







一.背景及目的
1.感知器的局限性
感知器本质是一个线性分类器:基于多个输入,加权求和,最终经过激活函数进行判别分类。
如图所示:
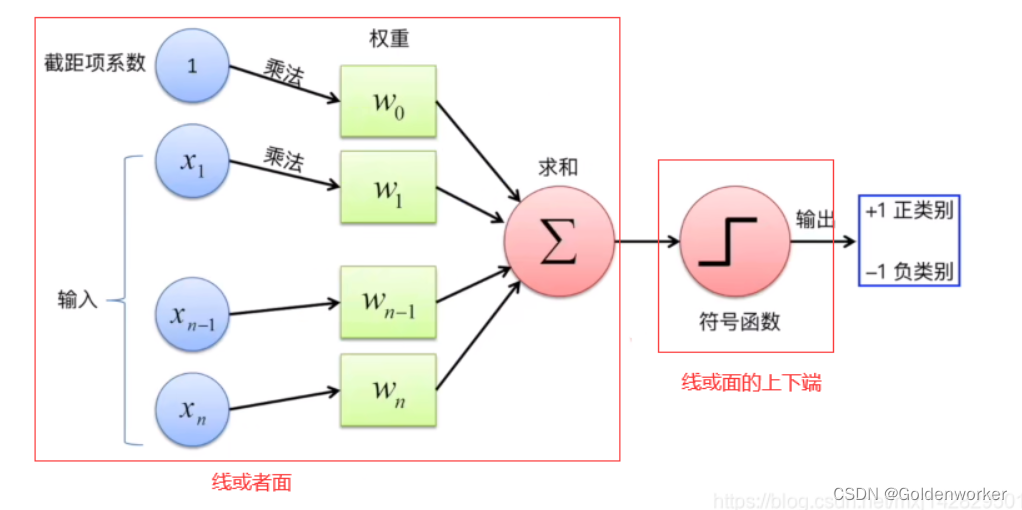
感知器的原理,注定感知器所能得到决策边界只能是一个“平面”。(二维平面里的线,三维空间里的面,或者更高维里的超平面)
如下图所示,对于前三个线性可分的与、或、非等计算,感知器可以通过一条线性的决策边界实现其功能。
但对于第四张图的“异或”,则超出了感知器所能实现的功能,因为他不能通过一条线去划分。
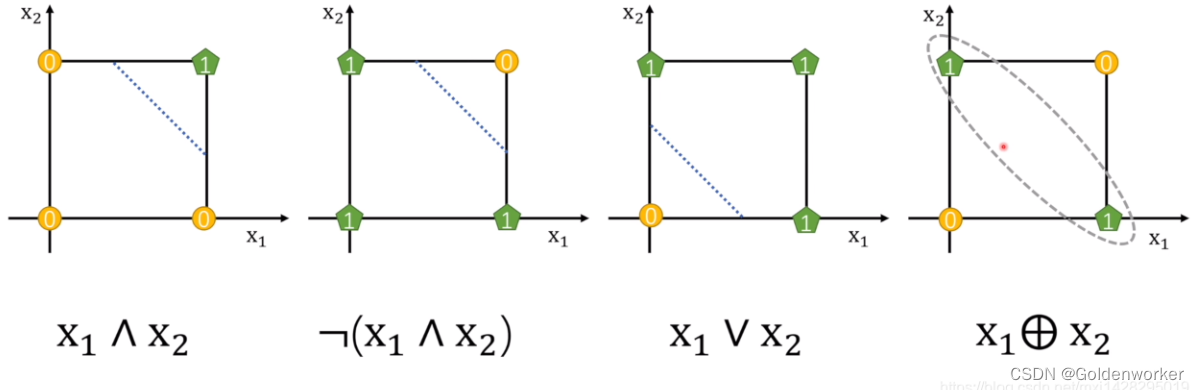
而现实中的问题往往会存在很多这种没法被“一刀两断”的问题,如面临下图所示的数据集。

2.如何解决
在布尔代数中,任何逻辑问题都可以由基本的与或非运算得到。如图所示。
A⊕B=(A∧-B)∨(-A∧B)
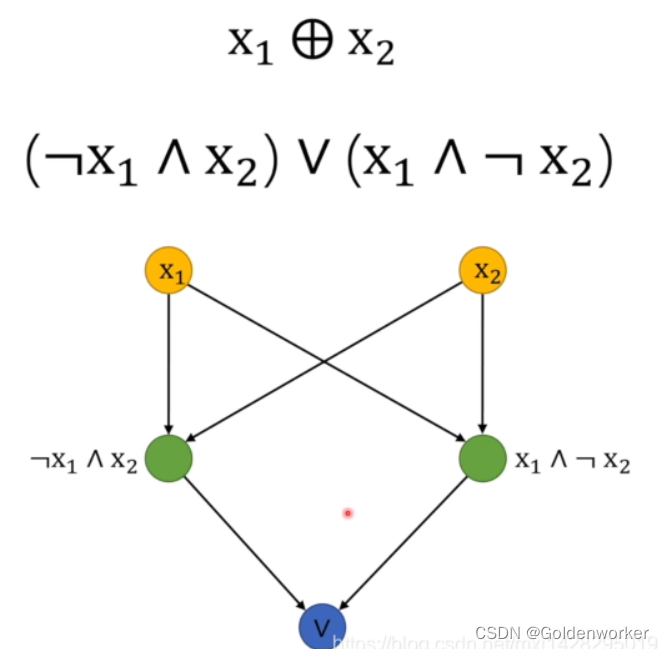
靠两个感知机由让原来,不同状态的变成了相同的状态,由此也启发我们,单层感知器无法实现的功能,可以尝试使用多层感知器来实现。
二.多层感知器实现姓氏分类
1.什么是多层感知器
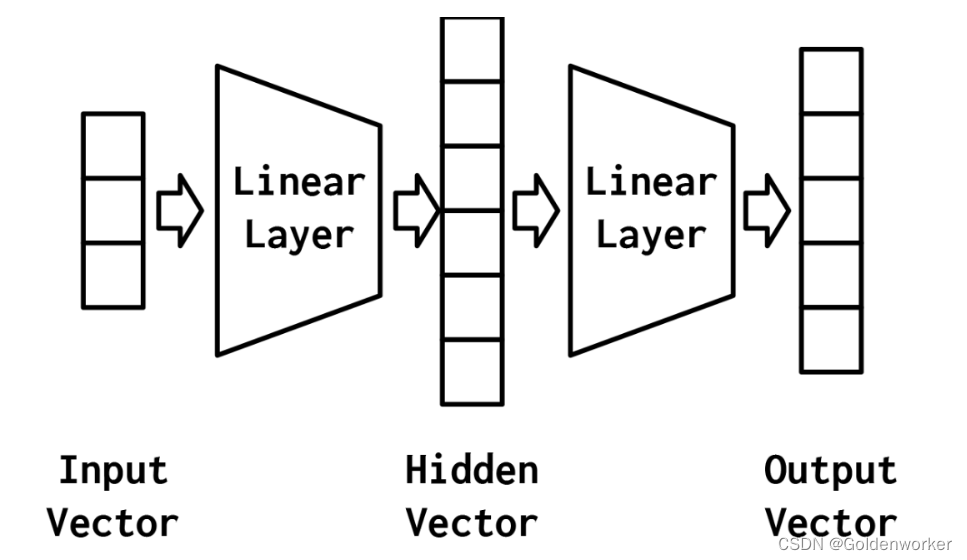
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
2.多层感知器的优势
以解决XOR问题为例,在探讨二元分类任务——区分星形和圆形数据点时,我们利用二维坐标系中的点进行训练。
通过图4-3的展示,我们可以直观地看到最终模型的预测效果。图中,错误分类的数据点用黑色标记以示区别,而正确分类的则保持空白。观察左侧面板,可以发现感知器在寻找一条能够有效分隔星形和圆形的决策边界上遇到了挑战。相比之下,右侧面板中的多层感知器(MLP)则展现出了其优势,成功地学习到了一个更为精确的决策边界,能够更好地对星形和圆形数据点进行分类。这一对比不仅体现了两种模型在处理复杂问题上的能力差异,也直观展示了MLP在解决非线性可分问题时的高效性。
如下图:

3.实现步骤
3.1导入第三方库
# 导入argparse模块,用于处理命令行参数
from argparse import Namespace
# 导入collections模块中的Counter类,用于统计元素出现的次数
from collections import Counter
# 导入json模块,用于处理JSON数据
import json
# 导入os模块,用于处理文件和目录
import os
# 导入string模块,提供一些常用的字符串常量
import string
# 导入numpy模块,用于进行科学计算
import numpy as np
# 导入pandas模块,用于进行数据分析和处理
import pandas as pd
# 导入torch模块,用于进行深度学习相关的操作
import torch
# 导入torch.nn模块,用于定义神经网络模型
import torch.nn as nn
# 导入torch.nn.functional模块,提供一些常用的神经网络函数
import torch.nn.functional as F
# 导入torch.optim模块,用于定义优化器
import torch.optim as optim
# 导入torch.utils.data模块中的Dataset和DataLoader类,用于加载数据集和数据加载器
from torch.utils.data import Dataset, DataLoader
# 导入tqdm模块中的tqdm_notebook函数,用于显示进度条
from tqdm import tqdm_notebook
3.2姓氏数据集
我们定义了一个名为SurnameDataset的类,用于处理姓氏数据集。这个数据集包含了来自18个不同国家的10,000个姓氏。数据集中的姓氏是从互联网上不同的姓名来源收集的。在这个类的课程实验中,我们将多次重用这个数据集,它具有一些有趣的特性。首先,它是相当不平衡的。排名前三的课程占数据的60%以上:27%是英语,21%是俄语,14%是阿拉伯语。剩下的15个民族的频率也在下降——这也是语言特有的特性。第二个特点是,在国籍和姓氏正字法(拼写)之间有一种有效和直观的关系。有些拼写变体与原籍国联系非常紧密(比如“O’Neill”、“Antonopoulos”、“Nagasawa”或“Zhu”)。
为了创建最终的数据集,我们从一个比课程补充材料中包含的版本处理更少的版本开始,并执行了几个数据集修改操作。第一个目的是减少这种不平衡——原始数据集中70%以上是俄文,这可能是由于抽样偏差或俄文姓氏的增多。为此,我们通过选择标记为俄语的姓氏的随机子集对这个过度代表的类进行子样本。接下来,我们根据国籍对数据集进行分组,并将数据集分为三个部分:70%到训练数据集,15%到验证数据集,最后15%到测试数据集,以便在这些部分之间的类标签分布具有可比性。
SurnameDataset类的实现与“示例:餐厅评论情绪分类”中的ReviewDataset几乎相同,只是在__getitem__方法的实现方式上略有不同。回想一下,本课程中呈现的数据集类继承自PyTorch的数据集类,因此,我们需要实现两个函数:__getitem__方法,它在给定索引时返回一个数据点;以及len方法,该方法返回数据集的长度。“示例:餐厅评论的情绪分类”中的示例与本示例的区别在__getitem__中,如示例4-5所示。它不像“示例:将餐馆评论的情绪分类”那样返回一个向量化的评论,而是返回一个向量化的姓氏和与其国籍相对应的索引。
class Vocabulary(object):
"""Class to process text and extract vocabulary for mapping"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): a pre-existing map of tokens to indices
add_unk (bool): a flag that indicates whether to add the UNK token
unk_token (str): the UNK token to add into the Vocabulary
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
# 创建一个反向映射字典,将索引映射到对应的token
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
""" returns a dictionary that can be serialized """
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
""" instantiates the Vocabulary from a serialized dictionary """
return cls(**contents)
def add_token(self, token):
"""Update mapping dicts based on the token.
Args:
token (str): the item to add into the Vocabulary
Returns:
index (int): the integer corresponding to the token
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""Add a list of tokens into the Vocabulary
Args:
tokens (list): a list of string tokens
Returns:
indices (list): a list of indices corresponding to the tokens
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""Retrieve the index associated with the token
or the UNK index if token isn't present.
Args:
token (str): the token to look up
Returns:
index (int): the index corresponding to the token
Notes:
`unk_index` needs to be >=0 (having been added into the Vocabulary)
for the UNK functionality
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""Return the token associated with the index
Args:
index (int): the index to look up
Returns:
token (str): the token corresponding to the index
Raises:
KeyError: if the index is not in the Vocabulary
"""
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
3.3将姓氏字符串转换为向量化的minibatches
利用词汇表、向量化器和DataLoader进行姓氏分类
为了对姓氏进行字符级分类,我们采用了一系列数据结构——词汇表、向量化器和DataLoader——将姓氏字符串转换成向量化的minibatches。这些工具在结构上与“餐厅评论情绪分类示例”中使用的相似,但在这里我们处理的是字符级别的数据,而非单词级别的数据。这种处理方式展示了一种多态性,即不区分字符标记和单词标记。在本例中,数据的向量化不是通过将单词映射到整数实现的,而是通过将字符映射到整数来完成。
词汇表类(Vocabulary Class)
本例中的词汇表类与“餐厅评论情绪分类示例”中的相同,负责将字符映射到对应的整数索引。简单来说,词汇表由两个Python字典组成,它们在字符(本例中)和整数之间建立双向映射。`add_token` 方法用于向词汇表中添加新令牌,`lookup_token` 方法用于检索索引,而 `lookup_index` 方法则用于在推断阶段检索给定索引的字符。与Yelp评论的词汇表不同,这里的词汇表是one-hot类型的,不计算字符出现的频率,仅对频繁出现的条目进行限制,因为数据集较小且大多数字符的出现频率足够高。
姓氏向量化器(SurnameVectorizer)
虽然词汇表将单个字符转换为整数,但SurnameVectorizer的职责在于应用这个词汇表,将姓氏转换为向量。其初始化和使用过程与“餐厅评论情绪分类示例”中的ReviewVectorizer非常类似,但有一个关键区别:字符串没有被空格分割。由于姓氏是由一系列字符组成的,每个字符在我们的词汇表中都是一个独立的标记。在引入“卷积神经网络”之前,我们将忽略序列信息,通过迭代字符串中的每个字符来创建输入的收缩one-hot向量表示。对于之前未遇到的字符,我们指定了一个特殊的令牌,即UNK。由于词汇表仅从训练数据实例化,且验证或测试数据中可能包含唯一的字符,因此在字符词汇表中仍然使用UNK符号。
虽然在这个示例中我们使用了收缩的one-hot编码,但在后续实验中,我们将探索其他向量化方法,这些方法有时比one-hot编码更优。具体来说,在“使用CNN对姓氏进行分类的示例”中,我们将看到一个热门矩阵,其中每个字符都对应矩阵中的一个位置,并拥有自己的热门向量。接着,在实验5中,我们将学习嵌入层、返回整数向量的向量化以及如何使用它们创建密集向量矩阵。接下来,请参考示例中的SurnameVectorizer代码。
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab):
"""
Args:
surname_vocab (Vocabulary): maps characters to integers
nationality_vocab (Vocabulary): maps nationalities to integers
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot (np.ndarray): a collapsed one-hot encoding
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









