







1)需求:根据每个输入文件的行数来规定输出多少个切片。例如每三行放入一个切片中。
2)输入数据:
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dcbanzhang ni hao
xihuan hadoop banzhang dc
3)输出结果:
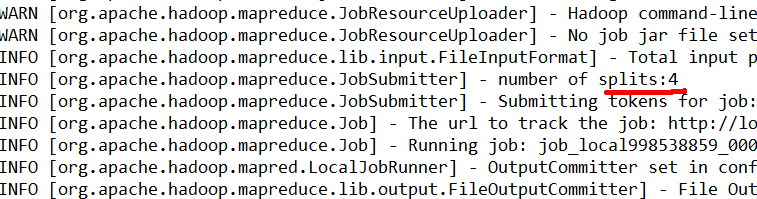
Number of splits:4
4)代码实现:
(1)编写mapper
| package com.atguigu.mapreduce.nline; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
private Text k = new Text(); private LongWritable v = new LongWritable(1);
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行 final String line = value.toString();
// 2 切割 final String[] splited = line.split(" ");
// 3 循环写出 for (int i = 0; i < splited.length; i++) {
k.set(splited[i]);
context.write(k, v); } } } |
(2)编写Reducer
| package com.atguigu.mapreduce.nline; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
public class NLineReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
LongWritable v = new LongWritable();
@Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0l; // 1 汇总 for (LongWritable value : values) { count += value.get(); }
v.set(count);
// 2 输出 context.write(key, v); } } |
(3)编写driver
| package com.atguigu.mapreduce.nline; import java.io.IOException; import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NLineDriver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// 获取job对象 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration);
// 设置每个切片InputSplit中划分三条记录 NLineInputFormat.setNumLinesPerSplit(job, 3);
// 使用NLineInputFormat处理记录数 job.setInputFormatClass(NLineInputFormat.class);
// 设置jar包位置,关联mapper和reducer job.setJarByClass(NLineDriver.class); job.setMapperClass(NLineMapper.class); job.setReducerClass(NLineReducer.class);
// 设置map输出kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class);
// 设置最终输出kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class);
// 设置输入输出数据路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交job job.waitForCompletion(true); } } |
5)结果查看
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dc
banzhang ni hao
xihuan hadoop banzhang dcbanzhang ni hao
xihuan hadoop banzhang dc
(2)输出结果的切片数:















 3668
3668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









