







首先找背包遍历
1.通过物品数量我们入手找
2.首先CE搜索当前药品数量

3.然后消耗一瓶血药

4.CE继续搜索10,你会发现还剩下1423个结果
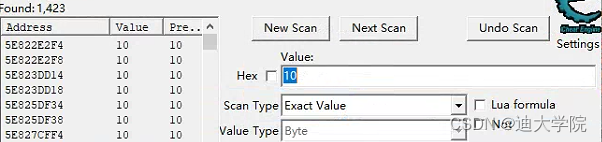
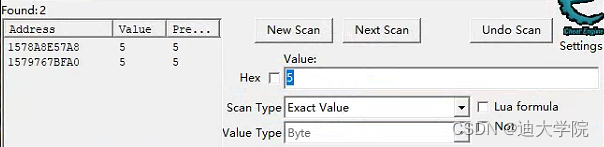
5.经过我们几次的筛选,最终找到几个结果
6.拿到地址后,我们用XDBG附加游戏后查看这个地址

7.随后我们在这个地址上下写入断点,通过消耗血药,就能触发断点

8.我们发现rbp+68]存的就是数量,那么rbp就是一个结构体,通过几层返回
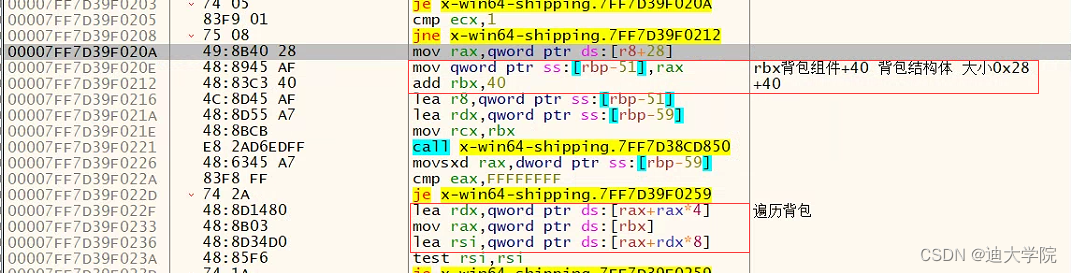
9.找到了一个结构体数组遍历,这个结构体数组存在背包组件对象+40的偏移,同是我们发现结构体大小为0x28

9.我们进入这个结构体数组看一看,可以看到每0x28结构体大小就是一个背包物品信息

物品品质分析
1.很显然我们可以看到每个结构体的信息大概是什么,
+0是ID
+10是对象1
+18对象2
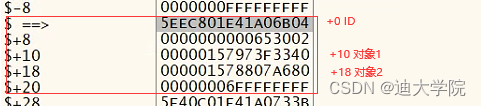
2.目前还不清楚分配存储的是什么信息,那么我们手动进入这2个对象进去看看
3.首先进入对象1,发现在+68的地方就是我们上面用CE搜索出来的数量的偏移,尽管可能不是同一个物品对象但是结构体是一样的
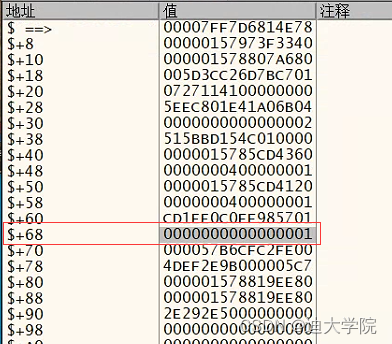
4.在找品质的时候,我们要清楚UE4的一些潜规则!
5.大多数UE4 UE5游戏品质类型规定1为白 2为绿 3为蓝 4为紫 5黄 6橙 7红 不是这些数字全看做白装
6.通过观察我们发现我们背包的基本全是白装,那么品质类型应该是1才对
7.继续观察上面对象1的数据信息,发现了很多1,那么我们尝试修改为2,然后回到游戏观察,结果发现对象1下没有品质属性
8.好,那么我们继续观察,最好搞2个物品的对象1信息比较下
9.发现当前对象1是没有的,但是我们仔细观察到在+80+88的地方有2个对象,目前还不知道是啥,就是看到了也有类似1的存在,我们可以尝试修改下

10.果不其然在+26 一个字节的地方找到了
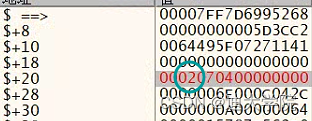

11.多改几次看看
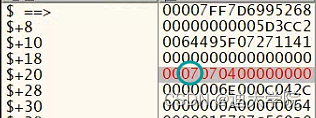

12.这样我们就通过观察对比加上一些潜规则就找到了我们物品的品质类型了!
感谢关注迪大学院:285530835
















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











