







本文中涉及的代码地址:analyseExecutionOfC
文件结构:
analyse-execution-of-c
|-- compilePreProcessSource.o
|-- compilePreProcessSource.o.png
|-- compilePreProcessSource.s
|-- preProcessSource.c
|-- source
|-- source.c
|-- source.png
引言
我们比较熟悉的C语言执行流程为:预处理、编译、汇编、链接、运行。但是各个阶段的具体流程又是什么呢?接下来针对每个阶段详细分析。
C语言的流行离不开gcc编译器的成功。gcc编译器帮助C程序完成四个阶段:预处理、编译、汇编、链接。然后将链接后的程序交给OS 执行。
本文简单介绍了C语言在执行之前的准备阶段,事实上每个阶段都是十分复杂的,绝对不是一篇或者几篇文章能够描述的,所以这里只能将描述停留在入门级上,希望能够对大家有所帮助。
GCC 编译过程
源文件
#include<stdio.h>
// 声明函数sum
int sum(int arg1, int arg2);
// main被gcc编译器的桩程序调用
int main(){
sum(3, 5);
return 0;
}
// 初始化函数sum
int sum(int arg1, int arg2){
int res = arg1 + arg2;
return res;
}
预处理
在 linux 中运行:gcc -E source.c -o preProcessSource.c 。得到 preProcessSource.c 文件。
参数 -E 运行 preprocessor,-o 将运行结果输出到 preProcessSource.c 文件中。
预处理会丰富我们的源程序,调整删除多余的空格字符和制表符;将字符常数转化成对应的值;替换宏定义等。此时输出仍然是纯C代码。
编译
在 linux 中运行:gcc -S preProcessSource.c -o compilePreProcessSource.s。得到 compilePreProcessSource.s 文件。
参数 -S 将 preProcessSource.c 编译为汇编程序 compilePreProcessSource.s。
编译可以被通俗地理解为将一种格式的字符串转化为另一种格式的字符串。将这个概念带入 -S 指令,可以认为 source.c 源码中出现的 sum(3, 5) 被转化为汇编语言 call sum。
实际上C语言中函数的调用的确对应 X86汇编语言 的 call 指令。但是转化过程十分复杂。不同理论的语言有不同的编译原理,主要分为两各派系,一类是面向过程的编译,一类是面向对象的编译。
接下来我将站在逻辑层面(means I won’t code a real compiler, But I will guide you to understand the compilation process ),结合C语言编译器的实现过程描述C语言的实现过程。
-
词法分析:分解源程序,得到一个个符号。
将输入的源程序分解为一个个独立的词法符号,又记为token。
假设下例中
a的类型为float。 -
语法分析:分析程序结构,将词法符号串转化为语法分析树。
韦氏词典:
语法--组合单词以形成词组、从句或句子的方法。 -
语义分析:确定语法分析得到的树形结构中每个节点符号的含义,建立变量和声明的关联,检查表达式的类型。
此时需要引入一个新的概念:符号表。其作用是将表欧师傅映射到他们的类型和储存位置。符号表:
语法分析树经过语义分析形成语义分析树。
-
栈帧布局:按照机器要求的方式将变量、函数参数等分配到栈帧中。
C语言栈帧布局如图所示:

可以参考这篇文章进一步了解C语言运行时栈结构:C程序方法调用。 -
翻译:生成中间代码,这是一种与任何特定语言无关的中间表示。
为什么需要生成中间代码,而不是直接生成目标代码呢?技术上可定支持将语义分析树直接转化为目标代码,但是这样做不利于可移植性和模块化设计。
一种好的中间代码有以下特点:
- 能够充分利用语义分析阶段生成的语义分析树。
- 对于希望支持的所有目标机器,它必须便于生成真实机器语言。
- 中间表示的每种结构必须具有简单明了的含义,以便能够比较容易指定和重写中间表示的各种优化操作。
这里我们使用三地址指令来描述中间代码。
// 这就是中间表示的一种形式。站在Java程序的角度class字节码就是Java源程序的中间表示。 t1 = inttofloat(10) t2 = id(a) + t1 id(sum) = t2 -
规范化:中间表示最终需要转化为机器语言或者汇编语言,我们需要仔细选择和定义规则以便中间表示能够和大多数机器的能力匹配。例如,我们定义规则–方法以外的标识符不能出现"()"。接下来我们就需要检查中间表示,如果发现不不符合规则的变量,将其修改为符合规则的变量。
修改后的指令代码为:
t1 = inttofloat(10) t2 = id<a> + t1 id<sum> = t2 -
指令选择
中间表示的每个操作过程可能对应机器语言的多个操作指令,或者机器语言的一个操作指令对应中间表示的多个操作过程。此时我们就需要找到中间表示每个操作过程在机器语言中对应的最小指令集合。这个过程叫做指令选择。
指令选择的目的是 找出一个给定的中间表示的恰当机器指令序列。
本文中我们假设规范后的程序就是恰当的机器指令序列。
-
控制流分析&数据流分析
编译器将程序转换为含有大量临时变量的中间语言,转换后的程序必须在寄存器有限的计算机上运行。如果两个临时变量不会同时使用,则可以考虑将他们放在同一个寄存器中储存。因此,尽管有很多临时变量,我们通过调和之后只需要使用少量的寄存器保存他们。如果不能全部将他们放在寄存器中,超出的变量可以放在储存器中。
因此编译器需要分析程序的中间表示,确定哪些临时变量会被同时使用,哪些变量会在将来被使用。
为了对程序进行分析,通常有益的方法是生成程序的控制流程图。
CSDN的flowchart中<>会被自动隐藏,所以接下来我们使用sum代表id<sum>,使用a代表id<a>。
从流程图上我们可以观察到同一时刻出现变量最多是3个,因此最多需要3各个寄存器储存变量的值。
事实上之所以能够计算出来寄存器的使用情况,使用到的技术是控制流分析和数据流分析。
控制流分析:分析指令的执行过程建立控制流程图,此图表示程序执行时所有可能流经的途径。
数据流分析:收集程序变量的数据流信息。例如,活跃性分析计算每一个变量需被使用的其他地点。
-
寄存器分配
为程序中的每一个变量和临时数据选择一个寄存器,不在同一时刻活跃的变量可以共享同一个寄存器。
-
代码流出
用机器寄存器替代每一条机器指令中出现的临时变量名。
source.c文件到这里被处理为compilePreProcessSource.s文件。
汇编
在 linux 中运行:gcc -c compilePreProcessSource.s -o compilePreProcessSource.o 得到 compilePreProcessSource.o 文件。
参数 -c 将执行汇编过程,并通过 -o 将汇编结果输出到 compilePreProcessSource.o 文件中。
汇编结果展示:
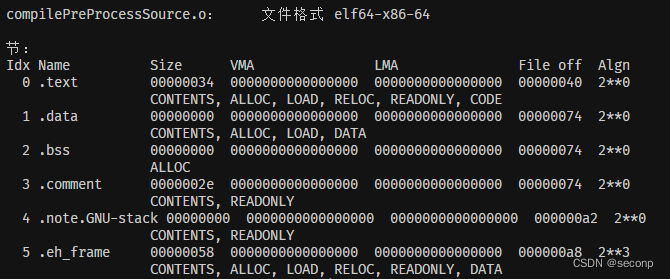
看到展示的结果,小伙伴们可能有一些懵,不用着急,随着接下来我们新概念的引入,相信能够解决你的疑惑。
区
区(section)(也称为段、节或部分)用于表示一个地址范围,操作系统以相同的方式对待和处理在该地址范围内的数据信息。区的概念主要用来表示编译器生成的目标文件(或可执行文件)中不同的信息区域。
链接器会将输入的目标文件内容按照一定规律组合成一个可执行程序。
这里仅仅讲解其中的部分区域,有兴趣的小伙伴可以参考gcc官方文档查看每一个区的作用。
text区、data区:这两个区用以保存程序。当程序运行时,text区通常不会改变,text区中的内容会被进程共享,其中含有指令代码和常数等内容。程序在执行时data区的内容通常是变化的,例如,C语言的变量就存放在data区中。
bss区:该区用于存放未初始化的变量或作为公共变量储存空间。
因为 .o 目标文件有自己规定的格式,每种格式有其特殊含义,所以建议有兴趣的小伙伴可以阅读gcc官方文档。只要理解不同的区被用来实现不同的功能,这些功能配合起来能够成功执行程序就行了。
链接
链接器会将输入的目标文件内容按照一定规律组合成一个可执行程序。
在 linux 中运行:gcc compilePreProcessSource.o -o source 得到 source 文件。
gcc 命令将 compilePreProcessSource.o 链接为可执行文件 source。
链接结果展示:
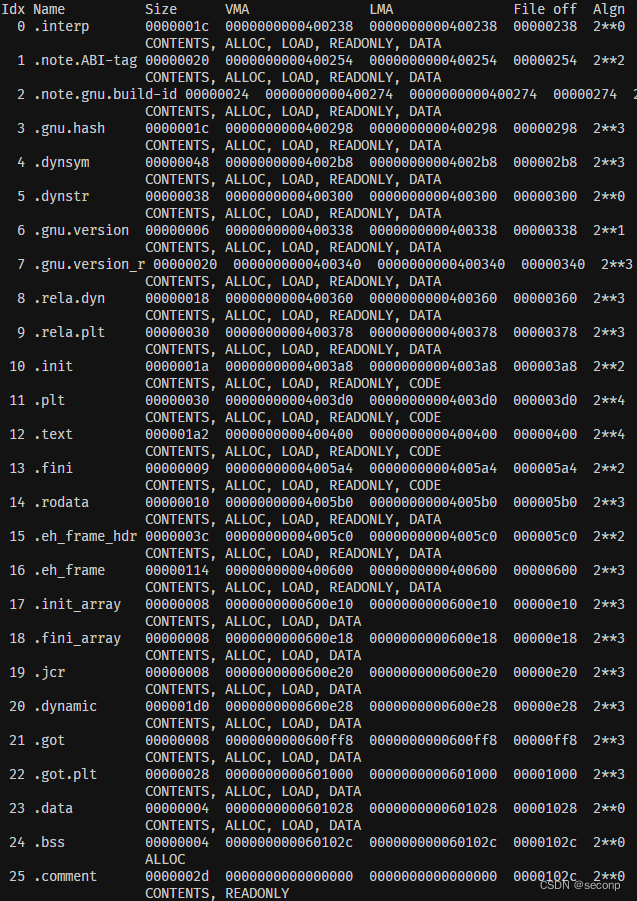
在汇编阶段已经介绍了链接器将目标文件转化为可执行文件。
可执行文件也是文件,有自己的格式,但是不同操作系统定义了不同的可执行文件的格式。根据可执行文件操作系统就能够按顺序执行对应的汇编指令,我们也能得到程序的运行结果。
问题
如果有什么问题可以在issue中发起提问。
另外稍后将会出一片文章,使用本文中的代码将程序的出栈入栈过程绘制出来。
参考文章
- Preprocessing source files
- 赵炯.linux0.11源码
- [美]Andrew W.Appel, Maia Ginsburg.现代编译原理 C语言(修订版)[M].赵克佳,黄春,沈志宇,译.北京:人民邮电出版社,2018.4
- [美] Alfred V.Aho, Monica S.Lam, Ravi Sethi, Jeffrey D.Ullman. 编译原理[M]. 赵建华,郑滔,戴新宇,译. 北京:机械工业出版社,2009.1















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









