







使用ip代理服务器可以防止在爬虫时被封本机ip。国内免费的高匿代理可以选择西刺网
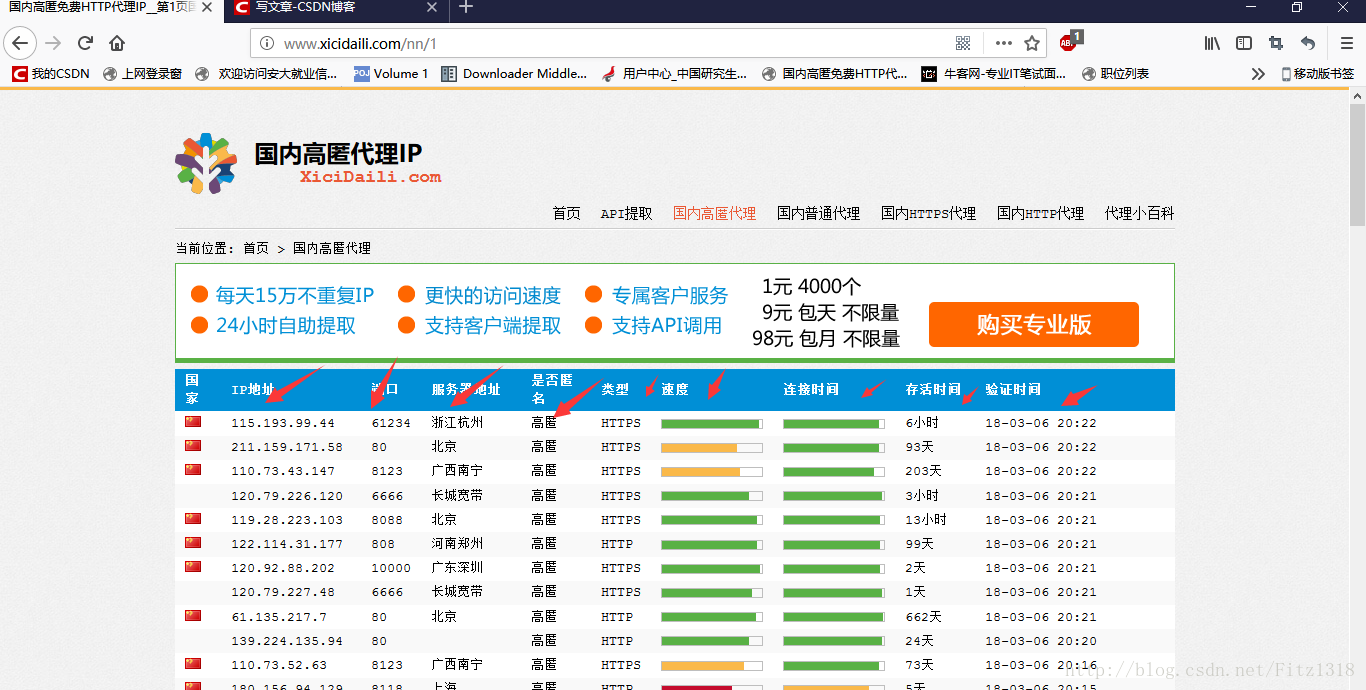
总体目标是写一个爬虫,将这些字段保存在数据库中,然后筛选速度快的作为代理服务器,实现ip代理池。
在这里使用requests库来实现。代码如下
import requests
def crawl_ips():
#爬取西刺的免费高匿IP代理
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"}
re = requests.get("http://www.xicidaili.com/nn", headers = headers)
print(re.text)
print(crawl_ips())
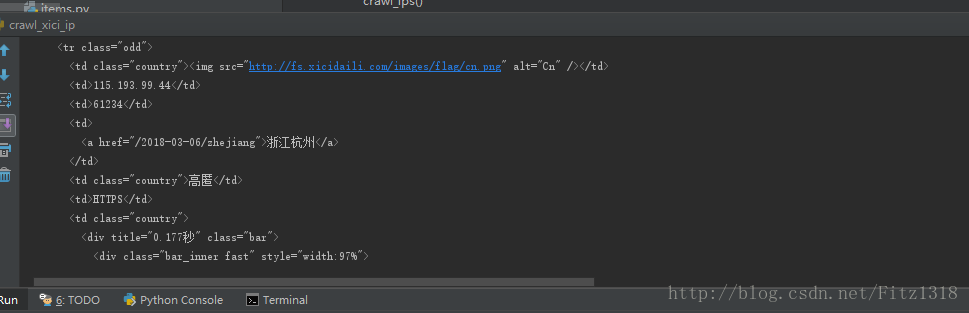
发现可以爬取到,接下来就是对爬到的数据进行解析入库。
打开web控制台
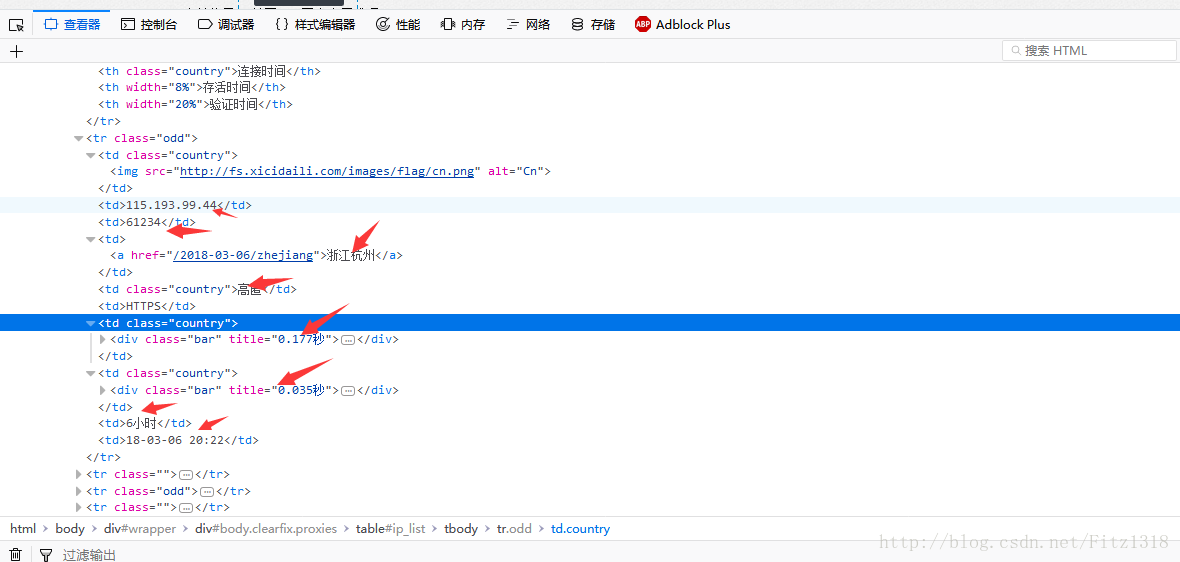
import requests
from scrapy.selector import Selector
def crawl_ips():
#爬取西刺的免费高匿IP代理
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"}
re = requests.get("http://www.xicidaili.com/nn", headers = headers)
selector = Selector(text=re.text)
all_trs = selector.css("#ip_list tr")
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
print(all_texts)
print(crawl_ips())打断点测试
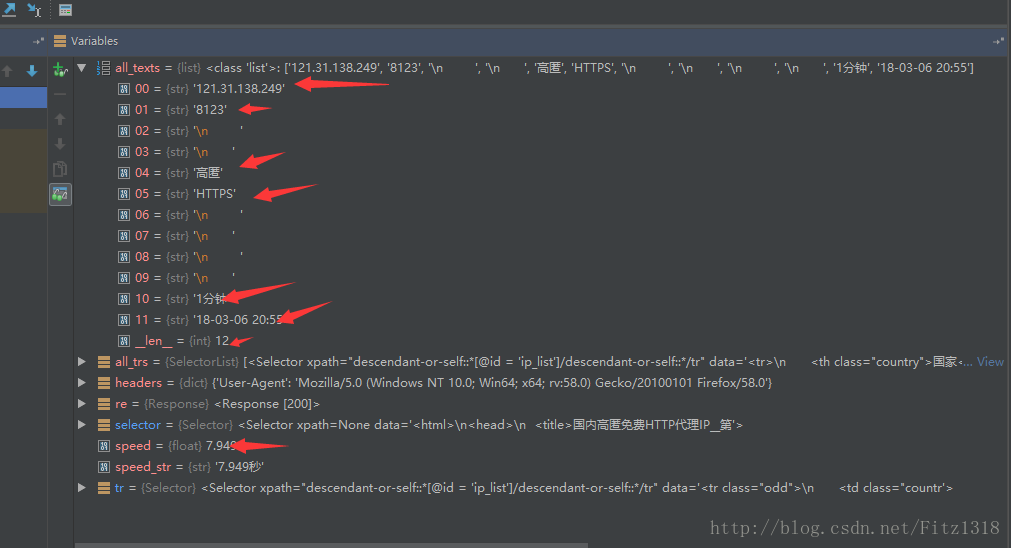
然后根据这个提取。
代码如下
import requests
import re
from scrapy.selector import Selector
def crawl_ips():
#爬取西刺的免费高匿IP代理
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"}
for i in range(1568):
res = requests.get(
"http://www.xicidaili.com/nn/{0}".format(i),
headers=headers)
selector = Selector(text=res.text)
all_trs = selector.css("#ip_list tr")
ip_list = []
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
match_obj1 = re.match(".*'HTTPS'.*", str(all_texts))
match_obj2 = re.match(".*'HTTP'.*", str(all_texts))
proxy_type = ""
if match_obj1:
proxy_type = "HTTPS"
elif match_obj2:
proxy_type = "HTTP"
ip = all_texts[0]
port = all_texts[1]
ip_list.append((ip, port, proxy_type, speed))
print(ip_list)
print(crawl_ips())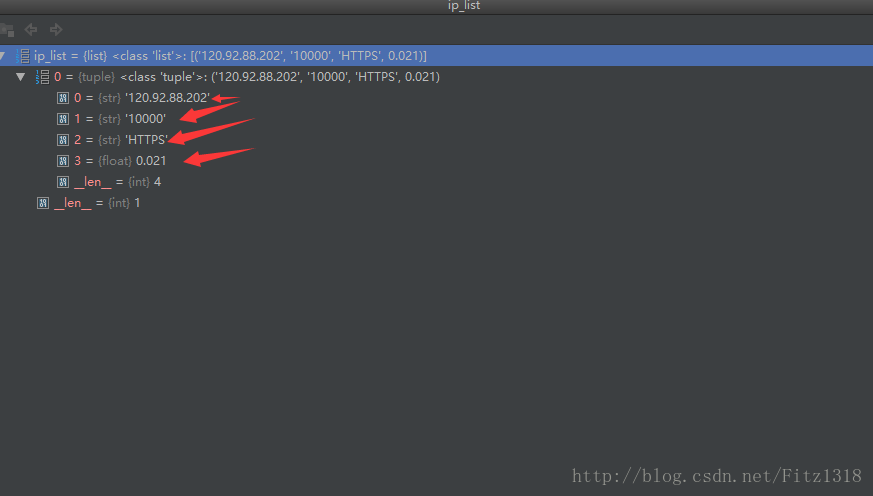
接下来就是将这些数据存储到数据库中。代码如下
import re
import requests
from scrapy.selector import Selector
import MySQLdb
conn = MySQLdb.connect(
host="localhost",
user="root",
passwd="1234",
db="jobbole",
charset="utf8")
cursor = conn.cursor()
def crawl_ips():
# 爬取西刺的免费ip代理
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"}
for i in range(1568):
res = requests.get(
"http://www.xicidaili.com/nn/{0}".format(i),
headers=headers)
selector = Selector(text=res.text)
all_trs = selector.css("#ip_list tr")
ip_list = []
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
match_obj1 = re.match(".*'HTTPS'.*", str(all_texts))
match_obj2 = re.match(".*'HTTP'.*", str(all_texts))
proxy_type = ""
if match_obj1:
proxy_type = "HTTPS"
elif match_obj2:
proxy_type = "HTTP"
ip = all_texts[0]
port = all_texts[1]
ip_list.append((ip, port, proxy_type, speed))
for ip_info in ip_list:
cursor.execute(
"insert xici(ip, port, speed, proxy_type) VALUES('{0}', '{1}', {2}, '{3}')".format(
ip_info[0], ip_info[1], ip_info[3], ip_info[2]))
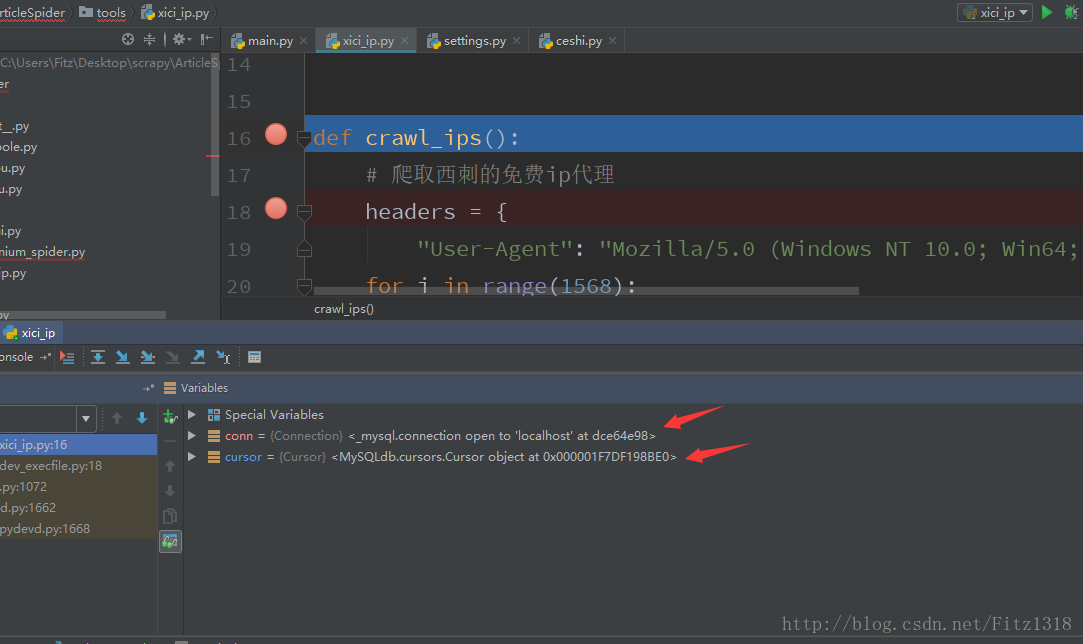
conn.commit()可是问题来了,如下图所示,数据库连接成功了,可是却进不去def crawl_ips()这个函数里面。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









