






基于Python的图片批量切割与合并(保持原像素不变,不会出现像素大小不匹配、填充黑边的问题)
前言
1、本文介绍了基于Python实现的图片切割后按原尺寸合并还原的方法。
2、本文前面详细介绍了各个方法,文末提供了完整代码。
3、本文需要自行填充一些路径,具体请看文末完整代码中的中文信息。
4、本文适配的MacOS解决了目录会自动生成.DS_Store文件的问题。
5、本文的逻辑将会是从切割到复原的全部流程,代码并不会在切割之后停下。
5、本文的逻辑中,存放切割后小图片的目录是作为临时目录,在对下一张图片处理之前将会把此文件夹清空,若需要对小图片做一些操作,可以在文末完整代码对应位置上添加流程。
在一般的图像切割与合并博文中,基本都不会考虑固定尺寸切割最后会导致尺寸损失或尺寸变大,体现就是图片的像素变少了,或者加上了没必要的多余像素。
本文在基于网络上的一些切割合并图像文章之后,实现了对一个目录内所有的图像进行切割、合并的操作,并且能保持像素数量与原图尺寸,不会出现图像尺寸的变化。
效果图
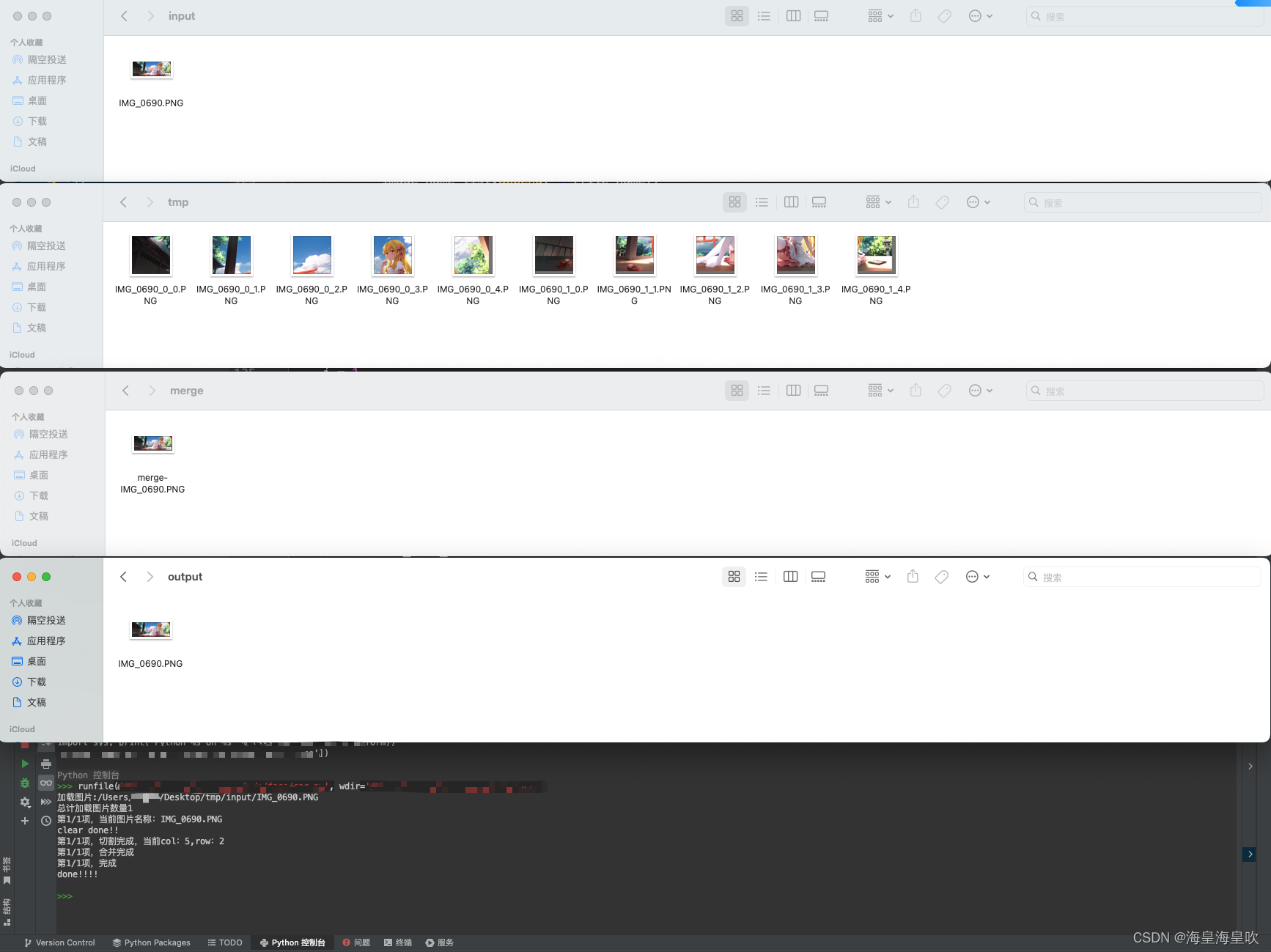
1、批量读取文件
调用os,读取目录下的所有文件,同时排除了MacOS系统自动生成的.DS_Store文件。
# 加载图片列表
def round_read_file(file_path):
image_name_list = []
for file_name in os.listdir(file_path):
# 排除MacOS的.DS_Store文件,Windows下不受影响。
if file_name != '.DS_Store':
print("加载图片:"+str(file_path)+str(file_name))
image_name_list.append(str(file_name))
print("总计加载图片数量" + str(len(image_name_list)))
return image_name_list
2、清空目标目录方法(配合切割图片方法使用)
# 清空TEMP
# dir_path:需要清空的目录路径
def del_files(dir_path):
# os.walk会得到dir_path下各个后代文件夹和其中的文件的三元组列表,顺序自内而外排列,
for root, dirs, files in os.walk(dir_path, topdown=False):
# 第一步:删除文件
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
# 第二步:删除空文件夹
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除一个空目录
print("clear done!!")
3、批量切割图片(像素不足自动补全)
# 切割
# orgPath:加载图片所在路径
def qg(orgPath):
del_files("切割后的小图片要保存在的目录/")
global static_cols
global static_rows
# 目标分割大小
DES_HEIGHT = 1500
DES_WIDTH = 1500
# 获取图像信息
path_img = orgPath
# 获取原始高分辨的图像的属性信息
src = cv2.imread(path_img)
height = src.shape[0]
width = src.shape[1]
# 把原始图像边缘填充至分割大小的整数倍
padding_height = math.ceil(height / DES_HEIGHT) * DES_HEIGHT
padding_width = math.ceil(width / DES_WIDTH) * DES_WIDTH
# 将padding图像与原始图像进行融合,使得原始
padding_img = np.random.randint(0, 255, size=(padding_height, padding_width, 3)).astype(np.uint8)
padding_img[0:height + 0, 0:width + 0] = src
img = padding_img # 读取彩色图像,图像的透明度(alpha通道)被忽略,默认参数;灰度图像;读取原始图像,包括alpha通道;可以用1,0,-1来表示
sum_rows = img.shape[0] # 高度
sum_cols = img.shape[1] # 宽度
cols = DES_WIDTH
rows = DES_HEIGHT
save_path = "切割后的小图片要保存在的目录/".format(cols, rows) # 切割后的照片的存储路径
static_rows = int(sum_rows / rows)
static_cols = int(sum_cols / cols)
filename = os.path.split(path_img)[1]
for i in range(int(sum_cols / cols)):
for j in range(int(sum_rows / rows)):
cv2.imwrite(
save_path + os.path.splitext(filename)[0] + '_' + str(j) + '_' + str(i) + os.path.splitext(filename)[1],
img[j * rows:(j + 1) * rows, i * cols:(i + 1) * cols, :])
4、切割图片合成大图片(此处并不是最终处理完成)
# 合并分割图像,指定行列数
# merge_path:切割后的小图片所在路径
# num_of_cols:多少列
# num_of_rows:多少行
# target_path:合成后的目标图片保存路径
# file_name:合成后的文件名称
def merge_picture(merge_path, num_of_cols, num_of_rows, target_path, file_name):
filename = os.listdir(merge_path)
# 排除MacOS的.DS_Store文件
if filename[0] == '.DS_Store':
filename.remove('.DS_Store')
full_path = os.path.join(merge_path, filename[0])
shape = cv2.imread(full_path).shape # 三通道的影像需把-1改成1
cols = shape[1]
rows = shape[0]
channels = shape[2]
dst = np.zeros((rows * num_of_rows, cols * num_of_cols, channels), np.uint8)
for i in range(len(filename)):
full_path = os.path.join(merge_path, filename[i])
img = cv2.imread(full_path, -1)
cols_th = int(full_path.split("_")[-1].split('.')[0])
rows_th = int(full_path.split("_")[-2])
roi = img[0:rows, 0:cols, :]
dst[rows_th * rows:(rows_th + 1) * rows, cols_th * cols:(cols_th + 1) * cols, :] = roi
cv2.imwrite(target_path + "merge-" + file_name, dst)
5、最终处理(根据原图的尺寸,将多余的像素去除)
# 最终尺寸切割
# real_org_file_path:真正的原图所在的文件夹
# real_org_file_name:真正的原图的名称
# org_path:合成后的带有多余像素的图片所在路径
# fin_path:最终成品图保存的位置
# org_file_name:合成后带有多余像素的图片名字
# fin_file_name:最终成品图的名字
def cp(real_org_file_path, real_org_file_name, org_path, fin_path, org_file_name, fin_file_name):
from PIL import Image
img = Image.open(org_path+org_file_name) # 打开chess.png文件,并赋值给img
org_img = Image.open(real_org_file_path+real_org_file_name)
region = img.crop((0, 0, org_img.width, org_img.height)) # 0,0表示要裁剪的位置的左上角坐标,w长 h宽。
region.save(fin_path+fin_file_name) # 将裁剪下来的图片保存
6、完整代码
import math
import os
import cv2
import numpy as np
from PIL import Image
Image.MAX_IMAGE_PIXELS = 2300000000
static_cols = -1
static_rows = -1
# 清空TEMP
# dir_path:需要清空的目录路径
def del_files(dir_path):
# os.walk会得到dir_path下各个后代文件夹和其中的文件的三元组列表,顺序自内而外排列,
for root, dirs, files in os.walk(dir_path, topdown=False):
# 第一步:删除文件
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
# 第二步:删除空文件夹
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除一个空目录
print("clear done!!")
# 切割
# orgPath:加载图片所在路径
def qg(orgPath):
del_files("切割后的小图片要保存在的目录/")
global static_cols
global static_rows
# 目标分割大小
DES_HEIGHT = 1500
DES_WIDTH = 1500
# 获取图像信息
path_img = orgPath
# 获取原始高分辨的图像的属性信息
src = cv2.imread(path_img)
height = src.shape[0]
width = src.shape[1]
# 把原始图像边缘填充至分割大小的整数倍
padding_height = math.ceil(height / DES_HEIGHT) * DES_HEIGHT
padding_width = math.ceil(width / DES_WIDTH) * DES_WIDTH
# 将padding图像与原始图像进行融合,使得原始
padding_img = np.random.randint(0, 255, size=(padding_height, padding_width, 3)).astype(np.uint8)
padding_img[0:height + 0, 0:width + 0] = src
img = padding_img # 读取彩色图像,图像的透明度(alpha通道)被忽略,默认参数;灰度图像;读取原始图像,包括alpha通道;可以用1,0,-1来表示
sum_rows = img.shape[0] # 高度
sum_cols = img.shape[1] # 宽度
cols = DES_WIDTH
rows = DES_HEIGHT
save_path = "切割后的小图片要保存在的目录/".format(cols, rows) # 切割后的照片的存储路径
static_rows = int(sum_rows / rows)
static_cols = int(sum_cols / cols)
filename = os.path.split(path_img)[1]
for i in range(int(sum_cols / cols)):
for j in range(int(sum_rows / rows)):
cv2.imwrite(
save_path + os.path.splitext(filename)[0] + '_' + str(j) + '_' + str(i) + os.path.splitext(filename)[1],
img[j * rows:(j + 1) * rows, i * cols:(i + 1) * cols, :])
# 合并分割图像,指定行列数
# merge_path:切割后的小图片所在路径
# num_of_cols:多少列
# num_of_rows:多少行
# target_path:合成后的目标图片保存路径
# file_name:合成后的文件名称
def merge_picture(merge_path, num_of_cols, num_of_rows, target_path, file_name):
filename = os.listdir(merge_path)
# 排除MacOS的.DS_Store文件
if filename[0] == '.DS_Store':
filename.remove('.DS_Store')
full_path = os.path.join(merge_path, filename[0])
shape = cv2.imread(full_path).shape # 三通道的影像需把-1改成1
cols = shape[1]
rows = shape[0]
channels = shape[2]
dst = np.zeros((rows * num_of_rows, cols * num_of_cols, channels), np.uint8)
for i in range(len(filename)):
full_path = os.path.join(merge_path, filename[i])
img = cv2.imread(full_path, -1)
cols_th = int(full_path.split("_")[-1].split('.')[0])
rows_th = int(full_path.split("_")[-2])
roi = img[0:rows, 0:cols, :]
dst[rows_th * rows:(rows_th + 1) * rows, cols_th * cols:(cols_th + 1) * cols, :] = roi
cv2.imwrite(target_path + "merge-" + file_name, dst)
# 最终尺寸切割
# real_org_file_path:真正的原图所在的文件夹
# real_org_file_name:真正的原图的名称
# org_path:合成后的带有多余像素的图片所在路径
# fin_path:最终成品图保存的位置
# org_file_name:合成后带有多余像素的图片名字
# fin_file_name:最终成品图的名字
def cp(real_org_file_path, real_org_file_name, org_path, fin_path, org_file_name, fin_file_name):
from PIL import Image
img = Image.open(org_path+org_file_name) # 打开chess.png文件,并赋值给img
org_img = Image.open(real_org_file_path+real_org_file_name)
region = img.crop((0, 0, org_img.width, org_img.height)) # 0,0表示要裁剪的位置的左上角坐标,w长 h宽。
region.save(fin_path+fin_file_name) # 将裁剪下来的图片保存
# 加载图片列表
def round_read_file(file_path):
image_name_list = []
for file_name in os.listdir(file_path):
# 排除MacOS的.DS_Store文件,Windows下不受影响。
if file_name != '.DS_Store':
print("加载图片:"+str(file_path)+str(file_name))
image_name_list.append(str(file_name))
print("总计加载图片数量" + str(len(image_name_list)))
return image_name_list
# 主函数
if __name__ == '__main__':
main_tmp_path = '切割后的小图片所保存的目录路径/'
main_org_path = '真正的原图所在目录路径/'
main_merge_path = '第一次合成之后带多余像素的图片所保存的路径/'
main_fin_path = '最终成品所在的路径/'
main_img_name_list = round_read_file(main_org_path)
i = 1
for main_file_name in main_img_name_list:
print("第" + str(i) + "/" + str(len(main_img_name_list)) + "项," + "当前图片名称:" + main_file_name)
qg(main_org_path+main_file_name)
print("第" + str(i) + "/" + str(len(main_img_name_list)) + "项,切割完成,当前col:"+str(static_cols)+",row:" + str(static_rows))
################################################
#可在此处添加对小图的处理,例如某些对图片尺寸有要求的API#
################################################
merge_picture(main_tmp_path, static_cols, static_rows, main_merge_path, main_file_name)
print("第" + str(i) + "/" + str(len(main_img_name_list)) + "项,合并完成")
cp(main_org_path, main_file_name, main_merge_path, main_fin_path, str("merge-" + main_file_name), main_file_name)
print("第" + str(i) + "/" + str(len(main_img_name_list)) + "项,完成")
static_rows = -1
static_cols = -1
i = i + 1
print("done!!!!")















 2856
2856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









