







文章目录
1. Pod生命周期
主要包括两类容器和两种探针(存活和就绪)
在k8s中,google为k8s准备了一个镜像pause,用来准备Pod的基础环境,作为容器环境初始化。初始化容器可以有多个,并且每个只能在上一个结束后才能开始运行。有时需要将环境初始化容器与应用容器分开。Liveness作为探针时刻检测应用容器是否在工作,readiness为可用性探针。
官方文档:Pod生命周期
- Pod可以包含多个容器,应用运行在这些容器里面,同时Pod也可以有一个或多个先与应用容器启动的Init容器
- Init容器与普通容器非常像,除以下两点:
– 它们总是运行到完成(运行到完毕)
– Init容器不支持Readliness,因为他们必须在Pod就绪之前就运行完成,每个Init容器必须运行成功,下一个才能够运行。 - 如果Pod的Init容器失败,k8s会不断的重启该Pod,知道Init容器成功为止。然而,如果Pod对应的restartPolicy值为never,它不会重新启动
Init容器能做什么?
- Init容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码,分开的好处是可以让应用镜像表小
- Init容器可以安全的运行这些工具,避免这些工具导致应用镜像的安全性降低
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像
- Init容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问Secrets的权限,而应用容器不能够访问
- 由于Init容器必须在应用容器启动前运行完成,因此Init容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先诀条件。一旦前置条件满足,Pod内所有的应用容器会并行启动
重启策略:
- PodSpec中有一个restartPolicy字段,可能的值为Always,OnFailure和Never。默认为Always
Pod的生命
- 一般Pod不会消失,直到人为的销毁
- 建议创建适当的控制器来创建Pod,而不是直接自己创建Pod。因为单独的Pod在机器故障的情况下没有办法自动复原,而控制器可以
- 三种可用的控制器
– 使用Job运行预期会终止的Pod,例如批量计算。Job仅适用于重启策略为OnFailure或Never的Pod
– 对预期不会终止的Pod使用ReplicationController,ReplicaSet和Deployment,例如Web服务器。ReplicationController仅适用于工具有restartPolicy为always的Pod
提供特定于机器的系统服务,使用DaemonSet为每台机器运行一个Pod
2. 控制器
2.1 控制器分类
Pod的分类:
- 自主式Pod:Pod退出后不会被创建
- 控制器管理的Pod:在控制器的生命周期里,始终要维持Pod的副本数目
控制器类型:
- Replication Controller(RC)和ReplicaSet(RS)生产环境暂时RS已替代RC
- Deployment 最常用
- DaemonSet
- StatefulSet
- Job
- CronJob
- HPA全称Horizontal Pod Autoscaler
2.2 具体简介
2.2.1 RC和RS
- RS是下一代的RC,官方推荐使用RS
- RS和RC的唯一区别是选择器的支持,RS支持新的基于集合的选择器需求
- RS确保任何时间都有指定数量的Pod副本在运行
- 虽然RS可以独立使用,但是今天主要被Deployments用作协调Pod创建,删除和更新的机制
2.2.2 Deployment
- Deployment为Pod和RS提供了一个申明式的定义方法
- 典型的应用场景
– 用来创建Pod和PS
– 滚动更新和回滚
– 扩容和缩容
– 暂停和恢复
2.2.3 DaemonSet
- DaemonSet确保全部(或者某些)节点上运行一个Pod副本。当有节点加入集群时,也会为他们新增一个Pod。当有节点从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod
- DaemonSet的典型用法:
– 在每个节点上运行集群储存DaemonSet,将被作为每种类型的daemon使用
– 一个稍微复杂的用法是单独对每种daemon类型使用多个DaemonSet,但具体不同的标志,并且对不同硬件类型具有不同的内存,CPU要求。
2.2.4 StatefuSet
- StatefulSet是用来管理有状态应用的工作负载API对象,实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,称为“有状态应用”
- StatefulSet用来管理Deployment和扩展一组Pod,并且能为这些Pod提供序号和唯一性保证
- StatefuSets对于需要满足以下一个或多个需求的应用程序很有价值:
– 稳定的,唯一的网络标识符
– 稳定的,持久的储存
– 有序的,优雅的部署和缩放
– 有序的,自动的滚动更新
2.2.5 其他
Job:执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束
CronJob:
- CronJob创建基于时间调度的Jobs
- 一个Cronob对象就像crontab(cron table)文件中的一行,他用cron格式进行编写,并周期性的在给定的调度时间执行Job
HPA:根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放
2.3 控制器清单
2.3.1 RS控制器
vim rs.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset-example
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v1
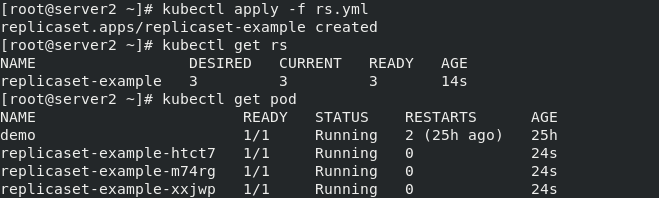
RS控制器一般不会单独有,一般和Deployment一起用,主要功能就是控制副本
删除RS控制器:kubectl delete rs replicaset-example
2.3.2 Deployment控制器
和上述的RS很像:
apiVersion: apps/v1
kind: Deployment
metadata:
name: Deployment-example
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v1
deployment控制rs,rs控制Pod
控制器是根据Pod标签实现对Pod的控制:

若对其中已有的Pod修改其名称:kubectl label pod deployment-6456d7c676-2lzmq app=myapp --overwrite
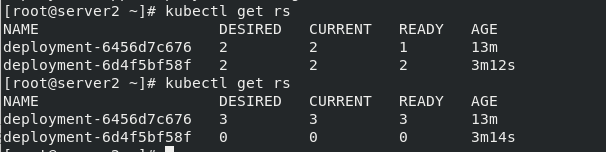
则会多出一个Pod:

这是由于控制清单上定义了3个nginx标签,rs控制器通过匹配标签来保证时刻有3个Pod在运行,改名后RS会自动拉伸。新打标签的Pod由于不在控制器控制范围内,所以此时删除等操作不会受RS控制器控制
此时若版本更新,myapp标签的Pod不会更新:

更新完成后的RS策略不会删除:

在版本回滚时会重新使用:
2.3.3 DaemonSet控制器
适用于集群节点上的信息采集和监控
一般每个节点部署一个,如zabbix agent,此时已在harbor仓库准备好了zabbix-agent镜像
vim daemonset.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset
labels:
k8s-app: zabbix-agent
spec:
selector:
matchLabels:
name: zabbix-agent
template:
metadata:
labels:
name: zabbix-agent
spec:
containers:
- name: zabbix-agent
image: zabbix-agent
可看到在每个节点上部署了一个:

此时若再新加一个集群节点,则会立马在新节点上继续部署一个
2.3.4 Job控制器
用于一次性执行任务,如集群的辈份任务,计算圆周率,在此提前准备perl镜像:
vim job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
perl镜像过大,大几百M,此处跳过
2.3.5 Cronjob控制器
周期性的执行任务
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure

官方文档:使用Cronjob运行自动化任务














 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









