










五种不同的自适应分解方法在脑电信号癫痫检测和分类中的应用
文章目录
摘要
在癫痫研究中,信号处理和机器学习方法是很有价值的工具,有可能在长期监测中帮助诊断、癫痫检测、预测和实时事件检测。最近的方法涉及以数据相关和自适应的方式将EEG信号分解为不同的模式,这在处理非线性和非平稳数据时可能比常用的基于傅立叶的方法具有优势。这些方法包括经验模态分解(EMD)、扩展EMD(EEMD)、带自适应噪声的完整EEMD(CEEMDAN)、经验小波变换(EWT)和变分模式分解(VMD)。在这项工作中,从原始未分解信号和上述自适应分解方法中提取的特征集被用于使用两个免费可用的数据集对EEG发作数据进行分类。我们提供了一种以前不可用的通用方法,用于比较这些方法在使用相同的分类器、参数以及频谱和时域特征时的性能。总的来说,评估的分解方法之间的结果相似,VMD和CEEMDAN的值略高。从原始未分解信号中提取的特征导致较低的类别可分性,但使用特定的分类器仍然可以实现相当准确的预测。经过评估的分解方法对于癫痫检测是很有前途的方法,但应谨慎分析它们的使用,尤其是在需要实时处理和计算能力的情况下。这项工作的另一个贡献是为EWT(ewtpy)和VMD(vmdpy)开发python包,PyPI存储库已经提供了这些包。
1 引言
癫痫是一种负担沉重的神经系统疾病,其患病率约为每1000人6例,发病率为61/每1000人-年[1]。导致其高发病率的因素之一是导致这种情况的大量原因,例如:遗传易感性、发育不良、脑血管病(CVD)、创伤、肿瘤、感染、缺血等[2]。
反复发作被认为是癫痫的特征。这些事件反映了大脑中神经元群的异常放电,通常是同步的和高强度的[3]。这种对神经元正常功能模式的偏离可能引发各种感觉,从奇怪的感觉、行为和感觉到肌肉痉挛发作和可能丧失良知[4]。
脑电图(EEG)是一种高时间分辨率的脑电活动记录,是诊断癫痫和其他神经系统疾病的基本方法。EEG可以反映发作期(即癫痫发作)或发作间期的异常神经元活动,例如发作间期出现的剧烈瞬变[5]。这些信号通常由经验丰富的神经学家通过视觉检查进行解释,并考虑到波形的频率、振幅和规律性、对刺激的反应性、信号异常的空间范围和时间持续性等特征[6]。然而,这种方法可能会很麻烦和耗时,尤其是对于长系列和多通道数据,这可能会导致假阴性结果的比率越来越高。此外,还有一系列微妙的信号特征和成分,以及通道间的关系,这些几乎不可能通过简单的视觉检查来检测。这项任务可以由信号处理和分类算法[7]来辅助,这些算法可以处理信号的非线性和微妙性、高维数据和实时处理。因此,这些自动化方法是诊断、检测和预测癫痫和癫痫发作的有价值的工具[8]。
为了提取与癫痫现象相关的特征,已经开发了多种算法和信号处理技术[9]。并不总是推荐使用傅里叶变换分析频率分量的方法,因为EEG信号包含非平稳分量,违反了使用这种变换的条件[10]。因此,最近用于癫痫患者脑电图分析的方法可能使用时频方法,或非线性方法,如李亚普诺夫指数、分形维数、熵或关联维数[11]。其他方法包括以自适应方式使用信号分解,如Huang等人[10]提出的经验模式分解(EMD)。
EMD是一种自适应的、依赖于数据的分解方法,它可以连续提取由调幅(AM)和调频(FM)分量定义的本征模函数(IMF)。因此,复杂的非线性和非平稳信号可以分解为有限数量的IMF,每个IMF都具有良好的希尔伯特变换[10]。已经提出了EMD方法的扩展,以处理多变量数据[12,13],并缓解模式混合问题——当同一个IMF中存在大不相同尺度的信号振幅,或具有相似尺度的信号被划分为不同的IMF分量[14,15]。后者的例子包括集成经验模式分解(EEMD)[15]和带自适应噪声的完整集成EMD(CEEMDAN)[14]。EMD及其扩展[16,17]已成功用于癫痫研究[16-21]。然而,诸如计算成本、缺乏理论(由于其算法方法)以及难以解释大量模式等缺点促使人们在癫痫脑电信号中使用和评估不同的自适应分解方法[22]。
经验小波变换(EWT)[22]解决了EMD的一些局限性。通过采用一些小波形式,该方法设计适当的小波滤波器组,并将信号分解为预定数量的模式。EWT的使用已在不同领域进行了探索,如心电图(ECG)信号的压缩[23]、地震活动的分解[24]和非平稳信号的时频表示[25]。虽然小波在癫痫检测和分类中的应用已经得到了广泛的探索[6,26–28],但很少有研究评估EWT处理癫痫EEG信号[29,30]。
变分模式分解[31](VMD)的自适应方法将信号自适应和非递归地分解为其主要模式。该方法与所谓的维纳滤波器有关,这一特性使其在噪声鲁棒性方面具有优势。与EWT的情况类似,很少有研究评估VMD用于癫痫脑电图分析[32–34]。
当从发作现象中处理EEG时,使用上述分解方法生成的特征是有前途的工具。除了自适应能力和处理非线性和非平稳信号的能力外,提取的模式(或信号分量)围绕特定的中心频率紧凑,并且具有良好的希尔伯特变换。这使得能够提取与振幅或带宽调制以及瞬时相位和振幅相关的特征。这项工作的目的是通过提取相同的特征集和分类器,使用一个免费的数据库和一种通用的方法,比较不同的自适应分解方法用于脑电信号癫痫检测。到目前为止,这一比较不仅受到少数使用EWT和VMD的作品的阻碍,还受到以下事实的阻碍:在癫痫检测文献中,EMD、EEMD、CEEMDAN、VMD和EWT使用不同的方法进行评估。在这项工作中,还将结果与从原始未分解信号中提取的特征进行了比较。预期结果是使用自适应分解方法(EMD、EEMD、CEEMDAN、EWT和VMD)提高性能,但它们之间的总体性能相似。
这项工作的其余部分分为三个部分。第二节介绍了所使用的方法,包括所使用的数据、分解方法、提取特征的描述和分类问题。在第3节中,给出了这两个数据集的结果,然后是第4节中的讨论。结束语留给最后一节。
2 - 方法
2.1 数据集
这项工作使用两个公共在线EEG数据集:(i)一个是由波恩大学提供的,并且通常被用作癫痫检测算法的基准,和(ii)另一个来自新德里Hauz Khas神经和睡眠中心(NSC-ND)的癫痫患者(NSC-ND)。
2.1.1. 波恩大学(UOB)数据集
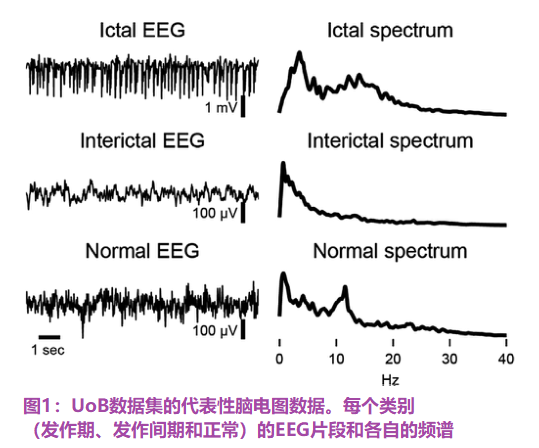
将该数据集分为5个子集:Z、O、N、F、S(或A、B、C、D、E)。每个子集包含100个时间序列,采样频率为173.6 Hz,持续时间为23.6秒。Z类和O类分别对应于5名健康志愿者在睁眼和闭眼时的表面脑电图记录。其余的亚群属于癫痫患者的术前记录。集合S包含癫痫发作活动,而集合F和N来自无癫痫发作间隔,电极分别放置在致痫区和对侧海马。这项工作涉及一个分类问题,使用三个子集:S、F和Z(E、D和a),分别对应于发作期、发作间期和正常类别。图1显示了每个类别的样本及其正则化光谱,由每个信号的高斯滤波快速傅里叶变换(FFT)给出。该数据集处理的第一阶段包括应用截止频率为40 Hz的零相位四阶低通巴特沃斯滤波器[35]。
2.1.2. 新德里神经病学和睡眠中心(NSC-ND)
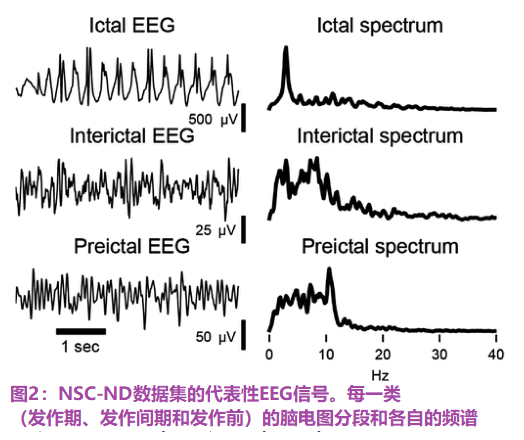
该数据集包含在新德里Hauz Khas神经病学和睡眠中心获得的分段脑电图记录。每个信号以200 Hz的频率采样,从0.5 Hz到70 Hz进行带通滤波,并在5.12 s的窗口中分段[37]。每个脑电图片段被分为三类——发作前、发作间期和发作期(分别为X、Y和Z组)。使用的数据集由[38]上一名患者的150个片段组成(每个类别50个片段)。图2显示了该数据集中每类样本的EEG数据和各自的皮普。这项工作考虑了该数据集的两个分类问题:(i)发作间期与发作期(Y-Z)和(ii)所有三个类别(发作前、正常和发作期–X-Y-Z)。
2.2. 分析方法和自适应分解方法
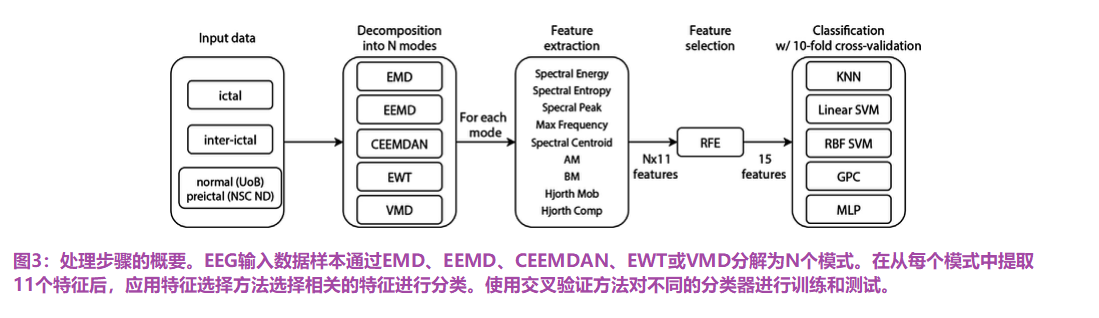
图3给出了以下分析步骤的概要。简而言之,信号通过EMD、EEMD、CEEMDAN、EWT或VMD分解为N个模式或IMFs。然后是每个模式的特征提取和随后的特征选择,为所选分类器定义一组输入。接下来,计算每个分类器的性能指标,从而评估用于癫痫检测和分类的每个自适应分解方法。以下各节对每个处理步骤进行了总结。

2.2.1 经验模态分解(EMD)
EMD是一种有趣的方法,因为它的适应性,不依赖于线性或平稳性等假设。这种方法的目的是将分析的信号划分为一系列固有模式函数(IMF),其中每个IMF必须满足两个相对简单的条件:
- 极值的数量必须与过零点的数量相等或相差一(最多)。
- 由局部最大值和最小值定义的平均包络值必须等于零。
Huang等人[10]提出的获得IMF的算法由以下步骤描述的筛选过程组成:给定输入时间序列 f ( t ) f(t) f(t),
- 求时间序列的局部极大值和极小值。
- 分别通过极大值和极小值的三次样条插值生成包络 e m a x emax emax和 e m i n emin emin。
- 计算包络线的平均值: m i ( t ) = ( e m a x ( t ) + e m i n ( t ) ) / 2 m_i(t)=(emax(t)+emin(t))/2 mi(t)=(emax(t)+emin(t))/2
- 从信号中减去之前发现的值: h ( t ) = f ( t ) − m i ( t ) h(t)=f(t)-m_i(t) h(t)=f(t)−mi(t)。
- 检查提取的信号 h ( t ) h(t) h(t)是否满足两个IMF条件(零均值和最大值/最小值的数量)。如果满足该条件,则找到IMF c i ( t ) = h ( t ) c_i(t)=h(t) ci(t)=h(t)。否则,对提取的信号重复步骤1-5。
- 生成一个新的残差 r ( t ) = f ( t ) − c i ( t ) r(t)=f(t)-c_i(t) r(t)=f(t)−ci(t)。
重复步骤1至5,应用于残差 r r r,以找到剩余的IMF。当无法再根据残差计算IMF时,该过程停止,然后将残差定义为最终残差 r M r_M rM。
因此,除了残差
r
M
r_M
rM之外,该信号还被分解为确定数量的IMFs
c
i
(
t
)
c_i(t)
ci(t),如(1)所示:
f
(
t
)
=
r
M
+
∑
i
=
1
N
c
i
(
t
)
f(t)=r_M+\sum_{i=1}^{N}c_i(t)
f(t)=rM+∑i=1Nci(t)
其中N是找到的IMFs的数量。
与离散小波变换等先提取低频(或近似值)后提取细节(对应于更高频率)的方法不同,EMD分离的第一个IMF对应于信号的高频,而较慢的分量则通过筛选过程逐步提取。
2.2.2 集合经验模态分解(EEMD)
EEMD是一种噪声辅助数据分析(NADA)方法,在该方法中,通过对原始信号的噪声版本集合的分解结果求平均值来获得结果模态15]。这旨在消除模态混叠问题,并保持感兴趣信号分解的物理唯一性。简而言之,该方法包括以下步骤:
- 将白噪声添加到目标输入序列
- 将结果信号加上步骤1中的噪声分解为IMF
- 使用不同的白噪声信号依次重复步骤1和步骤2
- 计算分解的相应IMF的集合平均值作为最终结果
虽然该方法解决了模式混合问题,但EEMD存在缺陷,例如重建的EEMD信号中存在残余噪声,相同输入数据的不同实现产生不同数量的模式。为了克服这些问题,提出了CEEMDAN方法[14]。
2.2.3 具有自适应噪声的完全集合经验模态分解(CEEMDAN)
Complete ensemble empirical mode decomposition with
adaptive noise
这项工作实现了CEEMDAN[39]的改进版本。设
w
(
i
)
w(i)
w(i)是均值和单位方差为零的高斯白噪声的实现,
∼
I
M
F
k
∼IMF_k
∼IMFk表示提取的分解模式,
E
k
(
⋅
)
E_k(·)
Ek(⋅)表示生成EMD分解的信号的第
k
k
k个模态的算子,
M
(
⋅
)
M(·)
M(⋅)表示生成信号平均值的算子。给定输入时间序列
f
(
t
)
f(t)
f(t),算法描述如下:
- 用EMD I 实线对加噪信号 f i ( t ) = f ( t ) + β 0 E 1 ( w i ) f^i(t)=f(t)+β_0E_1(w^i) fi(t)=f(t)+β0E1(wi)的分解。计算第一个残差 r 1 ( t ) = < M ( f i ( t ) ) > r_1(t)=<M(f^i(t))> r1(t)=<M(fi(t))>。 β k = ε k s t d ( r k ) β_k=ε_kstd(r_k) βk=εkstd(rk)
- 计算第一个模态 ∼ I M F 1 ( t ) = f ( t ) − r 1 ( t ) ∼IMF_1(t)=f(t)-r_1(t) ∼IMF1(t)=f(t)−r1(t)
- 通过平均局部实现方法得到第二个残差 r 1 ( t ) = f ( t ) + β 1 E 2 ( w i ) r_1(t)=f(t)+β_1E_2(w^i) r1(t)=f(t)+β1E2(wi)。获得第二个模态 ∼ I M F 2 ( t ) = r 1 ( t ) − r 2 ( t ) = r 1 ( t ) − < M ( f ( t ) + β 1 E 2 ( w i ) ) > ∼IMF_2(t)=r_1(t)-r_2(t)=r_1(t)-<M( f(t)+β_1E_2(w^i) )> ∼IMF2(t)=r1(t)−r2(t)=r1(t)−<M(f(t)+β1E2(wi))>
- 计算第k个残差 r k ( t ) = < M ( r k − 1 ( t ) + β k − 1 E k ( w i ) ) > r_k(t)=< M(r_{k-1}(t)+β_{k-1}E_k(w^i)) > rk(t)=<M(rk−1(t)+βk−1Ek(wi))>,对 k = 3 , . . . , k k=3,...,k k=3,...,k
- 计算第k个模态: ∼ I M F k ( t ) = r k − 1 ( t ) − r k ( t ) ∼IMF_k(t)=r_{k-1}(t)-r_k(t) ∼IMFk(t)=rk−1(t)−rk(t)
- 对于下一个 k k k,返回步骤4。重复,直到残差不能进一步分解(residue has a maximum of one extreme at most)
改进的CEEMDAN方法提供了与EMD和EEMD相关的重大改进,例如避免杂散模式和减少噪声污染,从而赋予提取的IMF更多物理意义。这项工作使用pyEMD Python包[40]实现EMD、EEMD和CEEMDAN。
2.2.4 经验小波变换(EWT)
与EMD中的方法一样,EWT方法旨在提取信号的振幅(AM)和频率(FM)分量,考虑到这些分量具有紧凑的傅里叶支撑。它解决了EMD的一些局限性,例如缺乏数学理论。与使用预定义滤波器组结构的传统小波变换不同,EWT方法根据信号的频谱分布以完全自适应的方式定义滤波器的支撑度。分析时需要考虑以下因素:
- 由于对称性的需要,信号必须是实值的;
- 考虑了 2 π 2\pi 2π周期的标准化频率轴,但分析仅限于[0, π \pi π],由于香农的抽样标准。
接下来将对EWT方法进行总结,然后进行更详细的描述。
- 定义N个经验模式
- 计算信号频谱
- 找到N-1个局部频谱最大值
- 在两个连续最大值之间设置边界 ω n − m i d p o i n t s \omega n -midpoints ωn−midpoints
- 根据 ω n \omega n ωn的限制,定义EWT滤波器组
- 应用于输入信号,以获得N个经验模态。
预先定义了多个模态 N N N,确定如何分解原始信号,以及在 [ 0 , π ] [0,\pi] [0,π]范围内划分了多少段频谱。在要确定的 N + 1 N+1 N+1频率边界中,已经预定义了两个( ω 0 ω0 ω0和 ω N ωN ωN),分别对应于0和 π \pi π。
根据信号频谱的分布设置剩余的 N − 1 N-1 N−1限制:找到 N − 1 N-1 N−1局部最大值,并将边界 ω n ( N = 1 , 2 , … N − 1 ) ω_n(N=1,2,…N-1) ωn(N=1,2,…N−1)定义为两个连续最大值之间的中点。在这项工作中,通过在每个信号的快速傅里叶变换上应用高斯滤波器(滤波器长度=25,σ=5,UoB为5,NSC-ND为5和1),在平滑频谱上检测到最大值。图4给出了将信号频谱分割为5种模态的方法。
定义了ωn的限制后,分段 Λ n = [ ω n − 1 , ω n ] Λn=[ω_{n-1},ω_n] Λn=[ωn−1,ωn]填充区间 [ 0 , π ] [0,\pi] [0,π]。每一段的极限都以各自 ω n ω_n ωn为中心的过渡期为特征,宽度等于 2 τ n 2τ_n 2τn、 每段都与一个滤波器( ω 0 ω_0 ω0为低通,其余为带通)相关联,其构造与Littlewood-Paley和Meyer小波有关[41]。因此,定义了经验尺度函数 Ф n ( ω ) Ф_n(ω) Фn(ω)=和经验子波 ψ n ( ω ) ψ_n(ω) ψn(ω),对应于近似(低频)和细节(高频)系数。它们的构造方式可以获得紧密的框架。参考文献[22]中给出了此类函数构造的更多细节。
在满足构建紧框架的条件下,EWT的定义类似于传统的小波变换,细节由小波函数与信号的内积给出,近似值等于信号与尺度函数的内积。
基于Jérôme Gilles的MATLAB工具箱[42],为这项工作开发了一个EWT(ewtpy)Python包,可在https://pypi.org/project/ewtpy/ 和https://github.com/vrcarva/ewtpy中获得
2.2.5 变分模态分解(VMD)
VMD方法克服了EMD的局限性,如缺乏数学理论,以及EWT相对严格的滤波器组边界。通过同时估计相应模式,自适应地确定相关频带,可以在它们之间适当地平衡误差。此外,该方法对采样和噪声具有鲁棒性。与EMD相比,VMD在处理音调检测和分离的测试中表现更好[31]。
在变分模态分解中,通过约束变分优化问题提取预定义数量的K个模式,并使用交替方向乘子法(ADMM)求解[43,44]。最初,该方法假设每个模态 k k k在傅里叶频谱中具有紧凑的带宽,具有各自的中心频率 ω k ω_k ωk。该问题可通过以下方案简要描述。
- 从真实信号的希尔伯特变换构造单边带分析信号。
- 复谐波混合–将每个模式的频谱与调整到各自模式估计中心频率的指数函数相乘,从而将其移到基带。
- 通过解调信号的H1范数高斯平滑度评估带宽,即梯度的平方L2范数。
由此产生的约束变分问题如下所示:

u
k
u_k
uk是信号的第K个模态(从1到K),
ω
k
ω_k
ωk是各自的中心频率。
u
k
{u_k}
uk和
ω
k
{ω_k}
ωk分别代表全套模态和中心频率。要分解的输入信号由
f
f
f给出,δ是狄拉克函数。通过引入二次惩罚项和拉格朗日乘子,方程(2)可以表示为一个无约束问题。增广拉格朗日公式如下:
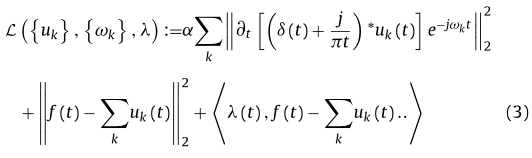
使用ADMM求解等式(3)时,对于每个迭代
n
n
n,会得到频域
(
u
^
k
)
(\hat u _k)
(u^k)中的所有K个估计模态:
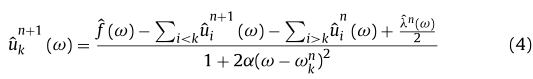
从方程4可以看出,模式通过简单的维纳滤波进行更新。中心频率可计算为每个模式频谱的相应重心:

时域(
u
k
u_k
uk)中的结果模态表示原始信号
f
(
t
)
f(t)
f(t)的完全分解。关于该方法的更详细描述,参考文献[31]中提供了完整的约束变分优化问题。尽管对长时间EEG信号使用VMD会因非平稳性而受到警告,但它在这项工作中的使用是基于所用数据库的时间序列持续时间相对较短,以及侧重于分类,而不是精确的模式分解和重建。为这项工作开发了一个基于原始MATLAB工具箱[45]的Python包,可在https://pypi.org/project/vmdpy/和 https://github.com/vrcarva/vmdpy。ewtpy和vmdpy都可以通过pip轻松安装(pip install vmdpy和pip install ewtpy)。
2.3. 希尔伯特变换和分析信号
所提出的分解方法具有具有“优良”希尔伯特变换的模态/本征函数的有趣特性[10,31],可以从中提取瞬时相位、频率或包络等特征。各模态/IMF的解析信号由式(6)给出。

在这里,
f
h
(
t
)
f_h(t)
fh(t)是
f
(
t
)
f(t)
f(t)的希尔伯特变换,

*是卷积算子。瞬时幅度和相位定义为:

给定IMF的瞬时频率可由其解析信号计算:

通过将一个信号划分为给定数量的模态/IMFs,可以提取与其各自分析信号和频谱相关的特征。
2.4 特征提取
上述五种方法(EMD、EEMD、CEEMDAN、EWT和VMD)给出的模态可视为调幅和调频信号。因此,根据各模态频谱的性质进行特征提取,参考文献[46]和[19]采用了类似的方法。提取的第一个特征是谱功率(SPow),由式(11)给出。

式中,N为谱系数总数,
P
X
X
P_{XX}
PXX为Welch’s method[47]估计的模态PSD。第二个特征是谱熵(SEnt),如式(12)所示。

P
^
X
X
\hat P_{XX}
P^XX为标准化PSD。以下三个特征与各自模态的主频率成分有关。在确定PXX的全局最大值后,定义对应的幅度为谱峰值(SP),以及相关的频率(f),定义了第3和第4个特征。以下特征为各模态的谱质心(SC),由式(13)定义:

其中
f
f
f为频率bin,
ω
(
f
)
ω(f)
ω(f)和
M
(
f
)
M(f)
M(f)分别为PSD的中心频率和幅度。最后两个频谱特征是AM和FM带宽,由公式14和15定义[48]:

其中
A
A
A是解析信号的振幅,
E
E
E是能量,<ω>为当前模态的中心频率,由式(16)给出。

从各模态中提取时域特征:Hjorth参数[49]和统计矩。
Hjorth mobility(Mob)与信号的平均频率有关,并与信号频谱的方差成正比,而Hjorth复杂度(Comp)是对信号带宽[50]的估计。它们的定义如下:

其中
f
(
t
)
f(t)
f(t)为当前信号分量,
V
a
r
(
)
Var()
Var()为方差。
偏度(skewness)与信号分布的不对称性有关,由下式给出:

f
(
t
)
f(t)
f(t)的标准差用σ表示,均值用μ表示。峰度(kurtosis)与信号产生的分布的尾部有关,由下式定义:

2.5 特征选择和分类
对于特征选择和分类算法,使用了scikit-learn包[51]中的函数。由于每个信号提取的特征数量比较多,并不是每个特征都与类别判别相关,因此需要一种特征选择或排序的方法。在这项工作中,这种选择是通过将递归特征消除(RFE)[52]应用于径向基函数(RBF)支持向量机(SVM)分类器来完成的。然后对不同的分类方法进行评价:
- k-近邻 (KNN)[53],均匀权值和欧氏距离度量;
- linear ( 惩罚参数C = 0.025,)和RBF (C = 1.0)支持向量机[54],gamma = ’ scale’,tolerance for stopping criteria= 0.001,
- 基于拉普拉斯近似[55]的RBF核高斯过程分类(GPC)和(IV)一个多层感知器(MLP)[56],具有1个隐藏层,100个神经元,校正线性单位激活函数(relu),“adam”优化器,alpha(正则项)=0.0001,恒定的学习率(0.001)。
分类问题涉及UoB数据集的3类(正常、发作期间期和发作期,各100个样本)和NSC-ND数据集的2类或3类;(i)发作期和发作期或(ii)发作前、发作期和发作期。为了验证分类算法的性能,采用了10倍交叉验证。在绩效评估方面,采用了四种常见的指标:准确性(ACC),特异性(SPEC),灵敏度(SEN)和受试者工作特征曲线下面积(AUC)。最后三个度量通过对分类器输出标签进行二值化计算,选择ictal类为正。最后,测量了各fold的分类训练次数。
3 结果
算法在带有Intel Core i7-8700 K CPU和64gb RAM的工作站上用Python 3.7实现。本工作中使用的所有脚本都可以在https://github.com/vrcarva/carvalho-eta -2019在线获得。
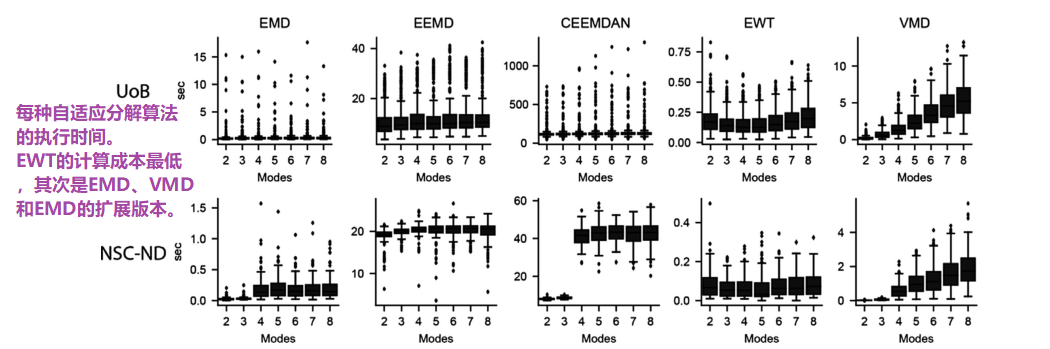
图5显示了用不同方法从每个数据集分解单个EEG信号的执行时间。除了VMD和CEEMDAN之外,增加模式的最大数量并不会显著影响执行时间,不同方法的执行时间会有很大差异。EWT是最快的,其次是VMD和EMD。尽管与EEMD相比,CEEMDAN的计算成本更低,但CEEMDAN的执行时间更长。这可能是由于pyEMD包的特定实现细节。
3.1 UoB数据集
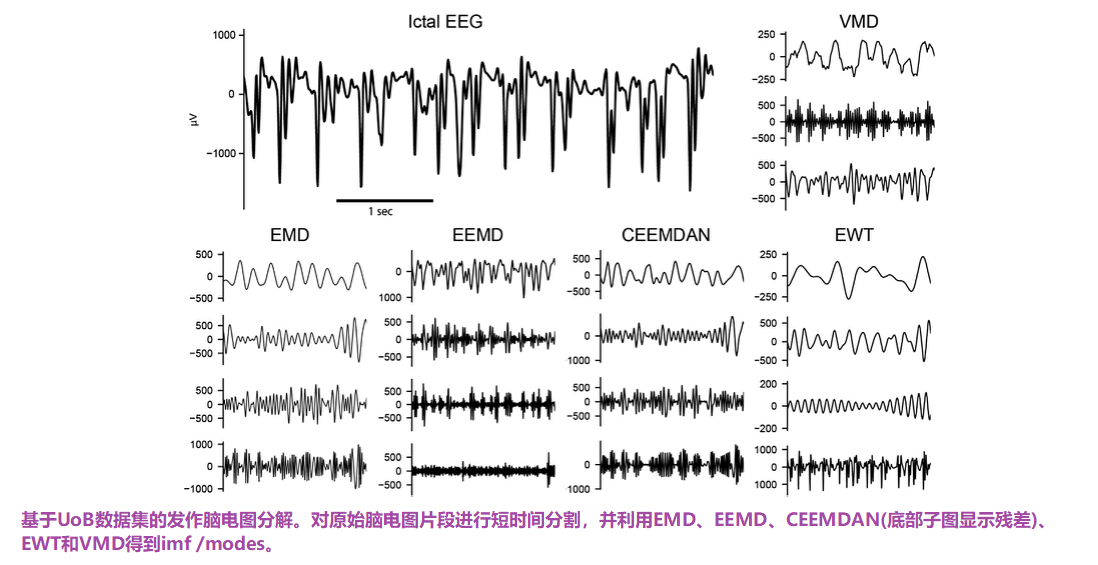
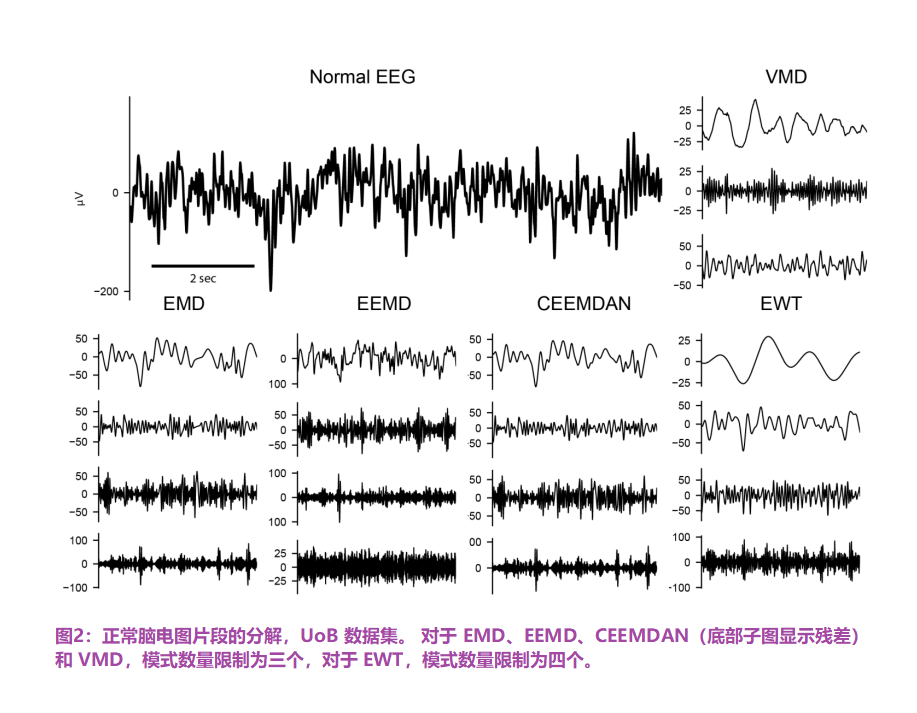
图6通过EMD、EEMD、CEEMDAN、EWT和VMD对癫痫脑电信号进行分解。图S1和S2分别显示了间信号和正常信号。
将每个类的样本分解为
N
N
N(2 - 8)个模态,然后提取每个模式的11个特征。因此,对于EWT/VMD,每个样本得到N × 11个特征,对EMD/EEMD/CEEMDAN,得到(N +1) × 11个特征(+1是因为特征也是从残差中提取的),SVM-RFE算法从中选择一个子集。根据准确率值与特征个数的关系,如图S5所示,每个分类器选择20个特征。RFE没有应用于“控制”(原始的,未分解的信号),这导致每个样本只有11个特征。然后对不同的分类器进行训练和测试,得到性能评价指标。进行了10次训练/测试迭代,得到了每个性能参数的均值±标准差。
图7显示了改变最大模态数对每种分解方法分类精度的影响。虽然最大模态数影响性能,但在任何情况下,精度值都没有低于从原始未分解信号中提取特征获得的精度值。此外,每种方法的最优模态数也不尽相同。
应用于每种分解方法的每个分类器的最佳结果(EMD为2个模态,EEMD为5个模态,CEEMDAN为5个模态,EWT为5个模态,VMD为7个模态)见表1——每种分类算法的ACC、SEN、SPEC、AUC和执行时间的度量。每种方法的最小和最大精度分别为EMD的[94.5 97.7%]%,EEMD的[95.6% 98.6]%,CEEMDAN的[96.2% 98.5]%,EWT的[92.8 97.1]%,VMD的[97.37 98.3]%。来自原始未分解信号的特征也可以产生相当准确的预测(GPC的最大预测精度为95.1%),但通常会导致较差的性能(最小预测精度为89.7%)。

3.2 NSC-ND数据集
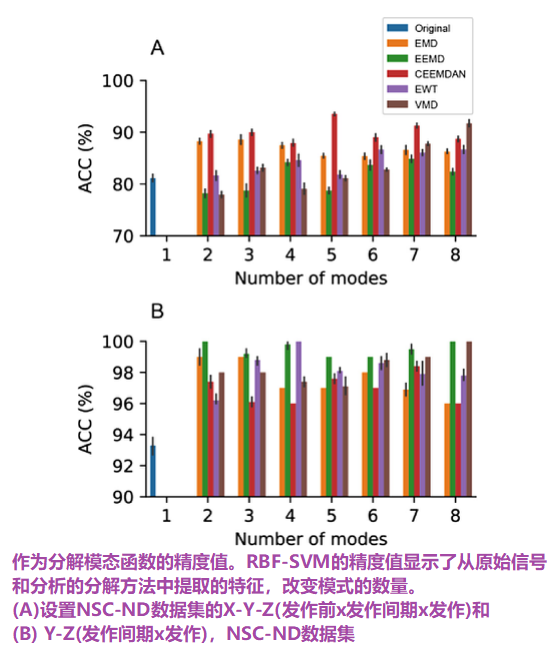
图8显示了来自NSC-ND数据集的癫痫EEG的分解。对于这两个分类问题(X-Y-Z和Y-Z),根据RFE方法只在20个(GCP分类器为40个)最相关的特征中选择一个子集。图9显示了每个分解方法的RBF-SVM分类器的精度值,在不同模态数量的情况下。
对于大多数分解方法,改变提取模态的数量对大多数方法的性能有显著的影响。有趣的是,每一种方法的最佳模态数量并不相同——虽然对于EMD和CEEMDAN,很少的imf可以产生更好的精度,但对于VMD来说,需要更多的模态才能获得良好的性能。在后者中,这是以增加提取IMF的执行时间为代价的,如图5所示。为每种分解方法选择最优的模态数,Y-Z分类问题的性能详见表2。S6表显示了X-Y-Z情况下的详细性能指标。
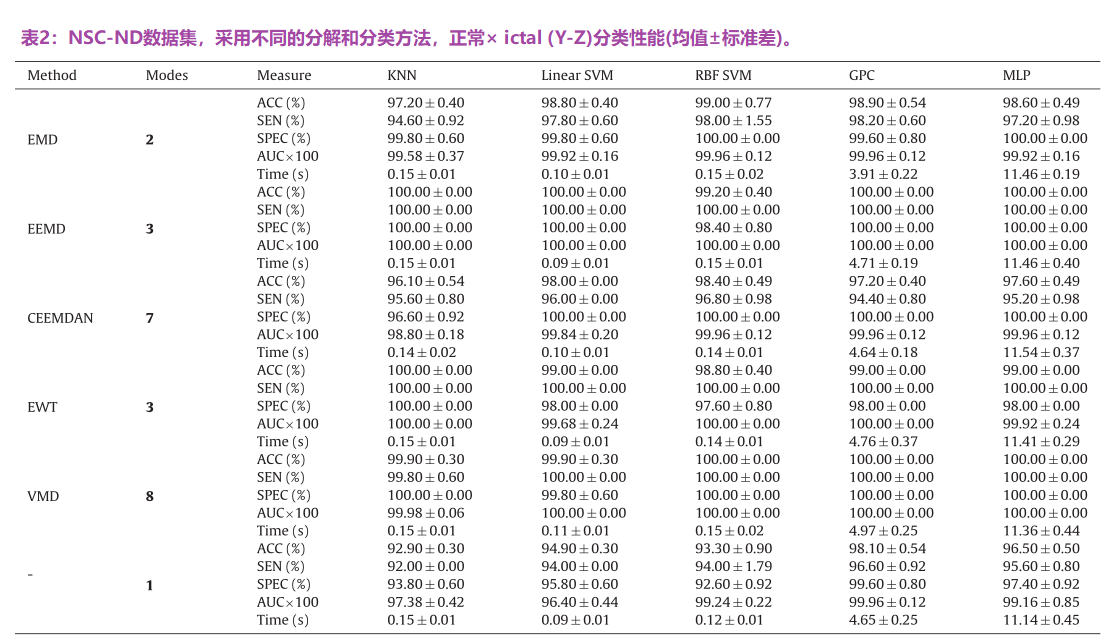
从表2,最小和最大精度的Y- Z分类结果为:[97.2 - 99.0]%的EMD, EEMD[100 - 99.2] %, CEEMDAN[96.1 - 98.4] %, [100 - 98.8]%,[100 - 99.9]% VMD和[92.9 - 98.1]%原始non-decomposed信号。
在Sup. 表1中,X-Y-Z分类结果在最小和最大精度为:[82.2 - 90.4]%的EMD,EEMD [79.9 - 85.3] %, CEEMDAN[78.5 - 93.1] %,EWT[78.2 - 91.3]%,[88.3 - 92.1]% VMD和[71.3 - 86.7]%原始non-decomposed信号。同样,原始信号特征的良好结果依赖于使用特定的分类器(GPC)和分解方法,提供了总体良好的性能,VMD值更优。
表3显示了本工作的结果与广泛的癫痫检测文献中选取的少数几篇论文的结果之间的总结比较。
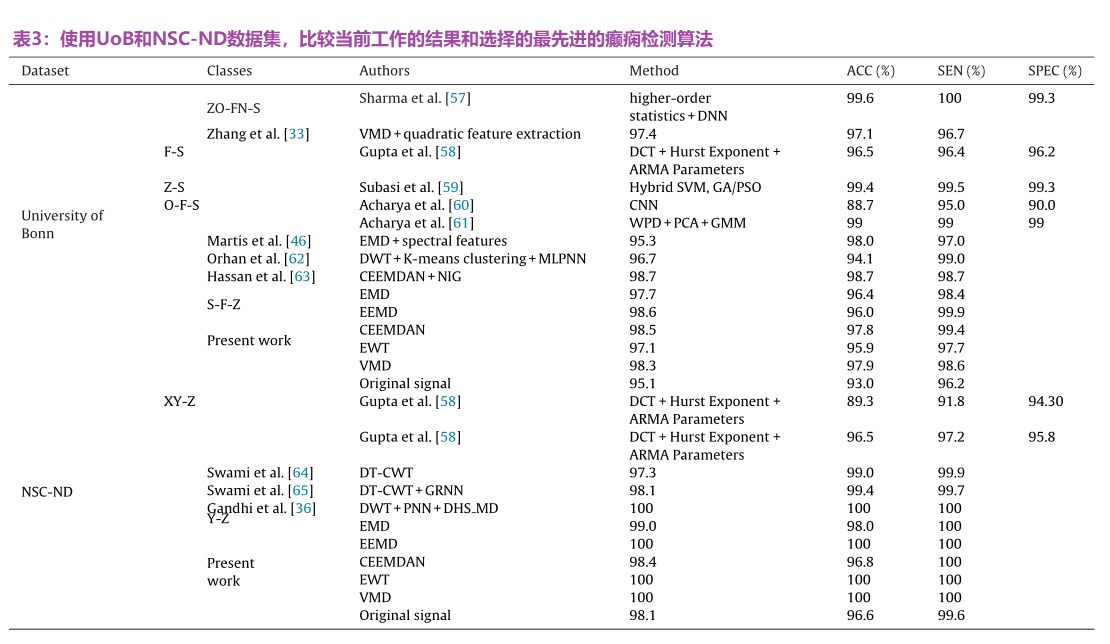
4 讨论
五种分解方法的最佳结果相似,EEMD、CEEMDAN和VMD的值略高。此外,当比较不同的分类器时,没有观察到不同的性能。这可能反映了所评估的自适应分解方法获得的整体较好的特征提取质量。对于原始的未分解信号,GPC分类器的结果较差,UoB数据集的准确率达到95.1%,NSC-ND的准确率达到98.1% (Y-Z)或96.7% (X-Y-Z)。因此,当从原始信号中提取特征集时,负担落在分类器上,而本工作中评估的自适应分解方法提供了更好的分类可分离性。这将对在自动癫痫发作检测设备上实现这些方法产生影响,在这种设备上,计算能力和性能之间的权衡至关重要。也就是说,在开发自动实时癫痫发作检测系统时,预测能力的增加应该与分解算法和分类器所需的额外执行时间进行权衡。
性能值与文献一致,UoB数据集的分类精度从文献[66]的90%到文献[59]的99.4%不等,NSC-ND[58]的分类精度在89%左右。当考虑正常的X发作类时,一些工作实现了100%的ACC[36,63]。使用其他数据集的工作也实现了100%的自动发作检测[20]。
尽管对每种方法的分类器参数进行特定的调优可以提高性能,但对所有分解方法都选择了相同的默认参数。这是考虑到本工作的主要目标,即不是提出一种新的癫痫发作检测方法,而是评估和比较相同条件下的分解方法。也就是说,给定相同的分类器应用于相同的谱和时域特征集,使用不同的自适应分解方法对分类性能有什么影响?我们发现,这些方法提供了更好的类可分性相对于非分解信号和相当相似的最佳情况性能。此外,达到最佳模态数的迭代次数根据分解方法和数据集的不同而不同,因此,为了最大限度地发挥每种分解方法的潜力,应该仔细选择该参数——例如,VMD在8个模态时达到最佳ACC,只有两个IMF(使用NSC-ND数据集)时,EMD的性能更好。
本研究中评估的方法旨在自适应地将信号分解为AM-FM分量,并提取每种模式的特征,以区分正常和无癫痫发作信号与癫痫发作信号。这对于鉴别癫痫系统和鉴别发作间期到发作期的状态转变有很好的应用前景。如果每个模式都被认为具有“表现良好”的希尔伯特变换(Hilbert Transforms),可以进一步探索特征提取能力,如果有多通道数据可用,就可以分析同一信号的不同模式之间或不同大脑区域之间的相位关系。由于同步化被认为在ictogenesis中发挥重要作用,这些方法可能进一步有助于揭示癫痫产生的机制和设计标记来预测发作状态的转变。
对结果的解释必须考虑到所使用的基准EEG数据集的局限性。虽然这些对于算法评价和与类似作品的比较非常有用,但两者的数据都是在相对受控的条件下选取的短段。因此,与在临床环境中发现的相比,在对伪迹和大脑状态变化的泛化和鲁棒性方面,这些都有较轻的要求。因此,本研究中分析的分解方法如果应用于临床环境或嵌入式设备,很可能会出现更大的差异。然而,使用这样的基准数据集是一个重要和必要的评估步骤,应该考虑所有的癫痫检测和预测方法。
5 结论
特征提取和分类方法的开发对于理解癫痫的运行机制和临床分析,包括癫痫检测和预测设备的可能应用都是关键的一步。
该工作表明,最佳癫痫检测结果在评估的自适应分解方法中是相似的,但提取的模式数量应根据分解方法和现有数据进行调整,以达到最佳性能。VMD、EEMD和CEEMDAN的值稍高。然而,EMD的扩展版本也导致了更长的执行时间,这可能会妨碍这些方法在实时应用程序中的使用。VMD和EWT是最快的分解方法,在计算成本和性能之间有很好的权衡。
使用自适应分解方法是一种很有前途的方法,因为它们能够分离在癫痫发生时(可能在这些事件之前的时期)发生变化的不同AM-FM成分。这将有助于提取与这些事件相关的特征,提高分类算法的性能。然而,从未分解的信号中提取相同的特征仍然可以得到相当精确的分类器。因此,在需要实时处理和有限的计算能力的情况下,性能收益应该与这种分解算法所需的额外计算成本进行权衡。
这项工作的另一个目标是为社区提供这些信号分解方法的Python代码。Python是一种快速发展的编程语言,目前是世界上第三大最流行的编程语言[67],在神经科学领域有着广泛的应用[68]。这些包的分发可以进一步鼓励使用开源编程语言来处理涉及这些特定信号处理方法的作品。
附录




















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









