围
feature_index1 = 0 # 第一个特征索引
feature_index2 = 1 # 第二个特征索引
feature_values1 = np.linspace(min(dataset['test_input'][:, feature_index1]), max(dataset['test_input'][:, feature_index1]), num=10)
feature_values2 = np.linspace(min(dataset['test_input'][:, feature_index2]), max(dataset['test_input'][:, feature_index2]), num=10)
# 计算二维部分依赖
predictions_2d_pdp = partial_dependence_2d(feature_index1, feature_index2, feature_values1, feature_values2, formula, dataset)
# 绘制二维部分依赖图(2D PDP)
sns.set(style="whitegrid")
fig = plt.figure(figsize=(14, 10))
ax = fig.add_subplot(111, projection='3d')
# 创建网格
X, Y = np.meshgrid(feature_values1, feature_values2)
surf = ax.plot_surface(X, Y, predictions_2d_pdp, cmap='viridis', edgecolor='k', linewidth=0.5, alpha=0.9)
fig.colorbar(surf, ax=ax, shrink=0.5, aspect=5, pad=0.1)
ax.set_xlabel('Feature {}'.format(feature_index1), fontsize=14, labelpad=10)
ax.set_ylabel('Feature {}'.format(feature_index2), fontsize=14, labelpad=10)
ax.set_zlabel('Average Prediction', fontsize=14, labelpad=10)
ax.set_title('2D Partial Dependence Plot (PDP) for Features {} and {}'.format(feature_index1, feature_index2), fontsize=16, pad=20)
ax.tick_params(axis='both', which='major', labelsize=12)
# 设置视角
ax.view_init(elev=60, azim=120)
plt.tight_layout()
plt.show()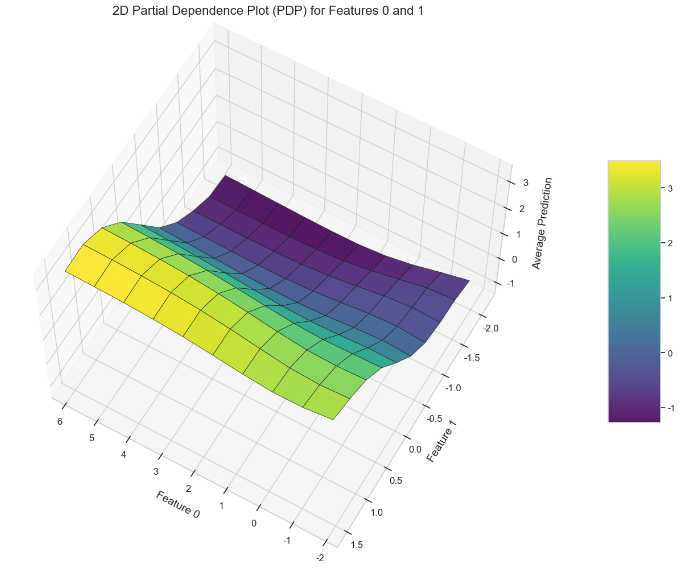
这里的2D PDP和通过PartialDependenceDisplay绘制的2D PDP可视化并不是一致,仅供读者参考,这里是同时改变两个选定特征的值,而固定其他特征的值,计算预测结果,从而绘制二维部分依赖图(2D PDP),展示这两个特征对预测结果的联合影响
往期推荐
KAN:Kolmogorov–Arnold Networks分类模型实现
论文可视化设计:掌握 Seaborn 15 种精美数据可视化
PDP(部分依赖图)、ICE(个体条件期望)解释机器学习模型保姆级教程
ARIMA与Prophet的完美结合:AutoARIMAProphet时序模型
如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~
Python机器学习AI 个人观点,仅供参考
















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











