






基于超算平台的矩阵乘法MPI并行实验
一、实验目的
- 熟悉超算环境,掌握在超算上如何运行作业
- 熟悉MPI编程环境,掌握MPI编程基本函数及MPI的相关通信函数用法;
- 将通用矩阵乘法转为MPI并行实现,减少大型矩阵乘法计算所需的时间,进一步加深MPI的使用与理解
二、实践平台与环境:
本实验在国家超级计算郑州中心先进计算平台上进行,郑州中心于2020 年建成并投入运行,理论峰值计算能力达到 100PFlops,存储裸容量 100PB,网络系统带宽 200Gb/s,网络延迟微秒级;同时配备国产安全可靠的云计算平台、高性能计算集群管理调度平台、人工智能平台以及专业的在线运维平台,提供类型多样的先进计算服务;采用绿色节能的浸没式相变液冷冷却技术,PUE 值小于 1.04。
-
系统平台:超算平台(郑州超算中心)
-
加载的module:
compiler/devtoolset/7.3.1
mpi/hpcx/2.4.1/gcc-7.3.1
三、实验方案
(一)问题描述
通过MPI并行对两个大型矩阵A(MxN),B(NxK)做乘法得到矩阵C(MxK)
(二)方案描述
将矩阵A按行“平均”分配给所有进程,将整个矩阵B分配给所有进程,最终每个进程都将获得A的部分行和矩阵B,然后每个进程将自己所获得的A矩阵的行与B矩阵进行矩阵乘法运算,最终将每个进程所计算的结果进行组装,获得最终的矩阵C。
1、矩阵A的分配。由于矩阵A的行数可能不能够被总的进程数目整除,为尽可能的做到“平均”,且一次性将A矩阵的行数全部分给所有的进程,需要先计算每个进程分配的行数, 可以采用以下的方式计算每个进程分配的行数:

/*
M:矩阵A的总的行数
world_size: 总的进程数目
lines: 数组,存放每个进程需要分配的行数
*/
int *lines = new int[world_size];
int equal_rows = M / world_size;
int remain_lines = M % world_size;
for (int i = 0; i < world_size; i++)
{
int rows = equal_rows;
if (remain_lines != 0)
{
rows++;
remain_lines--;
}
lines[i] = rows;
}
然后可以采用集合通信的方式实现分配,这里采用MPI_Scatterv;MPI_Scatterv的语法如下:

其中两个关键的参数:

因此需要计算发送到每个进程的元素数,和要发送每个进程数据相对于矩阵A中元素的偏移,这里计算的方式就比较简单,不在过多叙述:
// 为每个rank分配发送数据相对于矩阵A的起始位置scatter_info.displs[i],
// 发送数据的个数scatter_info.displs[i]
DataInfo scatter_info = DataInfo(world_size);
int tmp = 0;
for (int i = 0; i < world_size; i++)
{
scatter_info.cnts[i] = lines[i] * N;
scatter_info.displs[i] = tmp;
tmp += scatter_info.cnts[i];
}
double *split_A = new double[lines[rank] * N]; // 每个进程获得矩阵A的部分数据
MPI_Scatterv(Matrix_A, scatter_info.cnts, scatter_info.displs, MPI_DOUBLE,
split_A, lines[rank] * N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
2、矩阵B的分配。矩阵B的分配可以采用MPI_Bcast函数广播到每一个进程,其实现过程如下:
MPI_Bcast(Matrix_B, N * K, MPI_DOUBLE, 0, MPI_COMM_WORLD);
3、每个进程进行矩阵计算。
void AxB(double *A, double *B, int m, int n, int k, double *C) // A(mxn) B(nxk)
{
for (int i = 0; i < m; i++) // A 行数
for (int j = 0; j < k; j++) // B 列数
{
double temp = 0;
for (int p = 0; p < n; p++) // B 行数
{
temp += A[i * n + p] * B[p * k + j];
}
C[i * k + j] = temp;
}
}
double *split_A = new double[lines[rank] * N]; // 每个进程获得矩阵A的部分数据
MPI_Scatterv(Matrix_A, scatter_info.cnts, scatter_info.displs, MPI_DOUBLE,
split_A, lines[rank] * N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
double *resultbuff = new double[lines[rank] * K]; // 存放每个进程的计算结果
AxB(split_A, Matrix_B, lines[rank], N, K, resultbuff);
4、结果的收集。由于每一个进程计算的结果长度不一致,因此采用MPI_Gatherv函数对结果进行组合,MPI_Gatherv的语法如下:
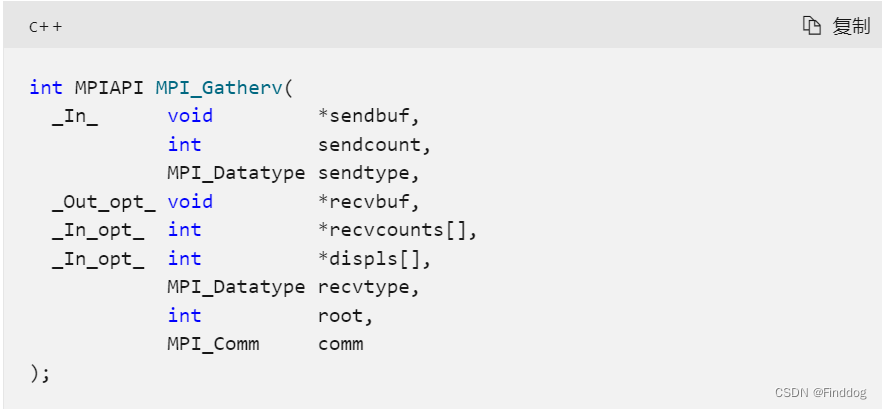
参数的使用与MPI_Scatterv类似,需要指定从每个进程获取的元素个数,以及从每个进程获取的元素需要存放的位置等。
DataInfo gatherinfo = DataInfo(world_size);
tmp = 0;
for (int i = 0; i < world_size; i++)
{
gatherinfo.displs[i] = tmp;
gatherinfo.cnts[i] = lines[i] * K;
tmp += gatherinfo.cnts[i];
}
MPI_Gatherv(resultbuff, lines[rank] * K, MPI_DOUBLE, Matrix_C, gatherinfo.cnts,
gatherinfo.displs, MPI_DOUBLE, 0, MPI_COMM_WORLD);
四、实验步骤与结果分析
1、加载并行计算环境

2、编译源文件

3、编写sbatch脚本 param.sh
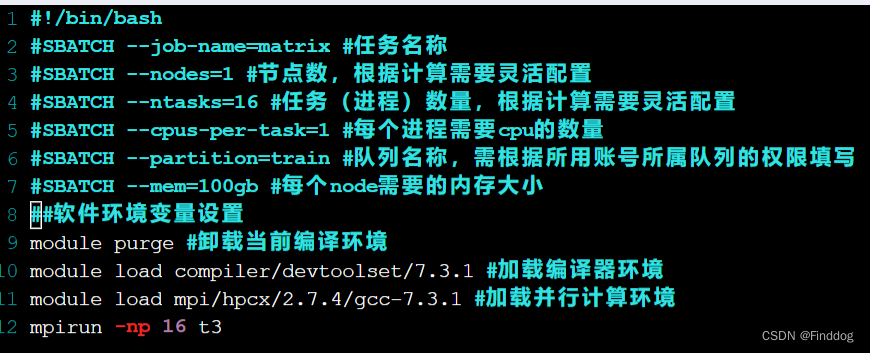
4、运行脚本。
sbatch param.sh
5、实验时间分析。
依次修改脚本中param.sh中mpirun -np 16 t3 中的进程数16为8、4、2、1进行实验,其运算所需的时间分别为0.4s、0.7s、1.3s、2.9s、4.5s,可以看出当进程数目从16减为8、4、2、1时,计算所用的时间差不多增加为原来的二倍,说明并行进程数可以加快计算的速度。

6、计算结果准确度分析。当使用两个进程来计算两个小矩阵的成绩,从结果可以看出,采用并行计算的结果和不采用并行计算的结果相同。
五、总结
一直以来,我就对并行计算有很大的兴趣,通过分布式计算这门课,让我了解到了mpi并行技术,于是就按照教程[2]动手尝试做了一些简单的例子,最终用mpi实现了下矩阵的并行运算,并整理了这份课程报告,从中加深了我对mpi并行计算的理解,同时呢,对于C++编程又重新的熟悉了以下,另外也熟悉了超算的使用,相信这门课对我以后的学习具有很大的帮助!
六、参考文献
[1] Microsoft MPI:https://learn.microsoft.com/zh-cn/message-passing-interface/microsoft-mpi
[2] MPI Tutorial: https://mpitutorial.com/tutorials/mpi-hello-world/zh_cn/
七、完整代码
#include <stdio.h>
#include "mpi.h"
#include <stdlib.h>
#include <iostream>
struct DataInfo
{
int *displs;
int *cnts;
DataInfo(int world_size)
{
this->displs = new int[world_size]();
this->cnts = new int[world_size]();
}
~DataInfo()
{
delete[] this->displs;
delete[] this->cnts;
}
};
void AxB(double *A, double *B, int m, int n, int k, double *C) // A(mxn) B(nxk)
{
for (int i = 0; i < m; i++) // A 行数
for (int j = 0; j < k; j++) // B 列数
{
double temp = 0;
for (int p = 0; p < n; p++) // B 行数
{
temp += A[i * n + p] * B[p * k + j];
}
C[i * k + j] = temp;
}
}
void PrintMatrix(double *matrix, int m, int n, char *name)
{
printf("%s:\n", name);
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
{
printf("%f", matrix[i * n + j]);
}
printf("\n");
}
printf("\n");
}
int main(int argc, char *argv[])
{
int M = 1000;
int N = 1100;
int K = 900;
if (argc > 0) // 测试计算精度,用小矩阵
{
M = 5;
N = 4;
K = 3;
}
double *Matrix_A = new double[M * N]; // 矩阵A MxN
double *Matrix_B = new double[N * K]; // 矩阵B NxK
double *Matrix_C = new double[M * K]; // 结果矩阵
int rank; // process id number
int world_size; // number of process
MPI_Init(&argc, &argv); // parallel init
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
double start, stop; // 计时时间
/*
M:矩阵A的总的行数
world_size: 总的进程数目
lines: 数组,存放每个进程需要分配的行数
*/
int *lines = new int[world_size];
int equal_rows = M / world_size;
int remain_lines = M % world_size;
for (int i = 0; i < world_size; i++)
{
int rows = equal_rows;
if (remain_lines != 0)
{
rows++;
remain_lines--;
}
lines[i] = rows;
}
if (rank == 0)
{
// 数组A,B赋值
start = MPI_Wtime();
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
Matrix_A[i * N + j] = i + 1;
}
for (int i = 0; i < N; i++)
{
for (int j = 0; j < K; j++)
Matrix_B[i * K + j] = j + 1;
}
}
MPI_Bcast(Matrix_B, N * K, MPI_DOUBLE, 0, MPI_COMM_WORLD);
// 为每个rank分配发送数据相对于矩阵A的起始位置scatter_info.displs[i],
// 发送数据的个数scatter_info.displs[i]
DataInfo scatter_info = DataInfo(world_size);
int tmp = 0;
for (int i = 0; i < world_size; i++)
{
scatter_info.cnts[i] = lines[i] * N;
scatter_info.displs[i] = tmp;
tmp += scatter_info.cnts[i];
}
double *split_A = new double[lines[rank] * N]; // 每个进程获得矩阵A的部分数据
MPI_Scatterv(Matrix_A, scatter_info.cnts, scatter_info.displs, MPI_DOUBLE,
split_A, lines[rank] * N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
double *resultbuff = new double[lines[rank] * K]; // 存放每个进程的计算结果
AxB(split_A, Matrix_B, lines[rank], N, K, resultbuff);
DataInfo gatherinfo = DataInfo(world_size);
tmp = 0;
for (int i = 0; i < world_size; i++)
{
gatherinfo.displs[i] = tmp;
gatherinfo.cnts[i] = lines[i] * K;
tmp += gatherinfo.cnts[i];
}
MPI_Gatherv(resultbuff, lines[rank] * K, MPI_DOUBLE, Matrix_C, gatherinfo.cnts,
gatherinfo.displs, MPI_DOUBLE, 0, MPI_COMM_WORLD);
if (rank == 0 && argc > 0)
{
PrintMatrix(Matrix_A, M, N, "A");
PrintMatrix(Matrix_B, N, K, "B");
printf("mpi total processes: %d", world_size);
PrintMatrix(Matrix_C, M, K, "mpi AXB");
double *resultc = new double[M * K];
AxB(Matrix_A, Matrix_B, M, N, K, resultc);
PrintMatrix(resultc, M, K, "AXB");
delete[] resultc;
}
delete[] split_A;
delete[] resultbuff;
delete[] Matrix_A;
delete[] Matrix_B;
delete[] Matrix_C;
stop = MPI_Wtime();
if (rank == 0 && argc == 0)
{
printf("consume time: %f s\n", stop - start);
}
MPI_Finalize();
}















 3712
3712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









