







最前面的话
因为spark的源语言是scala,所以,为了看懂spark的操作并且为了以后看spark源码做准备,先看scala还是很有必要的。另外这里主要是看的周志湖大神的博客里的scala教程
http://blog.csdn.net/lovehuangjiaju/article/category/5664003
后来好像又出了一本相关的书,这链接里都有。主要还是做个笔记,总结一下scala的主要特性,为spark编程做准备
第一节 入门
balalbala一通,就是告诉你scala有多棒,是spark的开发语言,以后处理大数据很好用之类的。
然后就是一些及其入门性的代码比如
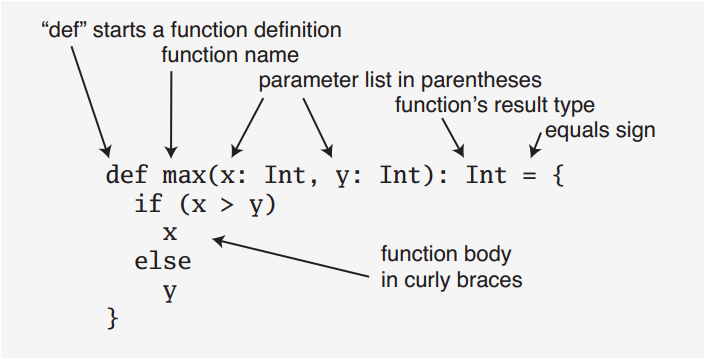
scala> val helloString="Hello World"
helloString: String = Hello World之类(真-)入门代码。之后介绍了scala标准的函数结构(当然以后会讲省略形式),这个hin重要,不过习惯了就好。
ps:一直困扰我的问题,就是在linux下如何执行scala脚本,这个问题直到三十节才说。。。。把下面的内容,保存成某个.sh文件(比如hello.sh)
#!/bin/sh
exec scala "$0" "$@"
!#
println("HellO,Linux World")然后到保存的目录下面给它增加权限和运行它就行了。特别是那些带main函数做入口的,运行就可以了。(不得不说,还是IDE省事啊)
root@sparkmaster:/home/zhouzhihu/scalaLearning# chmod +x hello.sh
root@sparkmaster:/home/zhouzhihu/scalaLearning# ./hello.sh
HellO,Linux World第二节
没什么难点,讲了scala主要数据类型,操作(加减乘除之类的),以及if else 循环之类的。
第三节 Array、List
Array和List的操作,也是普通得一批
第四节 Set、Map、Tuple、队列
有两种,一种是可变集合另一种是不可变集合;可变集合可以随便玩,不可变集合创建了就不能动了,动的话返回的是新的集合。
Set是酱婶儿的
scala> val set=Set(3,5)Map呢是酱的
scala> val map=Map("john" -> 21, "stephen" -> 22,"lucy" -> 20)Tuple是这样
//当然里面可以有不同类型的元素
scala> ("hello","china","beijing")还有队列和栈
scala> var queue=scala.collection.immutable.Queue(1,2,3)
//别忘了 import scala.collection.mutable.Stack
scala> val stack = new Stack[Int]第五节 函数与闭包
讲了将近十种写函数的方法,对,我是本地人,我有一百种方法写这个函数。
scala> val increase=(x:Int)=>x+1
//前面的语句等同于
scala> def increaseAnother(x:Int)=x+1
val increase2=(x:Int)=>{
println("Xue")
println("Tu")
println("Wu")
println("You")
x+1
}a
//数组的map方法中调用(写法1)
scala> println(Array(1,2,3,4).map(increase).mkString(","))
//匿名函数写法(写法2)
scala>println(Array(1,2,3,4).map((x:Int)=>x+1).mkString(","))
//花括方式(写法3)
scala> Array(1,2,3,4).map{(x:Int)=>x+1}.mkString(",")
//省略.的方式(写法4)
scala> Array(1,2,3,4) map{(x:Int)=>x+1} mkString(",")
//参数类型推断写法(写法5)
scala> Array(1,2,3,4) map{(x)=>x+1} mkString(",")
//函数只有一个参数的话,可以省略()(写法6)
scala> Array(1,2,3,4) map{x=>x+1} mkString(",")
//如果参数右边只出现一次,则可以进一步简化(写法7)
scala> Array(1,2,3,4) map{_+1} mkString(",")
//val fun0=1+_,该定义方式不合法,因为无法进行类型推断
scala> val fun0=1+_
//值函数简化方式(正确方式)
scala> val fun1=1+(_:Double)
//值函数简化方式(正确方式2)
scala> val fun2:(Double)=>Double=1+_另外还有闭包,好像就是在函数里定义了一个未知的变量,等什么时候要用的时候再赋值。
scala> var more=1
more: Int = 1
scala>val fun=(x:Int)=>x+more
fun: Int => Int = <function1>第六七节 类和对象
类的定义和对象的生成基本和java没什么区别,还有访问权限之类的下图十分明确了
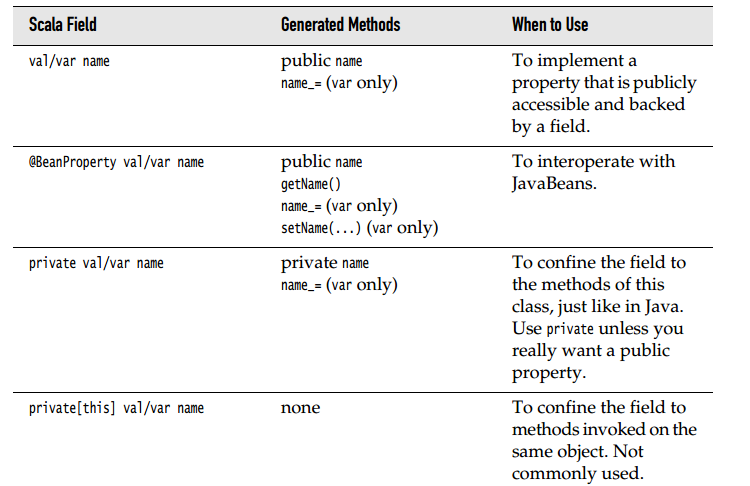
之后讲了主构造器和辅构造器。主构造器就相当于构造函数,辅构造器就是下面这个意思~
//禁用主构造函数
class Person private(var name:String,var age:Int){
//类成员
private var sex:Int=0
//辅助构造器
def this(name:String,age:Int,sex:Int){
this(name,age)
this.sex=sex
}
}第八节 包和引入
就是普通包的建立,还有个比较有趣的就是当引入的类重名时
import java.util.{ HashMap => JavaHashMap }
//或者隐藏
import java.util.{HashMap=> _,_}第九节 继承与组合
和java差不多
第十/十一节 Trait
Trait就是接口,还能有成员和方法的实现(简直就是多继承了),除了不能有带参数的构造器之外和类一模一样。
另外又讲了self type
trait X{
}
class B{
//self:X => 要求B在实例化时或定义B的子类时
//必须混入指定的X类型,这个X类型也可以指定为当前类型
self:X=>
}第十三节 高阶函数
这节看起来很用的样子,就是传进来的参数也是函数或者返回值也是函数,然后还能进行柯里化,就是弄成俩括号的样子。
第十四/五节 case class与模式匹配
模式匹配就是什么match case之类的,而这里定义了case class就不用new就可以新建类,还能把case class放到模式匹配里来匹配
第十六节 泛型与注解
泛型就是泛型,注解就是注解啊
第十七节 就是类的大于小于
有好几个方法 <:和:>















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









