







先恭喜我校这次取得了史上最好成绩!不是数学专业的,与王老师接触不太久,但他短短几天每晚穿睡衣来机房陪我们,真是感人=。=很负责的老师。这下他也能圆满的退居二线啦 。感谢所有,下面就这次国赛B题的解决过程做一个回顾。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
我们采用python和MATLAB混合编程,我和hl负责编程和建模,yy负责论文排版和表格整理,我再负责论文写作。
9.14晚上八点开题,那段时间真是太忙了,比赛开始前一小时还做了新生见面,由于要比赛急急忙忙就溜了。8点开题,拿到题目,随手就先点开了B题,一眼看上去,嗯...三个附件数据齐全,典型的数据挖掘结合数据建模,也是和队友hl很擅长的,当时很快就基本定下要做B了,扫了一眼A,无感。
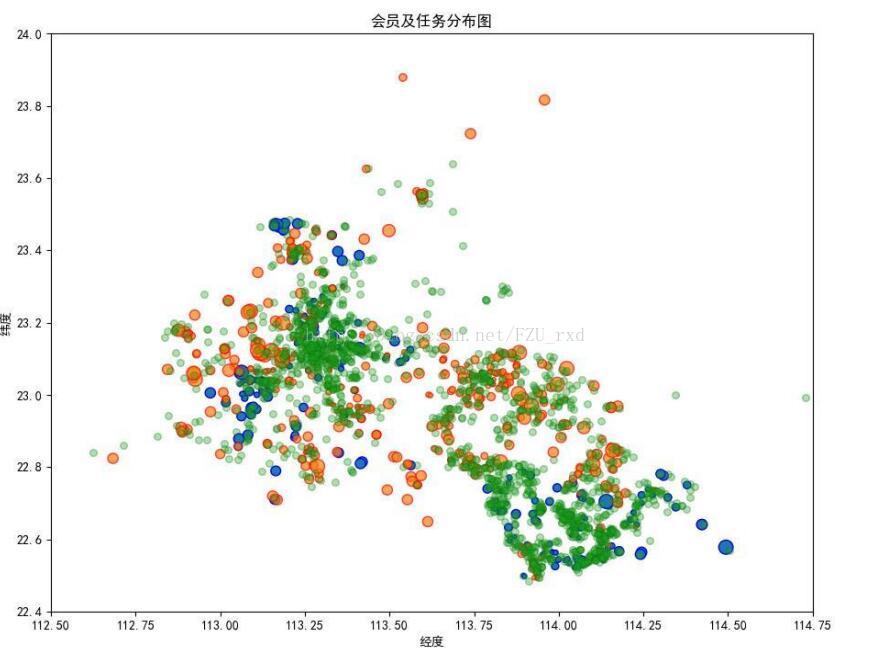
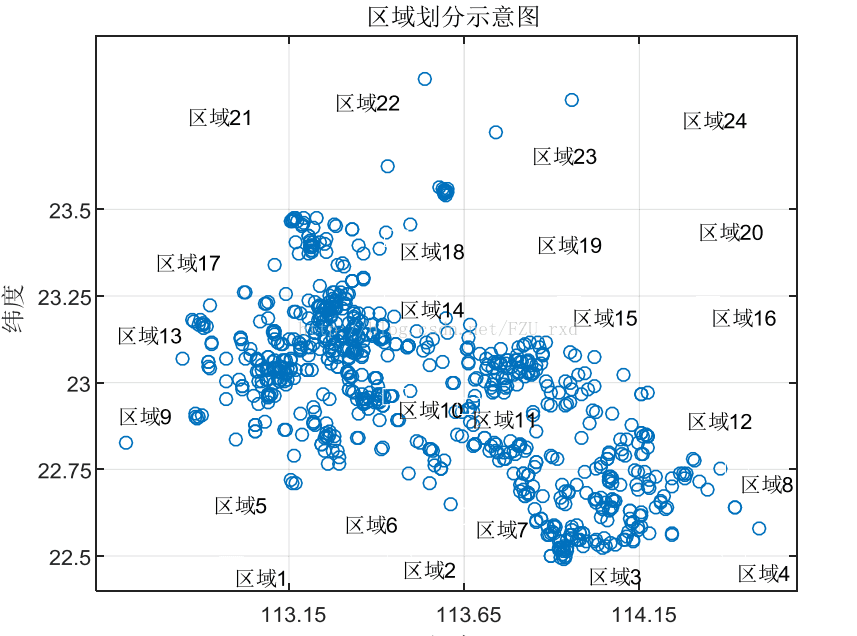
很快,读完题目,直接就上手做可视化,把附件一的经纬度坐标可视化后发现,嗯,异常点不多,且主要都集中在一个大的范围内,但具体位置杂乱无章。差点没看到附件二,发现还有用户的数据,于是把用户数据又做了可视化,用户中有明显的异常点,经纬度颠倒了,先做了数据清洗,用户中也有一些比较离群孤立的点,但我们没有选择滤除掉他们,因为就是简单的觉得存在即有意义,万一附件三投放的新任务在那些区域呢。叠加用户数据,和任务定价以及完成情况,在一张图上可视化,看上去舒服多了,有一部分区域任务会大面积未完成,也有部分是大面积完成,还有一堆都是杂乱无章的好像没有什么规律可循。那就结合特征开始推测,也许未完成地区是由于任务定价过低没人去完成,或是会员数目少,等等。对这些数据大致情况就有了大概的认识,我们开始思考第一问要去怎么做。第一问要求研究定价规律以及分析未完成原因,显然,要综合用户特征以及任务特征和二者结合构造出的联合特征来分析。但显然直接对这个图进行分析是无从下手的,第一时间就想到聚类,但显然这复杂度要炸,如果要聚成两三类显然是没卵用,聚几十类 怕是要跑两天程序,显然都不实际。我们从一个实际的初创APP公司出发,公司初期可能就是简单的分区进行定价,然后简单结合每个区域的人数和繁华程度进行。于是了,我们就决定先网格化来进行分区,这样分析起来就十分方便了。分多少格又是个麻烦事,索性就不思考那么多随意一点,4*4or3*6or4*6,大只在图上画了了几下,发现4*6好像比较靠谱。区域的特征十分明显,即有的区域任务很多,且完成情况较好,有的区域任务少人多,供不应求等等。仿佛每个格子内都是各色各样,这也方便我们去对比分析。这样,第一问好像就基本解决了。感觉时间不早,第一晚22.30左右就都溜回宿舍休息了,毕竟后面还有漫漫长路要走。
第二天,8点多点到达机房,开始干活!就昨晚的思路,先对任务进行分区,拿到队友hl给的经纬度分割节点,我开始对任务数据和用户数据进行划分,暴力for循环,大概40分钟完成,接着开始计算区域特征,初步选择了区域内任务数目 区域内任务数目 区域内任务与用户数之比 平均信誉度 平均完成率 区域内任务平均定价等等 大致想了9个特征,但最后发现,特征内有的是重复的特征 比如什么完成数和完成率就可以直接用完成率就ok。类似的,最后我们缩减为7个特征。进而打算做相关性分析,对定价规律做一简单阐述,毕竟后面三问才是重点。第二问要求重新定价,并进行对比。既然要重新定价,还要对比,那势必要结合原定价,对比,哪些方面可以对比呢?很容易想到 那就是完成率和利润。 一个主要的思路就是 想办法重新定价后 ,综合区域特征和任务的重新定价 用logistic回归来判定01。用原定价作为训练样本。这样就相当于模拟抢单。事实上,这一部分也可以用别的机器学习算法,knn或者随机森林都ok。时间够可以用更多的做一对比。但也有些多此一举,毕竟整体用一个主体模型贯穿最好。下面就是定价,这个我们采用灰色关联度,即以除定价外的特征最为比较数列,定价为参考数列,然后用关联度算权重加权。细节部分,发现原始定价均在65-85 且0.5为区间,重新定价也就映射在区间内再进行取0.5和1的处理。但在这时突然发现,之前取的特征好像都是区域内的,这样重新定价后每个区域所有任务定价全部相同了。很尴尬。然后我们就脑补了一个叫做区域内用户到任务平均欧式距离的特征,区域内就每个任务,计算区域内所有用户到其距离,之后加和平均,这样每个任务又多了一个都不相同的属性,灰色关联度程序跑出来 发现结果惊喜,所有属性均在0.5以上 ,三个属性在0.7以上属于强关联,而平均欧式距离就是0.8+。这让我们很兴奋,说明定价确实参考这些特征很靠谱,而且验证了我们所做的特征工程也比较合理。剩下的就是映射到价格区间。然后带入到logistic回归中预测完成率。很不错,较原定价方案完成率提高了18%。且盈利增加。这里盈利我们用了一个简单的逻辑关系表达,有一个前提假设,即用户完成任务,用户得到的钱一定是少于app公司拿到的钱,至于app公司从哪里拿钱,我们不用考虑。由此就可以通过11 01 10 00四种完成情况的逻辑变化,分别列出一个抽象的利润计算,显然最后利润是明显增加了。后面又把新的任务用户情况可视化,发现以前未完成的任务有部分完成,且区域集中,而有一区域内 任务完成情况几乎没发生改善。我们先没对此做分析,基本第二天白天的下午 我们前两问结果都跑出来了,下午饭后,我开始码前两问的论文,yy学姐把跑出来的数据整理成表,hl学长思考第三问的打包模型。大概忙到晚上23 点左右,论文前两问写的差不多,又和hl学长闲扯了会儿第三问,之后也0点前回宿舍回宿舍休息。回去路上觉得就剩两问还有两天,就感觉还是蛮不错的。
9.16一早,差不多还是8点多开始干活,继续就前两问论文进行完善,中午过后开始认真研究第三问,打包?为什么打包?我们做了一些假设,可能是人数集中任务集中,app公司单纯为了增加收入而这么做的,大概意思就是因为任务集中两个任务合并为一个也没人发现,虽然任务量大了,任务的报酬却不用直接按原来的加和,可以少一些,这样就赚了。还有一种原因可能是,任务过于集中,用户也过于集中,导致用户争抢,对app运行的要求提高,不如合并一些,任务少一点,好按照如信誉值之类的把用户排序去分配任务。但不管怎么样,打包一定是要做一些特殊假设的,不然显得太没原则。既然是任务过于集中要打包,那打包一定要任务距离比较近,用户争相选择,那一定是用户也很多。这两个就可以抽象为用户密度和任务密度,再进一步的可以做一个比值,即用户密度比任务密度,这样就仿佛可以设定一个阈值a之类的东西,来作为是否打包的标准。但打包任务数目怎么确定呢,想来想去感觉有些乱,hl提出两两打包,商讨了一下确实也是比较合理的,因为一个用户的劳动力有限,太多的打包到一起任务量过大可能起不到打包的目的效果=。=所以我们就做了两两打包的假设。最终方案,基于用户与任务密度比值进行两两打包,我们对任务和用户分别设定了一个半径r1和r2,作为算密度的范围。然后就是去遍历整个附件内的任务分别判定是否打包,打包任务后的经纬度直接选择两任务的中点。处理后,再对地图信息进行刷新,重新进行特征计算,对于定价模型的修改很简单,盈利嘛,那就加和后乘一个类似衰减因子的东西,也方便之后的灵敏度检验什么的。之后带入训练好的logistic回归分类器,队完成情况进行判定。思路好了,到了下午左右我和hl开始编程,hl负责打包的编程,我负责数据处理和地图信息刷新的编程。期间yy学姐也在安静的查文献,找到了之前一个类似打包的东西,也对我们打包的合理性得到了一定的检验。但编程这段并不顺畅,bug频频,打包后经纬度的刷新,以及任务的去重,等等,我这边需要等hl的数据,我也提前去编好程序框架,一直到快0点,还是有问题,我们让yy学姐先回去了,我和hl学长一直到3点左右,还好,一种拨开云雾见日升的感觉,终于以附件一为例,输出了打包后的任务以及任务编号,由831个任务缩减为800个左右。大功告成,松了一口气。hl学长索性住机房了,我就拖着电脑慢慢吞吞回到了宿舍,差不多快凌晨四点,过马路的时候还见到一辆闯红灯的大货车。那个时候人感觉是飘的,我路上还顺手用手机敲完了思政实习报告=。=有点佩服自己hhh
9.17一早8点起床,感觉还蛮精神,毕竟最后一天,一到机房我开始疯狂写论文,整理,忙到下午4点左右,开始第四问的编程,第四问其实就是将第三问和第二问的模型分别应用到一批新的投放任务上,在对新的投放任务可视化过程中发现了惊喜,发现附件三的任务全部投放在三块集中区域,更巧的是,这三个区域正好落入我们划分的网格内,这还不是关键,最关键的是一看这三个区域编号,发现这三个区域正是用户数很多,而且用户数远远大于任务数的区域。这说明什么?即正好是供不应求,也就是负荷app公司真实投放原则,即在这种供不应求的区域投放任务。这显然是很符合实际的。刷新地图信息,打包等等重复那些过程,跑出结果。我开始加速写论文,20点左右,感觉论文的雏形差不多了,还有一些可视化图和很多细节欠缺。hl学长发现python好像画区域不太方便,正好突然发现matlab好像可以,于是我用matlab又做了几个带区域划分的图,毕竟最后国奖论文可能这些东西的美观也是一个很重要的标准。到了晚上,我们都打算12点前就提交走人,事实上可以到凌晨6点前都可以,但感觉差不多也害怕出意外,就争取在12点前弄完,到了23点左右我论文整个初稿完成,下面yy学姐开始把一些表格做了美化,我们三人共同对论文细节以及公式编号进行细节处理,还包括图和表的编号。急急忙忙,又突然发现第二第三问结论写的不算完善,赶快又补充,23点45,王老师开始不停地催促=。=感觉像是制造恐慌,我们最终在23点50左右提交了所有.py .m .pdf等乱七八糟东西,结束。收拾走人=。=当时看到机房还有很多人都在打算做到凌晨6点,其实我是挺想再继续细化的,但大家也都很累了,我也是,仔细想了想,说不定反而更容易出错。索性,溜了溜了。走的时候我们都觉得只需要等奖状就ok,毕竟全部解决,但也不能这么奶自己,那就 肯定可以获奖,但至于获多大的奖那就随缘了。
最终结果还算满意,国一,很荣幸的成为了那0.8%,也为我校感到骄傲!看着国奖的名单,今年和省内某985齐平,终于在数模竞赛上也完成了这样的成就,还是很棒的hhh。
附上我们论文中的一些可视化图
再分享一点自己学习数模的经验吧,首先,兴趣第一,其次,数模竞赛近几年的题目也都是大数据相关,解题中也包含了很多机器学习思想,与未来方向贴切,是个不错的竞赛选择。记得16年暑假后开始看第一本《matlab在数学建模中的应用》卓金武那本,直接用那本书开始学习数模,主要是熟练了matlab的操作,后来又买了一批书,借了一批书,姜的数学模型确实太老了,自己并没觉得看了有啥实际上的收获,不过也还好,当科普书。借的书还包括运筹学、组合优化、数字图像处理等杂七杂八。基础的,比如针对评价问题(层次分析法(AHP)、熵权法、gossip法)等等,优化里的一些启发式算法(模拟退火、遗传算法),数据分析(各种聚类、拟合、回归)大致这些全部自己能用matlab或是python、R进行实现,这样基本我觉得是可以单干一场数模竞赛了。在17年四月份开始,单干了一堆数模竞赛五一联赛三等电工杯二等,校赛三等,每一次做总觉得都比前一次会有新的收获,在做的过程中其实更能进步更快,我觉得所有三个人的比赛,不能抱着只负责某一部分的学习,另外的由队友分工。而是从一开始,就要做到能独当一面,一个人也能完成所有的任务,这样即使在正式比赛中,遇到意外,也不用太过惊慌。但国赛的两位队友还是超级靠谱的hhh,感恩。在17年暑假,把spss R python 全部又熟悉了一遍,把机器学习的一些算法以及启发式算法又动手实践了一些。感觉在最后都是有用的。
大致我觉得,我个人做建模的过程 第一阶段:刚刚学会了一些基本方法,就根据题目,强行把题目往一个我会的方法上靠,去做。第二阶段:懂了些神经网络和启发式算法,就不管简单的还是复杂的优化,都去用一些看似高大上的方法去做。第三阶段:能够根据题目有自己的创新点,剖析出题目所隐藏的模型,合理选择一些不一定是看似高大上的方法,但能把建模的过程以及实际模型体现的淋漓尽致。
不是数学计算机专业出身,但热爱就够了。

















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









