







C++常用算法
C++ sort()排序函数用法详解
C++ STL 标准库提供有很多实用的排序函数,如表 1 所示。通过调用它们,我们可以很轻松地实现对普通数组或者容器中指定范围内的元素进行排序。
表 1 C++ STL 排序函数
| 函数名 | 用法 |
|---|---|
| sort (first, last) | 对容器或普通数组中 [first, last) 范围内的元素进行排序,默认进行升序排序。 |
| stable_sort (first, last) | 和 sort() 函数功能相似,不同之处在于,对于 [first, last) 范围内值相同的元素,该函数不会改变它们的相对位置。 |
| partial_sort (first, middle, last) | 从 [first,last) 范围内,筛选出 muddle-first 个最小的元素并排序存放在 [first,middle) 区间中。 |
| partial_sort_copy (first, last, result_first, result_last) | 从 [first, last) 范围内筛选出 result_last-result_first 个元素排序并存储到 [result_first, result_last) 指定的范围中。 |
| is_sorted (first, last) | 检测 [first, last) 范围内是否已经排好序,默认检测是否按升序排序。 |
| is_sorted_until (first, last) | 和 is_sorted() 函数功能类似,唯一的区别在于,如果 [first, last) 范围的元素没有排好序,则该函数会返回一个指向首个不遵循排序规则的元素的迭代器。 |
| void nth_element (first, nth, last) | 找到 [first, last) 范围内按照排序规则(默认按照升序排序)应该位于第 nth 个位置处的元素,并将其放置到此位置。同时使该位置左侧的所有元素都比其存放的元素小,该位置右侧的所有元素都比其存放的元素大。 |
对于表 1 中罗列的这些函数,本教程会一一进行讲解,这里先介绍 sort() 函数。
C++ sort()排序函数
C++ STL 标准库中的 sort() 函数,本质就是一个模板函数。正如表 1 中描述的,该函数专门用来对容器或普通数组中指定范围内的元素进行排序,排序规则默认以元素值的大小做升序排序,除此之外我们也可以选择标准库提供的其它排序规则(比如std::greater<T>降序排序规则),甚至还可以自定义排序规则。
sort() 函数是基于快速排序实现的,有关快速排序的具体实现过程,感兴趣的读者可阅读《快速排序(QSort,快排)算法》一文。
需要注意的是,sort() 函数受到底层实现方式的限制,它仅适用于普通数组和部分类型的容器。换句话说,只有普通数组和具备以下条件的容器,才能使用 sort() 函数:
- 容器支持的迭代器类型必须为随机访问迭代器。这意味着,sort() 只对 array、vector、deque 这 3 个容器提供支持。
- 如果对容器中指定区域的元素做默认升序排序,则元素类型必须支持
<小于运算符;同样,如果选用标准库提供的其它排序规则,元素类型也必须支持该规则底层实现所用的比较运算符; - sort() 函数在实现排序时,需要交换容器中元素的存储位置。这种情况下,如果容器中存储的是自定义的类对象,则该类的内部必须提供移动构造函数和移动赋值运算符。
另外还需要注意的一点是,对于指定区域内值相等的元素,sort() 函数无法保证它们的相对位置不发生改变。例如,有如下一组数据:
2 1 2 3 2
可以看到,该组数据中包含多个值为 2 的元素,此时如果使用 sort() 函数进行排序,则值为 2 的这 3 个元素的相对位置可能会发生改变,比如排序结果为:
1 2 2 2 3
可以看到,原本红色的元素 2 位于绿色 2 和橙色 2 的左侧,但经过 sort() 函数排序之后,它们的相对位置发生了改变,即红色 2 移动到了绿色 2 和橙色 2 的右侧。
实际场景中,如果需要保证值相等元素的相对位置不发生改变,可以选用 stable_sort() 排序函数。有关该函数的具体用法,后续章节会做详细讲解。
值得一提的是,sort() 函数位于<algorithm>头文件中,因此在使用该函数前,程序中应包含如下语句:
#include <algorithm>
sort() 函数有 2 种用法,其语法格式分别为:
//对 [first, last) 区域内的元素做默认的升序排序
void sort (RandomAccessIterator first, RandomAccessIterator last);
//按照指定的 comp 排序规则,对 [first, last) 区域内的元素进行排序
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
其中,first 和 last 都为随机访问迭代器,它们的组合 [first, last) 用来指定要排序的目标区域;另外在第 2 种格式中,comp 可以是 C++ STL 标准库提供的排序规则(比如 std::greater),也可以是自定义的排序规则。
关于如何自定义一个排序规则,除了《C++ STL关联式容器自定义排序规则》一节介绍的 2 种方式外,还可以直接定义一个具有 2 个参数并返回 bool 类型值的函数作为排序规则。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::sort
#include <vector> // std::vector
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector<int> myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用第一种语法格式,对 32、71、12、45 进行排序
std::sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater<T>)进行排序
std::sort(myvector.begin(), myvector.begin() + 4, std::greater<int>()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序
std::sort(myvector.begin(), myvector.end(), mycomp2());//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
return 0;
}
程序执行结果为:
12 26 32 33 45 53 71 80
可以看到,程序中分别以函数和函数对象的方式自定义了具有相同功能的 mycomp 和 mycomp2 升序排序规则。需要注意的是,和为关联式容器设定排序规则不同,给 sort() 函数指定排序规则时,需要为其传入一个函数名(例如 mycomp )或者函数对象(例如 std::greater() 或者 mycomp2())。
那么,sort() 函数的效率怎么样吗?该函数实现排序的平均时间复杂度为N*log2N(其中 N 为指定区域 [first, last) 中 last 和 first 的距离)。
C++ stable_sort()用法详解
通过阅读《C++ sort()排序函数》一节,读者已经了解了 sort() 函数的功能和用法。值得一提的是,当指定范围内包含多个相等的元素时,sort() 排序函数无法保证不改变它们的相对位置。那么,如果既要完成排序又要保证相等元素的相对位置,该怎么办呢?可以使用 stable_sort() 函数。
有些场景是需要保证相等元素的相对位置的。例如对于一个保存某种事务(比如银行账户)的容器,在处理这些事务之前,为了能够有序更新这些账户,需要按照账号对它们进行排序。而这时就很有可能出现相等的账号(即同一账号在某段时间做多次的存取钱操作),它们的相对顺序意味着添加到容器的时间顺序,此顺序不能修改,否则很可能出现账户透支的情况。
值得一提的是,stable_sort() 函数完全可以看作是 sort() 函数在功能方面的升级版。换句话说,stable_sort() 和 sort() 具有相同的使用场景,就连语法格式也是相同的(后续会讲),只不过前者在功能上除了可以实现排序,还可以保证不改变相等元素的相对位置。
注意,关于 stable_sort() 函数的使用场景,《C++ sort() 排序函数》一节已经做了详细的介绍,这里不再赘述。另外,stable_sort() 函数是基于归并排序实现的,关于此排序算法的具体实现过程,感兴趣的读者可阅读《归并排序算法》一文。
和 sort() 函数一样,实现 stable_sort() 的函数模板也位于<algorithm>头文件中,因此在使用该函数前,程序也应包含如下语句:
#include <algorithm>
并且,table_sort() 函数的用法也有 2 种,其语法格式和 sort() 函数完全相同(仅函数名不同):
//对 [first, last) 区域内的元素做默认的升序排序
void stable_sort ( RandomAccessIterator first, RandomAccessIterator last );
//按照指定的 comp 排序规则,对 [first, last) 区域内的元素进行排序
void stable_sort ( RandomAccessIterator first, RandomAccessIterator last, Compare comp );
其中,first 和 last 都为随机访问迭代器,它们的组合 [first, last) 用来指定要排序的目标区域;另外在第 2 种格式中,comp 可以是 C++ STL 标准库提供的排序规则(比如 std::greater),也可以是自定义的排序规则。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::stable_sort
#include <vector> // std::vector
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector<int> myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用第一种语法格式,对 32、71、12、45 进行排序
std::stable_sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater<T>)进行排序
std::stable_sort(myvector.begin(), myvector.begin() + 4, std::greater<int>()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序,这里也可以换成 mycomp2()
std::stable_sort(myvector.begin(), myvector.end(), mycomp);//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
return 0;
}
程序执行结果为:
12 26 32 33 45 53 71 80
那么,stable_sort() 函数的效率怎么样呢?当可用空间足够的情况下,该函数的时间复杂度可达到O(N*log2(N));反之,时间复杂度为O(N*log2(N)2),其中 N 为指定区域 [first, last) 中 last 和 first 的距离。
C++ partial_sort()函数详解
假设这样一种情境,有一个存有 100 万个元素的容器,但我们只想从中提取出值最小的 10 个元素,该如何实现呢?
通过前面的学习,读者可能会想到使用 sort() 或者 stable_sort() 排序函数,即通过对容器中存储的 100 万个元素进行排序,就可以成功筛选出最小的 10 个元素。但仅仅为了提取 10 个元素,却要先对 100 万个元素进行排序,可想而知这种实现方式的效率是非常低的。
对于解决类似的问题,C++ STL 标准库提供了更高效的解决方案,即使用 partial_sort() 或者 partial_sort_copy() 函数,本节就对这 2 个排序函数的功能和用法做详细的讲解。
首先需要说明的是,partial_sort() 和 partial_sort_copy() 函数都位于 头文件中,因此在使用这 2 个函数之前,程序中应引入此头文件:
#include <algorithm>
C++ partial_sort()排序函数
要知道,一个函数的功能往往可以从它的函数名中体现出来,以 partial_sort() 函数为例,partial sort 可直译为“部分排序”。partial_sort() 函数的功能确是如此,即该函数可以从指定区域中提取出部分数据,并对它们进行排序。
但“部分排序”仅仅是对 partial_sort() 函数功能的一个概括,如果想彻底搞清楚它的功能,需要结合该函数的语法格式。partial_sort() 函数有 2 种用法,其语法格式分别为:
//按照默认的升序排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
//按照 comp 排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last,
Compare comp);
其中,first、middle 和 last 都是随机访问迭代器,comp 参数用于自定义排序规则。
partial_sort() 函数会以交换元素存储位置的方式实现部分排序的。具体来说,partial_sort() 会将 [first, last) 范围内最小(或最大)的 middle-first 个元素移动到 [first, middle) 区域中,并对这部分元素做升序(或降序)排序。
需要注意的是,partial_sort() 函数受到底层实现方式的限制,它仅适用于普通数组和部分类型的容器。换句话说,只有普通数组和具备以下条件的容器,才能使用 partial_sort() 函数:
- 容器支持的迭代器类型必须为随机访问迭代器。这意味着,partial_sort() 函数只适用于 array、vector、deque 这 3 个容器。
- 当选用默认的升序排序规则时,容器中存储的元素类型必须支持 <小于运算符;同样,如果选用标准库提供的其它排序规则,元素类型也必须支持该规则底层实现所用的比较运算符;
- partial_sort() 函数在实现过程中,需要交换某些元素的存储位置。因此,如果容器中存储的是自定义的类对象,则该类的内部必须提供移动构造函数和移动赋值运算符。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::partial_sort
#include <vector> // std::vector
using namespace std;
//以普通函数的方式自定义排序规则
bool mycomp1(int i, int j) {
return (i > j);
}
//以函数对象的方式自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
std::vector<int> myvector{ 3,2,5,4,1,6,9,7};
//以默认的升序排序作为排序规则,将 myvector 中最小的 4 个元素移动到开头位置并排好序
std::partial_sort(myvector.begin(), myvector.begin() + 4, myvector.end());
cout << "第一次排序:\n";
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it)
std::cout << *it << ' ';
cout << "\n第二次排序:\n";
// 以指定的 mycomp2 作为排序规则,将 myvector 中最大的 4 个元素移动到开头位置并排好序
std::partial_sort(myvector.begin(), myvector.begin() + 4, myvector.end(), mycomp2());
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it)
std::cout << *it << ' ';
return 0;
}
程序执行结果为:
第一次排序:
1 2 3 4 5 6 9 7
第二次排序:
9 7 6 5 1 2 3 4
值得一提的是,partial_sort() 函数实现排序的平均时间复杂度为N*log(M),其中 N 指的是 [first, last) 范围的长度,M 指的是 [first, middle) 范围的长度。
C++ partial_sort_copy()排序函数
partial_sort_copy() 函数的功能和 partial_sort() 类似,唯一的区别在于,前者不会对原有数据做任何变动,而是先将选定的部分元素拷贝到另外指定的数组或容器中,然后再对这部分元素进行排序。
partial_sort_copy() 函数也有 2 种语法格式,分别为:
//默认以升序规则进行部分排序
RandomAccessIterator partial_sort_copy (
InputIterator first,
InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last);
//以 comp 规则进行部分排序
RandomAccessIterator partial_sort_copy (
InputIterator first,
InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last,
Compare comp);
其中,first 和 last 为输入迭代器;result_first 和 result_last 为随机访问迭代器;comp 用于自定义排序规则。
partial_sort_copy() 函数会将 [first, last) 范围内最小(或最大)的 result_last-result_first 个元素复制到 [result_first, result_last) 区域中,并对该区域的元素做升序(或降序)排序。
值得一提的是,[first, last] 中的这 2 个迭代器类型仅限定为输入迭代器,这意味着相比 partial_sort() 函数,partial_sort_copy() 函数放宽了对存储原有数据的容器类型的限制。换句话说,partial_sort_copy() 函数还支持对 list 容器或者 forward_list 容器中存储的元素进行“部分排序”,而 partial_sort() 函数不行。
但是,介于 result_first 和 result_last 仍为随机访问迭代器,因此 [result_first, result_last) 指定的区域仍仅限于普通数组和部分类型的容器,这和 partial_sort() 函数对容器的要求是一样的。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::partial_sort_copy
#include <list> // std::list
using namespace std;
bool mycomp1(int i, int j) {
return (i > j);
}
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
int myints[5] = { 0 };
std::list<int> mylist{ 3,2,5,4,1,6,9,7 };
//按照默认的排序规则进行部分排序
std::partial_sort_copy(mylist.begin(), mylist.end(), myints, myints + 5);
cout << "第一次排序:\n";
for (int i = 0; i < 5; i++) {
cout << myints[i] << " ";
}
//以自定义的 mycomp2 作为排序规则,进行部分排序
std::partial_sort_copy(mylist.begin(), mylist.end(), myints, myints + 5, mycomp2());
cout << "\n第二次排序:\n";
for (int i = 0; i < 5; i++) {
cout << myints[i] << " ";
}
return 0;
}
程序执行结果为:
第一次排序:
1 2 3 4 5
第二次排序:
9 7 6 5 4
可以看到,程序中调用了 2 次 partial_sort_copy() 函数,其作用分别是:
- 第 20 行:采用默认的升序排序规则,在 mylist 容器中筛选出最小的 5 个元素,然后将它们复制到 myints[5] 数组中,并对这部分元素进行升序排序;
- 第 27 行:采用自定义的 mycomp2 降序排序规则,从 mylist 容器筛选出最大的 5 个元素,同样将它们复制到 myints[5] 数组中,并对这部分元素进行降序排序;
值得一提的是,partial_sort_copy() 函数实现排序的平均时间复杂度为N*log(min(N,M)),其中 N 指的是 [first, last) 范围的长度,M 指的是 [result_first, result_last) 范围的长度。
C++ nth_element()用法详解
前面章节中,已经给大家介绍了 sort()、stable_sort()、partial_sort() 这些函数的功能和用法,本节再介绍一个排序函数,即 nth_element() 函数。
不过,在系统讲解 nth_element() 函数之前,我们先形成一个共识,即在有序序列中,我们可以称第 n 个元素为整个序列中“第 n 大”的元素。比如,下面是一个升序序列:
2 4 6 8 10
在这个序列中,我们可以称元素 6 为整个序列中“第 3 小”的元素,并位于第 3 的位置处;同样,元素 8 为整个序列中“第 4 小”的元素,并位于第 4 的位置处。
简单的理解 nth_element() 函数的功能,当采用默认的升序排序规则(std::less)时,该函数可以从某个序列中找到第 n 小的元素 K,并将 K 移动到序列中第 n 的位置处。不仅如此,整个序列经过 nth_element() 函数处理后,所有位于 K 之前的元素都比 K 小,所有位于 K 之后的元素都比 K 大。
当然,我们也可以将 nth_element() 函数的排序规则自定义为降序排序,此时该函数会找到第 n 大的元素 K 并将其移动到第 n 的位置处,同时所有位于 K 之前的元素都比 K 大,所有位于 K 之后的元素都比 K 小。
以下面这个序列为例:
3 4 1 2 5
假设按照升序排序,并通过 nth_element() 函数查找此序列中第 3 小的元素,则最终得到的序列可能为:
2 1 3 4 5
显然,nth_element() 函数找到了第 3 小的元素 3 并将其位于第 3 的位置,同时元素 3 之前的所有元素都比该元素小,元素 3 之后的所有元素都比该元素大。
要知道,nth_element() 本质也是一个函数模板,定义在<algorithm>头文件中。因此,如果程序中想使用该函数,就需要提前引入这个头文件:
#include <algorithm>
nth_element() 函数有以下 2 种语法格式:
//排序规则采用默认的升序排序
void nth_element (RandomAccessIterator first,
RandomAccessIterator nth,
RandomAccessIterator last);
//排序规则为自定义的 comp 排序规则
void nth_element (RandomAccessIterator first,
RandomAccessIterator nth,
RandomAccessIterator last,
Compare comp);
其中,各个参数的含义如下:
- first 和 last:都是随机访问迭代器,[first, last) 用于指定该函数的作用范围(即要处理哪些数据);
- nth:也是随机访问迭代器,其功能是令函数查找“第 nth 大”的元素,并将其移动到 nth 指向的位置;
- comp:用于自定义排序规则。
注意,鉴于 nth_element() 函数中各个参数的类型,其只能对普通数组或者部分容器进行排序。换句话说,只有普通数组和符合以下全部条件的容器,才能使用使用 nth_element() 函数:
- 容器支持的迭代器类型必须为随机访问迭代器。这意味着,nth_element() 函数只适用于 array、vector、deque 这 3 个容器。
- 当选用默认的升序排序规则时,容器中存储的元素类型必须支持 <小于运算符;同样,如果选用标准库提供的其它排序规则,元素类型也必须支持该规则底层实现所用的比较运算符;
- nth_element() 函数在实现过程中,需要交换某些元素的存储位置。因此,如果容器中存储的是自定义的类对象,则该类的内部必须提供移动构造函数和移动赋值运算符。
举个例子:
#include <iostream>
#include <algorithm> // std::nth_element
#include <vector> // std::vector
using namespace std;
//以普通函数的方式自定义排序规则
bool mycomp1(int i, int j) {
return (i > j);
}
//以函数对象的方式自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
std::vector<int> myvector{3,1,2,5,4};
//默认的升序排序作为排序规则
std::nth_element(myvector.begin(), myvector.begin()+2, myvector.end());
cout << "第一次nth_element排序:\n";
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
//自定义的 mycomp2() 或者 mycomp1 降序排序作为排序规则
std::nth_element(myvector.begin(), myvector.begin() + 3, myvector.end(),mycomp1);
cout << "\n第二次nth_element排序:\n";
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
return 0;
}
程序执行结果可能为(不唯一):
第一次nth_element排序:
1 2 3 4 5
第二次nth_element排序:
5 4 3 2 1
上面程序中,共调用了 2 次 nth_elelment() 函数:
- 第 20 行:nth_element() 函数采用的是默认的升序排序,nth 参数设置为 myvector.begin()+2,即指向的是 myvector 容器中第 3 个元素所在的位置。因此,nth_element() 函数会查找“第 3 小”的元素 3,并将其移动到 nth 指向的位置,同时使 nth 之前的所有元素都比 3 小,使 nth 之后的所有元素都比 3 大。
- 第 26 行:nth_element() 函数采用的是默认的降序排序,nth 参数设置为 myvector.begin()+3,即指向的是 myvector 容器中第 4 个元素所在的位置。因此,nth_element() 函数会查找“第 4 大”的元素 2,并将其移动到 nth 指向的位置,同时使 nth 之前的所有元素都比 2 大,使 nth 之后的所有元素都比 2 小。
C++ is_sorted()函数完全攻略
我们知道,排序操作是比较耗费时间的,尤其当数据量很大的时候。因此在设计程序时,我们应该有意识的去避免执行一些不必要的排序操作。
那么,何谓不必要的排序操作呢?举个例子,有这样一组数据:
1 2 3 4 5
这本就是一组有序的数据,如果我们恰巧需要这样的升序序列,就没有必要再执行排序操作。
因此,当程序中涉及排序操作时,我们应该为其包裹一层判断语句,像如下这样:
//...
if(不是有序序列){
//执行排序算法
}
//...
注意这里的“不是有序序列”,即只要该序列不符合我们指定的排序规则,就不是有序序列。
那么,怎样才能判断一个序列是否为有序序列呢?很简单,使用 is_sorted() 函数即可,此函数专门用于判断某个序列是否为有序序列。
C++ is_sorted()函数
和之前学习的其它排序函数(比如 sorted() 函数)一样,is_sorted() 函数本质上就是一个函数模板,定义在<algorithm>头文件中。因为,在使用该函数之前,程序中必须先引入此头文件:
#include <algorithm>
is_sorted() 函数有 2 种语法格式,分别是:
//判断 [first, last) 区域内的数据是否符合 std::less<T> 排序规则,即是否为升序序列
bool is_sorted (ForwardIterator first, ForwardIterator last);
//判断 [first, last) 区域内的数据是否符合 comp 排序规则
bool is_sorted (ForwardIterator first, ForwardIterator last, Compare comp);
其中,first 和 last 都为正向迭代器(这意味着该函数适用于大部分容器),[first, last) 用于指定要检测的序列;comp 用于指定自定义的排序规则。
注意,如果使用默认的升序排序规则,则 [first, last) 指定区域内的元素必须支持使用 < 小于运算符做比较;同样,如果指定排序规则为 comp,也要保证 [first, last) 区域内的元素支持该规则内部使用的比较运算符。
另外,该函数会返回一个 bool 类型值,即如果 [first, last) 范围内的序列符合我们指定的排序规则,则返回 true;反之,函数返回 false。值得一提得是,如果 [first, last) 指定范围内只有 1 个元素,则该函数始终返回 true。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::is_sorted
#include <vector> // std::array
#include <list> // std::list
using namespace std;
//以普通函数的方式自定义排序规则
bool mycomp1(int i, int j) {
return (i > j);
}
//以函数对象的方式自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
vector<int> myvector{ 3,1,2,4 };
list<int> mylist{ 1,2,3,4 };
//调用第 2 种语法格式的 is_sorted() 函数,该判断语句会得到执行
if (!is_sorted(myvector.begin(), myvector.end(),mycomp2())) {
cout << "开始对 myvector 容器排序" << endl;
//对 myvector 容器做降序排序
sort(myvector.begin(), myvector.end(),mycomp2());
//输出 myvector 容器中的元素
for (auto it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << " ";
}
}
//调用第一种语法格式的 is_sorted() 函数,该判断语句得不到执行
if (!is_sorted(mylist.begin(), mylist.end())) {
cout << "开始对 mylist 排序" << endl;
//......
}
return 0;
}
程序执行结果为:
开始对 myvector 容器排序
4 3 2 1
结合输出结果可以看到,虽然 myvector 容器中的数据为降序序列,但我们需要的是升序序列。因此第 22 行代码中 is_sorted() 函数的返回值为 false,而 !false 即 true,所以此 if 判断语句会得到执行。
同样在 33 行代码中,mylist 容器中存储的数据为升序序列,和 is_sorted() 函数的要求相符,因此该函数的返回值为 true,而 !true 即 false,所以此 if 判断语句将无法得到执行。
C++标准库官方网站给出了 is_sorted() 函数底层实现的等效代码,感兴趣的读者可自行前往查看。
C++ is_sorted_until()函数
和 is_sorted() 函数相比,is_sorted_until() 函数不仅能检测出某个序列是否有序,还会返回一个正向迭代器,该迭代器指向的是当前序列中第一个破坏有序状态的元素。
is_sorted_until() 函数的定义也位于<algorithm>头文件中。因为,在使用该函数之前,程序中必须先引入此头文件:
#include <algorithm>
is_sorted_until() 函数有以下 2 种语法格式:
//排序规则为默认的升序排序
ForwardIterator is_sorted_until (ForwardIterator first, ForwardIterator last);
//排序规则是自定义的 comp 规则
ForwardIterator is_sorted_until (ForwardIterator first,
ForwardIterator last,
Compare comp);
其中,first 和 last 都为正向迭代器(这意味着该函数适用于大部分容器),[first, last) 用于指定要检测的序列;comp 用于指定自定义的排序规则。
注意,如果使用默认的升序排序规则,则 [first, last) 指定区域内的元素必须支持使用 < 小于运算符做比较;同样,如果指定排序规则为 comp,也要保证 [first, last) 区域内的元素支持该规则内部使用的比较运算符。
可以看到,该函数会返回一个正向迭代器。对于第一种语法格式来说,该函数返回的是指向序列中第一个破坏升序规则的元素;对于第二种语法格式来说,该函数返回的是指向序列中第一个破坏 comp 排序规则的元素。注意,如果 [first, last) 指定的序列完全满足默认排序规则或者 comp 排序规则的要求,则该函数将返回一个和 last 迭代器指向相同的正向迭代器。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::is_sorted_until
#include <vector> // std::array
#include <list> // std::list
using namespace std;
//以普通函数的方式自定义排序规则
bool mycomp1(int i, int j) {
return (i > j);
}
//以函数对象的方式自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
vector<int> myvector{ 3,1,2,4 };
list<int> mylist{ 1,2,3,4 };
//如果返回值为 myvector.end(),则表明 myvector 容器中的序列符合 mycomp2() 规则
if (is_sorted_until(myvector.begin(), myvector.end(),mycomp2()) != myvector.end()) {
cout << "开始对 myvector 容器排序" << endl;
//对 myvector 容器做降序排序
sort(myvector.begin(), myvector.end(),mycomp2());
//输出 myvector 容器中的元素
for (auto it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << " ";
}
}
//该判断语句得不到执行
if (is_sorted_until(mylist.begin(), mylist.end()) != mylist.end()) {
cout << "开始对 mylist 排序" << endl;
//......
}
return 0;
}
程序执行结果为:
开始对 myvector 容器排序
4 3 2 1
C++ STL标准库这么多排序函数,该如何选择?
通过前面的学习我们知道,C++ STL 标准库共提供了 4 种排序函数,这里先带大家回顾一下,如表 1 所示。
表 1 C++ STL排序函数
| 排序函数 | 功能 |
|---|---|
| sort() | 对指定范围内所有的数据进行排序,排序后各个元素的相对位置很可能发生改变。 |
| stable_sort() | 对指定范围内所有的数据进行排序,并确保排序后各个元素的相对位置不发生改变。 |
| partial_sort() | 对指定范围内最大或最小的 n 个元素进行排序。 |
| nth_element() | 调整指定范围内元素的存储位置,实现位于位置 n 的元素正好是全排序情况下的第 n 个元素,并且按照全排序规则排在位置 n 之前的元素都在该位置之前,按照全排序规则排在位置 n 之后的元素都在该位置之后。 |
关于以上 4 种排序函数各自的用法,读者可阅读之前的文章,这里不再过多赘述。
值得一提的是,以上 4 种排序函数在使用时,都要求传入随机访问迭代器,因此这些函数都只适用于 array、vector、deque 以及普通数组。
当操作对象为 list 或者 forward_list 序列式容器时,其容器模板类中都提供有 sort() 排序方法,借助此方法即可实现对容器内部元素进行排序。其次,对关联式容器(包括哈希容器)进行排序是没有实际意义的,因为这类容器会根据既定的比较函数(和哈希函数)维护内部元素的存储位置。
那么,当需要对普通数组或者 array、vector 或者 deque 容器中的元素进行排序时,怎样选择最合适(效率最高)的排序函数呢?这里为大家总结了以下几点:
- 如果需要对所有元素进行排序,则选择 sort() 或者 stable_sort() 函数;
- 如果需要保持排序后各元素的相对位置不发生改变,就只能选择 stable_sort() 函数,而另外 3 个排序函数都无法保证这一点;
- 如果需要对最大(或最小)的 n 个元素进行排序,则优先选择 partial_sort() 函数;
- 如果只需要找到最大或最小的 n 个元素,但不要求对这 n 个元素进行排序,则优先选择 nth_element() 函数。
除此之外,很多读者都关心这些排序函数的性能。总的来说,函数功能越复杂,做的工作越多,它的性能就越低(主要体现在时间复杂度上)。对于以上 4 种排序函数,综合考虑它们的时间和空间效率,其性能之间的比较如下所示:
nth_element() > partial_sort() > sort() > stable_sort() <--从左到右,性能由高到低
建议大家,在实际选择排序函数时,应更多从所需要完成的功能这一角度去考虑,而不是一味地追求函数的性能。换句话说,如果你选择的算法更有利于实现所需要的功能,不仅会使整个代码的逻辑更加清晰,还会达到事半功倍的效果。
自定义STL算法规则,应优先使用函数对象!
作为一门面向对象的编程语言,使用 C++ 编写程序有一个缺点,即随着代码面向对象程度的提高,其执行效率反而会降低。例如,经实验证明几乎在所有情况下,直接操作一个 double 类型变量的执行效率,要比操作一个含 double 类型成员属性的类对象更高。
对于大多数读者来说,以上所说是很容易想通的,因为它符合我们对高级编程语言的认知。但本节要介绍的内容,一定程序上会打破这个认知。
前面章节中,我们学习了 STL 标准库中所有的排序算法,比如 sort()、stable_sort() 以及 nth_element() 等。不知读者有没有发现,这些排序算法都单独提供了带有 comp 参数的语法格式,借助此参数,我们可以自定义排序规则。
以 sort() 排序函数为例,其语法格式有以下 2 种:
//无 comp 参数
void sort (RandomAccessIterator first, RandomAccessIterator last);
//有 comp 参数
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
显然仅从使用语法上看,它们唯一的区别在于,第 2 种多了一个 comp 参数。
事实上,对于 STL 标准库中的每个算法,只要用户需要自定义规则,该算法都会提供有带 comp 参数的语法格式。
本质上讲,comp 参数用于接收用户自定义的函数,其定义的方式有 2 种,既可以是普通函数,也可以是函数对象。例如:
#include <iostream> // std::cout
#include <algorithm> // std::sort
#include <vector> // std::vector
//以普通函数的方式实现自定义排序规则
inline bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector<int> myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用普通函数定义的排序规则
std::sort(myvector.begin(), myvector.end(), mycomp);
//调用函数对象定义的排序规则
//std::sort(myvector.begin(), myvector.end(), mycomp2());
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
return 0;
}
程序执行结果为:
12 26 32 33 45 53 71 80
注意,为了提高执行效率,其函数都定义为内联函数(在类内部定义的函数本身就是内联函数)。至于为什么内联函数比普通函数的执行效率高,可阅读《C++ inline内联函数》一文。
要知道,函数对象可以理解为伪装成函数的对象,根据以往的认知,函数对象的执行效率应该不如普通函数。但事实恰恰相反,即便如上面程序那样,将普通函数定义为更高效的内联函数,其执行效率也无法和函数对象相比。
通过在 4 个不同的 STL 平台上,对包含 100 万个 double 类型数据的 vector 容器进行排序,最差情况下使用函数对象的执行效率要比普通内联函数高 50%,最好情况下则高 160%。
那么,是什么原因导致了它们执行效率上的差异呢?以 mycomp2() 函数对象为例,其 mycomp2::operator() 也是一个内联函数,编译器在对 sort() 函数进行实例化时会将该函数直接展开,这也就意味着,展开后的 sort() 函数内部不包含任何函数调用。
而如果使用 mycomp 作为参数来调用 sort() 函数,情形则大不相同。要知道,C++ 并不能真正地将一个函数作为参数传递给另一个函数,换句话说,如果我们试图将一个函数作为参数进行传递,编译器会隐式地将它转换成一个指向该函数的指针,并将该指针传递过去。
也就是说,上面程序中的如下代码:
std::sort(myvector.begin(), myvector.end(), mycomp);
并不是真正地将 mycomp 传递给 sort() 函数,它传递的仅是一个指向 mycomp() 函数的指针。当 sort() 函数被实例化时,编译器生成的函数声明如下所示:
std::sort(vector<int>::iterator first,
vector<int>::iterator last,
bool (*comp)(int, int));
可以看到,参数 comp 只是一个指向函数的指针,所以 sort() 函数内部每次调用 comp 时,编译器都会通过指针产生一个间接的函数调用。
也正是基于这个原因,C++ sort() 函数要比 C 语言 qsort() 函数的执行效率更高。读者可能会问,程序中 comp() 函数也是内联函数,为什么 C++ 不像函数对象那样去处理呢?具体原因我们无从得知,事实上也没必要关心,也许是编译器开发者觉得这种优化不值得去做。
除了效率上的优势之外,相比普通函数,以函数对象的方式自定义规则还有很多隐藏的优势。例如在某些特殊情况下,以普通函数的形式编写的代码看似非常合理,但就是无法通过编译,这也许是由于 STL 标准库的原因,也许是编译器缺陷所至,甚至两者都有可能。而使用函数对象的方式,则可以有效避开这些“坑”,而且还大大提升的代码的执行效率。
总之,以函数对象的方式为 STL 算法自定义规则,具有效率在内的诸多优势。当调用带有 comp 参数的 STL 算法时,除非调用 STL 标准库自带的比较函数,否则应优先以函数对象的方式自定义规则。
C++ merge()和inplace_merge()函数用法(详解版)
有些场景中,我们需要将 2 个有序序列合并为 1 个有序序列,这时就可以借助 merge() 或者 inplace_merge() 函数实现。
值得一提的是,merge() 和 inplace_merge() 函数都定义在<algorithm>头文件中,因此在使用它们之前,程序中必须提前引入该头文件:
#include <algorithm>
C++ merge()函数
merge() 函数用于将 2 个有序序列合并为 1 个有序序列,前提是这 2 个有序序列的排序规则相同(要么都是升序,要么都是降序)。并且最终借助该函数获得的新有序序列,其排序规则也和这 2 个有序序列相同。
举个例子,假设有 2 个序列,分别为5,10,15,20,25和7,14,21,28,35,42,显然它们不仅有序,而且都是升序序列。因此借助 merge() 函数,我们就可以轻松获得如下这个有序序列:
5 7 10 15 17 20 25 27 37 47 57
可以看到,该序列不仅包含以上 2 个序列中所有的元素,并且其本身也是一个升序序列。
值得一提的是,C++ STL 标准库的开发人员考虑到用户可能需要自定义排序规则,因此为 merge() 函数设计了以下 2 种语法格式:
//以默认的升序排序作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
//以自定义的 comp 规则作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result, Compare comp);
可以看到,first1、last1、first2 以及 last2 都为输入迭代器,[first1, last1) 和 [first2, last2) 各用来指定一个有序序列;result 为输出迭代器,用于为最终生成的新有序序列指定存储位置;comp 用于自定义排序规则。同时,该函数会返回一个输出迭代器,其指向的是新有序序列中最后一个元素之后的位置。
注意,当采用第一种语法格式时,[first1, last1) 和 [first2, last2) 指定区域内的元素必须支持 < 小于运算符;同样当采用第二种语法格式时,[first1, last1) 和 [first2, last2) 指定区域内的元素必须支持 comp 排序规则内的比较运算符。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::merge
#include <vector> // std::vector
using namespace std;
int main() {
//first 和 second 数组中各存有 1 个有序序列
int first[] = { 5,10,15,20,25 };
int second[] = { 7,17,27,37,47,57 };
//用于存储新的有序序列
vector<int> myvector(11);
//将 [first,first+5) 和 [second,second+6) 合并为 1 个有序序列,并存储到 myvector 容器中。
merge(first, first + 5, second, second + 6, myvector.begin());
//输出 myvector 容器中存储的元素
for (vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << ' ';
}
return 0;
}
程序执行结果为:
5 7 10 15 17 20 25 27 37 47 57
可以看到,first 数组和 second 数组中各存有 1 个升序序列,通过借助 merge() 函数,我们成功地将它们合并成了一个有序序列,并存储到 myvector 容器中。
注意,merge() 函数底层是通过拷贝的方式实现合并操作的。换句话说,上面程序在采用 merge() 函数实现合并操作的同时,并不会对 first 和 second 数组有任何影响。有关该函数的具体实现过程,可查看 C++ STL merge() 官网。
实际上,对于 2 个有序序列是各自存储(像 first 和 second 这样)还是存储到一起,merge() 函数并不关心,只需要给它传入恰当的迭代器(或指针),该函数就可以正常工作。因此,我们还可以将上面程序改写为:
//该数组中存储有 2 个有序序列
int first[] = { 5,10,15,20,25,7,17,27,37,47,57 };
//用于存储新的有序序列
vector<int> myvector(11);
//将 [first,first+5) 和 [first+5,first+11) 合并为 1 个有序序列,并存储到 myvector 容器中。
merge(first, first + 5, first + 5, first +11 , myvector.begin());
可以看到,2 个有序序列全部存储到了 first 数组中,但只要给 merge() 函数传入正确的指针,仍可以将它们合并为 1 个有序序列。
感兴趣的读者,可自行验证这段程序,其最终会得到和上面程序相同的 myvector 容器。
C++ inplace_merge()函数
事实上,当 2 个有序序列存储在同一个数组或容器中时,如果想将它们合并为 1 个有序序列,除了使用 merge() 函数,更推荐使用 inplace_merge() 函数。
和 merge() 函数相比,inplace_merge() 函数的语法格式要简单很多:
//默认采用升序的排序规则
void inplace_merge (BidirectionalIterator first, BidirectionalIterator middle,
BidirectionalIterator last);
//采用自定义的 comp 排序规则
void inplace_merge (BidirectionalIterator first, BidirectionalIterator middle,
BidirectionalIterator last, Compare comp);
其中,first、middle 和 last 都为双向迭代器,[first, middle) 和 [middle, last) 各表示一个有序序列。
和 merge() 函数一样,inplace_merge() 函数也要求 [first, middle) 和 [middle, last) 指定的这 2 个序列必须遵循相同的排序规则,且当采用第一种语法格式时,这 2 个序列中的元素必须支持 < 小于运算符;同样,当采用第二种语法格式时,这 2 个序列中的元素必须支持 comp 排序规则内部的比较运算符。不同之处在于,merge() 函数会将最终合并的有序序列存储在其它数组或容器中,而 inplace_merge() 函数则将最终合并的有序序列存储在 [first, last) 区域中。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::merge
using namespace std;
int main() {
//该数组中存储有 2 个有序序列
int first[] = { 5,10,15,20,25,7,17,27,37,47,57 };
//将 [first,first+5) 和 [first+5,first+11) 合并为 1 个有序序列。
inplace_merge(first, first + 5,first +11);
for (int i = 0; i < 11; i++) {
cout << first[i] << " ";
}
return 0;
}
程序执行结果为:
5 7 10 15 17 20 25 27 37 47 57
可以看到,first 数组中包含 2 个升序序列,借助 inplace_merge() 函数,实现了将这 2 个序列合并为 1 个升序序列,且新序列仍存储在 first 数组中。
C++ find()函数用法详解(超级详细)
find() 函数本质上是一个模板函数,用于在指定范围内查找和目标元素值相等的第一个元素。
如下为 find() 函数的语法格式:
InputIterator find (InputIterator first, InputIterator last, const T& val);
其中,first 和 last 为输入迭代器,[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素。
正因为 first 和 last 的类型为输入迭代器,因此该函数适用于所有的序列式容器。
另外,该函数会返回一个输入迭代器,当 find() 函数查找成功时,其指向的是在 [first, last) 区域内查找到的第一个目标元素;如果查找失败,则该迭代器的指向和 last 相同。
值得一提的是,find() 函数的底层实现,其实就是用==运算符将 val 和 [first, last) 区域内的元素逐个进行比对。这也就意味着,[first, last) 区域内的元素必须支持==运算符。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::find
#include <vector> // std::vector
using namespace std;
int main() {
//find() 函数作用于普通数组
char stl[] ="http://c.biancheng.net/stl/";
//调用 find() 查找第一个字符 'c'
char * p = find(stl, stl + strlen(stl), 'c');
//判断是否查找成功
if (p != stl + strlen(stl)) {
cout << p << endl;
}
//find() 函数作用于容器
std::vector<int> myvector{ 10,20,30,40,50 };
std::vector<int>::iterator it;
it = find(myvector.begin(), myvector.end(), 30);
if (it != myvector.end())
cout << "查找成功:" << *it;
else
cout << "查找失败";
return 0;
}
程序执行结果为:
c.biancheng.net/stl/
查找成功:30
可以看到,find() 函数除了可以作用于序列式容器,还可以作用于普通数组。
对于 find() 函数的底层实现,C++ 标准库中给出了参数代码,感兴趣的读者可自行研究:
template<class InputIterator, class T>
InputIterator find (InputIterator first, InputIterator last, const T& val)
{
while (first!=last) {
if (*first==val) return first;
++first;
}
return last;
}
能用STL算法,绝不自己实现!
前面章节已经介绍了很多算法函数,比如 find()、merge()、sort() 等。不知读者有没有发现,每个算法函数都至少要用一对迭代器来指明作用区间,并且为了实现自己的功能,每个函数内部都势必会对指定区域内的数据进行遍历操作。
举几个例子,find() 函数会对指定区域的数据逐个进行遍历,确认其是否为要查找的目标元素;merge() 函数内部也会分别对 2 个有序序列做逐个遍历,从而将它们合并为一个有序序列;sort() 函数在对指定区域内的元素进行排序时,其底层也会遍历每个元素。
事实上,虽然这些算法函数的内部实现我们不得而知,但无疑都会用到循环结构。可以这么说,STL 标准库中几乎所有的算法函数,其底层都是借助循环结构实现的。
在此基础上,由于 STL 标准库使用场景很广,因此很多需要手动编写循环结构实现的功能,用 STL 算法函数就能完成。举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::for_each
#include <string> // std::string
#include <vector> // std::vector
#include <functional>
using namespace std;
class Address {
public:
Address(string url) :url(url) {};
void display() {
cout << "url:" << this->url << endl;
}
private:
string url;
};
int main() {
vector<Address>adds{ Address("http://c.biancheng.net/stl/"),
Address("http://c.biancheng.net/java/"),
Address("http://c.biancheng.net/python/") };
//手动编写循环结构
cout << "first:\n";
for (auto it = adds.begin(); it != adds.end(); ++it) {
(*it).display();
}
//调用 STL 标准库中的算法函数
cout << "second:\n";
for_each(adds.begin(), adds.end(), mem_fun_ref(&Address::display));
return 0;
}
程序执行结果为:
first:
url:http://c.biancheng.net/stl/
url:http://c.biancheng.net/java/
url:http://c.biancheng.net/python/
second:
url:http://c.biancheng.net/stl/
url:http://c.biancheng.net/java/
url:http://c.biancheng.net/python/
可以看到,对于输出 adds 容器中存储的元素,除了可以手动编写循环结构实现,还可以使用 STL 标准库提供的 for_each() 函数。
那么,手动编写循环结构和调用 STL 算法函数相比,哪种实现方式更好呢?毫无疑问,直接调用算法会更好,理由有以下几个:
- 算法函数通常比自己写的循环结构效率更高;
- 自己写循环比使用算法函数更容易出错;
- 相比自己编写循环结构,直接调用算法函数的代码更加简洁明了。
- 使用算法函数编写的程序,可扩展性更强,更容易维护;
后面 3 个理由相信读者很容易理解,接下来重点讲一下“为什么算法函数的效率更高”。
为什么STL算法效率更高
仍以上面程序为例,如下是我们手动编写的循环代码:
for (auto it = adds.begin(); it != adds.end(); ++it) {
(*it).display();
}
此段代码中,每一次循环都要执行一次 end() 方法,事实上该方法并不需要多次调用,因为它的值自始至终都没有发生改变。也就是说,end() 方法只需要调用一次就够啦,for_each() 函数就对这一点进行了优化:
for_each(adds.begin(), adds.end(), mem_fun_ref(&Address::display));
可以看到,通过将 end() 方法作为参数传入 for_each() 函数,该方法只执行了 1 次。当然,这也仅是众多优化中的一处。事实上,STL 标准库的开发者对每个算法函数的底层实现代码都多了优化,使它们的执行效率达到最高。
有读者可能会说,难道我们自己对循环结构进行优化不行吗?可以,但是其执行效率仍无法和算法函数相提并论。
一方面,STL 开发者可以根据他们对容器底层的了解,对整个遍历过程进行优化,而这是我们难以做到的。以 deque 容器为例,该容器底层会将数据存储在多个大小固定的连续空间中。对于这些连续空间的遍历,只有 STL 开发者才知道这些连续空间的大小,才知道如何控制指针逐个遍历这些连续空间。
另一方面,某些 STL 函数的底层实现使用了复杂的科学计算方法,并不是普通 C++ 程序员能驾驭的。例如,在实现对某个序列进行排序时,我们很难编写出比 sort() 函数更高效的代码。
总之,STL 开发者比使用者更了解内部的实现细节,他们会充分利用这些知识来对算法进行优化。
当然,只有熟悉 STL 标准库提供的函数,才能在实际编程时想到使用它们。作为一个专业的 C++ 程序员,我们必须熟悉 STL 标准库中的每个算法函数,并清楚它们各自的功能。
C++ STL 标准库中包含 70 多个算法函数,如果考虑到函数的重载,大约有 100 多个不同的函数模板。本章仅介绍一些常用的算法函数,如果想了解全部的 STL 算法,读者可参考 C++ STL标准库官网。
STL算法和容器中的成员方法同名时,该如何选择?
通过前面的学习,我们已经掌握了一些 STL 算法的功能和用法。值得一提的是,STL 标准库提供有 70 多种算法函数,其中有些函数名称和 STL 容器模板类中提供的成员方法名相同。
例如,STL 标准库提供了 sort() 和 merge() 函数,而 list 容器模板类中也提供有同名的 sort() 和 merge() 成员方法。再比如,STL 标准库提供有 count()、find()、lower_bound()、upper_bound() 以及 equal_range() 这些函数,而每个关联式容器(除哈希容器外)也提供有相同名称的成员方法。
那么,当某个 STL 容器提供有和算法同名的成员方法时,应该使用哪一个呢?大多数情况下,我们应该使用 STL 容器提供的成员方法,而不是同名的 STL 算法,原因包括:
- 虽然同名,但它们的底层实现并不完全相同。相比同名的算法,容器的成员方法和自身结合地更加紧密。
- 相比同名的算法,STL 容器提供的成员方法往往执行效率更高;
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::find
#include <set> // std::set
#include <string> // std::string
using namespace std;
//为 set 容器自定义排序规则,即按照字符串长度进行排序
class mycomp {
public:
bool operator() (const string &i, const string &j) const {
return i.length() < j.length();
}
};
int main() {
//定义 set 容器,其排序规则为 mycomp
std::set<string,mycomp> myset{"123","1234","123456"};
//调用 set 容器成员方法
set<string>::iterator iter = myset.find(string("abcd"));
if (iter == myset.end()) {
cout << "查找失败" << endl;
}
else {
cout << *iter << endl;
}
//调用 find() 函数
auto iter2 = find(myset.begin(), myset.end(), string("abcd"));
if (iter2 == myset.end()) {
cout << "查找失败" << endl;
}
else {
cout << *iter << endl;
}
return 0;
}
程序执行结果为:
1234
查找失败
可以看到,程序中分别调用了 find() 函数和 set 容器自带的 find() 成员方法,都用于查找 “abcd” 这个字符串,但查找结果却不相同。其中,find() 成员方法成功找到了和 “abcd” 长度相同的 “1234”,但 find() 函数却查找失败。
之所以会这样,是因为 find() 成员方法和 find() 函数底层的实现机制不同。前者会依照 mycomp() 规则查找和 “abcd” 匹配的元素,而 find() 函数底层仅会依据 “==” 运算符查找 myset 容器中和 “abcd” 相等的元素,所以会查找失败。
不仅如此,无论是序列式容器还是关联式容器,成员方法的执行效率要高于同名的 STL 算法。仍以 find() 函数和 set 容器中的 find() 成员方法为例。要知道,find() 函数是通过“逐个比对”来实现查找的,它以线性时间运行;而由于 set 容器底层存储结构采用的是红黑树,所以 find() 成员方法以对数时间运行,而非线性时间。
换句话说,对于含有一百万个元素的 set 容器,如果使用 find() 成员方法查找目标元素,其最差情况下的比对次数也不会超过 40 次(平均只需要比对 20 次就可以查找成功);而使用同名的 find() 函数查找目标元素,最差情况下要比对一百万次(平均比对 50 万次才能查找成功)。
所谓“最差情况”,指的是当前 set 容器中未存储有目标元素。
并且需要注意的一点是,虽然有些容器提供的成员方法和某个 STL 算法同名,但该容器只能使用自带的成员方法,而不适用同名的 STL 算法。比如,sort() 函数根本不能应用到 list 容器上,因为该类型容器仅支持双向迭代器,而 sort() 函数的参数类型要求为随机访问迭代器;merge() 函数和 list 容器的 merge() 成员方法之间也存在行为上的不同,即 merge() 函数是不允许修改源数据的,而 list::merge() 成员方法就是对源数据做修改。
总之,当读者需要在 STL 算法与容器提供的同名成员方法之间做选择的时候,应优先考虑成员方法。几乎可以肯定地讲,成员方法的性能更优越,也更贴合当前要操作的容器。
C++ find_if()和find_if_not()函数用法详解
继《C++ find()函数》一节后,本节再讲解 2 个和 find() 功能类似的函数,分别为 find_if() 函数和 find_if_not() 函数。
值得一提的是,find_if() 和 find_if_not() 函数都定义在<algorithm>头文件中。因此在使用它们之前,程序中要先引入此头文件:
#include <algorithm>
C++ find_if()函数
和 find() 函数相同,find_if() 函数也用于在指定区域内执行查找操作。不同的是,前者需要明确指定要查找的元素的值,而后者则允许自定义查找规则。
所谓自定义查找规则,实际上指的是有一个形参且返回值类型为 bool 的函数。值得一提的是,该函数可以是一个普通函数(又称为一元谓词函数),比如:
bool mycomp(int i) {
return ((i%2)==1);
}
上面的 mycomp() 就是一个一元谓词函数,其可用来判断一个整数是奇数还是偶数。
如果读者想更深层次地了解 C++ 谓词函数,可阅读《C++谓词函数》一节。
也可以是一个函数对象,比如:
//以函数对象的形式定义一个 find_if() 函数的查找规则
class mycomp2 {
public:
bool operator()(const int& i) {
return ((i % 2) == 1);
}
};
此函数对象的功能和 mycomp() 函数一样。
确切地说,find_if() 函数会根据指定的查找规则,在指定区域内查找第一个符合该函数要求(使函数返回 true)的元素。
find_if() 函数的语法格式如下:
InputIterator find_if (InputIterator first, InputIterator last, UnaryPredicate pred);
其中,first 和 last 都为输入迭代器,其组合 [first, last) 用于指定要查找的区域;pred 用于自定义查找规则。
值得一提的是,由于 first 和 last 都为输入迭代器,意味着该函数适用于所有的序列式容器。甚至当采用适当的谓词函数时,该函数还适用于所有的关联式容器(包括哈希容器)。
同时,该函数会返回一个输入迭代器,当查找成功时,该迭代器指向的是第一个符合查找规则的元素;反之,如果 find_if() 函数查找失败,则该迭代器的指向和 last 迭代器相同。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::find_if
#include <vector> // std::vector
using namespace std;
//自定义一元谓词函数
bool mycomp(int i) {
return ((i % 2) == 1);
}
//以函数对象的形式定义一个 find_if() 函数的查找规则
class mycomp2 {
public:
bool operator()(const int& i) {
return ((i % 2) == 1);
}
};
int main() {
vector<int> myvector{ 4,2,3,1,5 };
//调用 find_if() 函数,并以 IsOdd() 一元谓词函数作为查找规则
vector<int>::iterator it = find_if(myvector.begin(), myvector.end(), mycomp2());
cout << "*it = " << *it;
return 0;
}
程序执行结果为:
*it = 3
结合程序执行结果不难看出,对于 myvector 容器中的元素 4 和 2 来说,它们都无法使 (i%2)==1 这个表达式成立,因此 mycomp2() 返回 false;而对于元素 3 来说,它可以使 mycomp2() 函数返回 true,因此,find_if() 函数找到的第一个元素就是元素 3。
值得一提的是,C++ STL find_if()官网给出了 find_if() 函数底层实现的参考代码(如下所示),感兴趣的读者可自行分析,这里不做过多描述:
template<class InputIterator, class UnaryPredicate>
InputIterator find_if (InputIterator first, InputIterator last, UnaryPredicate pred)
{
while (first!=last) {
if (pred(*first)) return first;
++first;
}
return last;
}
C++ find_if_not()函数
find_if_not() 函数和 find_if() 函数的功能恰好相反,通过上面的学习我们知道,find_if() 函数用于查找符合谓词函数规则的第一个元素,而 find_if_not() 函数则用于查找第一个不符合谓词函数规则的元素。
find_if_not() 函数的语法规则如下所示:
InputIterator find_if_not (InputIterator first, InputIterator last, UnaryPredicate pred);
其中,first 和 last 都为输入迭代器,[first, last) 用于指定查找范围;pred 用于自定义查找规则。
和 find_if() 函数一样,find_if_not() 函数也适用于所有的容器,包括所有序列式容器和关联式容器。
同样,该函数也会返回一个输入迭代器,当 find_if_not() 函数查找成功时,该迭代器指向的是查找到的那个元素;反之,如果查找失败,该迭代器的指向和 last 迭代器相同。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::find_if_not
#include <vector> // std::vector
using namespace std;
//自定义一元谓词函数
bool mycomp(int i) {
return ((i % 2) == 1);
}
int main() {
vector<int> myvector{4,2,3,1,5};
//调用 find_if() 函数,并以 mycomp() 一元谓词函数作为查找规则
vector<int>::iterator it = find_if_not(myvector.begin(), myvector.end(), mycomp);
cout << "*it = " << *it;
return 0;
}
程序执行结果为:
*it = 4
可以看到,由于第一个元素 4 就不符合 (i%2)==1,因此 find_if_not() 成功找到符合条件的元素,并返回一个指向该元素的迭代器。
find_if_not() 函数的底层实现和 find_if() 函数非常类似,C++ STL find_if_not()官网给出了该函数底层实现的参考代码,感兴趣的读者可自行分析,这里不做过多描述:
template<class InputIterator, class UnaryPredicate>
InputIterator find_if_not (InputIterator first, InputIterator last, UnaryPredicate pred)
{
while (first!=last) {
if (!pred(*first)) return first;
++first;
}
return last;
}
C++ find_end()函数详解
find_end() 函数定义在<algorithm>头文件中,常用于在序列 A 中查找序列 B 最后一次出现的位置。例如,有如下 2 个序列:
序列 A:1,2,3,4,5,1,2,3,4,5
序列 B:1,2,3
通过观察不难发现,序列 B 在序列 A 中出现了 2 次,而借助 find_end() 函数,可以轻松的得到序列 A 中最后一个(也就是第 2 个) {1,2,3}。
find_end() 函数的语法格式有 2 种:
//查找序列 [first1, last1) 中最后一个子序列 [first2, last2)
ForwardIterator find_end (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2);
//查找序列 [first2, last2) 中,和 [first2, last2) 序列满足 pred 规则的最后一个子序列
ForwardIterator find_end (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2,
BinaryPredicate pred);
其中,各个参数的含义如下:
- first1、last1:都为正向迭代器,其组合 [first1, last1) 用于指定查找范围(也就是上面例子中的序列 A);
- first2、last2:都为正向迭代器,其组合 [first2, last2) 用于指定要查找的序列(也就是上面例子中的序列 B);
- pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收 [first1, last1) 范围内的元素,第二个参数接收 [first2, last2) 范围内的元素)。函数定义的形式可以是普通函数,也可以是函数对象。
实际上,第一种语法格式也可以看做是包含一个默认的 pred 参数,该参数指定的是一种相等规则,即在 [first1, last1) 范围内查找和 [first2, last2) 中各个元素对应相等的子序列;而借助第二种语法格式,我们可以自定义一个当前场景需要的匹配规则。
同时,find_end() 函数会返回一个正向迭代器,当函数查找成功时,该迭代器指向查找到的子序列中的第一个元素;反之,如果查找失败,则该迭代器的指向和 last1 迭代器相同。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::find_end
#include <vector> // std::vector
using namespace std;
//以普通函数的形式定义一个匹配规则
bool mycomp1(int i, int j) {
return (i%j == 0);
}
//以函数对象的形式定义一个匹配规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return (i%j == 0);
}
};
int main() {
vector<int> myvector{ 1,2,3,4,8,12,18,1,2,3 };
int myarr[] = { 1,2,3 };
//调用第一种语法格式
vector<int>::iterator it = find_end(myvector.begin(), myvector.end(), myarr, myarr + 3);
if (it != myvector.end()) {
cout << "最后一个{1,2,3}的起始位置为:" << it - myvector.begin() << ",*it = " << *it << endl;
}
int myarr2[] = { 2,4,6 };
//调用第二种语法格式
it = find_end(myvector.begin(), myvector.end(), myarr2, myarr2 + 3, mycomp2());
if (it != myvector.end()) {
cout << "最后一个{2,3,4}的起始位置为:" << it - myvector.begin() << ",*it = " << *it;
}
return 0;
}
程序执行结果为:
匹配{1,2,3}的起始位置为:7,*it = 1
匹配{2,3,4}的起始位置为:4,*it = 8
上面程序中共调用了 2 次 find_end() 函数:
- 第 22 行代码:调用了第一种语法格式的 find_end() 函数,其功能是在 myvector 容器中查找和 {1,2,3} 相等的最后一个子序列,显然最后一个 {1,2,3} 中元素 1 的位置下标为 7(myvector 容器下标从 0 开始);
- 第 29 行代码:调用了第二种格式的 find_end() 函数,其匹配规则为 mycomp2,即在 myvector 容器中找到最后一个子序列,该序列中的元素能分别被 {2、4、6} 中的元素整除。显然,myvector 容器中 {4,8,12} 和 {8,12,18} 都符合,该函数会找到后者并返回一个指向元素 8 的迭代器。
注意,find_end() 函数的第一种语法格式,其底层是借助 == 运算符实现的。这意味着,如果 [first1, last1] 和 [first2, last2] 区域内的元素为自定义的类对象或结构体变量时,使用该函数之前需要对 == 运算符进行重载。
C++ STL标准库官方给出了 find_end() 函数底层实现的参考代码,感兴趣的读者可自行分析,这里不再做过多描述:
template<class ForwardIterator1, class ForwardIterator2>
ForwardIterator1 find_end(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2)
{
if (first2 == last2) return last1; // specified in C++11
ForwardIterator1 ret = last1;
while (first1 != last1)
{
ForwardIterator1 it1 = first1;
ForwardIterator2 it2 = first2;
while (*it1 == *it2) { // or: while (pred(*it1,*it2)) for version (2)
++it1; ++it2;
if (it2 == last2) { ret = first1; break; }
if (it1 == last1) return ret;
}
++first1;
}
return ret;
}
另外,C++ STL 标准库还提供了和 find_end() 函数功能恰恰相反的 search() 函数,有关该函数的用法,可阅读《C++ search() 函数》一节。
C++ find_first_of()函数完全攻略
在某些情境中,我们可能需要在 A 序列中查找和 B 序列中任意元素相匹配的第一个元素,这时就可以使用 find_first_of() 函数。
仅仅用一句话概述 find_first_of() 函数的功能,读者可能并不理解。别急,下面我们将从语法格式的角度继续阐述该函数的功能。
find_first_of() 函数定义于<algorithm>头文件中,因此使用该函数之前,程序中要先引入此头文件:
#include <algorithm>
find_first_of() 函数有 2 种语法格式,分别是:
//以判断两者相等作为匹配规则
InputIterator find_first_of (InputIterator first1, InputIterator last1,
ForwardIterator first2, ForwardIterator last2);
//以 pred 作为匹配规则
InputIterator find_first_of (InputIterator first1, InputIterator last1,
ForwardIterator first2, ForwardIterator last2,
BinaryPredicate pred);
其中,各个参数的含义如下:
- first1、last1:都为输入迭代器,它们的组合 [first1, last1) 用于指定该函数要查找的范围;
- first2、last2:都为正向迭代器,它们的组合 [first2, last2) 用于指定要进行匹配的元素所在的范围;
- pred:可接收一个包含 2 个形参且返回值类型为 bool 的函数,该函数可以是普通函数(又称为二元谓词函数),也可以是函数对象。
有关谓词函数,读者可阅读《C++谓词函数》一节详细了解。
find_first_of() 函数用于在 [first1, last1) 范围内查找和 [first2, last2) 中任何元素相匹配的第一个元素。如果匹配成功,该函数会返回一个指向该元素的输入迭代器;反之,则返回一个和 last1 迭代器指向相同的输入迭代器。
值得一提的是,不同语法格式的匹配规则也是不同的:
- 第 1 种语法格式:逐个取 [first1, last1) 范围内的元素(假设为 A),和 [first2, last2) 中的每个元素(假设为 B)做 A==B 运算,如果成立则匹配成功;
- 第 2 种语法格式:逐个取 [first1, last1) 范围内的元素(假设为 A),和 [first2, last2) 中的每个元素(假设为 B)一起带入 pred(A, B) 谓词函数,如果函数返回 true 则匹配成功。
注意,当采用第一种语法格式时,如果 [first1, last1) 或者 [first2, last2) 范围内的元素类型为自定义的类对象或者结构体变量,此时应对 == 运算符进行重载,使其适用于当前场景。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::find_first_of
#include <vector> // std::vector
using namespace std;
//自定义二元谓词函数,作为 find_first_of() 函数的匹配规则
bool mycomp(int c1, int c2) {
return (c2 % c1 == 0);
}
//以函数对象的形式定义一个 find_first_of() 函数的匹配规则
class mycomp2 {
public:
bool operator()(const int& c1, const int& c2) {
return (c2 % c1 == 0);
}
};
int main() {
char url[] = "http://c.biancheng.net/stl/";
char ch[] = "stl";
//调用第一种语法格式,找到 url 中和 "stl" 任一字符相同的第一个字符
char *it = find_first_of(url, url + 27, ch, ch + 4);
if (it != url + 27) {
cout << "*it = " << *it << '\n';
}
vector<int> myvector{ 5,7,3,9 };
int inter[] = { 4,6,8 };
//调用第二种语法格式,找到 myvector 容器中和 3、5、7 任一元素有 c2%c1=0 关系的第一个元素
vector<int>::iterator iter = find_first_of(myvector.begin(), myvector.end(), inter, inter + 3, mycomp2());
if (iter != myvector.end()) {
cout << "*iter = " << *iter;
}
return 0;
}
程序执行结果为:
*it = t
*iter = 3
此程序给读者演示了 find_first_of() 函数 2 种语法格式的用法。其中第 20 行代码中 find_first_of() 函数发挥的功能是,在 url 字符数组中逐个查找和 ‘s’、‘t’、‘l’ 这 3 个字符相等的字符,显然 url 数组第 2 个字符 ‘t’ 就符合此规则。
在第 29 行代码中,find_first_of() 会逐个提取 myvector 容器中的每个元素(假设为 A),并尝试和 inter 数组中的每个元素(假设为 B)一起带入 mycomp2(A, B) 函数对象中。显然,当将 myvector 容器中的元素 3 和 inter 数组中的元素 6 带入该函数时,c2 % c1=0 表达式第一次成立。
C++ STL 标准库给出了 find_first_of() 函数底层实现的参考代码,感兴趣的读者可自行分析:
template<class InputIt, class ForwardIt, class BinaryPredicate>
InputIt find_first_of(InputIt first, InputIt last,
ForwardIt s_first, ForwardIt s_last,
BinaryPredicate p)
{
for (; first != last; ++first) {
for (ForwardIt it = s_first; it != s_last; ++it) {
//第二种语法格式换成 if (p(*first, *it))
if (p(*first, *it)) {
return first;
}
}
}
return last;
}
C++ adjacent_find()函数用法详解
adjacent_find() 函数用于在指定范围内查找 2 个连续相等的元素。该函数的语法格式为:
//查找 2 个连续相等的元素
ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last);
//查找 2 个连续满足 pred 规则的元素
ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last,
BinaryPredicate pred);
其中,first 和 last 都为正向迭代器,其组合 [first, last) 用于指定该函数的查找范围;pred 用于接收一个包含 2 个参数且返回值类型为 bool 的函数,以实现自定义查找规则。
值得一提的是,pred 参数接收的函数既可以定义为普通函数,也可以用函数对象的形式定义。有关谓词函数,读者可阅读《C++谓词函数》一节详细了解。
另外,该函数会返回一个正向迭代器,当函数查找成功时,该迭代器指向的是连续相等元素的第 1 个元素;而如果查找失败,该迭代器的指向和 last 迭代器相同。
值得一提的是,adjacent_find() 函数定义于<algorithm>头文件中,因此使用该函数之前,程序中要先引入此头文件:
#include <algorithm>
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::adjacent_find
#include <vector> // std::vector
using namespace std;
//以创建普通函数的形式定义一个查找规则
bool mycomp1(int i, int j) {
return (i == j);
}
//以函数对象的形式定义一个查找规则
class mycomp2{
public:
bool operator()(const int& _Left, const int& _Right){
return (_Left == _Right);
}
};
int main() {
std::vector<int> myvector{ 5,20,5,30,30,20,10,10,20 };
//调用第一种语法格式
std::vector<int>::iterator it = adjacent_find(myvector.begin(), myvector.end());
if (it != myvector.end()) {
cout << "one : " << *it << '\n';
}
//调用第二种格式,也可以使用 mycomp1
it = adjacent_find(++it, myvector.end(), mycomp2());
if (it != myvector.end()) {
cout << "two : " << *it;
}
return 0;
}
程序执行结果为:
one : 30
two : 10
可以看到,程序中调用了 2 次 adjacent_find() 函数:
- 第 19 行:使用该函数的第一种语法格式,查找整个 myvector 容器中首个连续 2 个相等的元素,显然最先找到的是 30;
- 第 25 行:使用该函数的第二种语法格式,查找 {30,20,10,10,20} 部分中是否有连续 2 个符合 mycomp2 规则的元素。不过,程序中自定义的 mycomp1 或 mycomp2 查找规则也是查找 2 个连续相等的元素,因此最先找到的是元素 10。
注意,对于第一种语法格式的 adjacent_find() 函数,其底层使用的是 == 运算符来判断连续 2 个元素是否相等。这意味着,如果指定区域内的元素类型为自定义的类对象或者结构体变量时,需要先对 == 运算符进行重载,然后才能使用此函数。
C++ STL标准库官方给出了 adjacent_find() 函数底层实现的参考代码,感兴趣的读者可自行分析,这里不再做过多描述:
template <class ForwardIterator>
ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last)
{
if (first != last)
{
ForwardIterator next=first; ++next;
while (next != last) {
if (*first == *next) // 或者 if (pred(*first,*next)), 对应第二种语法格式
return first;
++first; ++next;
}
}
return last;
}
C++ search()函数用法完全攻略
通过《C++ find_end()函数》一节的讲解我们知道,find_end() 函数用于在序列 A 中查找序列 B 最后一次出现的位置。那么,如果想知道序列 B 在序列 A 中第一次出现的位置,该如何实现呢?可以借助 search() 函数。
search() 函数定义在<algorithm>头文件中,其功能恰好和 find_end() 函数相反,用于在序列 A 中查找序列 B 第一次出现的位置。
例如,仍以如下两个序列为例:
序列 A:1,2,3,4,5,1,2,3,4,5
序列 B:1,2,3
可以看到,序列 B 在序列 A 中出现了 2 次。借助 find_end() 函数,我们可以找到序列 A 中最后一个(也就是第 2 个){1,2,3};而借助 search() 函数,我们可以找到序列 A 中第 1 个 {1,2,3}。
和 find_end() 相同,search() 函数也提供有以下 2 种语法格式:
//查找 [first1, last1) 范围内第一个 [first2, last2) 子序列
ForwardIterator search (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2);
//查找 [first1, last1) 范围内,和 [first2, last2) 序列满足 pred 规则的第一个子序列
ForwardIterator search (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2,
BinaryPredicate pred);
其中,各个参数的含义分别为:
- first1、last1:都为正向迭代器,其组合 [first1, last1) 用于指定查找范围(也就是上面例子中的序列 A);
- first2、last2:都为正向迭代器,其组合 [first2, last2) 用于指定要查找的序列(也就是上面例子中的序列 B);
- pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收 [first1, last1) 范围内的元素,第二个参数接收 [first2, last2) 范围内的元素)。函数定义的形式可以是普通函数,也可以是函数对象。
实际上,第一种语法格式也可以看做是包含一个默认的 pred 参数,该参数指定的是一种相等规则,即在 [first1, last1) 范围内查找和 [first2, last2) 中各个元素对应相等的子序列;而借助第二种语法格式,我们可以自定义一个当前场景需要的匹配规则。
同时,search() 函数会返回一个正向迭代器,当函数查找成功时,该迭代器指向查找到的子序列中的第一个元素;反之,如果查找失败,则该迭代器的指向和 last1 迭代器相同。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::search
#include <vector> // std::vector
using namespace std;
//以普通函数的形式定义一个匹配规则
bool mycomp1(int i, int j) {
return (i%j == 0);
}
//以函数对象的形式定义一个匹配规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return (i%j == 0);
}
};
int main() {
vector<int> myvector{ 1,2,3,4,8,12,18,1,2,3 };
int myarr[] = { 1,2,3 };
//调用第一种语法格式
vector<int>::iterator it = search(myvector.begin(), myvector.end(), myarr, myarr + 3);
if (it != myvector.end()) {
cout << "第一个{1,2,3}的起始位置为:" << it - myvector.begin() << ",*it = " << *it << endl;
}
int myarr2[] = { 2,4,6 };
//调用第二种语法格式
it = search(myvector.begin(), myvector.end(), myarr2, myarr2 + 3, mycomp2());
if (it != myvector.end()) {
cout << "第一个{2,3,4}的起始位置为:" << it - myvector.begin() << ",*it = " << *it;
}
return 0;
}
程序执行结果为:
第一个{1,2,3}的起始位置为:0,*it = 1
第一个{2,3,4}的起始位置为:3,*it = 4
通过程序的执行结果可以看到,第 22 行代码借助 search() 函数找到了 myvector 容器中第一个 {1,2,3},并返回了一个指向元素 1 的迭代器(其下标位置为 0)。
而在第 29 行中,search() 函数使用的是第 2 种格式,其自定义了 mycomp2 匹配规则,即在 myvector 容器中找到第一个连续的 3 个元素,它们能分别被 2、4、6 整除。显然,myvector 容器中符合要求的子序列有 2 个,分别为 {4,8,12} 和 {8,12,18},但 search() 函数只会查找到第一个,并返回指向元素 4 的迭代器(其下标为 3)。
注意,search() 函数的第一种语法格式,其底层是借助 == 运算符实现的。这意味着,如果 [first1, last1] 和 [first2, last2] 区域内的元素为自定义的类对象或结构体变量时,使用该函数之前需要对 == 运算符进行重载。
C++ STL标准库官方给出了 search() 函数底层实现的参考代码,感兴趣的读者可自行分析,这里不再做过多描述:
template<class ForwardIterator1, class ForwardIterator2>
ForwardIterator1 search(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2)
{
if (first2 == last2) return first1;
while (first1 != last1)
{
ForwardIterator1 it1 = first1;
ForwardIterator2 it2 = first2;
while (*it1 == *it2) { // 或者 while (pred(*it1,*it2)) 对应第二种语法格式
if (it2 == last2) return first1;
if (it1 == last1) return last1;
++it1; ++it2;
}
++first1;
}
return last1;
}
C++ search_n()函数用法(超级详细)
《C++ search()函数》一节中,已经详细介绍了 search() 函数的功能和用法。在此基础上,本节再介绍一个功能类似的函数,即 search_n() 函数。
和 search() 一样,search_n() 函数也定义在<algorithm>头文件中,用于在指定区域内查找第一个符合要求的子序列。不同之处在于,前者查找的子序列中可包含多个不同的元素,而后者查找的只能是包含多个相同元素的子序列。
关于 search() 函数和 search_n() 函数的区别,给大家举个例子,下面有 3 个序列:
序列 A:1,2,3,4,4,4,1,2,3,4,4,4
序列 B:1,2,3
序列 C:4,4,4
如果想查找序列 B 在序列 A 中第一次出现的位置,就只能使用 search() 函数;而如果想查找序列 C 在序列 A 中第一次出现的位置,既可以使用 search() 函数,也可以使用 search_n() 函数。
search_n() 函数的语法格式如下:
//在 [first, last] 中查找 count 个 val 第一次连续出现的位置
ForwardIterator search_n (ForwardIterator first, ForwardIterator last,
Size count, const T& val);
//在 [first, last] 中查找第一个序列,该序列和 count 个 val 满足 pred 匹配规则
ForwardIterator search_n ( ForwardIterator first, ForwardIterator last,
Size count, const T& val, BinaryPredicate pred );
其中,各个参数的含义分别为:
- first、last:都为正向迭代器,其组合 [first, last) 用于指定查找范围(也就是上面例子中的序列 A);
- count、val:指定要查找的元素个数和元素值,以上面的序列 B 为例,该序列实际上就是 3 个元素 4,其中 count 为 3,val 为 4;
- pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收[first, last) 范围内的元素,第二个参数接收 val)。函数定义的形式可以是普通函数,也可以是函数对象。
实际上,第一种语法格式也可以看做是包含一个默认的 pred 参数,该参数指定的是一种相等规则,即在 [first, last) 范围内查找和 count 个 val 相等的子序列;而借助第二种语法格式,我们可以自定义一个当前场景需要的匹配规则。
同时,search_n() 函数会返回一个正向迭代器,当函数查找成功时,该迭代器指向查找到的子序列中的第一个元素;反之,如果查找失败,则该迭代器的指向和 last 迭代器相同。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::search_n
#include <vector> // std::vector
using namespace std;
//以普通函数的形式定义一个匹配规则
bool mycomp1(int i, int j) {
return (i%j == 0);
}
//以函数对象的形式定义一个匹配规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return (i%j == 0);
}
};
int main() {
int a[] = { 1,2,3,4,4,4,1,2,3,4,4,4 };
//调用第一种语法格式,查找 myvector 容器中第一个 {4,4,4}
int * it = search_n(a, a+12, 3, 4);
if (it != a+12) {
cout << "one:" << it - a << ",*it = " << *it << endl;
}
vector<int> myvector{1,2,4,8,3,4,6,8};
//调用第二种语法格式,以自定义的 mycomp2 作为匹配规则,查找 myvector 容器中和 {16,16,16} 满足 mycomp2 规则的序列
vector<int>::iterator iter = search_n(myvector.begin(), myvector.end(), 3, 2, mycomp2());
if (iter != myvector.end()) {
cout << "two:" << iter - myvector.begin() << ",*iter = " << *iter;
}
return 0;
}
程序执行结果为:
one:3,*it = 4
two:1,*iter = 2
程序中先后调用了 2 种语法格式的 search_n() 函数,其中第 28 行代码中,search_n() 函数不再采用默认的相等匹配规则,而是采用了自定义了 mycomp2 匹配规则。这意味着,该函数会去 myvector 容器中查找一个子序列,该序列中的 3 个元素都满足和 2 有 (i%j == 0) 的关系。显然,myvector 容器中符合条件的子序列有 2 个,分别为 {2,4,8} 和 {4,6,8},但 search_n() 函数只会查找到 {2,4,8}。
注意,search_n() 函数的第一种语法格式,其底层是借助 == 运算符实现的。这意味着,如果 [first, last] 区域内的元素为自定义的类对象或结构体变量时,使用此格式的 search_n() 函数之前,需要对 == 运算符进行重载。
C++ STL标准库官方给出了 search_n() 函数底层实现的参考代码,感兴趣的读者可自行分析,这里不再做过多描述:
template<class ForwardIterator, class Size, class T>
ForwardIterator search_n (ForwardIterator first, ForwardIterator last,
Size count, const T& val)
{
ForwardIterator it, limit;
Size i;
limit=first; std::advance(limit,std::distance(first,last)-count);
while (first!=limit)
{
it = first; i=0;
while (*it==val) // 或者 while (pred(*it,val)),对应第二种格式
{ ++it; if (++i==count) return first; }
++first;
}
return last;
}
C++ partition()和stable_partition()函数详解
partition 可直译为“分组”,partition() 函数可根据用户自定义的筛选规则,重新排列指定区域内存储的数据,使其分为 2 组,第一组为符合筛选条件的数据,另一组为不符合筛选条件的数据。
举个例子,假设有一个数组 a[9],其存储数据如下:
1 2 3 4 5 6 7 8 9
在此基础上,如果设定筛选规则为 i%2=0(其中 i 即代指数组 a 中的各个元素),则借助 partition() 函数,a[9] 数组中存储数据的顺序可能变为:
1 9 3 7 5 6 4 8 2
其中 {1,9,3,7,5} 为第一组,{6,4,8,2} 为第二组。显然前者中的各个元素都符合筛选条件,而后者则都不符合。由此还可看出,partition() 函数只会根据筛选条件将数据进行分组,并不关心分组后各个元素具体的存储位置。
如果想在分组之后仍不改变各元素之间的相对位置,可以选用 stable_partition() 函数。有关此函数的功能和用法,本节后续会做详细讲解。
值得一提得是,partition() 函数定义于<algorithm>头文件中,因此在使用该函数之前,程序中应先引入此头文件:
#include <algorithm>
如下为 partition() 函数的语法格式:
ForwardIterator partition (ForwardIterator first,
ForwardIterator last,
UnaryPredicate pred);
其中,first 和 last 都为正向迭代器,其组合 [first, last) 用于指定该函数的作用范围;pred 用于指定筛选规则。
所谓筛选规则,其本质就是一个可接收 1 个参数且返回值类型为 bool 的函数,可以是普通函数,也可以是一个函数对象。
同时,partition() 函数还会返回一个正向迭代器,其指向的是两部分数据的分界位置,更确切地说,指向的是第二组数据中的第 1 个元素。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::partition
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义partition()函数的筛选规则
bool mycomp(int i) { return (i % 2) == 0; }
//以函数对象的形式定义筛选规则
class mycomp2 {
public:
bool operator()(const int& i) {
return (i%2 == 0);
}
};
int main() {
std::vector<int> myvector{1,2,3,4,5,6,7,8,9};
std::vector<int>::iterator bound;
//以 mycomp2 规则,对 myvector 容器中的数据进行分组
bound = std::partition(myvector.begin(), myvector.end(), mycomp2());
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << " ";
}
cout << "\nbound = " << *bound;
return 0;
}
程序执行结果为:
8 2 6 4 5 3 7 1 9
bound = 5
可以看到,程序中借助 partition() 对 myvector 容器中的数据进行了再加工,基于 mycomp2() 筛选规则,能够被 2 整除的元素位于第 1 组,不能被 2 整除的元素位于第 2 组。
同时,parition() 函数会返回一个迭代器,通过观察程序的执行结果可以看到,该迭代器指向的是元素 5,同时也是第 2 组数据中的第 1 个元素。
值得一提的是,C++ STL partition()函数官方给出了该函数底层实现的参考代码,感兴趣的读者可自行前往分析,这里不再做过多描述。
C++ stable_partition()函数
前面提到,partition() 函数只负责对指定区域内的数据进行分组,并不保证各组中元素的相对位置不发生改变。而如果想在分组的同时保证不改变各组中元素的相对位置,可以使用 stable_partition() 函数。
也就是说,stable_partition() 函数可以保证对指定区域内数据完成分组的同时,不改变各组内元素的相对位置。
仍以数组 a[9] 举例,其存储的数据如下:
1 2 3 4 5 6 7 8 9
假定筛选规则为 i%2=0(其中 i 即代指数组 a 中的各个元素),则借助 stable_partition() 函数,a[9] 数组中存储数据的顺序为:
2 4 6 8 1 3 5 7 9
其中 {2,4,6,8} 为一组,{1,3,5,7,9} 为另一组。通过和先前的 a[9] 对比不难看出,各个组中元素的相对位置没有发生改变。
所谓元素的相对位置不发生改变,以 {2,4,6,8} 中的元素 4 为例,在原 a[9] 数组中,该元素位于 2 的右侧,6 和 8 的左侧;在经过 stable_partition() 函数处理后的 a[9] 数组中,元素 4 仍位于 2 的右侧,6 和 8 的左侧。因此,该元素的相对位置确实没有发生改变。
stable_partition() 函数定义在<algorithm>头文件中,其语法格式如下:
BidirectionalIterator stable_partition (BidirectionalIterator first,
BidirectionalIterator last,
UnaryPredicate pred);
其中,first 和 last 都为双向迭代器,其组合 [first, last) 用于指定该函数的作用范围;pred 用于指定筛选规则。
同时,stable_partition() 函数还会返回一个双向迭代器,其指向的是两部分数据的分界位置,更确切地说,指向的是第二组数据中的第 1 个元素。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::stable_partition
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义partition()函数的筛选规则
bool mycomp(int i) { return (i % 2) == 1; }
//以函数对象的形式定义筛选规则
class mycomp2 {
public:
bool operator()(const int& i) {
return (i%2 == 1);
}
};
int main() {
std::vector<int> myvector{1,2,3,4,5,6,7,8,9};
std::vector<int>::iterator bound;
//以 mycomp2 规则,对 myvector 容器中的数据进行分组
bound = std::stable_partition(myvector.begin(), myvector.end(), mycomp);
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << " ";
}
cout << "\nbound = " << *bound;
return 0;
}
程序执行结果为:
1 3 5 7 9 2 4 6 8
bound = 2
C++ partition_copy()函数详解
《C++ partition()和stable_partition()函数》一节中,已经详细介绍了 partition() 和 stable_partition() 函数的功能和用法。不知道读者是否发现,这 2 个函数在实现功能时,都直接修改了原序列中元素的存储位置。
而在某些场景中,我们需要类似 partition() 或者 stable_partition() 函数“分组”的功能,但并不想对原序列做任何修改。这种情况下,就可以考虑使用 partition_copy() 函数。
和 stable_partition() 一样,partition_copy() 函数也能按照某个筛选规则对指定区域内的数据进行“分组”,并且分组后不会改变各个元素的相对位置。更重要的是,partition_copy() 函数不会对原序列做修改,而是以复制的方式将序列中各个元组“分组”到其它的指定位置存储。
举个例子,有如下一个数组 a[10]:
1 2 3 4 5 6 7 8 9
假设筛选条件为 i%2==0(也就是筛选出偶数),如果借助 stable_partition() 函数,则数组 a[10] 中元素的存储顺序会变成:
2 4 6 8 1 3 5 7 9
而如果选用同样的筛选规则,使用 partition_copy() 函数还需要为其配备 2 个存储空间(例如 b[10] 和 c[10]),其中 b[10] 用于存储符合筛选条件的偶数,而 c[10] 用于存储不符合筛选条件的奇数,也就是说,partition_copy() 函数执行的最终结果为:
a[10]: 1 2 3 4 5 6 7 8 9
b[10]: 2 4 6 8
c[10]: 1 3 5 7 9
注意,这里仅展示了 b[10] 和 c[10] 数组中存储的有效数据。
值得一提的是,partition_copy() 函数定义在<algorithm>头文件中,其语法格式如下:
pair<OutputIterator1,OutputIterator2> partition_copy (
InputIterator first, InputIterator last,
OutputIterator1 result_true, OutputIterator2 result_false,
UnaryPredicate pred);
其中,各个参数的含义为:
- first、last:都为输入迭代器,其组合 [first, last) 用于指定该函数处理的数据区域;
- result_true:为输出迭代器,其用于指定某个存储区域,以存储满足筛选条件的数据;
- result_false:为输出迭代器,其用于指定某个存储区域,以存储满足筛选条件的数据;
- pred:用于指定筛选规则,其本质就是接收一个具有 1 个参数且返回值类型为 bool 的函数。注意,该函数既可以是普通函数,还可以是一个函数对象。
除此之外,该函数还会返回一个 pair 类型值,其包含 2 个迭代器,第一个迭代器指向的是 result_true 区域内最后一个元素之后的位置;第二个迭代器指向的是 result_false 区域内最后一个元素之后的位置
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::partition_copy
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义筛选规则
bool mycomp(int i) { return (i % 2) == 0; }
//以函数对象的形式定义筛选规则
class mycomp2 {
public:
bool operator()(const int& i) {
return (i % 2 == 0);
}
};
int main() {
vector<int> myvector{ 1,2,3,4,5,6,7,8,9 };
int b[10] = { 0 }, c[10] = { 0 };
//以 mycomp 规则,对 myvector 容器中的数据进行分组,这里的 mycomp 还可以改为 mycomp2(),即以 mycomp2 为筛选规则
pair<int*, int*> result= partition_copy(myvector.begin(), myvector.end(), b, c, mycomp);
cout << "b[10]:";
for (int *p = b; p < result.first; p++) {
cout << *p << " ";
}
cout << "\nc[10]:";
for (int *p = c; p < result.second; p++) {
cout << *p << " ";
}
return 0;
}
程序执行结果为:
b[10]:2 4 6 8
c[10]:1 3 5 7 9
程序中仅演示了如何用数组来存储 partition_copy() 函数分组后的数据,当然也可以用容器来存储。
C++ 标准库中还给出了 partition_copy() 函数底层实现的参考代码,感兴趣的读者可自行研究,这里不再进行过多赘述。
template <class InputIterator, class OutputIterator1,
class OutputIterator2, class UnaryPredicate pred>
pair<OutputIterator1,OutputIterator2>
partition_copy (InputIterator first, InputIterator last,
OutputIterator1 result_true, OutputIterator2 result_false,
UnaryPredicate pred)
{
while (first!=last) {
if (pred(*first)) {
*result_true = *first;
++result_true;
}
else {
*result_false = *first;
++result_false;
}
++first;
}
return std::make_pair (result_true,result_false);
}
C++ partition_point()函数(详解版)
在前面章节中,我们系统学习了 partition()、stable_partition() 和 partition_copy() 这 3 个函数,它们的功能本质上都是根据某个筛选规则对指定范围内的数据进行分组(即符合条件的为一组,不符合条件的为另一组),并且反馈给我们两组数据之间的分界位置。
事实上,有些数据本身就已经是按照某个筛选规则分好组的,例如:
1,2,3,4,5,6,7 <-- 根据规则 i<4,{1,2,3} 为一组,{4,5,6,7} 为另一组
2,4,6,8,1,3,5,7,9 <-- 根据规则 i%2=0,{2,4,6,8} 为一组,{1,3,5,7,9} 为另一组
类似上面这样已经“分好组”的数据,在使用时会有一个问题,即不知道两组数据之间的分界在什么位置。有读者可能想到,再调用一次 partition()、stale_partition() 或者 partition_copy() 不就可以了吗?这种方法确实可行,但对已经分好组的数据再进行一次分组,是没有任何必要的。
实际上,对于如何在已分好组的数据中找到分界位置,C++ 11标准库提供了专门解决此问题的函数,即 partition_point() 函数。
partition_point() 函数定义在<algorithm>头文件中,其语法格式为:
ForwardIterator partition_point (ForwardIterator first, ForwardIterator last,
UnaryPredicate pred);
其中,first 和 last 为正向迭代器,[first, last) 用于指定该函数的作用范围;pred 用于指定数据的筛选规则。
所谓筛选规则,其实就是包含 1 个参数且返回值类型为 bool 的函数,此函数可以是一个普通函数,也可以是一个函数对象。
同时,该函数会返回一个正向迭代器,该迭代器指向的是 [first, last] 范围内第一个不符合 pred 筛选规则的元素。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::partition_point
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义筛选规则
bool mycomp(int i) { return (i % 2) == 0; }
//以函数对象的形式定义筛选规则
class mycomp2 {
public:
bool operator()(const int& i) {
return (i % 2 == 0);
}
};
int main() {
vector<int> myvector{ 2,4,6,8,1,3,5,7,9 };
//根据 mycomp 规则,为 myvector 容器中的数据找出分界
vector<int>::iterator iter = partition_point(myvector.begin(), myvector.end(),mycomp);
//输出第一组的数据
for (auto it = myvector.begin(); it != iter; ++it) {
cout << *it << " ";
}
cout << "\n";
//输出第二组的数据
for (auto it = iter; it != myvector.end(); ++it) {
cout << *it << " ";
}
cout << "\n*iter = " << *iter;
return 0;
}
程序执行结果为:
2 4 6 8
1 3 5 7 9
*iter = 1
通过分析程序并结合输出结果可以看到,partition_point() 返回了一个指向元素 1 的迭代器,而该元素为 myvector 容器中第一个不符合 mycomp 规则的元素,同时其也可以第二组数据中第一个元素。
值得一提的是,C++ 11标准库中给出了 partition_point() 函数底层实现的参考代码(如下所示),感兴趣的读者可自行分析,这里不再进行赘述:
template <class ForwardIterator, class UnaryPredicate>
ForwardIterator partition_point (ForwardIterator first, ForwardIterator last,
UnaryPredicate pred)
{
auto n = distance(first,last);
while (n>0)
{
ForwardIterator it = first;
auto step = n/2;
std::advance (it,step);
if (pred(*it)) { first=++it; n-=step+1; }
else n=step;
}
return first;
}
C++ lower_bound()函数用法详解
前面章节中,已经给大家系统地介绍了几个查找函数,如 find()、find_if()、search() 等。值得一提的是,这些函数的底层实现都采用的是顺序查找(逐个遍历)的方式,在某些场景中的执行效率并不高。例如,当指定区域内的数据处于有序状态时,如果想查找某个目标元素,更推荐使用二分查找的方法(相比顺序查找,二分查找的执行效率更高)。
幸运的是,除了前面讲过的几个函数外,C++ STL标准库中还提供有 lower_bound()、upper_bound()、equal_range() 以及 binary_search() 这 4 个查找函数,它们的底层实现采用的都是二分查找的方式。
从本节开始,将给大家系统地讲解这 4 个二分查找函数的功能和用法,这里先从 lower_bound() 函数开始讲起。
有关二分查找算法的实现原理,感兴趣的读者可阅读《二分查找(折半查找)》一节做详细了解。
C++ lower_bound()函数
lower_bound() 函数用于在指定区域内查找不小于目标值的第一个元素。也就是说,使用该函数在指定范围内查找某个目标值时,最终查找到的不一定是和目标值相等的元素,还可能是比目标值大的元素。
lower_bound() 函数定义在<algorithm>头文件中,其语法格式有 2 种,分别为:
//在 [first, last) 区域内查找不小于 val 的元素
ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last,
const T& val);
//在 [first, last) 区域内查找第一个不符合 comp 规则的元素
ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last,
const T& val, Compare comp);
其中,first 和 last 都为正向迭代器,[first, last) 用于指定函数的作用范围;val 用于指定目标元素;comp 用于自定义比较规则,此参数可以接收一个包含 2 个形参(第二个形参值始终为 val)且返回值为 bool 类型的函数,可以是普通函数,也可以是函数对象。
实际上,第一种语法格式也设定有比较规则,只不过此规则无法改变,即使用 < 小于号比较 [first, last) 区域内某些元素和 val 的大小,直至找到一个不小于 val 的元素。这也意味着,如果使用第一种语法格式,则 [first,last) 范围的元素类型必须支持 < 运算符。
此外,该函数还会返回一个正向迭代器,当查找成功时,迭代器指向找到的元素;反之,如果查找失败,迭代器的指向和 last 迭代器相同。
再次强调,该函数仅适用于已排好序的序列。所谓“已排好序”,指的是 [first, last) 区域内所有令 element<val(或者 comp(element,val),其中 element 为指定范围内的元素)成立的元素都位于不成立元素的前面。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::lower_bound
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义查找规则
bool mycomp(int i,int j) { return i>j; }
//以函数对象的形式定义查找规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return i>j;
}
};
int main() {
int a[5] = { 1,2,3,4,5 };
//从 a 数组中找到第一个不小于 3 的元素
int *p = lower_bound(a, a + 5, 3);
cout << "*p = " << *p << endl;
vector<int> myvector{ 4,5,3,1,2 };
//根据 mycomp2 规则,从 myvector 容器中找到第一个违背 mycomp2 规则的元素
vector<int>::iterator iter = lower_bound(myvector.begin(), myvector.end(),3,mycomp2());
cout << "*iter = " << *iter;
return 0;
}
程序执行结果为:
*p = 3
*iter = 3
注意,myvector 容器中存储的元素看似是乱序的,但对于元素 3 来说,大于 3 的所有元素都位于其左侧,小于 3 的所有元素都位于其右侧,且查找规则选用的是 mycomp2(),其查找的就是第一个不大于 3 的元素,因此 lower_bound() 函数是可以成功运行的。
C++ STL标准库给出了 lower_bound() 函数底层实现的参考代码(如下所示),感兴趣的读者可自行研究,这里不再赘述:
template <class ForwardIterator, class T>
ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last, const T& val)
{
ForwardIterator it;
iterator_traits<ForwardIterator>::difference_type count, step;
count = distance(first,last);
while (count>0)
{
it = first; step=count/2; advance (it,step);
if (*it<val) { //或者 if (comp(*it,val)),对应第 2 种语法格式
first=++it;
count-=step+1;
}
else count=step;
}
return first;
}
C++ upper_bound()函数(精讲版)
《C++ lower_bound()》一节中,系统地介绍了 lower_bound() 二分法查找函数的功能和用法,在此基础上,本节再讲解一个功能类似的查找函数,即 upper_bound() 函数。
upper_bound() 函数定义在<algorithm>头文件中,用于在指定范围内查找大于目标值的第一个元素。该函数的语法格式有 2 种,分别是:
//查找[first, last)区域中第一个大于 val 的元素。
ForwardIterator upper_bound (ForwardIterator first, ForwardIterator last,
const T& val);
//查找[first, last)区域中第一个不符合 comp 规则的元素
ForwardIterator upper_bound (ForwardIterator first, ForwardIterator last,
const T& val, Compare comp);
其中,first 和 last 都为正向迭代器,[first, last) 用于指定该函数的作用范围;val 用于执行目标值;comp 作用自定义查找规则,此参数可接收一个包含 2 个形参(第一个形参值始终为 val)且返回值为 bool 类型的函数,可以是普通函数,也可以是函数对象。
实际上,第一种语法格式也设定有比较规则,即使用 < 小于号比较 [first, last) 区域内某些元素和 val 的大小,直至找到一个大于 val 的元素,只不过此规则无法改变。这也意味着,如果使用第一种语法格式,则 [first,last) 范围的元素类型必须支持 < 运算符。
同时,该函数会返回一个正向迭代器,当查找成功时,迭代器指向找到的元素;反之,如果查找失败,迭代器的指向和 last 迭代器相同。
另外,由于 upper_bound() 底层实现采用的是二分查 找的方式,因此该函数仅适用于“已排好序”的序列。注意,这里所说的“已排好序”,并不要求数据完全按照某个排序规则进行升序或降序排序,而仅仅要求 [first, last) 区域内所有令 element<val(或者 comp(element,val)成立的元素都位于不成立元素的前面(其中 element 为指定范围内的元素)。
有关二分查找算法,读者可阅读《二分查找算法》一节。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::upper_bound
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义查找规则
bool mycomp(int i, int j) { return i > j; }
//以函数对象的形式定义查找规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return i > j;
}
};
int main() {
int a[5] = { 1,2,3,4,5 };
//从 a 数组中找到第一个大于 3 的元素
int *p = upper_bound(a, a + 5, 3);
cout << "*p = " << *p << endl;
vector<int> myvector{ 4,5,3,1,2 };
//根据 mycomp2 规则,从 myvector 容器中找到第一个违背 mycomp2 规则的元素
vector<int>::iterator iter = upper_bound(myvector.begin(), myvector.end(), 3, mycomp2());
cout << "*iter = " << *iter;
return 0;
}
程序执行结果为:
*p = 4
*iter = 1
借助输出结果可以看出,upper_bound() 函数的功能和 lower_bound() 函数不同,前者查找的是大于目标值的元素,而后者查找的不小于(大于或者等于)目标值的元素。
此程序中演示了 upper_bound() 函数的 2 种适用场景,其中 a[5] 数组中存储的为升序序列;而 myvector 容器中存储的序列虽然整体是乱序的,但对于目标元素 3 来说,所有符合 mycomp2(element,3) 规则的元素都位于其左侧,不符合的元素都位于其右侧,因此 upper_bound() 函数仍可正常执行。
C++ STL标准库给出了 upper_bound() 函数底层实现的参考代码(如下所示),感兴趣的读者可自行研究,这里不再赘述:
template <class ForwardIterator, class T>
ForwardIterator upper_bound (ForwardIterator first, ForwardIterator last, const T& val)
{
ForwardIterator it;
iterator_traits<ForwardIterator>::difference_type count, step;
count = std::distance(first,last);
while (count>0)
{
it = first; step=count/2; std::advance (it,step);
if (!(val<*it)) // 或者 if (!comp(val,*it)), 对应第二种语法格式
{ first=++it; count-=step+1; }
else count=step;
}
return first;
}
C++ equel_range()函数详解
equel_range() 函数定义在<algorithm>头文件中,用于在指定范围内查找等于目标值的所有元素。
值得一提的是,当指定范围内的数据支持用 < 小于运算符直接做比较时,可以使用如下格式的 equel_range() 函数:
//找到 [first, last) 范围中所有等于 val 的元素
pair<ForwardIterator,ForwardIterator> equal_range (ForwardIterator first, ForwardIterator last, const T& val);
以上 2 种格式中,first 和 last 都为正向迭代器,[first, last) 用于指定该函数的作用范围;val 用于指定目标值;comp 用于指定比较规则,此参数可接收一个包含 2 个形参(第二个形参值始终为 val)且返回值为 bool 类型的函数,可以是普通函数,也可以是函数对象。
同时,该函数会返回一个 pair 类型值,其包含 2 个正向迭代器。当查找成功时:
- 第 1 个迭代器指向的是 [first, last) 区域中第一个等于 val 的元素;
- 第 2 个迭代器指向的是 [first, last) 区域中第一个大于 val 的元素。
反之如果查找失败,则这 2 个迭代器要么都指向大于 val 的第一个元素(如果有),要么都和 last 迭代器指向相同。
需要注意的是,由于 equel_range() 底层实现采用的是二分查找的方式,因此该函数仅适用于“已排好序”的序列。所谓“已排好序”,并不是要求 [first, last) 区域内的数据严格按照某个排序规则进行升序或降序排序,只要满足“所有令 element<val(或者 comp(element,val)成立的元素都位于不成立元素的前面(其中 element 为指定范围内的元素)”即可。
有关二分查找算法,读者可阅读《二分查找算法》一节。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::equal_range
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义查找规则
bool mycomp(int i, int j) { return i > j; }
//以函数对象的形式定义查找规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return i > j;
}
};
int main() {
int a[9] = { 1,2,3,4,4,4,5,6,7};
//从 a 数组中找到所有的元素 4
pair<int*, int*> range = equal_range(a, a + 9, 4);
cout << "a[9]:";
for (int *p = range.first; p < range.second; ++p) {
cout << *p << " ";
}
vector<int>myvector{ 7,8,5,4,3,3,3,3,2,1 };
pair<vector<int>::iterator, vector<int>::iterator> range2;
//在 myvector 容器中找到所有的元素 3
range2 = equal_range(myvector.begin(), myvector.end(), 3,mycomp2());
cout << "\nmyvector:";
for (auto it = range2.first; it != range2.second; ++it) {
cout << *it << " ";
}
return 0;
}
程序执行结果为:
a[9]:4 4 4
myvector:3 3 3 3
此程序中演示了 equal_range() 函数的 2 种适用场景,其中 a[9] 数组中存储的为升序序列;而 myvector 容器中存储的序列虽然整体是乱序的,但对于目标元素 3 来说,所有符合 mycomp2(element, 3) 规则的元素都位于其左侧,不符合的元素都位于其右侧,因此 equal_range() 函数仍可正常执行。
实际上,equel_range() 函数的功能完全可以看做是 lower_bound() 和 upper_bound() 函数的合体。C++ STL标准库给出了 equel_range() 函数底层实现的参考代码(如下所示),感兴趣的读者可自行研究,这里不再赘述:
//对应第一种语法格式
template <class ForwardIterator, class T>
pair<ForwardIterator,ForwardIterator> equal_range (ForwardIterator first, ForwardIterator last, const T& val)
{
ForwardIterator it = std::lower_bound (first,last,val);
return std::make_pair ( it, std::upper_bound(it,last,val) );
}
//对应第二种语法格式
template<class ForwardIterator, class T, class Compare>
std::pair<ForwardIt,ForwardIt> equal_range(ForwardIterator first, ForwardIterator last, const T& val, Compare comp)
{
ForwardIterator it = std::lower_bound (first,last,val,comp);
return std::make_pair ( it, std::upper_bound(it,last,val,comp) );
}
有关 lower_bound() 函数的功能和用法,可阅读《C++ lower_bound()函数》一节;有关 upper_bound() 函数的功能和用法,可阅读《C++ upper_bound()函数》一节。
C++ binary_search()函数详解//binary二进制的,双重的
binary_search() 函数定义在<algorithm>头文件中,用于查找指定区域内是否包含某个目标元素。
该函数有 2 种语法格式,分别为:
//查找 [first, last) 区域内是否包含 val
bool binary_search (ForwardIterator first, ForwardIterator last,
const T& val);
//根据 comp 指定的规则,查找 [first, last) 区域内是否包含 val
bool binary_search (ForwardIterator first, ForwardIterator last,
const T& val, Compare comp);
其中,first 和 last 都为正向迭代器,[first, last) 用于指定该函数的作用范围;val 用于指定要查找的目标值;comp 用于自定义查找规则,此参数可接收一个包含 2 个形参(第一个形参值为 val)且返回值为 bool 类型的函数,可以是普通函数,也可以是函数对象。
同时,该函数会返回一个 bool 类型值,如果 binary_search() 函数在 [first, last) 区域内成功找到和 val 相等的元素,则返回 true;反之则返回 false。
需要注意的是,由于 binary_search() 底层实现采用的是二分查找的方式,因此该函数仅适用于“已排好序”的序列。所谓“已排好序”,并不是要求 [first, last) 区域内的数据严格按照某个排序规则进行升序或降序排序,只要满足“所有令 element<val(或者 comp(element,val)成立的元素都位于不成立元素的前面(其中 element 为指定范围内的元素)”即可。
有关二分查找算法,读者可阅读《二分查找算法》一节。
举个例子:
#include <iostream> // std::cout
#include <algorithm> // std::binary_search
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义查找规则
bool mycomp(int i, int j) { return i > j; }
//以函数对象的形式定义查找规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return i > j;
}
};
int main() {
int a[7] = { 1,2,3,4,5,6,7 };
//从 a 数组中查找元素 4
bool haselem = binary_search(a, a + 9, 4);
cout << "haselem:" << haselem << endl;
vector<int>myvector{ 4,5,3,1,2 };
//从 myvector 容器查找元素 3
bool haselem2 = binary_search(myvector.begin(), myvector.end(), 3, mycomp2());
cout << "haselem2:" << haselem2;
return 0;
}
程序执行结果为:
haselem:1
haselem2:1
此程序中演示了 binary_search() 函数的 2 种适用场景,其中 a[7] 数组中存储的为升序序列;而 myvector 容器中存储的序列虽然整体是乱序的,但对于目标元素 3 来说,所有符合 mycomp2(element, 3) 规则的元素都位于其左侧,不符合的元素都位于其右侧,因此 binary_search() 函数仍可正常执行。
C++ STL标准库给出了 binary_search() 函数底层实现的参考代码(如下所示),感兴趣的读者可自行研究,这里不再赘述:
//第一种语法格式的实现
template <class ForwardIterator, class T>
bool binary_search (ForwardIterator first, ForwardIterator last, const T& val)
{
first = std::lower_bound(first,last,val);
return (first!=last && !(val<*first));
}
//第二种语法格式的底层实现
template<class ForwardIt, class T, class Compare>
bool binary_search(ForwardIt first, ForwardIt last, const T& val, Compare comp)
{
first = std::lower_bound(first, last, val, comp);
return (!(first == last) && !(comp(val, *first)));
}
有关 lower_bound() 函数的功能和用法,可阅读《C++ lower_bound()函数》一节;有关 upper_bound() 函数的功能和用法,可阅读《C++ upper_bound()函数》一节。
C++(STL) all_of、any_of及none_of算法详解
algorithm 头文件中定义了 3 种算法,用来检查在算法应用到序列中的元素上时,什么时候使谓词返回 true。这些算法的前两个参数是定义谓词应用范围的输入迭代器;第三个参数指定了谓词。检查元素是否能让谓词返回 true 似乎很简单,但它却是十分有用的。
例如,可以检查所有学生是否通过了考试,或者检查所有学生是否都参加了课程,或者检查有没有眼睛发绿的 Person 对象,甚至可以检查每个 Dog 对象是否度过了它自己的一天。谓词可以简单,也可以复杂,这取决于你。检查元素属性的三种算法是:
- all_of() 算法会返回 true,前提是序列中的所有元素都可以使谓词返回 true。
- any_of() 算法会返回 true,前提是序列中的任意一个元素都可以使谓词返回 true。
- none_of() 算法会返回 true,前提是序列中没有元素可以使谓词返回 true。
想象它们是如何工作的并不难。下面的一些代码用来说明如何使用 none_of() 算法:
std::vector<int> ages {22, 19, 46, 75, 54, 19, 27, 66, 61, 33, 22, 19};
int min_age{18};
std::cout << "There are "<< (std::none_of(std::begin(ages), std::end(ages),[min_age](int age) { return age < min_age; }) ? "no": "some") << " people under " << min_age << std::endl;
这个谓词是一个 lambda 表达式,用来将传入的 ages 容器中的元素和 min_age 的值作比较。用 none_of() 返回的布尔值来选择包含在输出信息中的是“no”还是“some”。当 ages 中没有元素小于 min_age 时,none_of() 算法会返回 true。在这种情况下,会选择“no”。当然,用 any_of() 也能产生同样的结果:
std::cout << "There are "<< (std::any_of(std::begin(ages), std::end(ages),[min_age] (int age) { return age < min_age;}) ? "some":"no") <<" people under " << min_age << std::endl;
只有在有一个或多个元素小于 min_age 时,any_of() 算法才会返回 true。
这里没有元素小于 min_age,所以也会选择“no”。
下面是一段代码,用来展示用 all_of() 检查 ages 容器中的元素:
int good_age{100};
std::cout << (std::all_of(std::begin(ages), std::end(ages),[good_age] (int age) { return age < good_age; }) ? "None": "Some") << " of the people are centenarians." << std::endl;
这个 lambda 表达式会将 ages 中的元素和 good_age 的值作比较,good_age 的值为 100。所有的元素都小于 100,所以 all_of() 会返回 true,而且输出消息会正确报告没有记录的百岁老人。
count 和 count_if 可以告诉我们,在前两个参数指定的范围内,有多少满足指定的第三个参数条件的元素。count() 会返回等同于第三个参数的元素的个数。count_if() 会返回可以使作为第三个参数的谓词返回 true 的元素个数。
下面是一些将这些算法应用到 ages 容器的示例:
std::vector<int> ages {22, 19, 46, 75, 54, 19, 27, 66, 61, 33, 22, 19};
int the_age{19};
std::cout << "There are "<< std::count(std::begin(ages),std::end(ages),the_age)<< " people aged "<< the_age << std::endl;
int max_age{60};
std::cout << "There are "<< std::count_if(std::begin(ages), std::end(ages),[max_age](int age) { return age > max_age; }) << " people aged over " << max_age << std::endl;
在第一条输出语句中使用 count() 算法来确定 ages 中等于 the_age 的元素个数,第二条输出语句使用 count_if() 来报告大于 max_age 的元素个数。
当我们想知道序列元素是否有某种特性或有多少满足标准时,本节中的所有算法都可以用来了解关于序列元素的基本特性的信息。如果想要知道具体的一序列中哪个元素匹配可以使用前面章节介绍的 find() 算法。
C++ equal(STL equal)比较算法详解
可以用和比较字符串类似的方式来比较序列。如果两个序列的长度相同,并且对应元素都相等,equal() 算法会返回 true。有 4 个版本的 equal() 算法,其中两个用 == 运算符来比较元素,另外两个用我们提供的作为参数的函数对象来比较元素,所有指定序列的迭代器都必须至少是输入迭代器。
用 == 运算符来比较两个序列的第一个版本期望 3 个输入迭代器参数,前两个参数是第一个序列的开始和结束迭代器,第三个参数是第二个序列的开始迭代器。如果第二个序列中包含的元素少于第一个序列,结果是未定义的。用 == 运算符的第二个版本期望 4 个参数:第一个序列的开始和结束迭代器,第二个序列的开始和结束迭代器,如果两个序列的长度不同,那么结果总是为 false。本节会演示这两个版本,但推荐使用接受 4 个参数的版本,因为它不会产生未定义的行为。
下面是一个演示如何应用它们的示例:
// Using the equal() algorithm
#include <iostream> // For standard streams
#include <vector> // For vector container
#include <algorithm> // For equal() algorithm
#include <iterator> // For stream iterators
#include <string> // For string class
using std::string;
int main()
{
std::vector<string> words1 {"one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
std::vector<string> words2 {"two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"};
auto iter1 = std::begin(words1);
auto end_iter1 = std::end(words1);
auto iter2 = std::begin(words2);
auto end_iter2 = std::end(words2);
std::cout << "Container - words1:";
std::copy(iter1, end_iter1, std::ostream_iterator<string>{std::cout, " "});
std::cout << "\nContainer - words2:";
std::copy(iter2, end_iter2, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::cout << "\n1. Compare from words1[1] to end with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2) << std::endl;
std::cout << "2. Compare from words2[0] to second-to-last with words1:";
std::cout << std::boolalpha << std::equal(iter2, end_iter2 - 1, iter1) << std::endl;
std::cout << "3. Compare from words1[1] to words1[5] with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, iter1 + 6, iter2) << std::endl;
std::cout << "4. Compare first 6 from words1 with first 6 in words2:";
std::cout << std::boolalpha << std::equal(iter1, iter1 + 6, iter2, iter2 + 6) << std::endl;
std::cout << "5. Compare all words1 with words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2) << std::endl;
std::cout << "6. Compare all of words1 with all of words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2, end_iter2) << std::endl;
std::cout << "7. Compare from words1[1] to end with words2 from first to second-to-last:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2, end_iter2 - 1) << std::endl;
}
输出结果为:
Container - words1: one two three four five six seven eight nine
Container - words2: two three four five six seven eight nine ten
1.Compare from words1[1] to end with words2: true
2.Compare from words2[0] to second-to-last with words1: false
3.Compare from words1[1] to wordsl[5] with words2: true
4.Compare first 6 from words1 with first 6 in words2: false
5.Compare all wordsl with words2: false
6.Compare all of words1 with all of words2: false
7.Compare from words1[1] to end with words2 from first to second_to_last: true
在这个示例中,对来自于 words1 和 words2 容器的元素的不同序列进行了比较。equal() 调用产生这些输出的原因如下:
- 第 1 条语句的输出为 true,因为 words1 的第二个元素到最后一个元素都从 words2 的第一个元素开始匹配。第二个序列的元素个数比第一个序列的元素个数多 1,但 第一个序列的元素个数决定了比较多少个对应的元素。
- 第 2 条语句的输出为 false,因为有直接的不匹配;words2 和 words1 的第一个元素不同。
- 第 3 条语句的输出为 true,因为 word1 中从第二个元素开始的 5 个元素和 words2 的前五个元素相等。
- 在第 4 条语句中,words2 的元素序列是由开始和结束迭代器指定的。序列长度相同,但它们的第一个元素不同,所以结果为 false。
- 在第 5 条语句中,两个序列的第一个元素直接就不匹配,所以结果为 false。
- 第 6 条语句的输出为 false,因为序列是不同的。这条语句不同于前面的 equal() 调用,因为指定了第二个序列的结束迭代器。
- 第 7 条语句会从 words1 的第二个元素开始,与 word2 从第一个元素开始比较相同个数的元素,所以输出为 true。
当用 equal() 从开始迭代器开始比较两个序列时,第二个序列用来和第一个序列比较的元素个数由第一个序列的长度决定。就算第二个序列比第一个序列的元素多,equal() 仍然会返回 true。如果为两个序列提供了开始和结束迭代器,为了使结果为 true,序列必须是相同的长度。
尽管可以用 equal() 来比较两个同种类型的容器的全部内容,但最好还是使用容器的成员函数 operator==() 来做这些事。示例中的第 6 条输出语句可以这样写:
std::cout << std::boolalpha << (words1 == words2) << " "; // false
这两个版本的 equal() 接受一个谓词作为额外的参数。这个谓词定义了元素之间的等价 比较。下面是一个说明它们用法的代码段:
std::vector<string> r1 { "three", "two", "ten"};
std::vector<string> r2 {"twelve", "ten", "twenty" };
std::cout << std::boolalpha<< std::equal (std::begin (r1) , std::end (r1) , std::begin (r2),[](const string& s1, const string& s2) { return s1[0] = s2[0]; })<< std::endl; // true
std::cout << std::boolalpha<<std::equal(std::begin(r1), std::end(r1), std::begin(r2), std::end(r2),[](const string& s1, const string& s2) { return s1[0] == s2[0]; }) << std::endl; // true
在 equal() 的第一次使用中,第二个序列是由开始迭代器指定的。谓词是一个在字符串 参数的第一个字符相等时返回 true 的 lambda 表达式。最后一条语句表明,equal() 算法可以使用两个全范围的序列,并使用相同的谓词。
不应该用 equal() 来比较来自于无序 map 或 set 容器中的元素序列。在无序容器中,一组给定元素的顺序可能和保存在另一个无序容器中的一组相等元素不同,因为不同容器的元素很可能会被分配到不同的格子中。
boolalpha的用法
由于"true"或"false"字符串打印不是自动进行的。只能输出0或1 向输出true"或"false"的话只能自己动手。boolalpha是头文件#include中的一个函数,是把bool a = 1;变量打印出false或者true的函数
copy()函数
现在我们来看看变易算法。所谓变易算法(Mutating algorithms)就是一组能够修改容器元素数据的模板函数,可进行序列数据的复制,变换等。
我们现在来看看第一个变易算法:元素复制算法copy。该算法主要用于容器之间元素的拷贝,即将迭代器区间[first,last)的元素复制到由复制目 标result给定的区间[result,result+(last-first))中。下面我们来看看它的函数原型:
1 template<class InputIterator, class OutputIterator>
2 OutputIterator copy(
3 InputIterator _First,
4 InputIterator _Last,
5 OutputIterator _DestBeg
6 );
参数
-
_First, _Last
指出被复制的元素的区间范围[ _First,_Last).
-
_DestBeg
指出复制到的目标区间起始位置
返回值
返回一个迭代器,指出已被复制元素区间的最后一个位置
程序示例:
首先我们来一个简单的示例,定义一个简单的整形数组myints,将其所有元素复制到容器myvector中,并将数组向左移动一位。
1 #include <iostream>
2 #include <algorithm>
3 #include <vector>
4
5 using namespace std;
6
7 int main ()
8 {
9 int myints[] = {10, 20, 30, 40, 50, 60, 70};
10 vector<int> myvector;
11 vector<int>::iterator it;
12
13 myvector.resize(7); // 为容器myvector分配空间
14
15 //copy用法一:
16 //将数组myints中的七个元素复制到myvector容器中
17 copy ( myints, myints+7, myvector.begin() );
18
19 cout << "myvector contains: ";
20 for ( it = myvector.begin(); it != myvector.end(); ++it )
21 {
22 cout << " " << *it;
23 }
24 cout << endl;
25
26 //copy用法二:
27 //将数组myints中的元素向左移动一位
28 copy(myints + 1, myints + 7, myints);
29
30 cout << "myints contains: ";
31 for ( size_t i = 0; i < 7; ++i )
32 {
33 cout << " " << myints[i];
34 }
35 cout << endl;
36
37 return 0;
38 }
从上例中我们看出copy算法可以很简单地将一个容器里面的元素复制至另一个目标容器中,**上例中代码特别要注意一点就是myvector.resize(7);这行代码,在这里一定要先为vector分配空间,否则程序会崩,这是初学者经常犯的一个错误。**其实copy函数最大的威力是结合标准输入输出迭代器的时候,我们通过下面这个示例就可以看出它的威力了。
1 #include <iostream>
2 #include <algorithm>
3 #include <vector>
4 #include <iterator>
5 #include <string>
6
7 using namespace std;
8
9 int main ()
10 {
11 typedef vector<int> IntVector;
12 typedef istream_iterator<int> IstreamItr;
13 typedef ostream_iterator<int> OstreamItr;
14 typedef back_insert_iterator< IntVector > BackInsItr;
15
16 IntVector myvector;
17
18 // 从标准输入设备读入整数
19 // 直到输入的是非整型数据为止 请输入整数序列,按任意非数字键并回车结束输入
20 cout << "Please input element:" << endl;
21 copy(IstreamItr(cin), IstreamItr(), BackInsItr(myvector));
22
23 //输出容器里的所有元素,元素之间用空格隔开
24 cout << "Output : " << endl;
25 copy(myvector.begin(), myvector.end(), OstreamItr(cout, " "));
26 cout << endl;
27
28 return 0;
29 }
C++ mismatch(STL mismatch)算法详解
equal() 算法可以告诉我们两个序列是否匹配。mismatch() 算法也可以告诉我们两个序列是否匹配,而且如果不匹配,它还能告诉我们不匹配的位置。
mismatch() 的 4 个版本和 equal() 一样有相同的参数——第二个序列有或没有结束迭代器,有或没有定义比较的额外的函数对象参数。mismatch() 返回的 pair 对象包含两个迭代器。它的 first 成员是一个来自前两个参数所指定序列的迭代器,second 是来自于第二个序列的迭代器。当序列不匹配时,pair 包含的迭代器指向第一对不匹配的元素;因此这个 pair 对象为 pair<iter1+n,iter2 + n>,这两个序列中索引为 n 的元素是第一个不匹配的元素。
当序列匹配时,pair 的成员取决于使用的 mismatch() 的版本和具体情况。iter1 和 end_iter1 表示定义第一个序列的迭代器,iter2 和 end_iter2 表示第二个序列的开始和结束迭代器。返回的匹配序列的 pair 的内容如下:
对于 mismatch(iter1,end_iter1,iter2):
- 返回 pair<end_iter1,(iter2 + (end_ter1 - iter1))>,pair 的成员 second 等于 iter2 加上第一个序列的长度。如果第二个序列比第一个序列短,结果是未定义的。
对于 mismatch(iterl, end_iter1, iter2, end_iter2):
- 当第一个序列比第二个序列长时,返回 pair<end_iter1, (iter2 + (end_iter1 - iter1))>,所以成员 second 为 iter2 加上第一个序列的长度。
- 当第二个序列比第一个序列长时,返回 pair<(iter1 + (end_iter2 - iter2)),end_iter2>, 所以成员 first 等于 iter1 加上第二个序列的长度。
- 当序列的长度相等时,返回 pair<end_iter1, end_iter2>。
不管是否添加一个用于比较的函数对象作为参数,上面的情况都同样适用。
下面是一个使用带有默认相等比较的 mismatch() 的示例:
// Using the mismatch() algorithm
#include <iostream> // For standard streams
#include <vector> // For vector container
#include <algorithm> // For equal() algorithm
#include <string> // For string class
#include <iterator> // For stream iterators
using std::string;
using word_iter = std::vector<string>::iterator;
int main()
{
std::vector<string> words1 {"one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
std::vector<string> words2 {"two", "three", "four", "five", "six", "eleven", "eight", "nine", "ten"};
auto iter1 = std::begin(words1);
auto end_iter1 = std::end(words1);
auto iter2 = std::begin(words2);
auto end_iter2 = std::end(words2);
// Lambda expression to output mismatch() result
auto print_match = [](const std::pair<word_iter, word_iter>& pr, const word_iter& end_iter)
{
if(pr.first != end_iter)
std::cout << "\nFirst pair of words that differ are "<< *pr.first << " and " << *pr.second << std::endl;
else
std::cout << "\nRanges are identical." << std::endl;
};
std::cout << "Container - words1: ";
std::copy(iter1, end_iter1, std::ostream_iterator<string>{std::cout, " "});
std::cout << "\nContainer - words2: ";
std::copy(iter2, end_iter2, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::cout << "\nCompare from words1[1] to end with words2:";
print_match(std::mismatch(iter1 + 1, end_iter1, iter2), end_iter1);
std::cout << "\nCompare from words2[0] to second-to-last with words1:";
print_match(std::mismatch(iter2, end_iter2 - 1, iter1), end_iter2 - 1);
std::cout << "\nCompare from words1[1] to words1[5] with words2:";
print_match(std::mismatch(iter1 + 1, iter1 + 6, iter2), iter1 + 6);
std::cout << "\nCompare first 6 from words1 with first 6 in words2:";
print_match(std::mismatch(iter1, iter1 + 6, iter2, iter2 + 6), iter1 + 6);
std::cout << "\nCompare all words1 with words2:";
print_match(std::mismatch(iter1, end_iter1, iter2), end_iter1);
std::cout << "\nCompare all of words2 with all of words1:";
print_match(std::mismatch(iter2, end_iter2, iter1, end_iter1), end_iter2);
std::cout << "\nCompare from words1[1] to end with words2[0] to second-to-last:";
print_match(std::mismatch(iter1 + 1, end_iter1, iter2, end_iter2 - 1), end_iter1);
}
注意 words2 中的内容和前面示例中的有些不同。每一次应用 mismatch() 的结果都是由定义为 print_match 的 lambda 表达式生成的。它的参数是一个 pair 对象和一个 vector 容器的迭代器。使用 using 指令生成 word_iter 别名可以使 lambda 表达式的定义更简单。
在 main() 的代码中使用了不同版本的 mismatch(),它们都没有包含比较函数对象的参数。如果第二个序列只用开始迭代器指定,为了和第一个序列匹配,它只需要有和第一个序列相等长度的元素,但也可以更长。如果第二个序列是完全指定的,会由最短的序列来确定比较多少个元素。
输出如下:
Container - words1: one two three four five six seven eight nine
Container - words2: two three four five six eleven eight nine ten
Compare from words1[1] to end with words2:
First pair of words that differ are seven and eleven
Compare from words2[0] to second-to-last with words1:
First pair of words that differ are two and one
Compare from words1[1] to words1[5] with words2:
Ranges are identical.
Compare first 6 from words1 with first 6 in words2:
First pair of words that differ are one and two
Compare all words1 with words2:
First pair of words that differ are one and two
Compare all of words2 with all of words1:
First pair of words that differ are two and one
Compare from words1[1] to end with words2[0] to second-to-last:
First pair of words that differ are seven and eleven
输出显示了每个 mismatch() 的运用结果。 在我们提供自己的函数对象时,就可以完全灵活地定义相等比较。例如:
std::vector<string> range1 {"one", "three", "five", "ten"};
std::vector<string> range2 {"nine", "five", "eighteen”,"seven"};
auto pr = std::mismatch( std::begin(range1), std::end(range1),std:rbegin(range2), std::end(range2),[](const string& s1, const string& s2) { return s1.back() = s2.back(); });
if(pr.first == std::end(range1) || pr.second == std::end(range2))
std::cout << "The ranges are identical." << std::endl;
else
std::cout << *pr.first << " is not equal to " << *pr.second <<std::endl;
当两个字符串的最后一个字符相等时,这个比较会返回 true,所以这段代码的输出为:
five is not equal to eighteen
C++11 lambda匿名函数用法详解
lambda 源自希腊字母表中第 11 位的 λ,在计算机科学领域,它则是被用来表示一种匿名函数。所谓匿名函数,简单地理解就是没有名称的函数,又常被称为 lambda 函数或者 lambda 表达式。
继 Python、Java、C#、PHP 等众多高级编程语言都支持 lambda 匿名函数后,C++11 标准终于引入了 lambda,本节将带领大家系统地学习 lambda 表达式的具体用法。
lambda匿名函数的定义
定义一个 lambda 匿名函数很简单,可以套用如下的语法格式:
[外部变量访问方式说明符] (参数) mutable noexcept/throw() -> 返回值类型
{
函数体;
};
其中各部分的含义分别为:
- [外部变量方位方式说明符]
[ ] 方括号用于向编译器表明当前是一个 lambda 表达式,其不能被省略。在方括号内部,可以注明当前 lambda 函数的函数体中可以使用哪些“外部变量”。
所谓外部变量,指的是和当前 lambda 表达式位于同一作用域内的所有局部变量。
-
(参数)
和普通函数的定义一样,lambda 匿名函数也可以接收外部传递的多个参数。和普通函数不同的是,如果不需要传递参数,可以连同 () 小括号一起省略; -
mutable
此关键字可以省略,如果使用则之前的 () 小括号将不能省略(参数个数可以为 0)。默认情况下,对于以值传递方式引入的外部变量,不允许在 lambda 表达式内部修改它们的值(可以理解为这部分变量都是 const 常量)。而如果想修改它们,就必须使用 mutable 关键字。
注意,对于以值传递方式引入的外部变量,lambda 表达式修改的是拷贝的那一份,并不会修改真正的外部变量; 4. noexcept/throw()
可以省略,如果使用,在之前的 () 小括号将不能省略(参数个数可以为 0)。默认情况下,lambda 函数的函数体中可以抛出任何类型的异常。而标注 noexcept 关键字,则表示函数体内不会抛出任何异常;使用 throw() 可以指定 lambda 函数内部可以抛出的异常类型。
值得一提的是,如果 lambda 函数标有 noexcept 而函数体内抛出了异常,又或者使用 throw() 限定了异常类型而函数体内抛出了非指定类型的异常,这些异常无法使用 try-catch 捕获,会导致程序执行失败(本节后续会给出实例)。
-
-> 返回值类型
指明 lambda 匿名函数的返回值类型。值得一提的是,如果 lambda 函数体内只有一个 return 语句,或者该函数返回 void,则编译器可以自行推断出返回值类型,此情况下可以直接省略-> 返回值类型。 -
函数体
和普通函数一样,lambda 匿名函数包含的内部代码都放置在函数体中。该函数体内除了可以使用指定传递进来的参数之外,还可以使用指定的外部变量以及全局范围内的所有全局变量。
需要注意的是,外部变量会受到以值传递还是以引用传递方式引入的影响,而全局变量则不会。换句话说,在 lambda 表达式内可以使用任意一个全局变量,必要时还可以直接修改它们的值。
其中,红色标识的参数是定义 lambda 表达式时必须写的,而绿色标识的参数可以省略。
比如,如下就定义了一个最简单的 lambda 匿名函数:
[]{}
显然,此 lambda 匿名函数未引入任何外部变量([] 内为空),也没有传递任何参数,没有指定 mutable、noexcept 等关键字,没有返回值和函数体。所以,这是一个没有任何功能的 lambda 匿名函数。
lambda匿名函数中的[外部变量]
对于 lambda 匿名函数的使用,令多数初学者感到困惑的就是 [外部变量] 的使用。其实很简单,无非表 1 所示的这几种编写格式。
表 1 [外部变量]的定义方式
| 外部变量格式 | 功能 |
|---|---|
| [] | 空方括号表示当前 lambda 匿名函数中不导入任何外部变量。 |
| [=] | 只有一个 = 等号,表示以值传递的方式导入所有外部变量; |
| [&] | 只有一个 & 符号,表示以引用传递的方式导入所有外部变量; |
| [val1,val2,…] | 表示以值传递的方式导入 val1、val2 等指定的外部变量,同时多个变量之间没有先后次序; |
| [&val1,&val2,…] | 表示以引用传递的方式导入 val1、val2等指定的外部变量,多个变量之间没有前后次序; |
| [val,&val2,…] | 以上 2 种方式还可以混合使用,变量之间没有前后次序。 |
| [=,&val1,…] | 表示除 val1 以引用传递的方式导入外,其它外部变量都以值传递的方式导入。 |
| [this] | 表示以值传递的方式导入当前的 this 指针。 |
注意,单个外部变量不允许以相同的传递方式导入多次。例如 [=,val1] 中,val1 先后被以值传递的方式导入了 2 次,这是非法的。
【例 1】lambda 匿名函数的定义和使用。
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int num[4] = {4, 2, 3, 1};
//对 a 数组中的元素进行排序
sort(num, num+4, [=](int x, int y) -> bool{ return x < y; } );
for(int n : num){
cout << n << " ";
}
return 0;
}
程序执行结果为:
1 2 3 4
程序第 9 行通过调用 sort() 函数实现了对 num 数组中元素的升序排序,其中就用到了 lambda 匿名函数。而如果使用普通函数,需以如下代码实现:
#include <iostream>
#include <algorithm>
using namespace std;
//自定义的升序排序规则
bool sort_up(int x,int y){
return x < y;
}
int main()
{
int num[4] = {4, 2, 3, 1};
//对 a 数组中的元素进行排序
sort(num, num+4, sort_up);
for(int n : num){
cout << n << " ";
}
return 0;
}
此程序中 sort_up() 函数的功能和上一个程序中的 lambda 匿名函数完全相同。显然在类似的场景中,使用 lambda 匿名函数更有优势。
除此之外,虽然 lambda 匿名函数没有函数名称,但我们仍可以为其手动设置一个名称,比如:
#include <iostream>
using namespace std;
int main()
{
//display 即为 lambda 匿名函数的函数名
auto display = [](int a,int b) -> void{cout << a << " " << b;};
//调用 lambda 函数
display(10,20);
return 0;
}
程序执行结果为:
10 20
可以看到,程序中使用 auto 关键字为 lambda 匿名函数设定了一个函数名,由此我们即可在作用域内调用该函数。
【例 2】值传递和引用传递的区别
#include <iostream>
using namespace std;
//全局变量
int all_num = 0;
int main()
{
//局部变量
int num_1 = 1;
int num_2 = 2;
int num_3 = 3;
cout << "lambda1:\n";
auto lambda1 = [=]{
//全局变量可以访问甚至修改
all_num = 10;
//函数体内只能使用外部变量,而无法对它们进行修改
cout << num_1 << " "
<< num_2 << " "
<< num_3 << endl;
};
lambda1();
cout << all_num <<endl;
cout << "lambda2:\n";
auto lambda2 = [&]{
all_num = 100;
num_1 = 10;
num_2 = 20;
num_3 = 30;
cout << num_1 << " "
<< num_2 << " "
<< num_3 << endl;
};
lambda2();
cout << all_num << endl;
return 0;
}
程序执行结果为:
lambda1:
1 2 3
10
lambda2:
10 20 30
100
可以看到,在创建 lambda1 和 lambda2 匿名函数的作用域中,有 num_1、num_2 和 num_3 这 3 个局部变量,另外还有 all_num 全局变量。
其中,lambda1 匿名函数是以 [=] 值传递的方式导入的局部变量,这意味着默认情况下,此函数内部无法修改这 3 个局部变量的值,但全局变量 all_num 除外。相对地,lambda2 匿名函数以 [&] 引用传递的方式导入这 3 个局部变量,因此在该函数的内部不就可以访问这 3 个局部变量,还可以任意修改它们。同样,也可以访问甚至修改全局变量。
感兴趣的读者,可自行尝试在 lambda1 匿名函数中修改 num_1、num_2 或者 num_3 的值,观察编译器的报错信息。
当然,如果我们想在 lambda1 匿名函数的基础上修改外部变量的值,可以借助 mutable 关键字,例如:
auto lambda1 = [=]() mutable{
num_1 = 10;
num_2 = 20;
num_3 = 30;
//函数体内只能使用外部变量,而无法对它们进行修改
cout << num_1 << " "
<< num_2 << " "
<< num_3 << endl;
};
由此,就可以在 lambda1 匿名函数中修改外部变量的值。但需要注意的是,这里修改的仅是 num_1、num_2、num_3 拷贝的那一份的值,真正外部变量的值并不会发生改变。
【例 3】执行抛出异常类型
#include <iostream>
using namespace std;
int main()
{
auto except = []()throw(int) {
throw 10;
};
try {
except();
}
catch (int) {
cout << "捕获到了整形异常";
}
return 0;
}
程序执行结果为:
捕获到了整形异常
可以看到,except 匿名数组中指定函数体中可以抛出整形异常,因此当函数体中真正发生整形异常时,可以借助 try-catch 块成功捕获并处理。
在此基础上,在看一下反例:
#include <iostream>
using namespace std;
int main()
{
auto except1 = []()noexcept{
throw 100;
};
auto except2 = []()throw(char){
throw 10;
};
try{
except1();
except2();
}catch(int){
cout << "捕获到了整形异常"<< endl;
}
return 0;
}
此程序运行会直接崩溃,原因很简单,except1 匿名函数指定了函数体中不发生任何异常,但函数体中却发生了整形异常;except2 匿名函数指定函数体可能会发生字符异常,但函数体中却发生了整形异常。由于指定异常类型和真正发生的异常类型不匹配,导致 try-catch 无法捕获,最终程序运行崩溃。
如果不使用 noexcept 或者 throw(),则 lambda 匿名函数的函数体中允许发生任何类型的异常。
C++(STL) lexicographical_compare字符串排序算法详解
两个字符串的字母排序是通过从第一个字符开始比较对应字符得到的。第一对不同的对应字符决定了哪个字符串排在首位。字符串的顺序就是不同字符的顺序。如果字符串的长度相同,而且所有的字符都相等,那么这些字符串就相等。如果字符串的长度不同,短字符串的字符序列和长字符串的初始序列是相同的,那么短字符串小于长字符串。因此 “age” 在“beauty” 之前,“a lull” 在 “a storm” 之前。显然,“the chicken” 而不是 “the egg” 会排在首位。
对于任何类型的对象序列来说,字典序都是字母排序思想的泛化。从两个序列的第一个元素开始依次比较对应的元素,前两个对象的不同会决定序列的顺序。显然,序列中的对象必须是可比较的。
lexicographical_compare()算法可以比较由开始和结束迭代器定义的两个序列。它的前两个参数定义了第一个序列,第 3 和第 4 个参数分别是第二个序列的开始和结束迭代器。默认用 < 运算符来比较元素,但在需要时,也可以提供一个实现小于比较的函数对象作为可选的第 5 个参数。如果第一个序列的字典序小于第二个,这个算法会返回 true,否则返回 false。所以,返回 false 表明第一个序列大于或等于第二个序列。
序列是逐个元素比较的。第一对不同的对应元素决定了序列的顺序。如果序列的长度不同,而且短序列和长序列的初始元素序列匹配,那么短序列小于长序列。长度相同而且对应元素都相等的两个序列是相等的。空序列总是小于非空序列。下面是一个使用 lexicographical_compare() 的示例:
std::vector<string> phrase1 {"the", "tigers", "of", "wrath"};
std::vector<string> phrase2 {"the", "horses", "of", "instruction"};
auto less = std::lexicographical_compare (std::begin (phrase1), std: :end (phrase1),
std::begin(phrase2), std::end(phrase2)); std::copy(std::begin(phrase1), std::end(phrase1), std::ostream_iterator<string>{std::cout, " "});
std::cout << (less ? "are":"are not") << " less than ";
std::copy(std::begin(phrase2), std::end(phrase2), std::ostream_iterator <string>{std::cout, " "});
std::cout << std::endl;
因为这些序列的第二个元素不同,而且“tigers”大于“horses”,这段代码会生成如下 输出:
the tigers of wrath are not less than the horses of instruction
可以在 lexicographical_compare() 调用中添加一个参数,得到相反的结果:
auto less = std::lexicographical_compare (std::begin (phrase1), std::end (phrase1),std::begin(phrase2), std::end(phrase2), [](const string& s1, const string& s2) { return s1.length() < s2.length(); });
这个算法会使用作为第 3 个参数的 lambda 表达式来比较元素。这里会比较序列中字符串的长度,因为 phrase1 中第 4 个元素的长度小于 phrase2 中对应的元素,所以 phrase1 小于 phrase2。
C++ next_permutation(STL next_permutation)算法详解
排列就是一次对对象序列或值序列的重新排列。例如,“ABC”中字符可能的排列是:
"ABC", "ACB", "BAC", "BCA", "CAB", "CBA"
三个不同的字符有 6 种排列,这个数字是从 321 得到的。一般来说,n 个不同的字 符有 n! 种排列,n! 是 nx(n_1)x(n-2)…x2x1。很容易明白为什么要这样算。有 n 个对象 时,在序列的第一个位置就有 n 种可能的选择。对于第一个对象的每一种选择,序列的第 二个位置还剩下 n-1 种选择,因此前两个有 nx((n-1) 种可能选择。在选择了前两个之后, 第三个位置还剩下 n-2 种选择,因此前三个有 nx(n-1)x(n-2) 种可能选择,以此类推。序列的末尾是 Hobson 选择,因为只剩下 1 种选择。
对于包含相同元素的序列来说,只要一个序列中的元素顺序不同,就是一种排列。next_permutation() 会生成一个序列的重排列,它是所有可能的字典序中的下一个排列,默认使用 < 运算符来做这些事情。它的参数为定义序列的迭代器和一个返回布尔值的函数,这个函数在下一个排列大于上一个排列时返回 true,如果上一个排列是序列中最大的,它返回 false,所以会生成字典序最小的排列。
下面展示了如何生成一个包含 4 个整数的 vector 的排列:
std::vector<int> range {1,2,3,4};
do {
std::copy (std::begin(range), std::end(range), std::ostream_iterator<int>{std::cout, " "});
std::cout << std::endl;
}while(std::next_permutation(std::begin(range), std::end(range)));
当 next_permutation() 返回 false 时,循环结束,表明到达最小排列。这样恰好可以生成 序列的全部排列,这只是因为序列的初始排列为 1、2、3、4,这是排列集合中的第一个排列。有一种方法可以得到序列的全排列,就是使用 next_permutation() 得到的最小排列:
std::vector<string> words { "one", "two", "three", "four", "five", "six", "seven", "eight"};
while(std::next_permutation(std::begin(words), std::end(words)));
do
{
std::copy(std::begin(words), std::end(words), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
} while(std::next_permutation(std::begin(words), std::end(words)));
words 中的初始序列不是最小的排列序列,循环会继续进行,直到 words 包含最小排列。do-wliile 循环会输出全部的排列。如果想执行这段代码,需要记住它会生成 8! 种排列,从而输出 40320 行,因此首先可能会减少 words 中元素的个数。
当排列中的每个元素都小于或等于它后面的元素时,它就是元素序列的最小排列,所以可以用 min_element() 来返回一个指向序列中最小元素的迭代器,然后用 iter_swap() 算法交换两个迭代器指向的元素,从而生成最小的排列,例如:
std::vector<string> words { "one", "two", "three", "four", "five","six",
"seven", "eight"};
for (auto iter = std::begin(words); iter != std::end(words)-1 ;++iter)
std::iter_swap(iter, std::min_element(iter, std::end(words)));
for 循环从序列的第一个迭代器开始遍历,直到倒数第二个迭代器。for 循环体中的语句会交换 iter 指向的元素和 min_element() 返回的迭代器所指向的元素。这样最终会生成一个最小排列,然后可以用它作为 next_permutation() 的起始点来生成全排列。
在开始生成全排列之前,可以先生成一个原始容器的副本,然后在循环中改变它,从 而避免到达最小排列的全部开销。
std::vector<string> words {"one","two", "three", "four", "five", "six", "seven", "eight"};
auto words_copy = words; // Copy the original
do {
std::copy(std::begin(words), std::end(words), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::next_permutation(std::begin(words), std::end(words));
}while(words != words_copy); // Continue until back to the original
循环现在会继续生成新的排列,直到到达原始排列。下面是一个找出单词中字母的全部排列的示例:
// Finding rearrangements of the letters in a word
#include <iostream> // For standard streams
#include <iterator> // For iterators and begin() and end()
#include <string> // For string class
#include <vector> // For vector container
#include <algorithm> // For next_permutation()
using std::string;
int main()
{
std::vector<string> words;
string word;
while(true)
{
std::cout << "\nEnter a word, or Ctrl+z to end: ";
if((std::cin >> word).eof()) break;
string word_copy {word};
do
{
words.push_back(word);
std::next_permutation(std::begin(word), std::end(word));
} while(word != word_copy);
size_t count{}, max{8};
for(const auto& wrd : words)
std::cout << wrd << ((++count % max == 0) ? '\n' : ' ');
std::cout << std::endl;
words.clear(); // Remove previous permutations
}
}
这段代码会从标准输入流读取一个单词到 word 中,然后在 word_copy 中生成一个副本,将 word 中字符的全排列保存到 words 容器中。这个程序会继续处理单词直到按下 Ctrl+Z 组合键。用 word 的副本来判断是否已经保存了全排列。然后所有的排列会被写入输出流,8 个一行。像之前说的那样,随着被排列元素个数的增加,排列的个数增加也很快,所以这里不要尝试使用太长的单词。
可以为 next_permutation() 提供一个函数对象作为第三个参数,从而用这个函数对象定 义的比较函数来代替默认的比较函数。下面展示如何使用这个版本的函数,通过比较最后 一个字母的方式来生成 words 序列的排列:
std::vector<string> words { "one", "two", "four", "eight"};
do {
std::copy(std:rbegin(words), std::end(words), std::ostream_iterator<string> {std::cout, " "});
std::cout << std::endl;
} while(std::next_permutation(std::begin(words), std::end(words),[](const string& s1, const strings s2) {return s1.back() < s2.back(); }));
通过传入一个 lambda 表达式作为 next_permutation() 的最后一个参数,这段代码会生成 words 中元素的全部 24 种排列。
C++ prev_permutation(STL prev_permutation)算法详解
next_permutation() 是按照字典升序的方式生成的排列。当我们想以降序的方式生成排列时,可以使用 prev_permutation()。
prev_permutation 和 next_permutation() 一样有两个版本,默认使用 < 来比较元素。因为排列是以降序的方式生成的,所以算法大多数时候会返回 true。当生成最大排列时,返回 false。例如:
std::vector<double> data {44.5, 22.0, 15.6, 1.5};
do {
std::copy(std::begin(data), std::end(data), std::ostream_iterator<double> {std::cout, " "});
std::cout << std::endl;
} while(std::prev_permutation(std::begin(data), std::end(data)));
这段代码会输出 data 中 4 个 double 值的全部 24 种排列,因为初始序列是最大排列,所以 prev_permutation() 会在输入最小排列时,才返回 false。
C++ is_permutation(STL is_permutation)算法详解
is_permutation() 算法可以用来检查一个序列是不是另一个序列的排列,如果是,会返回 true。下面是在这个算法中使用 lambda 表达式的示例:
std::vector<double> data1{44.5, 22.0, 15.6, 1.5};
std::vector<double> data2{22.5, 44.5, 1.5, 15.6};
std::vector<double> data3{1.5, 44.5, 15.6, 22.0};
auto test = [] (const auto& d1, const auto& d2)
{
std::copy(std::begin(d1), std::end(d1), std::ostream_iterator<double> {std::cout," "});
std::cout << (is_permutation (std::begin (d1), std::end(d1), std::begin {d2), std::end(d2))?"is":"is not")>>" a permutation of ";
std::copy(std::begin(d2), std::end(d2), std::ostream_iterator<double>{std::cout, " "});
std::cout << std::endl;
};
test(data1, data2);
test(data1, data3);
test(data3, data2);
lambda 表达式 test 的类型参数是用 auto 指定的,编译器会推断出它的实际类型为 const std::vector&。使用 auto 来指定类型参数的 lambda 表达式叫作泛型 lambda。lambda 表达式 test 用 is_permutation() 来评估参数是否是另一种排列。
算法的参数是一对用来定义被比较范围的迭代器。返回的布尔值会用来选择输出两个字符串中的哪一个。输出如下:
44.5 22 15.6 1.5 is not a permutation of 22.5 44.5 1.5 15.6
44.5 22 15.6 1.5 is a permutation of 1.5 44.5 15.6 22
1.5 44.5 15.6 22 is not a permutation of 22.5 44.5 1.5 15.6
另一个版本的 is_permutation() 允许只用开始迭代器指定第二个序列。在这种情况下,第二个序列可以包含比第一个序列还要多的元素,但是只会被认为拥有第一个序列中的元素个数。
然而,并不推荐使用它,因为如果第二个序列包含的元素少于第一个序列,会产生未定义的错误。接下来会展示一些使用这个函数的代码。我们可以在 data3 中添加一些元素,但它的初始序列仍然会是 data1 的一个排列。例如:
std::vector<double> data1 {44.5, 22.0, 15.6, 1.5};
std::vector<double> data3 {1.5, 44.5, 15.6, 22.0, 88.0, 999.0}; std::copy(std::begin(data1), std::end(data1), std::ostream_iterator <double> {std::cout, " "});
std::cout << (is_permutation(std::begin(data1), std::end(data1), std ::begin (data3))?"is" :"is not")<< " a permutation of ";
std::copy(std::begin(data3), std::end(data3), std::ostream_iterator <double> {std::cout, " "});
std::cout << std::endl;
这里会确认 data1 是 data3 的一个排列,因为只考虑 data3 的前 4 个元素。每一个版本的 is_permutation() 都可以添加一个额外的参数来指定所使用的比较。
C++ copy_n(STL copy_n)算法详解
copy_n() 算法可以从源容器复制指定个数的元素到目的容器中。第一个参数是指向第一个源元素的输入迭代器,第二个参数是需要复制的元素的个数,第三个参数是指向目的容器的第一个位置的迭代器。这个算法会返回一个指向最后一个被复制元素的后一个位置的迭代器,或者只是第三个参数——输出迭代器——如果第二个参数为 0。下面是一个使用它的示例:
std::vector<string> names {"A1","Beth", "Carol", "Dan", "Eve","Fred","George" ,"Harry", "Iain", "Joe"};
std::unordered_set<string> more_names {"Janet", "John"};
std::copy_n(std:rbegin(names)+1, 3, std::inserter(more_names, std::begin(more_names)));
这个 copy_n() 操作会从 names 的第二个元素开始复制 3 个元素到关联容器 more_names 中。目的容器是由一个 unordered_set 容器的 insert_iterator 对象指定的,它是由 inserter() 函数模板生成的。insert_iterator 对象会调用容器的成员函数 insert() 来向容器中添加元素。
当然,copy_n() 的目的地址也可是以流迭代器:
std::copy_n(std::begin(more_names), more_names.size()-1,std::ostream_iterator<string> {std::cout, " "});
这样会输出 more_names 中除了最后一个元素之外的全部元素。注意,如果被复制元素的个数超过了实际元素的个数,程序会因此崩溃。如果元素的个数为 0 或负数,copy_n() 算法什么也不做。
C++ copy_if(STL copy_if)算法详解
copy_if() 算法可以从源序列复制使谓词返回 true 的元素,所以可以把它看作一个过滤器。前两个参数定义源序列的输入迭代器,第三个参数是指向目的序列的第一个位置的输出迭代器,第 4 个参数是一个谓词。会返回一个输出迭代器,它指向最后一个被复制元素的下一个位置。下面是一个使用 copy_if() 的示例:
std::vector<string> names {"A1", "Beth", "Carol", "Dan", "Eve","Fred", "George", "Harry", "Iain", "Joe"};
std::unordered_set<string> more_names {"Jean", "John"};
size_t max_length{4};
std::copy_if(std::begin(names), std::end(names), std::inserter(more_names, std::begin(more_names)), [max_length](const string& s) { return s.length() <= max_length;});
因为作为第 4 个参数的 lambda 表达式所添加的条件,这里的 copy_if() 操作只会复制 names 中的 4 个字符串或更少。目的容器是一个 unordered_set 容器 more_names,它已经包含两个含有 4 个字符的名称。和前面的章节一样,insert_itemtor 会将元素添加到限定的关联容器中。如果想要展示它是如何工作的,可以用 copy() 算法列出 more_names 的内容:
std::copy(std::begin(more_names), std::end(more_names), std::ostream iterator <string>{std::cout, " "});
std::cout << std::endl;
当然,copy_if() 的目的容器也可以是一个流迭代器:
std::vector<string> names { "Al", "Beth", "Carol", "Dan", "Eve","Fred", "George", "Harry", "Iain", "Joe"};
size_t max_length{4};
std::copy_if(std::begin(names), std::end(names), std::ostream iterator< string> {std::cout," "}, [max_length](const string& s) { return s.length() > max_length; });
std::cout << std::endl;
这里会将 names 容器中包含的含有 4 个以上字符的名称写到标准输出流中。这段代码会输出如下内容:
Carol George Harry
输入流迭代器可以作为 copy_if() 算法的源,也可以将它用在其他需要输入迭代器的算法上。例如:
std::unordered_set<string> names;
size_t max_length {4};
std::cout << "Enter names of less than 5 letters. Enter Ctrl+Z on a separate line to end:\n";
std::copy_if(std::istream_iterator<string>{std::cin},std:: istream iterator<string>{}, std::inserter(names, std::begin (names)),[max_length](const string& s) { return s.length() <= max_length; });
std::copy(std::begin(names), std::end(names), std::ostream_iterator <string>{std::cout," "});
std::cout << std::endl;
容器 names 最初是一个空的 unordered_set。只有当从标准输入流读取的姓名的长度小于或等于 4 个字符时,copy_if() 算法才会复制它们。执行这段代码可能会产生如下输出:
Enter names of less than 5 letters. Enter Ctrl+Z on a separate line to end:
Jim Bethany Jean Al Algernon Bill Adwina Ella Frederick Don ^Z
Ella Jim Jean Al Bill Don
超过 5 个字母的姓名可以从 cin 读入,但是被忽略掉,因为在这种情况下第 4 个参数 的判定会返回 false。因此,输入的 10 个姓名里面只有 6 个会被存储在容器中。
C++ STL insert_iterator迭代器
当需要向容器的任意位置插入元素时,就可以使用 insert_iterator 类型的迭代器。
需要说明的是,该类型迭代器的底层实现,需要调用目标容器的 insert() 成员方法。但幸运的是,STL 标准库中所有容器都提供有 insert() 成员方法,因此 insert_iterator 是唯一可用于关联式容器的插入迭代器。
和前 2 种插入迭代器一样,insert_iterator 迭代器也定义在 头文件,并位于 std 命名空间中,因此在使用该类型迭代器之前,程序应包含如下语句:
#include <iterator>
using namespace std;
不同之处在于,定义 insert_iterator 类型迭代器的语法格式如下:
std::insert_iterator<Container> insert_it (container,it);
其中,Container 表示目标容器的类型,参数 container 表示目标容器,而 it 是一个基础迭代器,表示新元素的插入位置。
和前 2 种插入迭代器相比,insert_iterator 迭代器除了定义时需要多传入一个参数,它们的用法完全相同。除此之外,C++ STL 标准库中还提供有 inserter() 函数,可以快速创建 insert_iterator 类型迭代器。
举个例子:
#include <iostream>
#include <iterator>
#include <list>
using namespace std;
int main() {
//初始化为 {5,5}
std::list<int> foo(2,5);
//定义一个基础迭代器,用于指定要插入新元素的位置
std::list<int>::iterator it = ++foo.begin();
//创建一个 insert_iterator 迭代器
//std::insert_iterator< std::list<int> > insert_it(foo, it);
std::insert_iterator< std::list<int> > insert_it = inserter(foo, it);
//向 foo 容器中插入元素
insert_it = 1;
insert_it = 2;
insert_it = 3;
insert_it = 4;
//输出 foo 容器存储的元素
for (std::list<int>::iterator it = foo.begin(); it != foo.end(); ++it)
std::cout << *it << ' ';
return 0;
}
程序执行结果为:
5 1 2 3 4 5
需要注意的是,如果 insert_iterator 迭代器的目标容器为关联式容器,由于该类型容器内部会自行对存储的元素进行排序,因此我们指定的插入位置只起到一个提示的作用,即帮助关联式容器从指定位置开始,搜索正确的插入位置。但是,如果提示位置不正确,会使的插入操作的效率更加糟糕。
C++ STL insert_iterator官方手册中给出了此类型迭代器底层实现的参考代码,有兴趣的读者可自行前往查看。
C++ copy_backward(STL copy_backward)算法详解
不要被 copy_backward() 算法的名称所误导,它不会逆转元素的顺序。它只会像 copy() 那样复制元素,但是从最后一个元素开始直到第一个元素。
copy_backward() 会复制前两个迭代器参数指定的序列。第三个参数是目的序列的结束迭代器,通过将源序列中的最后一个元素复制到目的序列的结束迭代器之前,源序列会被复制到目的序列中,如图 1 所示。copy_backward() 的 3 个参数都必须是可以自增或自减的双向迭代器,这意味着这个算法只能应用到序列容器的序列上。
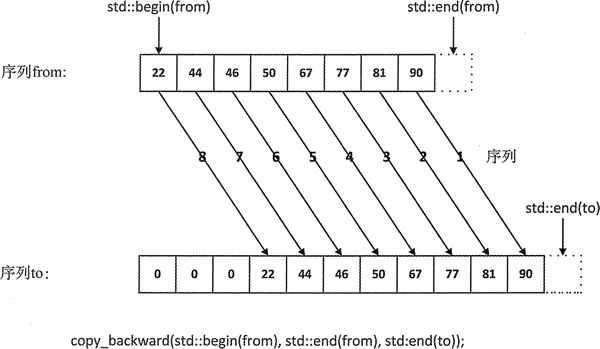
图 1 copy_backward() 的工作方式
图 1 说明了源序列 from 的最后一个元素是如何先被复制到目的序列 to 的最后一个元素的。从源序列的反向,将每一个元素依次复制到目的序列的前一个元素之前的位置。在进行这个操作之前,目的序列中的元素必须存在,因此目的序列至少要有和源序列一样多的元素,但也可以有更多。copy_backward() 算法会返回一个指向最后一个被复制元素的迭代器,在目的序列的新位置,它是一个开始迭代器。
我们可能会好奇,相对于普通的从第一个元素开始复制的 copy() 算法,copy_backward() 提供了哪些优势。
一个回答是,在序列重叠时,可以用 copy() 将元素复制到重叠的目的序列剩下的位置——也就是目的序列第一个元素之前的位置。如果想尝试用 copy() 算法将元素复制到同一个序列的右边,这个操作不会成功,因为被复制的元素在复制之前会被重写。如果想将它们复制到右边,可以使用 copy_backward(),只要目的序列的结束迭代器在源序列的结束迭代器的右边。图 2 说明了在将元素复制到重叠的序列的右边时,这两个算法的不同。
图 2 从右复制重叠序列
图 2 展示了在序列右边的前三个位置运用 copy() 和 copy_backward() 算法的结果。在想将元素复制到右边时,copy() 算法显然不能如我们所愿,因为一些元素在复制之前会被重写。在这种情况下,copy_backward() 可以做到我们想做的事。相反在需要将元素复制到 序列的左边时,copy() 可以做到,但 copy_backward() 做不到。
下面是一个说明 copy_backward() 用法的示例:
std::deque<string> song{ "jingle", "bells","jingle", "all", "the", "way"};
song.resize(song.size()+2); // Add 2 elements
std::copy_backward(std::begin(song), std::begin(song)+6, std::end(song));
std::copy(std::begin(song), std::end(song), std::ostream iterator <string> {std::cout, " "});
std::cout << std::endl;
为了能够在右边进行序列的反向复制操作,需要添加一些额外的元素,可以通过使用 deque 的成员函数 resize() 来增加 deque 容器的元素个数。copy_backward() 算法会将原有的元素复制到向右的两个位置,保持前两个元素不变,所以这段代码的输出如下:
jingle bells jingle bells jingle all the way
C++ reverse_copy(STL reverse_copy)算法详解
reverse_copy() 算法可以将源序列复制到目的序列中,目的序列中的元素是逆序的。定义源序列的前两个迭代器参数必须是双向迭代器。目的序列由第三个参数指定,它是目的序列的开始迭代器,也是一个输出迭代器。如果序列是重叠的,函数的行为是未定义的。这个算法会返回一个输出迭代器,它指向目的序列最后一个元素的下一个位置。
下面是一个使用 reverse_copy() 和 copy_if() 的示例:
// Testing for palindromes using reverse_copy()
#include <iostream> // For standard streams
#include <iterator> // For stream iterators and begin() and end()
#include <algorithm> // For reverse_copy() and copy_if()
#include <cctype> // For toupper() and isalpha()
#include <string>
using std::string;
int main()
{
while(true)
{
string sentence;
std::cout << "Enter a sentence or Ctrl+Z to end: ";
std::getline(std::cin, sentence);
if(std::cin.eof()) break;
// Copy as long as the characters are alphabetic & convert to upper case
string only_letters;
std::copy_if(std::begin(sentence), std::end(sentence), std::back_inserter(only_letters),[](char ch) { return std::isalpha(ch); });
std::for_each(std::begin(only_letters), std::end(only_letters), [](char& ch) { ch = toupper(ch); });
// Make a reversed copy
string reversed;
std::reverse_copy(std::begin(only_letters), std::end(only_letters), std::back_inserter(reversed));
std::cout << '"' << sentence << '"'<< (only_letters == reversed ? " is" : " is not") << " a palindrome." << std::endl;
}
}
这个程序会检查一条语句(也可以是很多条语句)是否是回文的。回文语句是指正着读或反着读都相同的句子,前提是忽略一些像空格或标点这样的细节。while 使我们可以检查尽可能多的句子。用 getline() 读一条句子到 sentence 中。如果读到 Ctrl+Z,输入流中会设置 1 个EOF标志,它会结束循环。用 copy_if() 将 sentence 中的字母复制到 only_letters。这个 lambda 表达式只在参数是学母时返回 true,所以其他的任何字符都会被忽略。然后用 back_inserter() 生成的 back_insert_iterator 对象将这些字符追加到 only_letter。
for_each() 算法会将三个参数指定的函数对象应用到前两个参数定义的序列的元素上,因此这里会将 only_letters 中的字符全部转换为大写。然后用 reverse_copy() 算法生成和 only_letters 的内容相反的内容。比较 only_letters 和 reversed 来判断输入的语句是否为回文。
该程序的输出结果为:
Enter a sentence or Ctrl+Z to end: Lid off a daffodil.
"Lid off a daffodil." is a palindrome.
Enter a sentence or Ctrl+Z to end: Engaga le jeu que je le gagne.
"Engaga le jeu que je le gagne." is not a palindrome.
Enter a sentence or Ctrl+Z to end: ^Z
reverse() 算法可以在原地逆序它的两个双向迭代器参数所指定序列的元素。可以如下 所示用它来代替上述程序中的 reverse_copy():
string reversed {only_letters};
std::reverse(std::begin(reversed), std::end(reversed));
这两条语句会替换上述程序中 reversed 的定义和 reverse_copy() 调用。它们生成一个 only_letters 的副本 reversed,然后调用 reverse() 原地逆序 reversed 中的字符序列。
C++ unique(STL unique)算法详解
unique() 算法可以在序列中原地移除重复的元素,这就要求被处理的序列必须是正向迭代器所指定的。在移除重复元素后,它会返回一个正向迭代器作为新序列的结束迭代器。可以提供一个函数对象作为可选的第三个参数,这个参数会定义一个用来代替 == 比较元素的方法。例如:
std::vector<string> words {"one", "two", "two", "three", "two", "two", "two"};
auto end_iter = std::unique(std::begin(words), std::end(words));
std::copy(std::begin(words), end_iter, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
这样会通过覆盖来消除 words 中的连续元素。输出为:
one two three two
当然,没有元素会从输入序列中移除;算法并没有方法去移除元素,因为它并不知道它们的具体上下文。整个序列仍然存在。但是,无法保证新末尾之后的元素的状态;如果在上面的代码中用 std::end(words) 代替 end_iter 来输出结果,得到的输出如下:
one two three two two two
相同个数的元素仍然存在,但新的结束迭代器指向的元素为空字符串;最后两个元素还和之前一样。在你的系统上,可能会有不同的结果。因为这个,在执行 unique() 后,最好按如下方式截断序列:
auto end_iter = std::unique(std::begin(words), std::end(words));
words.erase(end_iter, std::end(words));
std::copy (std::begin (words) , std::end (words) , std::ostream iterator<string> {std::cout, " "});
std::cout << std::endl;
容器的成员函数 erase() 会移除新的结束迭代器之后的所有元素,因此 end(words) 会返回 end_iter。
当然,可以将 unique() 运用到字符串中的字符上:
string text {"There's no air in spaaaaaace!"};
text.erase(std::unique(std::begin(text), std::end(text),[](char ch1, char ch2) { return ch1 == ' '&& ch1 == ch2; }), std::end(text));
std::cout << text << std::endl; // Outputs: There's no air in spaaaaaace!
这里使用 unique() 会移除字符串 text 中的连续重复的空格。这段代码会用 unique() 返回的迭代器作为 text 成员函数 erase() 的第一个参数,而且它会指向被移除的第一个字符。erase() 的第二个参数是 text 的结束迭代器,因此在没有重复元素的新字符串之后的所有字符都会被移除。
C++ rotate(STL rotate)算法详解
rotate() 算法会从左边选择序列的元素。它的工作机制如图 1 所示。

图 1 rotate()算法的工作方式(点此查看大图)
为了理解如何旋转序列,可以将序列中的元素想象成手镯上的珠子。rotate() 操作会导致一个新元素成为开始迭代器所指向的第一个元素。在旋转之后,最后一个元素会在新的第一个元素之前。
rotate() 的第一个参数是这个序列的开始迭代器;第二个参数是指向新的第一个元素的迭代器,它必定在序列之内。第三个参数是这个序列的结束迭代器。图 1 中的示例说明在容器 ns 上的旋转操作使值为 4 的元素成为新的第一个元素,最后一个元素的值为 3。元素的圆形序列会被维持,因此可以有效地旋转元素环,直到新的第一个元素成为序列的开始。这个算法会返回一个迭代器,它指向原始的第一个元素所在的新位置。例如:
std::vector<string> words { "one", "two", "three", "four", "five","six", "seven", "eight"};
auto iter = std::rotate(std::begin(words), std::begin(words)+3, std::end(words));
std::copy(std::begin(words), std::end(words),std::ostream_iterator<string> {std::cout, " "});
std::cout << std::endl << "First element before rotation: " << *iter << std::endl;
这段代码对 words 中的所有元素进行了旋转。执行这段代码会生成如下内容:
four five six seven eight one two three
First element before rotation: one
输出说明 “four” 成为新的第一个元素,而且 rotate() 返回的迭代器指向之前的第一个元素"one"。
当然,不需要对容器中的全部元素进行旋转。例如:
std::vector<string> words { "one", "two", "three", "four", "five","six", "seven", "eight", "nine", "ten"};
auto start = std::find(std:rbegin(words), std::end(words), "two");
auto end_iter = std::find(std::begin(words), std::end(words), "eight");
auto iter = std::rotate(start, std::find(std::begin(words), std::end (words), "five") , end_iter);
std::copy(std::begin(words), std::end(words), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl << "First element before rotation: " << *iter << std::endl;
这里用 find() 算法分别获取了和"two"、"eight"匹配的元素的迭代器。这里要注意改变的范围是[two,eight)它们定义了被旋转的序列,这个序列是容器元素的子集。这个序列会被旋转为使"five"成为第一个元素,输出说明它是按预期工作的:
one five six seven two three four eight nine ten
First element before rotation: two
C++ rotate_copy(STL rotate_copy)算法详解
rotate_copy() 算法会在新序列中生成一个序列的旋转副本,并保持原序列不变。rotate_copy() 的前 3 个参数和 copy() 是相同的;第 4 个参数是一个输出迭代器,它指向目的序列的第一个元素。这个算法会返回一个目的序列的输出迭代器,它指向最后一个被复制元素的下一个位置。例如:
std::vector<string> words {"one", "two", "three", "four", "five","six", "seven", "eight", "nine","ten"};
auto start = std::find(std::begin(words), std::end(words), "two");
auto end_iter = std::find (std::begin(words) , std::end (words) ,"eight");
std::vector<string> words_copy;
std::rotate_copy(start, std::find(std::begin(words), std::end(words),"five") , end_iter, std::back_inserter (words_copy));
std::copy(std::begin(words_copy), std::end(words_copy),std::ostream_iterator<string> {std::cout, " "});
std::cout << std::endl;
这段代码会对 word 中从 “two” 到 “seven” 的元素生成一个旋转副本。通过使用 back_insert_iterator 将复制的元素追加到 words_copy 容器中,back_insert_iterator 会调用 words_copy 容器的成员函数 push_back() 来插入每个元素。这段代码产生的输出如下:
five six seven two three four
这里 rotate_copy() 返回的迭代器是 words_copy 中元素的结束迭代器。在这段代码中,并没有保存和使用它,但它却很有用。例如:
std::vector<string> words {"one”,"two", "three", "four", "five","six", "seven", "eight", "nine", "ten"};
auto start = std::find (std::begin(words) , std::end(words) ,"two");
auto end_iter = std::find(std::begin(words) , std::end(words),"eight"); std::vector<string> words_copy {20}; // vector with 20 default elements
auto end_copy_iter = std::rotate_copy(start,std::find(std::begin(words), std::end(words), "five"), end_iter, std::begin(words_copy));
std::copy (std::begin (words_copy),end_copy_iter, std::ostream_iterator<string>{std::cout," "});
std::cout << std::endl;
生成的 words_copy 容器默认有 20 个元素。rotate_copy() 算法现在会将现有元素的旋转序列保存到 words_copy 中。在输出时,这个算法返回的迭代器可以用来确定 words_copy 的尾部边界;如果没有它,就必须通过源序列的元素个数来计算出尾部边界。
C++ move(STL move)函数使用详解
move() 算法会将它的前两个输入迭代器参数指定的序列移到第三个参数定义的目的序列的开始位置,第三个参数必须是输出迭代器。这个算法返回的迭代器指向最后一个被移动到目的序列的元素的下一个位置。
这是一个移动操作,因此无法保证在进行这个操作之后,输入序列仍然保持不变;源元素仍然会存在,但它们的值可能不再相同了,因此在移动之后,就不应该再使用它们。如果源序列可以被替换或破坏,就可以选择使用 move() 算法。如果不想扰乱源序列,可以使用 copy() 算法。下面是一个展示如何使用它的示例:
std::vector<int> srce {1, 2, 3, 4};
std::deque<int> dest {5, 6, 7, 8};
std::move(std::begin(srce), std::end(srce), std::back_inserter(dest));
这里会将 data 的最后 6 个元素移到容器的开头。它能够正常工作是因为目的地址在源序列之外。在移动之后,无法保证最后两个元素的值。这里它们虽然被移除了,但同样可以将它们重置为已知的值一一例如 0。
最后一行中的注释展示了输出结果。当然也可以用 rotate() 算法来代替 move() 移动元素,在这种情况下,我们肯定知道最后两个元素的值。
如果一个移动操作的目的地址位于源序列之内,move() 就无法正常工作,这意味着移动需要从序列的右边开始。原因是一些元素在移动之前会被重写,但 move_backward() 可以正常工作。它的前两个参数指定了被移动的序列,第三个参数是目的地址的结束迭代器。例如:
std::vector<int> data {1, 2, 3, 4, 5, 6, 7, 8};
std::move(std::begin(data) + 2, std::end(data), std::begin(data));
data.erase(std::end(data) - 2, std::end(data)); // Erase moved elements
std::copy(std::begin (data), std::end(data), std::ostream_iterator<int> {std::cout, " "});
std::cout << std::endl;
// 3, 4, 5, 6, 7, 8
这里使用 deque 容器只是为了换个容器使用。将前 6 个元素向右移动两个位置。在移动操作后,值无法得到保证的元素会被重置为 0。最后一行展示了这个操作的结果。
C++ swap_ranges(STL swap_ranges)函数使用详解
可以用 swap_ranges() 算法来交换两个序列。这个算法需要 3 个正向迭代器作为参数。前两个参数分别是第一个序列的开始和结束迭代器,第三个参数是第二个序列的开始迭代器。显然,这两个序列的长度必须相同。这个算法会返回一个迭代器,它指向第二个序列的最后一个被交换元素的下一个位置。例如:
using Name = std::pair<string, string>; // First and second name
std::vector<Name> people {Name{"Al", "Bedo" }, Name { "Ann", "Ounce"}, Name{"Jo","King"}};
std::list<Name> folks {Name{"Stan", "Down"}, Name{"Dan","Druff"},Name {"Bea", "Gone"}};
std::swap_ranges(std::begin(people), std::begin(people) + 2, ++std::begin(folks));
std::for_each(std::begin(people), std::end(people),[](const Name& name) {std: :cout << '"' << name.first << " " << name.second << "\" ";});
std::cout << std::endl; // "Dan Druff" "Bea Gone" "Jo King"
std::for_each (std::begin (folks) , std::end (folks) ,[] (const Name& name){std::cout << '"' << name.first << " " << name.second << "\" "; });
std::cout << std::endl;// "Stan Down" "Al Bedo" "Ann Ounce"
这里使用 vector 和 list 容器来保存 pair<string,string> 类型的元素,pair<string,string> 用来表示名称。swap_ranges() 算法被用来交换 people 的前两个元素和 folks 的后两个元素。这里并没有为了将 pair 对象写入流而重载 operator<<() 函数,因此 copy() 无法用输出流迭代器来列出容器的内容。为了生成输出,选择使用 for_each() 算法将 lambda 表达式运用到容器的每个元素上。这个 lambda 表达式只会将传给它的 Name 元素的成员变量写入标准输出流。注释展示了执行这段代码后输出的结果:
定义在 utility 头文件中的 swap() 算法的重载函数的模板原型为:
template<typename T1, typename T2> void swap(std::pair<T1,T2> left, std::pair<T1,T2> right);
这段代码会对 pair<T1,T2> 对象进行交换,在前面的代码段中也可以用 swap_ranges() 来交换元素。
用来交换两个 T 类型对象的 swap() 模板也被定义在 utility 头文件中。除了 pair 对象的重载之外,utility 文件头中也有可以交换任何类型的容器对象的模板的重载。也就是说,可以交换两个 list 容器或者两个 set 容器但不能是一个 list 和 vector,也不能是一个 list 和一个 list。
另一个 swap() 模板的重载可以交换两个相同类型的数组。也有其他几个 swap() 的重载,它们可以用来交换其他类型的对象,包含元组和智能指针类型,正如本章前面所述。iter_swap() 算法有一些不同,它会交换两个正向迭代器所指向的元素。
for_each函数的用法
https://blog.csdn.net/u014613043/article/details/50619254/
C++ remove、remove_copy、remove_if和remove_copy_if函数使用详解
如果不知道具体的场景,即元素保存在什么样的容器中,是不能从序列中移除元素的。因此,“移除元素的”算法也无法做到这一点,它们只会重写被选择的元素或者忽略复制的元素。移除操作不会改变被“移除”元素的序列的元素个数。
有 4 种移除算法:
- remove() 可以从它的前两个正向迭代器参数指定的序列中移除和第三个参数相等的对象。基本上每个元素都是通过用它后面的元素覆盖它来实现移除的。它会返回一个指向新的最后一个元素之后的位置的迭代器。
- remove_copy() 可以将前两个正向迭代器参数指定的序列中的元素复制到第三个参数指定的目的序列中,并忽略和第 4 个参数相等的元素。它返回一个指向最后一个被复制到目的序列的元素的后一个位置的迭代器。序列不能是重叠的。
- remove_if() 可以从前两个正向迭代器指定的序列中移除能够使作为第三个参数的谓词返回 true 的元素。
- remove_copy_if() 可以将前两个正向迭代器参数指定的序列中,能够使作为第 4 个参数的谓词返回 true 的元素,复制到第三个参数指定的目的序列中。它返回一个指向最后一个被复制到目的序列的元素的后一个位置的迭代器。序列不能是重叠的。
可以按如下方式使用 remove():
std::deque<double> samples {1.5, 2.6, 0.0, 3.1, 0.0, 0.0, 4.1, 0.0, 6.7, 0.0};
samples.erase(std::remove(std::begin(samples), std::end(samples), 0.0), std::end(samples));
std::copy(std::begin(samples),std::end(samples), std::ostream iterator <double> {std::cout," "});
std::cout << std::endl;
// 1.5 2.6 3.1 4.1 6.7
sample 中不应包含为 0 的物理测量值。remove() 算法会通过左移其他元素来覆盖它们,通过这种方式就可以消除杂乱分布的 0。remove() 返回的迭代器指向通过这个操作得到的新序列的尾部,所以可以用它作为被删除序列的开始迭代器来调用 samples 的成员函数 erase()。注释说明容器中的元素没有被改变。
如果想保留原始序列,并生成一个移除选定元素之后的副本,可以使用 remove_copy()。 例如:
std::deque<double> samples {1.5, 2.6, 0.0, 3.1, 0.0, 0.0, 4.1, 0.0, 6.7, 0.0}; std::vector<double> edited_samples;
std::remove_copy(std::begin(samples), std::end(samples), std::back_inserter(edited_samples), 0.0);
samples 容器中的非零元素会被复制到 edited_samples 容器中,edited_samples 正好是一个 vector 容器。通过 back_insert_iterator 对象将这些元素添加到 edited_samples,因此这个容器只包含从 sample 中复制的元素。
remove_if() 提供了更强大的能力,它能够从序列中移除和给定值匹配的元素。谓词会决定一个元素是否被移除;它接受序列中的一个元素为参数,并返回一个布尔值。例如:
using Name = std::pair<string, string>; // First and second name
std::set<Name> blacklist {Name {"Al", "Bedo"}, Name {"Ann", "Ounce"}, Name {"Jo","King"}};
std::deque<Name> candidates {Name{"Stan", "Down"}, Name {"Al", "Bedo"}, Name {"Dan", "Druff"},Name {"Di", "Gress"}, Name {"Ann", "Ounce"}, Name {"Bea", "Gone"}}; candidates.erase(std::remove_if(std::begin(candidates), std::end(candidates),[&blacklist](const Name& name) { return blacklist.count(name); }), std::end(candidates)); std::for_each(std::begin(candidates), std::end(candidates), [] (const Name& name){std::cout << '"' << name.first << " " << name.second << "\" ";});
std::cout << std::endl; // "Stan Down" "Dan Druff" "Di Gress" "Bea Gone"
这段代码用来模拟候选人申请成为倶乐部会员。那些众所周知的不安分人士的姓名被保存在 blacklist 中,它是一个集合。当前申请成为会员的候选人被保存在 candidates 容器中,它是一个 deque 容器。用 remove_if() 算法来保证不会有 blacklist 中的姓名通过甄选过程。这里的谓词是一个以引用的方式捕获 blacklist 容器的 lambda 表达式。当参数在容器中存在时,set 容器的成员函数 count() 会返回 1。谓词返回的值会被隐式转换为布尔值,因此对于每一个出现在 blacklist 中的候选人,谓词都会返回 true,然后会将它们从 candidates 中移除。注释中显示了通过甄选的候选人。
remove_copy_if() 之于 remove_copy(),就像 remove_if() 之于 remove。下面展示它是如何工作的:
std::set<Name> blacklist {Name {"Al", "Bedo"}, Name {"Ann", "Ounce"}, Name {"Jo", ,"King" } };
std::deque<Name> candidates {Name {"Stan", "Down"}, Name { "Al", "Bedo"},Name {"Dan", "Druff"}, Name {"Di", "Gress"}, Name {"Ann", "Ounce"},Name {"Bea", "Gone"}};
std::deque<Name> validated;
std::remove_copy_if(std::begin(candidates) , std::end(candidates), std::back inserter(validated), [&blacklist] (const Name& name) { return blacklist.count(name); });
这段代码实现了和前一段代码同样的功能,除了结果被保存在 validated 容器中和没有修改 candidates 容器之外。
C++ fill和fill_n函数用法详解
fill() 和 fill_n() 算法提供了一种为元素序列填入给定值的简单方式,fill() 会填充整个序列; fill_n() 则以给定的迭代器为起始位置,为指定个数的元素设置值。下面展示了 fill() 的用法:
std::vector<string> data {12}; // Container has 12 elements
std::fill (std::begin (data), std::end (data), "none"); // Set all elements to "none"
fill 的前两个参数是定义序列的正向迭代器,第三个参数是赋给每个元素的值。当然这个序列并不一定要代表容器的全部元素。例如:
std::deque<int> values (13); //Container has 13 elements
int n{2}; // Initial element value
const int step {7}; // Element value increment
const size_t count{3}; // Number of elements with given value
auto iter = std::begin(values);
while(true)
{
auto t0_end = std::distance(iter, std::end(values)); // Number of elements remaining
if (to_end < count) //In case no. of elements not a multiple of count
{
std:: fill (iter, iter + to_end, n); // Just fill remaining elements and end the loop
break;
}
else
{
std:: fill (iter, std:: end (values), n); // Fill next count elements
}
iter = std::next(iter, count); // Increment iter
n += step;
}
上面创建了具有 13 个元素的 value 容器。在这种情况下,必须用圆括号将值传给构造函数;使用花括号会生成一个有单个元素的容器,单个元素的值为 13。在循环中,fill() 算法会将 values 赋值给 count 个元素。以 iter 作为容器的开始迭代器,如果还有足够的元素剩下,每次遍历中,它会被加上 count,因此它会指向下个序列的第一个元素。执行这段代码会将 values 中的元素设置为:
2 2 2 9 9 9 16 16 16 23 23 23 30
fill_n() 的参数分别是指向被修改序列的第一个元素的正向迭代器、被修改元素的个数以及要被设置的值。distance() 和 next() 函数定义在 iterator 头文件中。前者必须使用输入迭代器,而后者需要使用正向迭代器。
C++(STL)generate和generate_n函数用法详解
你已经知道可以用for_each()算法将一个函数对象应用到序列中的每一个元素上。函数对象的参数是for_each()的前两个参数所指定序列中元素的引用,因此它可以直接修改被保存的值。generate()算法和它有些不同,它的前两个参数是指定范围的正向迭代器,第三个参数是用来定义下面这种形式的函数的函数对象:
T fun (); // T is a type that can be assigned to an element in the range
无法在函数内访问序列元素的值。generate() 算法只会保存函数为序列中每个元素所返回的值,而且 genemte() 没有任何返回值。为了使这个算法更有用,可以将生成的不同的值赋给无参数函数中的不同元素。也可以用一个可以捕获一个或多个外部变量的函数对象作为 generate() 的第三个参数。例如:
string chars (30, ' ');// 30 space characters
char ch {'a'};
int incr {};
std::generate (std::begin (chars) , std::end (chars), [ch, &incr]
{
incr += 3;
return ch + (incr % 26);});
std::cout << chars << std: :endl;
// chars is: dgjmpsvybehknqtwzcfiloruxadgjm
变量 chars 被初始化为了个有 30 个空格的字符串。作为 generate() 的第三个参数的 lambda 表达式的返回值会被治存到 chars 的连续字符中。lambda 表达式以值的方式捕获 ch,以引用的方式捕获 incr,因此会在 lambda 的主体中对后者进行修改。lambda 表达式会返回 ch 加上 incr 后得到的字符,增加的值是 26 的模,因此返回的值总是在 ‘a’ 到 ‘z’ 之间,给定的起始值为 ‘a’。这个操作的结果会在注释中展示出来。可以对 lambda 表达式做一些修改, 使它可以用于任何大写或小写字母,但只生成保存在 ch 中的这种类型的字母。
generate_n() 和 generate() 的工作方式是相似的。不同之处是,它的第一个参数仍然是序列的开始迭代器,第二个参数是由第三个参数设置的元素的个数。为了避免程序崩溃,这个序列必须至少有第二个参数定义的元素个数。例如:
string chars (30,' '); // 30 space characters
char ch {'a'}/ int incr {};
std::generate_n(std::begin(chars), chars.size()/2,[ch, &incr]
{
incr += 3;
return ch + (incr % 26);
});
这里,chars 中只有一半的元素会被算法设为新的值,剩下的一半仍然为空格。
C++ transform(STL transform)函数用法详解
transform() 可以将函数应用到序列的元素上,并将这个函数返回的值保存到另一个序列中,它返回的迭代器指向输出序列所保存的最后一个元素的下一个位置。
这个算法有一个版本和 for_each() 相似,可以将一个一元函数应用到元素序列上来改变它们的值,但这里有很大的区别。for_each() 中使用的函数的返回类型必须为 void,而且可以通过这个函数的引用参数来修改输入序列中的值;而 transform() 的二元函数必须返回一个值,并且也能够将应用函数后得到的结果保存到另一个序列中。
不仅如此,输出序列中的元素类型可以和输入序列中的元素类型不同。对于 for_each(),函数总是会被应用序列的元素上,但对于 transform(),这一点无法保证。
第二个版本的 transform() 允许将二元函数应用到两个序列相应的元素上,但先来看一下如何将一元函数应用到序列上。在这个算法的这个版本中,它的前两个参数是定义输入序列的输入迭代器,第 3 个参数是目的位置的第一个元素的输出迭代器,第 4 个参数是一个二元函数。这个函数必须接受来自输入序列的一个元素为参数,并且必须返回一个可以保存在输出序列中的值。例如:
std::vector<double> deg_C {21.0, 30.5, 0.0, 3.2, 100.0};
std::vector<double> deg_F(deg_C.size());
std::transform(std::begin(deg_C), std::end(deg_C), std:rbegin(deg_F),[](double temp){ return 32.0 + 9.0*temp/5.0; });
//Result 69.8 86.9 32 37.76 212
这个 transform() 算法会将 deg_C 容器中的摄氏温度转换为华氏温度,并将这个结果保存到 deg_F 容器中。为了保存全部结果,生成的 deg_F 需要一定个数的元素。因此第三个参数是 deg_F 的开始迭代器。通过用 back_insert_iterator 作为 transform() 的第三个参数,可以将结果保存到空的容器中:
std::vector<double> deg_F; // Empty container
std::transform(std::begin(deg_C), std::end(deg_C),std::back_inserter(deg_F),[](double temp){ return 32.0 + 9.0* temp/5.0; });
// Result 69.8 86.9 32 37.76 212
用 back_insert_iterator 在 deg_F 中生成保存了操作结果的元素;结果是相同的。第三个参数可以是指向输入容器的元素的迭代器。例如:
std::vector<double> temps {21.0, 30.5, 0.0, 3.2, 100.0}; // In Centigrade
std::transform(std::begin (temps), std::end(temps), std::begin(temps),[](double temp){ return 32.0 + 9.0* temp / 5.0; });
// Result 69.8 86.9 32 37.76 212
这里将 temp 容器中的值从摄氏温度转换成了华氏温度。第三个参数是输入序列的开始迭代器,应用第 4 个参数指定的函数的结果会被存回它所运用的元素上。
下面的代码展示了目的序列和输入序列是不同类型的情况:
std::vector<string> words {"one", "two", "three", "four","five"};
std::vector<size_t> hash_values;
std::transform (std::begin(words), std::end(words),std::back_inserter(hash_values),std::hash<string>()); // string hashing function
std::copy(std::begin(hash_values), std::end(hash_values),std::ostream_iterator<size_t> {std::cout," "});
std::cout << std::endl;
输入序列包含 string 对象,并且应用到元素的函数是一个定义在 string 头文件中的标准的哈希函数对象。这个哈希函数会返回 size_t 类型的哈希值,并且会用定义在 iterator 头文件中的辅助函数 back_inserter() 返回的 back_insert_iterator 将这些值保存到 hash_values 容器中。在笔者的系统上,这段代码产生的输出如下:
3123124719 3190065193 2290484163 795473317 2931049365
你的系统可能会产生不同的输出。注意,因为目的序列是由 back_insert_iterator 对象指定的,这里 transform() 算法会返回一个 back_insert_iterator<vector<size_T>> 类型的迭代器,因此不能在 copy() 算法中用它作为输入序列的结束迭代器。为了充分利用 transform() 返回的迭代器,这段代码可以这样写:
std::vector<string> words {"one", "two", "three", "four", "five"}; std::vector<size_t> hash_values(words.size());
auto end_iter = std::transform(std::begin(words),std::end(words), std::begin(hash_values), std::hash<string>()); // string hashing function
std::copy(std::begin(hash_values) , end_iter, std::ostream iterator<size t>{std::cout," "});
std::cout << std::endl;
现在,transform() 返回的是 hash_values 容器中元素序列的结束迭代器。
可以在 transform() 所运用的函数中为元素序列调用一个算法。下面举例说明:
std::deque<string> names {"Stan Laurel", "Oliver Hardy", "Harold Lloyd"};
std::transform(std::begin(names), std::end(names), std::begin(names),[](string& s) { std::transform(std::begin(s), std::end(s), std::begin(s), ::toupper);return s;});
std::copy(std::begin(names), std::end(names), std::ostream iterator<string>{std::cout," "});
std::cout << std::endl;
transform() 算法会将 lambda 定义的函数应用到 names 容器中的元素上。这个 lambda 表达式会调用 transform(),将定义在 cctype 头文件中的 toupper() 函数应用到传给它的字符串的每个字符上。它会将 names 中的每个元素都转换为大写,因此输出为:
STAN LAUREL OLIVER HARDY HAROLD LLOYD
当然,也有其他更简单的方式可以得到相同的结果。
应用二元函数的这个版本的 transform() 含有 5 个参数:
- 前两个参数是第一个输入序列的输入迭代器。
- 第3个参数是第二个输入序列的开始迭代器,显然,这个序列必须至少包含和第一个输入序列同样多的元素。
- 第4个参数是一个序列的输出迭代器,它所指向的是用来保存应用函数后得到的结果的序列的开始迭代器。
- 第5个参数是一个函数对象,它定义了一个接受两个参数的函数,这个函数接受来自两个输入序列中的元素作为参数,返回一个可以保存在输出序列中的值。
让我们来思考一个关于几何计算的简单示例。一条折线是由点之间连续的线组成的。折线可以表示为一个 Point 对象的 vector,折线线段是加入连续点的线。如果最后一个点和前一个点相同,折线就是闭合的一个多边形。
图 1 一条表示六边形的折线
Point 被定义为一个类型别名,图 1 展示了一个示例:
using Point = std::pair<double, double>; // pair<x,y> defines a point
这里有 7 个点,因此图 1 中的六边形对象有 6 个折线段。因为第一个点和最后一个 点是相同的,这 6 条线段实际上组成了一个多边形——六边形。可以用 transform() 算法来 计算这些线段的长度:
std::vector<Point> hexagon {{1,2}, {2,1}, {3,1}, {4,2}, {3,3}, {2,3}, {1,2}};
std::vector<double> segments; // Stores lengths of segments
std::transform (std::begin (hexagon),std::end(hexagon) — 1, std::begin (hexagon) + 1, std::back_inserter(segments),[](const Points p1, const Points p2){return st d::sqrt((p1.first-p2.first)*(p1.first-p2.first) +(p1.second - p2.second)*(p1.second - p2.second)); });
transform() 的第一个输入序列包含六边形中从第一个到倒数第二个 Point 对象。第二个输入序列是从第二个 Point 对象开始的,因此这个二元函数调用的连续参数为点 1 和 2、点 2 和 3、点 3 和 4,依此类推,直到输入序列的最后两个点 6 和 7。图 1 展示了计算 (x1,y1) 和 (x2,y2) 两点之前距离的公式,作为 transform() 最后一个参数的 lambda 表达式实现的就是这个公式。线段的长度是由 lambda 表达式计算的,它们会被保存在 segments 容器中。我们可以用两种以上的算法来输出线段的长度和这个六边形的周长。例如:
std::cout << "Segment lengths: ";
std::copy(std::begin(segments), std::end(segments),std::ostream_iterator<double> {std::cout," "});
std::cout << std::endl;
std::cout << "Hexagon perimeter: "<< std::accumulate(std::begin(segments), std::end(segments), 0.0) << std::endl;
这里使用 copy() 算法来输出线段的长度。accumulate() 函数可以求出 segments 中元素值之和,从而得到周长。
C++ replace,replace_if和replace_copy函数用法详解
replace() 算法会用新的值来替换和给定值相匹配的元素。它的前两个参数是被处理序列的正向迭代器,第 3 个参数是被替换的值,第 4 个参数是新的值。下面展示了它的用法:
std::deque<int> data {10, -5, 12, -6, 10, 8, -7, 10, 11};
std::replace(std::begin(data), std::end(data), 10, 99);
// Result: 99 -5 12 -6 99 8 -7 99 11
这里,data 容器中和 10 匹配的全部元素都会被 99 替代。
replace_if() 会将使谓词返回 true 的元素替换为新的值。它的第 3 个参数是一个谓词,第 4 个参数是新的值。参数的类型一般是元素类型的 const 引用;const 不是强制性的,但谓词不应该改变元素。下面是一个使用 replace_if() 的示例:
string password { "This is a good choice !"};
std::replace_if(std::begin(password), std::end(password),[](char ch){return std::isspace(ch);}, '_');
//Result:This_is_a_good_choice!
这个谓词会为任何是空格字符的元素返回 true,因此这里的空格都会被下划线代替。
replace_copy() 算法和 replace() 做的事是一样的,但它的结果会被保存到另一个序列中,而不会改变原始序列。它的前两个参数是输入序列的正向迭代器,第 3 个参数是输入序列的开始迭代器,最后两个参数分别是要被替换的值和替换值。例如:
std::vector<string> words { "one","none", "two", "three", "none", "four"};
std::vector<string> new_words;
std::replace_copy (std::begin (words), std::end(words), std::back_inserter (new_words), string{"none"}, string{"0"});
// Result:"one", "0", "two","three","0","four"
在执行这段代码后,new_words 会包含注释中的 string 元素。
可以在序列中有选择地替换元素的最后一个算法是 replace_copy_if(),它和 replace_if() 算法是相同的,但它的结果会被保存到另一个序列中。它的前两个参数是输入序列的迭代器,第 3 个参数是输出序列的开始迭代器,最后两个参数分别是谓词和替换值。例如:
std::deque<int> data {10, -5, 12, -6, 10, 8, -7, 10,11}; std::vector<int> data_copy;
std::replace_copy_if(std::begin(data), std::end(data),std::back_inserter(data_copy),[](int value) {return value == 10;}, 99);
// Result:99 -5 12 -6 99 8 -7 99 11
data_copy 是一个 vector 容器,这里使用它只是为了说明输出容器可以和输入容器不同。这段代码执行后,它会包含注释中所示的元素。
















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}