







 本文详述了神经网络的结构,从基本的前向传播开始,逐步推导出代价函数,然后采用梯度下降法,特别是介绍了反向传播(BP)算法的原理。通过举例说明了神经元的计算过程,解释了代价函数的作用和正则化目的,并展示了如何利用链式法则求解网络参数的梯度。最后提到了完整的训练过程将在后续实验篇章中阐述。
本文详述了神经网络的结构,从基本的前向传播开始,逐步推导出代价函数,然后采用梯度下降法,特别是介绍了反向传播(BP)算法的原理。通过举例说明了神经元的计算过程,解释了代价函数的作用和正则化目的,并展示了如何利用链式法则求解网络参数的梯度。最后提到了完整的训练过程将在后续实验篇章中阐述。
作者述:之前有学习过一遍,但是一段时间过后,很多细节地方已经模糊。最近重新推导了一遍,为了尽可能保留推导思路,特地写作此博文。一方面供自己日后回忆,另一方面方便跟大家交流学习。
关于本博文,说明如下:
1. 本博文不保证推导过程完全正确,如有问题,欢迎指正。
2. 如果需要,欢迎大家转载,唯一的要求是请注明出处。
本文会从最基本的神经网络结构开始,一步步推导,最终得到一个神经网络利用BP算法进行训练的完整过程,以及中间会用到的公式的推导。
神经网络
神经网络结构如下图所示,总体上由三部分组成:输入层、隐藏层(为方便起见,图中给出一层,实际中可以有多层)和输出层。对于每一层,都是由若干个单元(神经元)组成。相邻两层的神经元之间是全连接的,但是同一层内,各神经元之间无连接。现在对各参数进行说明: X=[(x(1))T,(x(2))T,…,(x(m))T]T 是原始输入数据集,其中对于单个输入样本, x(i)=[x(i)1,x(i)2,…,x(i)n]T ,也就是每个样本有 n 个特征,对应着神经网络输入层的神经元个数。通常在训练网络时需要有标签的训练样本集
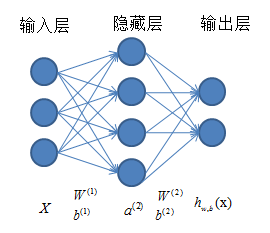
整个神经网络的工作过程是:从输入层开始输入数据,依靠线性组合,得到与输入层相邻层的各个神经元的值,然后用当前层作为输入,作用于下一层,依次进行,直到到达输出层,得到最终的输出。但是,如果仅仅进行线性变换,最终得到的输出结果仅仅是输入的线性表达。这显然不能满足我们的需求(我们需要得到输入的一个非线性表达),因此,通常在每个神经元进行线性组合之后,再经过一个激励函数,激励函的结果作为对应神经元的值。激励函数的选择有很多种,我使用的是 f(z)=sigmoid(z)=11+e(−z) 函数
前向传播与代价函数
从输入层开始,依次计算其余各层各神经元值的过程就是前向传播(十分形象)。对于每个待求的神经元,其过程是先利用前一层各个神经元的值和层间的权值与偏置进行线性组合,然后通过一个指定的激励函数 f(z) ,得到该神经元的具体值。以单样本 x=[x1,x2,x3]T 为例:
第二层的各神经元:
z(2)1=∑3j=1(W(1)1jxj)+b(1)1
a(2)1=f(z(2)1)
z(2)2=∑3j=1(W(1)2jxj)+b(1)2
a(2)2=f(z(2)2)
z(2)3=∑3j=1(W(1)3jxj)+b(1)3
a(2)3=f(z(2)3)
z(2)4=∑3j=1(W(1)4jxj)+b(1)4
a(2)4=f(z(2)4)
第三层(输出层)的各神经元
z(3)1=∑4j=1(W(2)1ja(2)j)+b(2)1
a(3)1=f(z(3)1)
z(3)2=∑4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









