










大家好,欢迎来到STL【常用算法】详解模块,本文将对STL中常见但又高频的算法进行一个详细又简单的入门级教学🎓
一、算法概述
1.什么是算法?
算法就是一种函数模板,C++中的算法是通过迭代器和模板来实现的,简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果。
2.算法是怎么样生成的?
对于算法,它是从迭代器哪里获得一个元素,而迭代器则查找元素的位置并将这些信息提供给算法能够访问这些元素。
- 举个例子来说,大家可以把算法想象成一个做手术的外科医生,那么迭代器就是外科医生的助手。当外科医生需要一把手术刀🔪或者其他工具🔍时的时候,助手就提供给他。而外科医生则不会把精力放在如何去找那把手术刀上,他则是一心一意地对待病人,只专注于如何解决当前摆在它面前的这些数
3.算法的头文件有哪些?
①这是STL中最大的一个头文件,范围设计到比较、交换、查找、遍历操作、复制、修改等等
#include <algorithm>
②这个算法头文件它的体积很小,只包括几个在序列上面进行简单数学运算的模板函数
#include <numeric>
③这个头文件它主要是定义了一些模板类,用以声明函数对象
#include <functional>
4.算法可以分为哪几大类?🐯
| 类别 | 简介 |
|---|---|
| ①非可变序列算法 | 如:for_each,先行查找,子序列匹配,元素个数,元素比较,最大与最小值,不能直接修改其所操作的容器内容。 |
| ②可变序列算法 | 算法要修改容器元素的值或顺序。例如:复制、填充、交换、替换、生成等,可以修改它们所操作的容器内容的算法 |
| ③排序算法 | 包括排序、二分查找、归并排序、堆排序、有序查找等。 |
| ④数值算法 | 包括向量运算、复数运算、求和、内积等,对容器内容进行数值计算。 |
二、常用算法合集
1、遍历算法
1.1 for_each(遍历容器)
①算法简介
- for_each算法是最常见的遍历算法,它是一种增强型for循环,可以实现数组或集合的遍历
②函数原型
for_each(iterator beg,iterator end,_func);
//beg - 开始迭代器
//end- 结束迭代器
//-func - 函数或函数对象
③示例代码
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
//常用遍历算法 - for_each
//普通函数
void print1(int val)
{
cout << val << " ";
}
//仿函数
class print2 {
public:
void operator()(int val)
{
cout << val << " ";
}
};
void test1()
{
vector<int> v;
for (int i = 0; i < 10; ++i)
{
v.push_back(i);
}
for_each(v.begin(), v.end(), print1);
cout << endl;
for_each(v.begin(), v.end(), print2());
cout << endl;
}
int main(void)
{
test1();
return 0;
}
运行结果:

讲解:
- 可以看到,用的vector容器插入了十个数,然后对它们进行输出。这里在使用for_each时用到了两种方法,也就是第三个参数的变化,首先使用的是函数print1(),这就是一个普通的打印函数;第二种使用的则是函数对象,这里需要在前面先定义一个仿函数,这个我在STL容器详解中有到过,大家可以去看看。这里需要注意的是,在使用普通函数是,for_each()中是不需要写*()小括号的,但是在使用函数对象的大家不要忘了加上()小括号*
1.2 transform(搬运容器)
①算法简介
- 接下来介绍另一种遍历算法transform,它可以实现将一个容器中的内容搬运到另一个容器中
②函数原型
transform(iterator beg1,iterator end1,iterator beg2,_func);
//beg1 - 原容器的开始迭代器
//end1- 原容器的结束迭代器
//beg2 - 目标容器的开始迭代器
//_func - 函数或函数对象
③示例代码
class Transform {
public:
int operator()(int v)
{
return v + 100;
}
};
//输出
class print{
public:
void operator()(int val)
{
cout << val << " ";
}
};
void test2()
{
vector<int> v;
for (int i = 0; i < 10; ++i)
{
v.push_back(i);
}
vector<int> v2;
v2.resize(v.size()); //以v1的大小为v2重新开辟空间
transform(v.begin(),v.end(),v2.begin(),Transform());
for_each(v2.begin(), v2.end(), print());
}
运算结果:

讲解:
- 从运行结果我们可以看到容器中1~10的数字都加上了100,这是因为在transform算法的使用中最后一个参数可以对搬运过程中的数据进行一些逻辑运算,比如说加减乘除之类的,这里我就用仿函数并return了每个数加100之后的结果,然后用for_each输出,便是我们所要的结果
2、查找算法
2.1 find(查找元素)
①算法简介
- 接下来就开始介绍查找算法,首先就是最常见的find,它的功能是查找指定元素,找到返回指定元素的迭代器,找不到返回结束迭代器end()
②函数原型
find(iterator beg,iterator end,value);
//beg - 开始迭代器
//end- 结束迭代器
//value- 查找的元素
③示例代码
首先是内置数据类型的查找
void test3()
{
vector<int> v;
for (int i = 0; i < 10; ++i)
{
v.push_back(i);
}
vector<int>::iterator it = find(v.begin(), v.end(), 5);
if (it == v.end())
{
cout << "没有找到此元素" << endl;
}
else
{
cout << "找到了," << "此元素为:" << *it << endl;
}
}
运行结果:

接着是自定义数据类型
//自定义数据类型
class Person {
public:
Person(string name, int age)
{
this->m_name = name;
this->m_age = age;
}
bool operator==(const Person& p)
{
if (this->m_name == p.m_name && this->m_age == p.m_age)
{
return true;
}
else
{
return false;
}
}
string m_name;
int m_age;
};
void test4()
{
vector<Person> v2;
Person p1("aaa", 10);
Person p2("bbb", 20);
Person p3("ccc", 30);
Person p4("ddd", 40);
v2.push_back(p1);
v2.push_back(p2);
v2.push_back(p3);
v2.push_back(p4);
Person pp("aaa", 10);
vector<Person>::iterator it = find(v2.begin(), v2.end(), pp);
if (it == v2.end())
{
cout << "没有找到此元素" << endl;
}
else
{
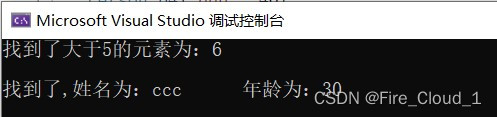
cout << "找到了," << "姓名为:" << it->m_name << "\t年龄为:" << it->m_age << endl;
}
}
运行结果:

讲解:
- 这里是对于两种数据类型进行查找。首先是第一种内置数据类型,就是简单地查找在一个vector容器中指定的数据;然后是较复杂一些的自定义数据类型,这里是定义了一个Person类,有姓名和年龄两种数据类型,在构建好类对象后将他们放入容器,接着就是通过find来查找在容器中是否有和给出的对象相同的数据属性,因为find返回的是一个迭代器,所以我们要用这个容器所对应的迭代器去接收,当这个迭代器抵达容器的end()还没有找到,说明在此容器中无需要查找的元素值。但是如果就这样运行的话会报这样的错误👇

find算法底层原理:
template <class _InIt, class _Ty>
_NODISCARD _CONSTEXPR20 _InIt find(_InIt _First, const _InIt _Last, const _Ty& _Val) { // find first matching _Val
_Adl_verify_range(_First, _Last);
_Seek_wrapped(_First, _Find_unchecked(_Get_unwrapped(_First), _Get_unwrapped(_Last), _Val));
return _First;
}
我们到find算法的底层可以知晓,,因为我们现在操作的是自定义的数据类型,编译器并不知道如何去做"=="号的对比,不知道是比较姓名还是年龄,因此我们需要利用C++中重载运算符的操作,将这个等于号重新定义一下,于是就有了这段代码,在这样重载后,进行两个元素的比较就不会出现问题了。
所以大家在操纵自定义数据类型的时候别忘了重载这个等于号;
bool operator==(const Person& p)
{
if (this->m_name == p.m_name && this->m_age == p.m_age)
{
return true;
}
else
{
return false;
}
}
2.2 find_if(按条件查找元素)
①算法简介
- 对于find_if,它其实就是find升级版,可以按条件查找元素,比较特殊的是它的第三个参数是一个 lambda 表达式的谓词。这个 lambda 表达式以值的方式捕获 value,并在 lambda 参数大于 value 时返回 true
②函数原型
transform(iterator beg1,iterator end1,iterator beg2,_func);
//beg1 - 开始迭代器
//end1- 结束迭代器
//_Pred - 函数或者谓词(返回布尔类型的仿函数)
③示例代码
由于这里的代码与find中相似,只是做了一些仿函数的修改,因此只出示关键代码
//内置数据类型
class GreaterFive {
//仿函数的编写
public:
bool operator()(int v)
{
return v > 5;
}
};
//具体函数的使用
vector<int>::iterator it = find_if(v.begin(), v.end(), GreaterFive());
//自定义数据类型
class Greater20 {
//仿函数的编写
public:
bool operator()(Person& p)
{
return p.m_age > 20;
}
};
//具体函数的使用
vector<Person>::iterator it = find_if(v2.begin(), v2.end(), Greater20());
运行结果:
讲解:
这里是使用到了谓词,它是仿函数的一种,我们把返回bool类型的仿函数就叫做谓词。首先对于内置数据类型,return v > 5是返回一个大于5的数字,如果找到了,它会返回true,如果没找到呢,就会返回false;然后是对于自定义数据类型,return p.m_age > 20是返回年龄大于20岁的所属元素对象,在项目制作时,仿函数还是会起到很大作用的,大家可以去了解一下。
2.3 adjacent_find(查找相邻重复元素)
①算法简介
- adjacent_find,这个算法可以用来查找相邻的重复元素,然后返回相邻元素的第一个位置的迭代器
②函数原型
adjacent_find(iterator beg,iterator end);
//beg - 开始迭代器
//end- 结束迭代器
③示例代码
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
//常用查找算法 - adjacent_find
void test7()
{
vector<int> v;
v.push_back(4);
v.push_back(1);
v.push_back(6);
v.push_back(9);
v.push_back(9);
v.push_back(14);
v.push_back(2);
vector<int>::iterator it=adjacent_find(v.begin(), v.end());
if (it == v.end())
cout << "没找到相邻的重复元素" << endl;
else
cout << "找到相邻的重复元素,为:" << *it << endl;
}
int main(void)
{
test7();
return 0;
}
运行结果:

讲解:
对于这个算法,它并不复杂,传入需查找元素的其实迭代器和结束迭代器就行,我们来看一下它的底层定义,从中可以看出,它是利用了一个next值去不断更新起始迭代器的位置,找出重复的元素,然后去逐一判断两个元素是否相邻,如果next != last,则表示此时后面的元素与前一个元素已然不同,因此跳出while循环,此时的后一位元素。
从这里我们可以看出这个算法的调用虽然很简单,但是其底层原理的判断还是有些曲折,但好在是有这么一个算法,如果我们将它记住,在需要用到此功能的场景时就可以得心应手了🐑
template <class ForwardIterator>
ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last)
{
if (first != last)
{
ForwardIterator next=first; ++next;
while (next != last) {
if (*first == *next) // or: if (pred(*first,*next)), for version (2)
return first;
++first; ++next;
}
}
return last;
}
2.4 binary_search(二分查找法)
①算法简介
- 接下来呢也是一个常用也很高效的算法,就是binary_search用英文直译过来就是二分查找,这个算法相信起初大家在学习C语言的时候应该也有接触过,并且学习并实现过其代码,现在这里有一个现成的算法模板可以用,接下来让我们来探究一番。
②函数原型
bool binary_search(iterator beg,iterator end,value);
//beg - 开始迭代器
//end- 结束迭代器
//value - 查找的元素
③示例代码
vector<int> v;
for (int i = 0; i < 10; ++i)
{
v.push_back(i);
}
//v.push_back(2);
//若所示序列为无序序列,则查找结果不确定
//必须要是有序序列
bool ret = binary_search(v.begin(), v.end(), 9);
if (ret)
cout << "找到了" << endl;
else
cout << "未找到" << endl;
讲解:
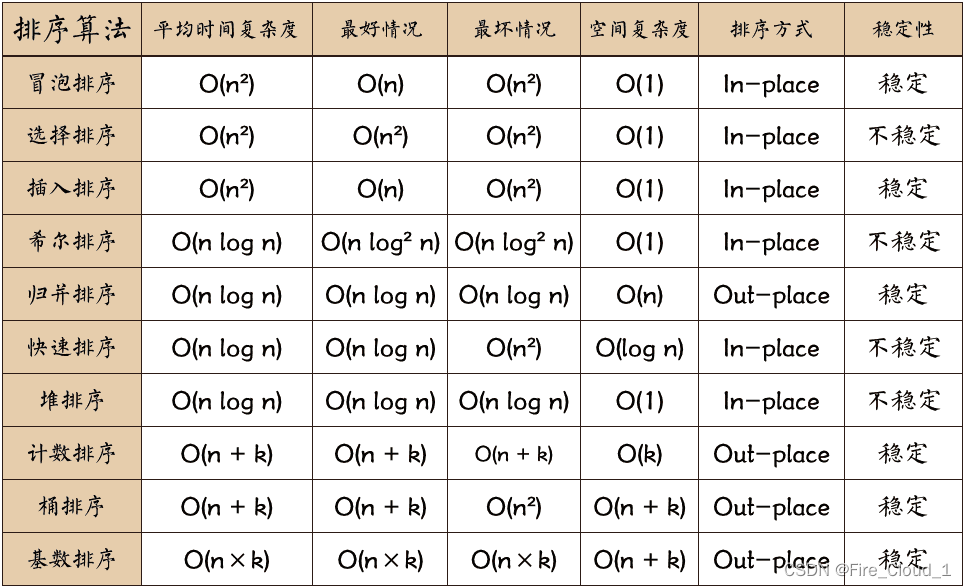
由于其运行结果过于简洁明了,就不作展示了,从代码中可以看出,这个算法和前面的算法不太一样,因为它要判断是否找到需查元素,因此会返回true和false,因此就要定义一个布尔类型的值去接收它。这里还要注意的一点是,查找的序列要为一个有序序列,不可是无序序列,但如果大家在做题的时候碰到的是一个无序序列,可以用归并排个序,然后用此二分查找,在我认为这样的时间复杂度是最低的,因为归并较其他的排序来说相对稳定,而且时间复杂度也比较低,大家可以去学习一下,它是十大排序算法中的一种,这里给出表格大家可以先参照一下🐌;
2.5 count(统计元素个数)
①算法简介
- 对于count()算法,它可以统计一个区间中元素出现的次数,比如我们可以找出容器中元素值为80的元素个数,直接定义一个整型变量去接收即可
②函数原型
count(iterator beg,iterator end,value);
//beg - 开始迭代器
//end- 结束迭代器
//value - 查找的元素
③示例代码
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
//常用查找算法 - count
//内置数据类型
void test9()
{
vector<int> v;
v.push_back(80);
v.push_back(10);
v.push_back(50);
v.push_back(80);
v.push_back(80);
v.push_back(80);
int num = count(v.begin(), v.end(), 80);
cout << "容器中数值 80 有:" << num << "个" << endl;
}
//自定义数据类型
class Person {
public:
Person(string name, int age)
{
this->m_name = name;
this->m_age = age;
}
bool operator==(const Person& p)
{
if (this->m_age == p.m_age)
return true;
else
return false;
}
string m_name;
int m_age;
};
void test10()
{
vector<Person> v;
Person p1("刘备",35);
Person p2("关羽",40);
Person p3("张飞",36);
Person p4("孙权",35);
Person p5("孙策",35);
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
v.push_back(p4);
v.push_back(p5);
Person p("诸葛亮", 35);
int num = count(v.begin(), v.end(), p);
cout << "容器中与诸葛亮年龄相同的人有:" << num << "个" << endl;
}
/**/int main(void)
{
test9();
cout << endl;
test10();
return 0;
}
运行结果:

讲解:
本算法也是可以有两种数据类型的统计,其元素和上述讲过的算法类似,故不做过多分析,大家一看就能懂,就是在统计容器中指定元素的个数
2.6 count_if(按条件统计元素个数)
①算法简介
- count与count_if和find与find_if类型,后面加了if,说明这可以加入条件判断,以此来输出我们执行范围的元素个数
②函数原型
count_if(iterator beg,iterator end,value);
//beg - 开始迭代器
//end- 结束迭代器
//value - 查找的元素
③示例代码
这里一样只给出关键代码
//内置数据类型
class Greater20 {
public:
int operator()(int v)
{
return v > 20;
}
};
class Greater30 {
public:
int operator()(const Person& p)
{
return p.m_age > 35;
}
};
运行结果:

3、排序算法
3.1 sort(快速排序)
①算法简介
- 接下来我们来学习常用的排序算法,首先就是用的最多的sort()快速排序,虽然其稳定性和时间复杂度有些许逊色,但用起来还是很香的😍,因为它已经给我们定义好了这么一个API,不需要我们自己实现了,只需要传入对应的参数,即可完成升序或者降序的功能
②函数原型
sort(iterator beg,iterator end,_Pred);
//beg - 开始迭代器
//end- 结束迭代器
//_Pred - 谓词
③示例代码
class print {
public:
void operator()(int val)
{
cout << val <<" ";
}
};
void test1()
{
vector<int> v;
v.push_back(10);
v.push_back(90);
v.push_back(40);
v.push_back(60);
v.push_back(70);
sort(v.begin(), v.end()); //默认升序 - less
for_each(v.begin(), v.end(), print());
cout << endl;
sort(v.begin(), v.end(),greater<int>()); //降序 - greater
for_each(v.begin(), v.end(), print());
cout << endl;
}
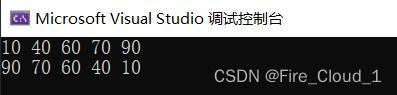
运行结果:
讲解:
从运行结果我们可以看出,对容器中的无序数据进行默认sort()排序,是升序的,谓词也就是less,这个和优先队列里面的小顶堆类似,然后我们去更改它的谓词值,改为greater(),看显示结果就变为了降序,greater也就是大顶锥,在优先队列中相当于优先出队中最大的元素,所以最前面的就是最大的,了解了这两种谓词,那你也就掌握快速的使用方法;
3.2 random_shuffle(随机调整次序)
①算法简介
- 接下来这个算法叫做random_shuffle,听起来是不是很高大上呢,它可以将我们容器中的顺序随机做一个打乱,所以我们管这个算法也叫做洗牌算法,看起来很厉害,其实正在用的时候很简单,只需要提供容器的起始迭代器和结束迭代器便可;
②函数原型
transform(iterator beg,iterator end);
//beg - 开始迭代器
//end- 结束迭代器
③示例代码
class print {
public:
void operator()(int val)
{
cout << val << " ";
}
};
void test2()
{
srand((unsigned int)time(NULL));
vector<int> v;
for (int i = 0; i < 10; ++i)
{
v.push_back(i);
}
cout << "打乱前" << endl;
for_each(v.begin(), v.end(), print());
cout << endl;
cout << "打乱后" << endl;
random_shuffle(v.begin(), v.end());
for_each(v.begin(), v.end(), print());
cout << endl;
}
运行结果:

讲解:
从运行结果我们可以看出,确实是进行了一个洗牌的操作,对vector容器,我们插入了十个0-9之间的数,在传入其begin()和end()直接便直接进行“洗牌”操作,这个的话在生活实例中可以做类似于抽签之类的操作,可以打乱原数组的顺序,既然有这么一个现成的算法,我们就可以直接拿来用,不需要在自己重新写一个了
3.3 merge(容器元素合并)
①算法简介
- 接下来讲的这个算法,也比较厉害,它可以将两个容器元素合并,并存储到另一容器中,但是要放入的迭代器就会很多,从其函数原型中,我们可以看到它要接收的参数有五个
②函数原型
merge(iterator beg1,iterator end1,iterator beg2,iterator end2,iterator dest);
//beg1 - 容器1的开始迭代器
//end1- 容器1的结束迭代器
//beg2 - 容器2的开始迭代器
//end2- 容器2的结束迭代器
//dest - 目标容器的起始迭代器
③示例代码
vector<int> v1;
vector<int> v2;
v1.push_back(2);
v1.push_back(5);
v1.push_back(6);
v1.push_back(10);
v1.push_back(48);
v2.push_back(8);
v2.push_back(15);
v2.push_back(20);
v2.push_back(28);
v2.push_back(30);
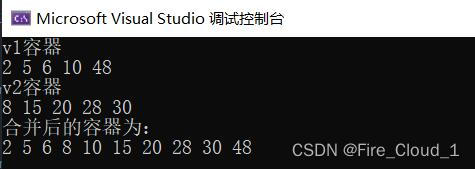
cout << "v1容器" << endl;
for_each(v1.begin(), v1.end(), print());
cout << endl;
cout << "v2容器" << endl;
for_each(v2.begin(), v2.end(), print());
cout << endl;
vector<int> v3;
v3.resize(v1.size() + v2.size());
cout << "合并后的容器为:" << endl;
merge(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for_each(v3.begin(), v3.end(), print());
cout << endl;
运行结果:
讲解:
从运行结果我们可以看到首先是生成了两个容器,并且分别存入五个数据,然后就是将容器1的起始迭代器和结束迭代器传入,同理,容器2也是一样,最后放置的是目标容器的起始迭代器,但是这里有一个细节要注意,如果你直接将两个容器合并放到一个容器中,那这个目标容器其实是空的,没有存储空间来放置这些元素,所以这里我们要利用容器1和容器2的大小来resize(重新开辟)目标容器的大小,其大小表示前二者之和,从结果来看,这个算法不仅可以实现容器的合并,还可以对合并后的这些数据自动进行一个排序
3.4 reverse(容器元素反转)
①算法简介
- 最后这个排序算法叫做reverse,英文直译就是反转的意思,因此它可以将容器内的元素进行一个反转
②函数原型
transform(iterator beg1,iterator end1,iterator beg2,_func);
//beg - 开始迭代器
//end- 结束迭代器
③示例代码
v.push_back(2);
v.push_back(5);
v.push_back(6);
v.push_back(10);
v.push_back(48);
cout << "反转前" << endl;
for_each(v.begin(), v.end(), print());
cout << endl;
cout << "反转后" << endl;
reverse(v.begin(), v.end());
for_each(v.begin(), v.end(), print());
cout << endl;
运行结果:

讲解:
从代码和运行结果来看,这个算法都显得非常得简单,但正是因为它简单,所以我们更应该很好地去记住它,虽然这个功能实现起来也不太麻烦,十行代码之内也能解决,但这就是STL算法的魅力,可以将大家都常用的功能封装成一个算法,一个模板,可以让我们直接来使用,在进行一些大型开发时就可以很好地利用
4、拷贝和替换算法
4.1 copy(容器元素拷贝)
①算法简介
- 接下来要介绍的是拷贝算法copy(),这个算法可是非常的常见,而且被广大程序员所经常使用,可以将容器内执行范围的元素拷贝到另一容器中,它的实现也不复杂,让我们一起来看看吧
②函数原型
copy(iterator beg,iterator end,iterator dest);
//beg - 开始迭代器
//end- 结束迭代器
//dest- 目标容器其实迭代器
③示例代码
vector<int> v;
for (int i = 0; i < 10; ++i)
{
v.push_back(i);
}
cout << "原容器中的元素为:";
for_each(v.begin(), v.end(), print);
cout << endl;
vector<int> v2;
v2.resize(v.size());
copy(v.begin(), v.end(), v2.begin());
cout << "拷贝完后的目标容器元素为:";
for_each(v2.begin(), v2.end(), print);
cout << endl;
运行结果:
讲解:
这个算法也和上一个reverse算法一样,都不是很难,但确实用的比较多的两个算法,这里也是要注意,对需要拷贝的目标容器,一样要重新开辟其容器空间,而且要以原容器的size()来开辟;
接下来介绍的这两个算法和find,find_if以及count,count_if类似,因此只做简略分析,给出关键代码
4.2 replace(修改元素)
①算法简介
- 这个算法可以将容器内指定范围内的元素替换成新元素
②函数原型
replace(iterator beg,iterator end,oldvalue,newvalue);
//beg - 开始迭代器
//end- 结束迭代器
//oldvalue - 旧元素
//newvalue - 新元素
③示例代码
vector<int> v;
v.push_back(50);
v.push_back(10);
v.push_back(70);
v.push_back(30);
v.push_back(60);
v.push_back(20);
v.push_back(50);
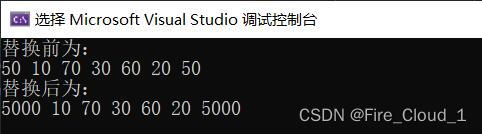
cout << "替换前为:" << endl;
for_each(v.begin(), v.end(), print2);
cout << endl;
replace(v.begin(), v.end(), 50, 5000);
cout << "替换后为:" << endl;
for_each(v.begin(), v.end(), print2);
cout << endl;
运行结果:
讲解:
从运行结果可以看出,原容器中的50都被改成了5000,实现了整体替换的功能
4.3 replace_if(按条件修改元素)
①算法简介
- 这个算法就是在replace的基础上,加上一个条件判断,对容器内指定大小或范围的元素进行一个替换操作
②函数原型
transform(iterator beg1,iterator end1,_pred,newvalue);
//beg - 开始迭代器
//end- 结束迭代器
//_pred - 谓词
//newvalue - 替换的新元素
③关键代码
class Greater30 {
public:
int operator()(int val)
{
return val > 30;
}
};
replace_if(v.begin(), v.end(), Greater30(), 3000);
运行结果:

讲解:
从运行结果我们可以看出,使用了谓词Greater30()后,原容器中所有>30的数都被改成了3000,这个功能其实就挺强大的,因为我们程序员在开发的过程中,每天要面对上万行代码,对一些小数据不可能一个个地去改,但如果有了这种指定修改的功能,那么就会事半而功倍
4.4 swap(容器元素交换)
①算法简介
- 最后是一个交换算法swap()这个算法相信很多小伙伴在学习C语言的时候都自己也去实现过这个功能,通过指针地址的传值,或者C++中的引用传址,都可以交换两个数,但是这里就有一个现成封装好算法,如果我们把它记住了,那就不用每次都重新写一遍交换算法了,可以直接把这个算法拿来用
②函数原型
swap(containter c1,containter c2);
//c1 - 容器1
//c2 - 容器2
注:传入的容器需要同种类型的,不可以是一个vector容器一个list容器
③示例代码
vector<int> v1;
vector<int> v2;
for (int i = 0; i < 10; ++i)
{
v1.push_back(i);
v2.push_back(i + 100);
}
cout << "替换前为:" << endl;
for_each(v1.begin(), v1.end(), print4);
cout << endl;
for_each(v2.begin(), v2.end(), print4);
cout << endl;
cout << "替换后为:" << endl;
swap(v1, v2);
for_each(v1.begin(), v1.end(), print4);
cout << endl;
for_each(v2.begin(), v2.end(), print4);
cout << endl;
运行结果:

讲解:
从结果我们可以看到,起初两个vector容器v1和v2分别是0-9和100-109,然后经过swap()函数替换之后,输出的顺序就发生了改变,其实两个容器已经发生了互换,怎么样,是不是很简便,只需要传入两个容器体即可,无需传入迭代器
5、算数生成算法
接下来将两个常用的算数生成算法,这两个算法属于一种小型算法,它们所属的头文件并不是algorithm,而是我们开头提到过的numeric
#include <numeric>
5.1 accumulate(计算累计总和)
①算法简介
- 这个算法可以用于计算区间内容器元素的累计总和,平常我们也会有过计算一个数组的总和,但这个算法却可以计算一个指定区间内的总和
②函数原型
accumulate(iterator beg,iterator end,value);
//beg - 开始迭代器
//end- 结束迭代器
//value - 起始的累加值
③示例代码
vector<int> v;
for (int i = 0; i <= 100; ++i)
{
v.push_back(i);
}
//参数3 - 起始的累加值
int total = accumulate(v.begin(), v.end(), 0);
cout << "total=" << total << endl;
运行结果:

讲解:
可以看出代码和运行结果都非常简单,只需要传入一个容器的起始迭代器和结束迭代器,然后最后一个参数值得关注一下,指的就是起始的累加值,比如说我们这里是从0加到100,结果是5050,因为起始累加值是0,但如果将其改为1000,那么这个结果就要在1000的基础上去累加,出来的结果便是6050了,大家明白了吗🐳
5.2 fill(填充元素)
①算法简介
- fill从字面意思来看就是填充的意思,它可以是实现向容器中填充指定的元素,让我们一起来探究一番
②函数原型
fill(iterator beg,iterator end,value);
//beg - 开始迭代器
//end- 结束迭代器
//value - 填充的值
③示例代码
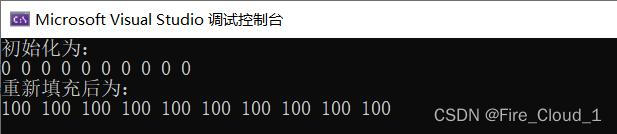
vector<int> v;
v.resize(10);
cout << "初始化为:" << endl;
for_each(v.begin(), v.end(), print);
cout << endl;
//后期重新填充
fill(v.begin(), v.end(), 100);
cout << "重新填充后为:" << endl;
for_each(v.begin(), v.end(), print);
cout << endl;
运行结果:
讲解:
首先我们创建了一个vector容器,一开始的时候我们就用resize()的方式指定几个数字进去,这里会按照你指定的大小来给你填充默认0,但是在后期如果我们像修改这些值,就可以使用fill来进行一个重新的填充。很简单,只需要传入容器的起始的结束迭代器,以及需要填充的值,观看运行结果,我们便可以看到容器中的10个元素已经被填充成为0;
6、集合算法
最后呢,我们来看看常用的集合算法,主要有交集、并集和差集这几种,为了可视化,所以配了插图哦🌌
6.1 set_intersection(交集)
①算法简介
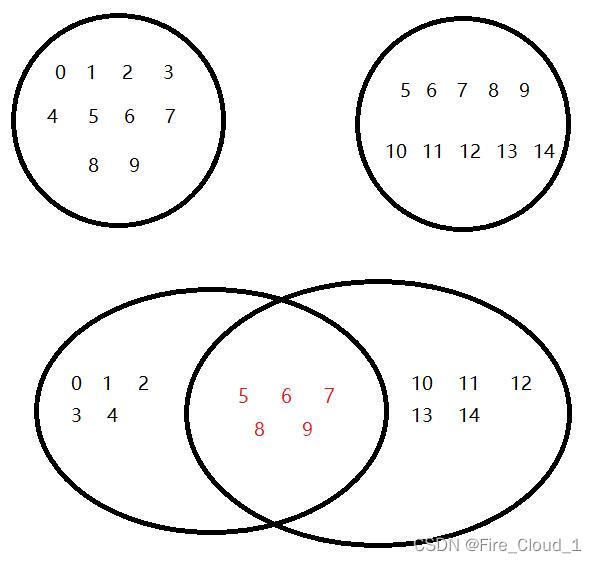
- 首先呢,是求两个容器中元素的交集,使用到的是set_intersection()这个算法,什么是交集呢,我们来看看这张图,从中可以看出,是两个容器中相同的元素:
②函数原型
set_intersection(iterator beg1,iterator end1,iterator beg2,iterator end2,iterator dest);
//beg1 - 容器1开始迭代器
//end1 - 容器1结束迭代器
//beg2 - 容器2开始迭代器
//end2 - 容器2结束迭代器
//dest - 目标容器开始迭代器
③示例代码
vector<int> v1;
vector<int> v2;
//两个集合需要是有序序列
for (int i = 0; i < 10; ++i)
{
v1.push_back(i); //0~9
v2.push_back(i + 5); //5~14
} //--》5 6 7 8 9
vector<int> v3;
//目标容器需要提前开辟空间
//最特殊情况 大容器包含小容器 开辟空间 取小容器的size即可
v3.resize(min(v1.size(), v2.size())); //min() - 比较两者的大小
vector<int>::iterator itEnd = set_intersection(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
cout << "两容器中元素的交集为:";
//返回目标容器最后一个元素的迭代器位置
for_each(v3.begin(), itEnd, print());
//for_each(v3.begin(), v3.end(), print()); //相当于把容器所有所有数据都遍历一遍
//如果用的不是itEnd而是v3.end(),
运行结果:

讲解:
运行结果很明确,和我们前面分析的一致,这里要注意的是,对于目标容器,我们要重新开辟其大小,以=最坏的情况来分析,就是大容器包含小容器,因此我们将目标容器的大小设置为两个容器中较小的那个便可,这里的min()函数就是取两个当中最小值,然后因为set_intersection()返回的是一个迭代器,所以我们要用对应的迭代器去接收,最后要注意的一点是在遍历输出的时候,结束迭代器的位置不可以写当前迭代器的end(),不然就会出现下面这样的情况 👇

这样相当于把容器中所有数据都遍历一遍,但是刚才我们在开辟容器的时候,我们考虑的时候一种最特殊的情况,但实际中可以比这个大,也有可能比这个小,这里就是比大了,所以容器中剩余的部分自动填充为0,但我们用这个求交集算法返回的迭代器的位置,就是它最后所求得的两个容器中相同的最后一个元素,所以不会出现多余的情况
6.2 set_union(并集)
①算法简介
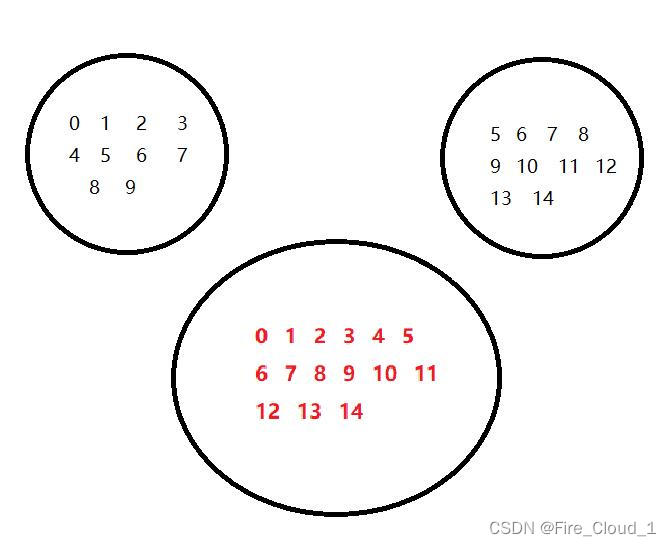
- 这个算法和上一个求交集的算法是同源的,这个是求并集,原理也是一样,把两个容器中所有元素都去重并合并到另一个容器中,我们依旧来看一下它的原理,就如下图所示,
②函数原型
set_union(iterator beg1,iterator end1,iterator beg2,iterator end2,iterator dest);
//beg1 - 容器1开始迭代器
//end1 - 容器1结束迭代器
//beg2 - 容器2开始迭代器
//end2 - 容器2结束迭代器
//dest - 目标容器开始迭代器
③关键代码
v3.resize(v1.size() + v2.size());
vector<int>::iterator itEnd = set_union(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for_each(v3.begin(), itEnd, print());
运行结果:

讲解:
这里的并集和求交集的代码很是类似,因此只给出关键代码,依旧要注意的一点是,这里目标容器的大小也是要重新开辟,这里要考虑到的最坏情况就是两个容器无交集,是分离的,就像我上面画的那样,所以大小等于的他们的size()相加。还有一点也是一样,就是在输出的时候要用set_union()算法最后遍历到的迭代器,不要用我们自己开辟大小的迭代器的末尾元素,不然会像求交集那样后面输出都是0
6.2 set_difference(差集)
①算法简介
- 终于到了本文章的最后一个常用算法,那就是求两个容的差集,比如说容器A和容器B,如果要求解的是A在B中的差集,就是A中有而B中没有,让我们一起来看一下原理图:
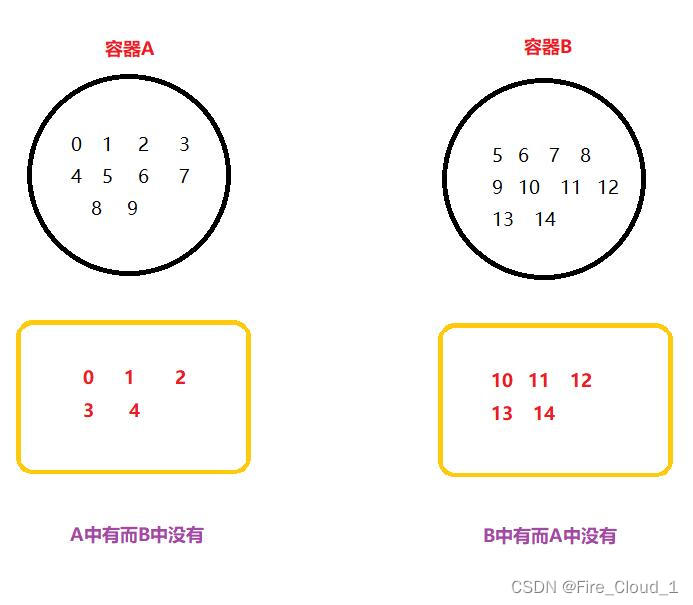
②函数原型
set_difference(iterator beg1,iterator end1,iterator beg2,iterator end2,iterator dest);
//beg1 - 容器1开始迭代器
//end1 - 容器1结束迭代器
//beg2 - 容器2开始迭代器
//end2 - 容器2结束迭代器
//dest - 目标容器开始迭代器
③关键代码
vector<int> v3;
//最特殊的情况,两个容器没有交集,差集便是大的那个容器
v3.resize(max(v1.size(), v2.size()));
cout << "v1与v2的差集为:" << endl;
vector<int>::iterator itEnd=set_difference(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for_each(v3.begin(), itEnd, print);
cout <<endl<< "v2与v1的差集为:" << endl;
itEnd = set_difference(v2.begin(), v2.end(), v1.begin(), v1.end(), v3.begin());
for_each(v3.begin(), itEnd, print);
运行结果:
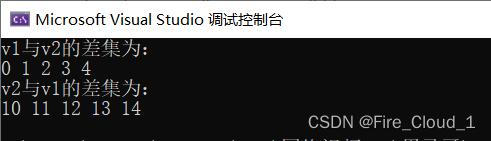
讲解:
从运行结果来看,对于我们的原理图是不是更加清晰了,好了,这就是求两个容器的差集。这三个对于集合方面的运算其实在企业开发过程中还是可能能用到,因为可以对两个容器中的数据进行求解多数求解操作,大家能记住的话还是很有帮助的
三、总结与回顾
完结撒花🌺 看完了STL中的这些常用算法,你对于算法有没有一个基本的概念呢,让我们一起来回顾一下吧,在本文中,我们分别讲了遍历、查找、排序、拷贝、替换、算法生成和集合算法这些,每一种算法里面分别例举几个常见的,但是STL中的算法可不止这些,还有很多呢,因为只是给大家做一个了解入门,所以只例举了里面的一些常见但高频的算法,如果您还想继续学习一些更高级的算法,像equal_range(折半查找)、partial_sort(局部排序)以及pre/next_permutation(上\下一个排列组合)这些等等。推荐大家去看《STL源码剖析》这本书,里面介绍很多算法以及计算机内部的一些底层实现
最后感谢您对本文的观看,如有问题,请于评论区或私信指出,谢谢
















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











