







Redis如何实现快速恢复?(二:内存快照ROB)
对 Redis来说,它实现类似照片记录效果的方式,就是把某一时刻的状态以文件的形式写到磁盘上,也就是快照。这样一来,即使宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。这个快照文件就称为
RDB 文件,其中,RDB 就是 Redis DataBase 的缩写。和 AOF 相比,RDB
记录的是某一时刻的数据,并不是操作,所以,在做数据恢复时,我们可以直接把 RDB 文件读入内存,很快地完成恢复。
- 对哪些数据做快照?这关系到快照的执行效率问题;
- 做快照时,数据还能被增删改吗?这关系到 Redis 是否被阻塞,能否同时正常处理请求。
全量快照:Redis 的数据都在内存中,为了提供所有数据的可靠性保证,它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中.
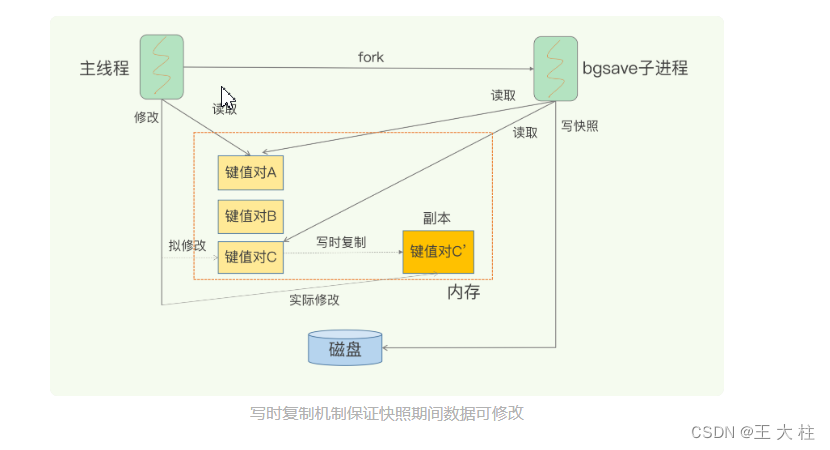
- Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。
- save:在主线程中执行,会导致阻塞;
- bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。
快照时数据能修改吗? No

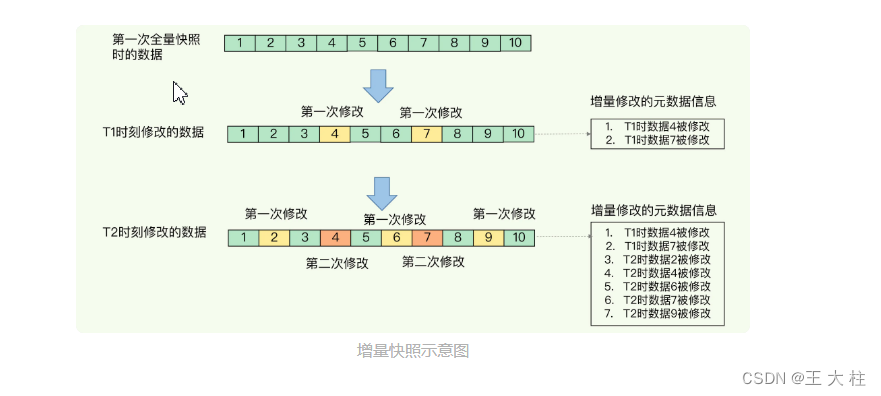
- 增量快照,所谓增量快照,就是指,做了一次全量快照后,后续的快照只对修改的数据进行快照记录,这样可以避免每次全量快照的开销。在第一次做完全量快照后,T1 和 T2 时刻如果再做快照,我们只需要将被修改的数据写入快照文件就行。但是,这么做的前提是,我们需要记住哪些数据被修改了;
- 但是,有的时候,键值对非常小,比如只有 32 字节,而记录它被修改的元数据信息,可能就需要 8 字节,这样的画,为了“记住”修改,引入的额外空间开销比较大。这对于内存资源宝贵的 Redis 来说,有些得不偿失;
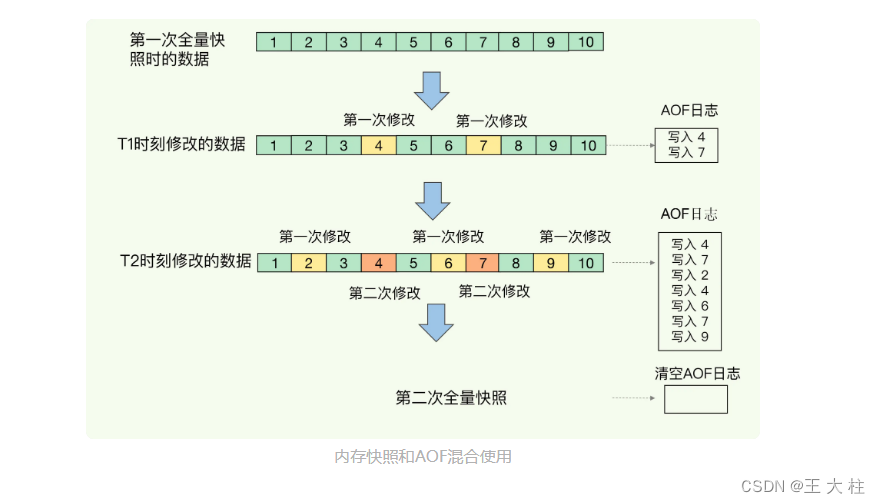
- Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法
简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。如下图所示,T1 和 T2 时刻的修改,用 AOF 日志记录,等到第二次做全量快照时,就可以清空 AOF 日志,因为此时的修改都已经记录到快照中了,恢复时就不再用日志了。
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择;
- 如果允许分钟级别的数据丢失,可以只使用 RDB;
- 如果只用 AOF,优先使用everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
场景:读比例为8:2,此时做RDB持久化,产生的风险?
主要在于 CPU资源 和 内存资源 这2方面:
a、内存资源风险:Redis fork子进程做RDB持久化,由于写的比例为80%,那么在持久化过程中,“写实复制”会重新分配整个实例80%的内存副本,大约需要重新分配1.6GB内存空间,这样整个系统的内存使用接近饱和,如果此时父进程又有大量新key写入,很快机器内存就会被吃光,如果机器开启了Swap机制,那么Redis会有一部分数据被换到磁盘上,当Redis访问这部分在磁盘上的数据时,性能会急剧下降,已经达不到高性能的标准(可以理解为武功被废)。如果机器没有开启Swap,会直接触发OOM,父子进程会面临被系统kill掉的风险。
b、CPU资源风险:虽然子进程在做RDB持久化,但生成RDB快照过程会消耗大量的CPU资源,虽然Redis处理处理请求是单线程的,但Redis Server还有其他线程在后台工作,例如AOF每秒刷盘、异步关闭文件描述符这些操作。由于机器只有2核CPU,这也就意味着父进程占用了超过一半的CPU资源,此时子进程做RDB持久化,可能会产生CPU竞争,导致的结果就是父进程处理请求延迟增大,子进程生成RDB快照的时间也会变长,整个Redis Server性能下降。
c、另外,可以再延伸一下,老师的问题没有提到Redis进程是否绑定了CPU,如果绑定了CPU,那么子进程会继承父进程的CPU亲和性属性,子进程必然会与父进程争夺同一个CPU资源,整个Redis Server的性能必然会受到影响!所以如果Redis需要开启定时RDB和AOF重写,进程一定不要绑定CPU。















 2308
2308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









