







Spark初探
一、Spark简介及特性
1.1什么是Spark
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。Spark为我们提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
1.2 Spark特性
Spark在数据处理过程中使用低成本的shuffle方式,同时利用内存数据计算和高效的处理能力,将Hadoop的MapReduce提升到一个更高层次,比其他的大数据处理技术的性能高出不少;Spark支持大数据查询的延迟计算,帮助优化大数据处理流程中的处理步骤;提供的高级API让用户非常容易入门进而编写分布式应用程序;以弹性分布式数据集RDD(Resilient Distributed Datesets)为基石,提供对数据的并行、容错处理。
二、Spark作业运行流程
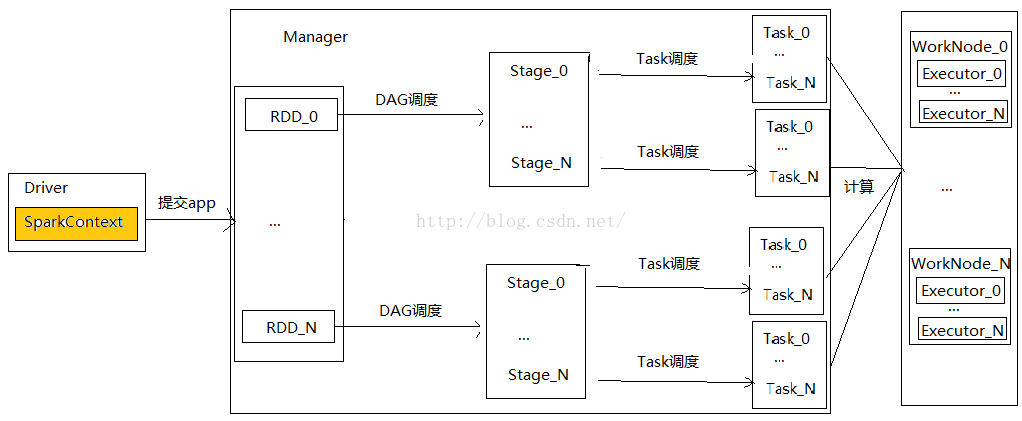
以下简要介绍其工作流程(以spark-submit模式提交)及术语:
A) 用户编写程序提交给spark后便生成一个相应的application;application在运行时会在Driver模块中创建SparkContext(spark资源环境)作为调度的总入口;
B) 在Manager模块中初始化创建DAGScheduler(进行Stage调度)和TaskScheduler(进行Task调度)两个模块,为后续的任务调度做准备;
C) 将提交的application进行DAG和Task的划分,最后分发给各个数据处理节点运行;
D) 数据处理节点启动Executor模块将分配过来的Task进行数据处理,所需资源需要向Manager申请;
E) 将各个节点处理之后的数据汇总给Manager,Manager再把数据组织之后汇报给Driver,完成作业。
基本运行流程如下图:















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









