






MPI实现矩阵乘矩阵运算
实验环境
操作系统:Ubuntu 20.04
编程语言:C++
实验原理
什么是MPI
MPI是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。
尽管MPI属于OSI参考模型的第五层或者更高,他的实现可能通过传输层的sockets和Transmission Control Protocol (TCP)覆盖大部分的层。大部分的MPI实现由一些指定惯例集(API)组成,可由C,C++,Fortran,或者有此类库的语言比如C#, Java or Python直接调用。MPI优于老式信息传递库是因为他的可移植性和速度。
MPI并行运算的思想
并行编程模式
对等模式—程序的各个部分地位相同,功能和代码基本一致,只是处理的数据或对象不同;主从模式—程序通信进程之间的一种主从或依赖关系。
点对点通信模式
阻塞—发送完成的数据已经拷贝出发送缓冲区,即发送缓冲区可以重新分配使用,阻塞接受的完成意味着接收数据已经拷贝到接收缓冲区,即接收方已可以使用。非阻塞—在必要的硬件支持下,可以实现计算和通信的重叠。4种通信模式:标准通信模式、缓存通信模式、同步通信模式、就绪通信模式。
组通信
一个特定组内所有进程都参加全局的数据处理和通信操作。
功能:通信—组内数据的传输;同步—所有进程在特定的点上取得一致;计算—对给定的数据完成一定的操作。
类型:1)数据移动:广播(mpi bcast) 收集(mpi gather) 散射(mpi scater)组收集(mpi all gather)全交换(all to all);2)聚集:规约(mpi reduce)将组内所有的进程输入 缓冲区中的数据按,定操作OP进行运算,并将起始结果返回到root进程的接收缓冲区扫描(mpi scan)要求每一个进程对排在它前面的进程进行规约操作,结果存入自身的输出缓冲区;3)同步:路障(mpi barrier)实现通信域内所有进程互相同步,它们将处于等待状态,直到所有进程执行它们各自的MPI-BARRIER调用。
MPI调用接口
1.mpi init()初始化MPI执行环境,建立多个MPI进程之间的联系,为后续通信做准备;
2.mpi finalize 结束MPI执行环境;
3.mpi comm rank用来标识各个MPI进程的,给出调用该函数的进程的进程号,返回整型的错误值。两个参数:MPI_Comm类型的通信域,标识参与计算的MPI进程组; &rank返回调用进程中的标识号;
4.mpi comm size用来标识相应进程组中有多少个进程;
5.mpi send(buf,counter,datatype,dest,tag,comm): buf:发送缓冲区的起始地址,可以是数组或结构指针;count:非负整数,发送的数据个数;datatype:发送数据的数据类型;dest:整型,目的的进程号;tag:整型,消息标志;comm:MPI进程组所在的通信域;
含义:向通信域中的dest进程发送数据,数据存放在buf中,类型是datatype,个数是count,这个消息的标志是tag,用以和本进程向同一目的进程发送的其它消息区别开来 [1] 。
6.mpi recv(buf,count,datatype,source,tag,comm,status): source:整型,接收数据的来源,即发送数据进程的进程号; status:MPI_Status结构指针,返回状态信息。
实验设计
问题描述与分析
设有L×M矩阵A和M*N矩阵B相乘,得到结果为LxN的矩阵C。记矩阵A、B、C的第i行第j列的元素为Aij (i=0…L. j=0…M) ,Bij ( i=0…M, j=O…N) ,Cij (i=0…L., j=0 …N)。则:
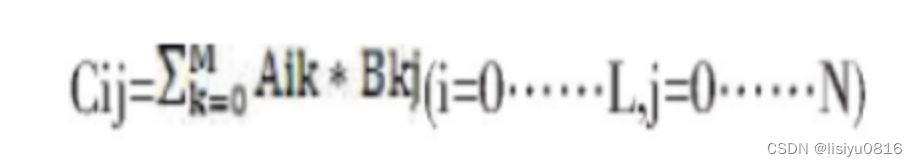
可见Cij只与A和B的第i行相关,而与其他行无关,所以具有并行计算的可行性。
假设有n个进程并行计算,则把矩阵A按行分成n个M/n行的小矩阵,每个小矩阵与B进行矩阵乘法,得到n个MIn行,N列的矩阵,将这些矩阵合并到—起就得到最终的结果。
算法思想
假设开启np个进程
(1). 首先将矩阵A和C按行分为np块;
(2). 进程号为 id 的进程读取A的第 id 个分块和B;
(3). 进程号为 id 的进程求解相应的C的第 id 个分块。
算法实现
#include<iostream>
#include<mpi.h>
#include<math.h>
#include<stdlib.h>
void initMatrixWithRV(float *A, int rows, int cols);
void matMultiplyWithSingleThread(float *A, float *B, float *matResult, int m, int p, int n);
int main(int argc, char** argv)
{
int m = atoi(argv[1]);//A矩阵的行
int p = atoi(argv[2]);//A矩阵的列及B矩阵的行
int n = atoi(argv[3]);//B矩阵的列
float *A, *B, *C;
float *bA, *bC;
double beginTime, endTime;//时间
int myrank, numprocs;
MPI_Status status;
MPI_Init(&argc, &argv); // 并行开始
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); //并行线程数
MPI_Comm_rank(MPI_COMM_WORLD, &myrank); //执行顺序
int bm = m / numprocs; //矩阵A按行分块
bA = new float[bm * p];
B = new float[p * n];
bC = new float[bm * n];
if(myrank == 0){//生成矩阵
A = new float[m * p];
C = new float[m * n];
initMatrixWithRV(A, m, p);
initMatrixWithRV(B, p, n);
}
//开始计时
beginTime = MPI_Wtime();
//阻塞其他进程强制等待
MPI_Barrier(MPI_COMM_WORLD);
//数据分配
MPI_Scatter(A, bm * p, MPI_FLOAT, bA, bm *p, MPI_FLOAT, 0, MPI_COMM_WORLD);
MPI_Bcast(B, p * n, MPI_FLOAT, 0, MPI_COMM_WORLD);
//并行计算
matMultiplyWithSingleThread(bA, B, bC, bm, p, n);
MPI_Barrier(MPI_COMM_WORLD);
//聚合通信,汇总结果
MPI_Gather(bC, bm * n, MPI_FLOAT, C, bm * n, MPI_FLOAT, 0, MPI_COMM_WORLD);
//计算多余分块
int remainRowsStartId = bm * numprocs;
if(myrank == 0 && remainRowsStartId < m){
int remainRows = m - remainRowsStartId;
matMultiplyWithSingleThread(A + remainRowsStartId * p, B, C + remainRowsStartId * n, remainRows, p, n);
}
//结束计时
endTime = MPI_Wtime();
delete[] bA;
delete[] B;
delete[] bC;
if(myrank == 0){
delete[] A;
delete[] C;
printf("Time: %f\n",endTime-beginTime);
}
MPI_Finalize(); // 并行结束
return 0;
}
//初始化矩阵随机生成
void initMatrixWithRV(float *A, int rows, int cols)
{
srand((unsigned)time(NULL));
for(int i = 0; i < rows*cols; i++){
A[i] = (float)rand() / RAND_MAX;
}
}
//矩阵乘法计算
void matMultiplyWithSingleThread(float *A, float *B, float *matResult, int m, int p, int n)
{
for(int i=0; i<m; i++){
for(int j=0; j<n; j++){
float temp = 0;
for(int k=0; k<p; k++){
temp += A[i*p+k] * B[k*n + j];
}
matResult[i*n+j] = temp;
}
}
}
实验结果
编译前先安装相关指令:sudo apt install mpich
编译指令:mpicxx mpimatrix.cc -o mpimatrix(c程序为mpicc)
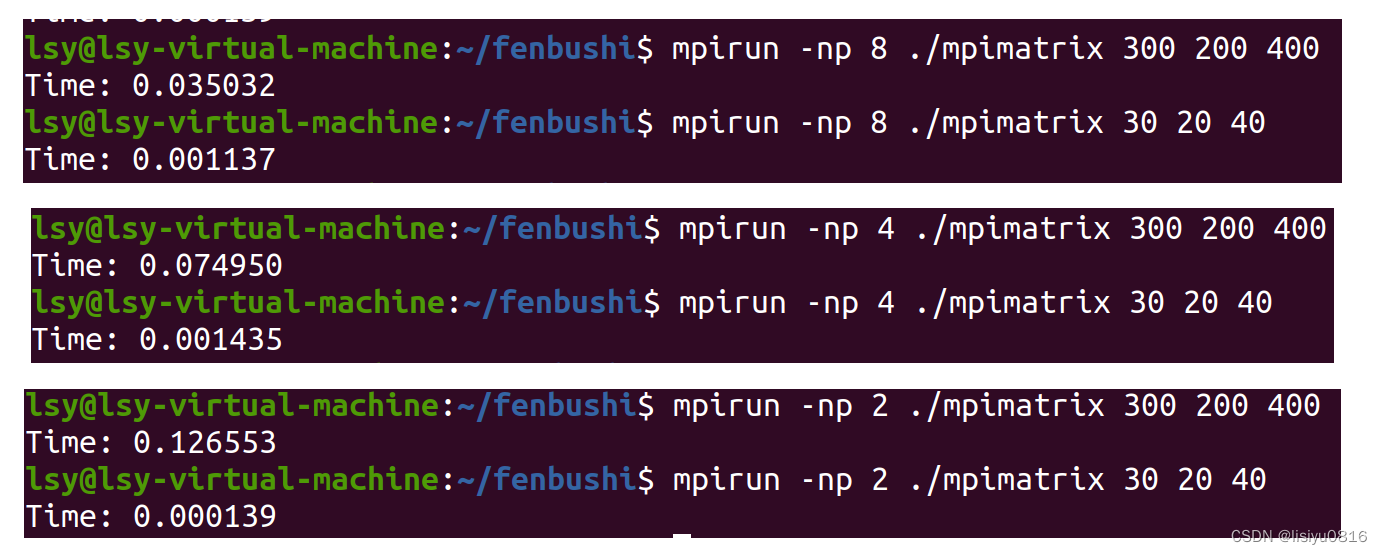
执行指令:mpirun -np 4 ./mpimatrix 300 200 400,其中4表示4个进程并行执行,300,200,400分别对应矩阵的相关参数。
执行结果截图:
实验结论
从上图的实验结果图中能直观看到随着矩阵的增大运行时间明显增大,因为计算也越来越复杂。同时并行计算的进程数越多时间越快。深刻体会到并行算法的效率和强大。
现实世界中许多现象都表现出并行性,众多问题的求解过程都有并行的可能性,但由于人们习惯用SISD计算模型上的思维,使得编写并行机执行程序变得不合常规,其实,底意识的并行才更接近问题.MPI程序的SPMD编程模式给人们进行并行思维以很好的训练,MPI的通信机制为人们在连网工作站上编写并实现并行程序提供了舞台,使得问题求解变得更加自然.
计算的进程数越多时间越快。深刻体会到并行算法的效率和强大。
现实世界中许多现象都表现出并行性,众多问题的求解过程都有并行的可能性,但由于人们习惯用SISD计算模型上的思维,使得编写并行机执行程序变得不合常规,其实,底意识的并行才更接近问题.MPI程序的SPMD编程模式给人们进行并行思维以很好的训练,MPI的通信机制为人们在连网工作站上编写并实现并行程序提供了舞台,使得问题求解变得更加自然.
多核处理器的普及与并行计算机的发展极大地促进了并行程序设计的发展,越来越多的领域尤其是高性能计算与进程通信等领域都使用了并行计算的实现方法。本文使用并行编程的一种重要工具MP I实现了一种矩阵相乘的并行算法。通过对原问题进行建模分析,找出其计算的并行性,从而使用并行计算的方法解决。并行计算充分利用了处理器资源,能够完成串行计算无法胜任的工作,是未来计算的趋势。
参考博文:https://www.cnblogs.com/fengfu-chris/p/4364142.html















 2557
2557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









