







来自多个渠道整理而成,均在内容前面对来源进行了标记说明。
本部分来自公众号 软件测试面试汇总

select e.Emp_id,e.Emp_name,e.Dept_id FROM emp e LEFT JOIN dept d on e.Dept_id=d.Dept_id请编写SQL语句:
1)创建一张学生表,包含以下信息,学号,姓名,年龄,性别,家庭住址,联系电话
CREATE TABLE Student(
s_id int(5),
s_name VARCHAR(20),
s_age INT(3),
s_sex char(2),
s_address VARCHAR(20),
s_phone char(11)
)2)修改学生表的结构,添加一列信息,学历
alter TABLE Student add s_ed VARCHAR(10);3)修改学生表结构,删除一列信息,家庭住址
ALTER TABLE Student DROP COLUMN s_address;4)向学生表添加如下信息: 学号 姓名 年龄 性别 联系电话 学历
1A22男123456小学;2B21男119中学;3C23男110高中;4D18女114大学
INSERT into Student VALUES(1,'A',22,'男','123456','小学');
INSERT into Student VALUES(2,'B',21,'男','119','中学');
INSERT into Student VALUES(3,'C',23,'男','110','高中');
INSERT into Student VALUES(4,'B',18,'女','114','大学');5)修改学生表的数据,将电话号码以11开头的学员的学历改为“大专‘’
UPDATE Student SET s_ed='大专' WHERE s_phone like '11%';6)删除学生表的数据,姓名以C开头,性别为“男”的记录删除
DELETE FROM Student where s_sex='男' and s_name like 'C%';7)查询学生表的数据,将所有年龄小于22岁的,学历为“’大专”的,学生的姓名和学号示出来
SELECT s_name,s_id FROM Student WHERE s_sex < 22 and s_ed='大专';设计题:已知教学数据库包含三个关系:学生关系S(SND,SNAME,SA,SD)课程关系C(CNO,CN,TNAME),选课关系SC(SNO,CNO,G)其中,下划线的字段为该关系的码,SNO代表学号,SNAME代表学生姓名,SA代表学生年龄,SD代表学生所在系,CNO代表课程号,CN代表课程名,TNAME代表任课老师姓名,G代表成绩,请用SQL语句实现:
1、简历学生关系和选课关系,有完整约束的要定义完整性约束
CREATE TABLE S(
SNO INT(10) not null PRIMARY KEY,-- 学号
SNAME VARCHAR(20) not null,-- 姓名
SAINT(3),-- 年龄
SD VARCHAR(10)-- 所在系
)
CREATE TABLE C(
CNO INT(10) not null PRIMARY KEY,-- 课程号
CN VARCHAR(20) UNIQUE , -- 课程名
TNAMEINT(3) not null-- 任课老师
)
CREATE TABLE SC(
SNO INT(10),-- 学号
CNO VARCHAR(20), -- 课程号
GINT(3),-- 成绩
FOREIGN KEY (SNO) REFERENCES S(SNO),
FOREIGN KEY (CNO) REFERENCES C(CNO)
)2、将下列学生信息插入学生关系中:李丹,18岁,电信系,学号:20070206
INSERT into S(SNO,SNAME,SD) VALUES(20070206,'李丹','电信系');3、找出选修了课程为“112002”的学生学号和姓名
SELECT S.SNO,S.SNAME FROM S S,SC C where S.SNO=C.SNO AND C.CNO='112002';4、修改学号为“20070206”的学生所在的系为计算机
UPDATE S SET SD='计算机' WHERE SNO='20070206'5、 查询选修了数据库系统原理 这门课的学生的姓名和成绩
SELECT S.SNAME,C.G FROM S S,SC C where S.SNO=C.SNO;本部分来自公众号 编测编学0基础软件测试训练营

第一题参考答案:
select * from Laagent where Sex=0 and EmployDate >'2003-11-02' order by Agentcode desc;第二题参考答案:
update Laagent set State='01' where Agentcode in (select Agentcode from LaTree where StartDate >'2003-01-01');第三题参考答案:
union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;union all:对两个结果集进行并集操作,包括重复行,不进行排序;
本部分内容来自公众号DB宝
Q
题目如下所示:
Linux文件的三种时间(mtime、atime、ctime)的区别是什么?
A
答案如下所示:
在Windows下,一个文件有:创建时间、修改时间、访问时间,而在Linux下,一个文件也有三种时间,分别是:访问时间、修改时间、状态时间。在Linux中,文件是没有创建时间的,只是如果刚刚创建一个文件,毋庸置疑它的三个时间是都等于创建时间的。下面分别介绍这3种时间状态:
l 修改时间(mtime,Modify time):文件的内容被最后一次修改的时间,“ls -l”命令显示出来的文件时间就是这个时间,当用vim对文件进行编辑之后保存,它的mtime就会相应的改变;
l 访问时间(atime,Access time):对文件进行一次读操作,它的访问时间就会改变。例如:cat、more等操作,但是stat、ls命令对atime是不会有影响的;
l 状态时间(ctime,Change time):当文件的状态被改变的时候,状态时间就会随之改变,例如当使用chmod、chown等命令改变文件属性时,ctime就会变动。
可以使用stat命令查看文件的mtime、atime、ctime属性,也可以通过ls命令来查看,具体如下:
ls -lc filename #列出文件的ctime
ls -lu filename #列出文件的atime
ls -l filename #列出文件的mtime
以下示例是查看a.txt文件的属性:
[root@rhel6lhr adump]# stat a.txt
File: `a.txt'
Size: 2 Blocks: 8 IO Block: 4096 regular file
Device: fd07h/64775d Inode: 278405 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-08-22 18:03:35.432369855 +0800
Modify: 2017-08-22 18:04:05.602610124 +0800
Change: 2017-08-22 18:04:05.602610124 +0800
[root@rhel6lhr adump]# ls -lc a.txt
-rw-r--r-- 1 root root 2 Aug 22 18:04 a.txt
[root@rhel6lhr adump]# ls -lu a.txt
-rw-r--r-- 1 root root 2 Aug 22 18:03 a.txt
[root@rhel6lhr adump]# ls -l a.txt
-rw-r--r-- 1 root root 2 Aug 22 18:04 a.txt
在Oracle中,SELECT语句在带有下列哪个选项中的子句时可以在表的一行或多行放置排它锁()
A、FOR INSERT
B、FOR UPDATE
C、FOR DELETE
D、FOR REFRESH
答案:B。
如果只是SELECT的话,Oracle是不会加任何锁的,也就是Oracle对SELECT读到的数据不会有任何限制,虽然这时候有可能另外一个进程正在修改表中的数据,并且修改的结果可能影响到你目前SELECT语句的结果,但是因为没有锁,所以SELECT结果为当前时刻表中记录的状态。
当对话使用SELECT ... FOR UPDATE子串打开一个游标时,所有返回结果集中的数据行都将处于行级(Row-X)独占式锁定,其它对象只能查询这些数据行,不能进行UPDATE、DELETE或SELECT ... FOR UPDATE操作,但是可以执行INSERT的操作。在Oracle 10g之前FOR UPDATE是行级共享锁(SS,Sub-Share)锁,在Oracle 10g及其以后的版本中,FOR UPDATE属于行级排它锁(SX,Sub-Exclusive)。
在Oracle中无A、C和D选项的语法。
所以,本题的答案为B。
在Oracle中,通过下列哪个选项中的命令可以释放锁()
A、INSERT
B、DELETE
C、ROLLBACK
D、UNLOCK
答案:C。
要结束一个事务,只有通过COMMIT或者ROLLBACK命令,而INSERT、DELETE或UPDATE都会加锁。对于选项D,Oracle中没有UNLOCK这个命令。
显然,本题的答案为C。
在Oracle中,当以SYSDBA登录,CUSTOMER表位于MARY用户方案中,下面哪条语句为数据库中的所有用户创建CUSTOMER表的同义词()
A、CREATE PUBLIC SYNONYM CUST ON MARY.CUSTOMER;
B、CREATE PUBLIC SYNONYM CUST FOR MARY.CUSTOMER;
C、CREATE SYNONYM CUST ON MARY.CUSTOMER FOR PUBLIC;
D、不能创建CUSTOMER的公用同义词。
答案:B。
创建同义词的语法为:
CREATE OR REPLACE [PUBLIC ] SYNONYM 同义词名称 FOR 用户名.表名称;
要为所有用户创建同义词需要使用PUBLIC关键词。所以,本题的答案为B。
在Oracle数据库中,表VENDOR包含以下列:
VENDOR_ID NUMBER PRIMARY KEY
NAME VARCHAR2(30)
LOCATION_ID NUMBER
ORDER_DT DATE
ORDER_AMOUNT NUMBER(8,2)
下面对表VENDOR运用分组函数的子句合法的是?()
A、FROM MAX(ORDER_DT)
B、SELECT SUM(ORDER_DT)
C、SELECT SUM(ORDER_AMOUNT)
D、WHERE GROUP BY ORDER_D
答案:C。
考察SELECT查询的写法。
本题中,对于选项A,FROM后边只能跟表名或视图名称。所以,选项A错误。
对于选项B,ORDER_DT为日期类型,不能采用SUM函数进行相加。所以,选项B错误。
对于选项C,ORDER_AMOUNT为数字类型,可以采用SUM函数进行相加。所以,选项C正确。
对于选项D,WHERE后应该跟上过滤条件或者连接条件。所以,选项D错误。
所以,本题的答案为C。
在SQL Server 2000中,如果希望用户U1在DB1数据库中具有查询T1表的权限,那么正确的授权语句是()
A、GRANT SELECT ON DB1(T1) TO U1
B、GRANT SELECT TO U1 ON DB1(T1)
C、GRANT SELECT TO U1 ON T1
D、GRANT SELECT ON T1 TO U1
答案:D。
授权语句的语法为:
GRANT 对象权限名[,…] ON {表名|视图名|存储过程名} TO {数据库用户名|用户角色名};
这里权限是SELECT,表名是T1,用户是U1。
所以,本题的答案为D。
数据模型定义了数据库中数据的组织、描述、存储和操作规范,可以分为概念模型、数据结构模型和物理模型三大类。概念模型的典型代表是()
A、实体-联系模型
B、关系模型
C、面向对象模型
D、网状模型
概念数据模型也可简称为概念模型,最典型的概念数据模型是实体-联系模型,所以,本题的答案为A。
以下关于查询语句叙述错误的是()
A、查询语句的功能是从数据库中检索满足条件的数据
B、查询的数据源可以来自一张表,或多张表甚至是视图
C、查询的结果是由0行或是多行记录组成的一个记录集合
D、不允许选择多个字段作为输出字段
答案:D。
查询语句的功能是从数据库中检索满足条件的数据;查询的数据源可以来自一张表,或多张表关联,也可以来自于视图,包括物化视图;查询的结果是由0行或多行记录组成的一个记录集合,并且可以选择一个或多个字段作为输出字段,使用“*”可以输出所有字段。所以,本题的答案为D。
关于视图的属性列有如下说法,正确的是()
A、组成视图的属性列名应该全部指定
B、组成视图的属性列名可以省略一部分或者指定一部分,其他隐含在子查询中
C、组成视图的属性列名或者全部省略或者全部指定,别无选择
D、组成视图的属性列名应该全部省略
视图是从一个或几个基本表或视图导出的表,组成视图的属性列名或者全部省略或者全部指定,没有第三种选择。如果省略了视图的各个属性列名,那么该视图的列名就隐含在子查询中,所以,本题的答案为C。
当对通过视图看到的数据进行修改时,相应的基本表的数据也要发生变化,同时,若基本表的数据发生变化,则这种变化也可以自动地反映到视图中。
什么是视图?视图的作用是什么?哪一类是可更新视图?
视图是由从数据库的基本表中选取出来的数据组成的逻辑窗口,它不同于基本表,它是一个虚拟表,其内容由查询定义。在数据库中,存放的只是视图的定义而已,而不存放数据,这些数据仍然存放在原来的基本表结构中。只有在使用视图的时候,才会执行视图的定义,从基本表中查询数据。
同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。对其中所引用的基础表而言,视图的作用类似于筛选。定义视图可以来自当前或其它数据库的一个或多个表,或者其它视图。分布式查询也可用于定义使用多个异类源数据的视图。如果有几台不同的服务器分别存储不同地区的数据,那么当需要将这些服务器上相似结构的数据组合起来的时候,这种方式就非常有用。
通过视图进行查询没有任何限制,用户可以将注意力集中在其关心的数据上,而非全部数据,这样就大大提高了运行效率与用户满意度。如果数据来源于多个基本表结构,或者数据不仅来自于基本表结构,还有一部分数据来源于其它视图,并且搜索条件又比较复杂,需要编写的查询语句就会比较繁琐,此时定义视图就可以使数据的查询语句变得简单可行。定义视图可以将表与表之间的复杂的操作连接和搜索条件对用户不可见,用户只需要简单地对一个视图进行查询即可,所以,视图虽然增加了数据的安全性,但是不能提高查询的效率。
视图看上去非常像数据库的物理表,对它的操作同任何其它的表一样。当通过视图修改数据时,实际上是在改变基表(即视图定义中涉及到的表)中的数据;相反地,基表数据的改变也会自动反映在由基表产生的视图中。由于逻辑上的原因,有些Oracle视图可以修改对应的基表,有些则不能(仅仅能查询)。
数据库视图的作用有以下几点:
(1)隐藏了数据的复杂性,可以作为外模式,提供了一定程度的逻辑独立性。
(2)有利于控制用户对表中某些列或某些机密数据的访问,提高了数据的安全性。
(3)能够简化结构,执行复杂查询操作。
(4)使用户能以多种角度、更灵活地观察和共享同一数据。
视图对于DML操作应遵循的原则如下所示:
(1)简单视图可以执行DML操作。
(2)当视图包含GROUP BY子句、DISTINCT关键字时,不能执行DELETE操作。
(3)当视图出现下列情况时,不能通过视图修改基表或插入数据到基表:
(a)视图中包含GROUP BY子句、DISTINCT关键字。
(b)视图中包含了由表达式定义的列。
(c)视图中包含了ROWNUM伪列(针对Oracle数据库)。
(d)基表中未在视图中选择的其它列定义为非空且无默认值。
设计题
有商品表(商品号,商品名,分类,单价),请编写一个实现更改商品单价的存储过程(存储过程名为PUPDATE),更改规则如下:“电脑”类商品降价10%,“电视”类商品降价6%,“冰箱”类商品降价3%,其它商品不降价。以商品的分类作为输入参数,假设“分类”为字符串类型,长度最多为6个字符。如果商品表中没有用户指定的分类,那么用输出参数返回字符串“指定的分类不存在”;如果用户指定的分类存在,那么用输出参数返回字符串“修改已成功”。
这里以Oracle的存储过程语法进行说明:
CREATE PROCEDURE PUPDATE(P_TYPE VARCHAR2(6), P_OUT VARCHAR2(10)) AS
V_COUNT NUMBER;
BEGIN
SELECT COUNT(1) INTO V_COUNT FROM 商品表 WHERE 分类 = P_TYPE;
IF V_COUNT > 0 THEN
IF P_TYPE = '电脑' THEN
UPDATE 商品表 SET 单价 = 单价 * 0.9 WHERE 分类='电脑';
END IF;
IF P_TYPE = '电视' THEN
UPDATE 商品表 SET 单价 = 单价 * 0.94 WHERE 分类='电视';
END IF;
IF P_TYPE = '冰箱' THEN
UPDATE 商品表 SET 单价 = 单价 * 0.97 WHERE 分类='冰箱';
END IF;
P_OUT := '修改已成功';
ELSE
P_OUT := '指定的分类不存在';
END IF;
END;数据库系统的组成与结构有哪些?
数据库系统(DataBase System,简称DBS)一般由4个部分组成:数据库、硬件、软件、人员。
(1)数据库:是指长期存储在计算机内的、有组织、可共享的数据的集合。数据库中的数据按一定的数学模型组织、描述和存储,具有较小的冗余,较高的数据独立性和易扩展性,并可为各种用户共享。
(2)硬件:构成计算机系统的各种物理设备,包括存储所需的外部设备。硬件的配置应满足整个数据库系统的需要。
(3)软件:包括操作系统、数据库管理系统及应用程序。数据库管理系统(DataBase Management System,简称DBMS)是数据库系统的核心软件,它在操作系统的支持下工作,解决如何科学地组织和存储数据,如何高效获取和维护数据的系统软件,其主要功能包括:数据定义功能、数据操纵功能、数据库的运行管理和数据库的建立与维护等。
(4)人员:主要有4类。第一类为系统分析员和数据库设计人员:系统分析员负责应用系统的需求分析和规范说明,他们和用户及数据库管理员一起确定系统的硬件配置,并参与数据库系统的概要设计。数据库设计人员负责数据库中数据的确定、数据库各级模式的设计。第二类为应用程序员,负责编写使用数据库的应用程序。这些应用程序可对数据进行检索、建立、删除或修改。第三类为最终用户,他们利用系统的接口或查询语言访问数据库。第四类用户是数据库管理员(DBA),负责数据库的总体信息控制。DBA的职责通常包括以下几点内容:维护数据库中的信息内容和结构,制定数据库的存储结构和存取策略,定义数据库的安全性要求和完整性约束条件,监控数据库的使用和运行,负责数据库的性能改进、数据库的重组和重构,以提高系统的性能。其中,应用程序包含在软件范围内,是指数据库应用系统,例如开发工具、人才管理系统、信息管理系统等。
索引有哪些作用?
答案:创建索引可以大大提高系统的性能,总体来说,创建索引有如下几点用途:
① 大大加快数据的检索速度,这也是创建索引的最主要的原因。
② 索引可以加速表和表之间的连接。
③ 索引在实现数据的参照完整性方面特别有意义,例如在外键列上创建索引可以有效的避免死锁的发生,也可以防止当更新父表主键时,数据库对子表的全表锁定。
④ 索引是减少磁盘I/O的许多有效手段之一。
⑤ 当使用分组(GROUP BY)和排序(ORDER BY)子句进行数据检索时,可以显著减少查询中分组和排序的时间,大大加快数据的检索速度。
⑥ 创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
⑦ 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
什么是聚簇索引和非聚簇索引?在哪些列上适合创建聚簇索引?
索引是一种特殊的数据结构。微软的SQL Server提供了两种索引:聚集索引(Clustered Index,也称聚类索引、簇集索引、聚簇索引)和非聚集索引(Nonclustered Index,也称非聚类索引、非簇集索引)。
聚集索引是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的一种索引。由于聚集索引的索引页面指针指向数据页面,所以,使用聚集索引查找数据几乎总是比使用非聚集索引快。需要注意的是,由于聚集索引规定了数据在表中的物理存储顺序,所以,每张表只能创建一个聚集索引,并且创建聚集索引需要更多的存储空间,以存放该表的副本和索引中间页。
聚集索引表记录的排列顺序与索引的排列顺序一致,优点是查询速度快,因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理上是相邻的。例如,如果应用程序执行的一个查询经常检索某一日期范围内的记录,那么使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,那么可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。
非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+Tree的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。
聚集索引和非聚集索引的根本区别是表记录的物理排列顺序和索引的排列顺序是否一致。聚集索引和非聚集索引有如下几点不同:
① 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
② 聚集索引存储记录是物理上连续存在,物理存储按照索引排序,而非聚集索引是逻辑上的连续,物理存储并不连续,物理存储不按照索引排序。
③ 聚集索引查询数据比非聚集索引速度快,插入数据速度慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入);非聚集索引反之。
④ 索引是通过二叉树的数据结构来描述的,聚集索引的叶节点就是数据节点,而非聚集索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
下表列出了何时使用聚集索引或非聚集索引:
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
| 列经常被分组或排序 | 应 | 应 |
| 返回某范围内的数据 | 应 | 不应 |
| 一个或极少不同值 | 不应 | 不应 |
| 小数目的不同值 | 应 | 不应 |
| 大数目的不同值 | 不应 | 应 |
| 频繁更新的列 | 不应 | 应 |
| 外键列 | 应 | 应 |
| 主键列 | 应 | 应 |
| 频繁修改索引列 | 不应 | 应 |
在Oracle中,位图索引是什么?在哪些列上适合创建位图索引?
位图索引(Bitmap Indexes)是一种使用位图的特殊数据库索引。它针对大量相同值的列而创建,例如:类别、型号等。位图索引块的一个索引行中存储的是键值(以比特位0、1的形式存储)和起止ROWID(ROWID的内容可以参考【3.2.28 ROWID和ROWNUM有什么区别?】),以及这些键值的位置编码,位置编码中的每一位表示键值对应的数据行的有无。一个块可能指向的是几十甚至成百上千行数据的位置。
在位图索引中,数据库为每个索引键存储一个位图。在传统的B-Tree索引中,一个索引条目指向单个行,但是在位图索引中,每个索引键存储指向多个行的指针。相对于B-Tree索引,位图索引占用的空间非常小,创建和使用速度非常快。当根据键值查询时,可以根据起始ROWID和位图状态,快速定位数据。当根据键值做AND、OR或IN (X,Y,..)查询时,直接用索引的位图进行或运算,快速得出结果集。当SELECT COUNT(XX)时,可以直接访问索引从而快速得出统计数据。
位图索引与其它索引不同,它不是存储的索引列的列值,而是以比特位0、1的形式存储,所以在空间上它占的空间比较小,相应的一致性查询所使用的数据块也比较小,查询的效率就会比较高。所以,一般应用于即席查询和快速统计条数。由于位图索引本身存储特性的限制,所以,在重复率较低的列或需要经常更新的列上是不适合建立位图索引的。另外,位图索引更新列更容易引起死锁。
在Oracle中,哪几种情况不能用上索引?
“为什么索引没有被使用”是一个涉及面较广的问题。有多种原因会导致索引不能被使用。首要的原因就是统计信息不准,第二原因就是索引的选择度不高,使用索引比使用全表扫描效率更差。还有一个比较常见的原因,就是对索引列进行了函数、算术运算或其他表达式等操作,或出现隐式类型转换,导致无法使用索引。还有很多其它原因会导致不能使用索引,这个问题在MOS(MOS即My Oracle Support)“文档1549181.1为何在查询中索引未被使用”中有非常详细的解释,作者已经将相关内容发布到BLOG(http://blog.itpub.net/26736162/viewspace-2113670/)上了。下面是一些非常有用的检查项目。
在Oracle中,行迁移和行连接的区别有哪些?
当一行的数据过长而不能存储在单个数据块中时,可能发生两种事情:行链接(Row Chaining)或行迁移(Row Migration)。
① 行链接(Row Chaining):当第一次插入行时,由于行太长而不能容纳在一个数据块中时,就会发生行链接。在这种情况下,Oracle会使用与该块链接的一个或多个数据块来容纳该行的数据。行链接经常在插入比较大的行时才会发生,例如包含LONG、LONG ROW、LOB等类型的数据。在这些情况下,行链接是不可避免的。行链接通常由INSERT操作引起。
② 行迁移(Row Migration):当一个行上的更新操作导致当前的数据增加以致于不能再容纳在当前块,这个时候就需要进行行迁移,在这种情况下,Oracle将会迁移整行数据到一个新的数据块中。一个行迁移意味着整行数据都将会移动,原始的数据块上仅仅保留的是指向新块的一个地址信息。发生行迁移的时候行的ROWID不会改变。行迁移的情况主要是由于表上的PCTFREE参数设置过小导致,所以必须设置一个合适的PCTFREE参数。可以使用exp/imp工具导入导出来处理行迁移。行迁移通常由UPDATE操作引起。
在Oracle中,如何查看登陆到系统的用户的用户名?
以下3个命令均可以查看当前登录到系统的用户名:
SHOW USER;
SELECT SYS_CONTEXT('USERENV','SESSION_USER') FROM DUAL;
SELECT USER FROM DUAL;Oracle和MySQL中的分组(GROUP BY)有什么区别?
Oracle对于GROUP BY是严格的,所有要SELECT出来的字段必须在GROUP BY后边出现,否则会报错:“ORA-00979: not a GROUP BY expression”。而MySQL则不同,如果SELECT出来的字段在GROUP BY后面没有出现,那么会随机取出一个值,而这样查询出来的数据不准确,语义也不明确。所以,作者建议在写SQL语句的时候,应该给数据库一个非常明确的指令,而不是让数据库去猜测,这也是写SQL语句的一个非常良好的习惯。
MySQL支持哪几类分区表?
表分区是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成,每个分区都是一个独立的对象。分区有利于管理大表,体现了“分而治之”的理念。一个表最多支持1024个分区。MySQL支持的分区类型主要包括RANGE分区、LIST分区、HASH分区、KEY分区。分区表中对每个分区再次分割就是子分区(Subpartitioning),又称为复合分区。在MySQL 5.5中引入了COLUMNS分区,细分为RANGE COLUMNS和LIST COLUMNS分区。引人COLUMNS分区解决了MySQL 5.5版本之前RANGE分区和LIST分区只支持整数分区,从而导致需要額外的函数计算得到整数或者通过额外的转换表来转换为整数再分区的问题。
下列关于数据库基本概念的叙述中,哪一条是错误的()
A、数据库可理解为是在计算机存储设备中按一定格式存放数据的仓库
B、数据库是按一定结构组织并可以长期存储在计算机内的、在逻辑上保持一致的、可共享的大量相关联数据的集合
C、数据库中的数据一般都具有较大的冗余度
D、数据库中的数据是按一定的数据模型组织在一起的
数据库中的数据一般满足第三范式,具有较小的冗余度,所以,选项C描述错误。
所以,本题的答案为C。
设有关系模式:教师表(教师号,教师名,所在系,工资),现需建立一个统计每个系全体教师工资总额的视图,正确的语句是()
A、CREATE VIEW SALARYVIEW(系名,工资总额)AS
SELECT 所在系,COUNT(工资) FROM 教师表 GROUP BY 所在系;
B、CREATE VIEW SALARYVIEW(系名,工资总额)AS
SELECT 所在系,SUM(工资) FROM 教师表 GROUP BY 所在系;
C、CREATE VIEW SALARYVIEW AS
SELECT 所在系,COUNT(工资) FROM 教师表 GROUP BY 所在系;
D、CREATE VIEW SALARYVIEW AS
SELECT 所在系,SUM(工资) FROM 教师表 GROUP BY 所在系;
本题中,求工资总额应该使用SUM函数,据此排除A和C,另外,由于要返回所在系和工资总额,共有2列,D选项的列“SUM(工资)”必须有别名,否则会报错。所以,选项B正确。
下列关于数据模型的叙述中,哪一条是错误的()
A、数据模型是用来描述、组织和处理现实世界中数据的工具
B、数据模型主要用于定义数据库的静态特征,但是不便于描述数据间的动态行为
C、数据模型需要能比较真实地模拟现实世界
D、数据模型是数据库系统的核心和基础
模型是现实世界特征的模拟和抽象。数据模型(概念模型、逻辑模型、物理模型)是用来描述数据库数据的结构、定义在结构上的操纵、数据间的约束的一组概念和定义,描述数据库的静态特征、动态行为、数据约束条件,为数据库的表示和操纵提供框架。数据模型的三要素:数据结构、数据操作、数据约束。数据模型应满足:①能比较真实的模拟现实世界,②容易为人理解,③便于在计算机上实现。显然,选项A、C和D的描述正确。
对于选项B,数据模型主要用于描述数据库的静态特征、动态行为、数据约束条件,所以,选项B描述错误。
若一门课程只能由一位教师讲授,而一位教师可以讲授若干门课程,则课程与教师这两个实体型之间的联系是()
A、一对一
B、多对多
C、一对多
D、多对一
实体集A、B,若对于A中的每一个实体,B中有n(n≥0)个于之关联,反之,对于B中的每一个实体,A中至多只有一个实体与之关联,则A:B=1:n。所以,选项D正确。
下列关于概念模型的叙述中,哪一条是错误的()
A、概念模型是现实世界到信息世界的抽象
B、概念模型是从用户观点对数据和信息的建模
C、概念模型具有较强的语法表达能力,却无法描述语义信息
D、E-R模型是概念模型最常用的表示方法
概念模型是现实世界到信息世界的语义抽象,主要用于数据库设计中的概念设计,是划分客观世界概念、描述概念的性质以及概念间联系的语义模型,是数据库设计者与用户之间交流的工具,是数据库逻辑模型的基础,它表示简单、易于理解且具有较强的语义表达能力,独立于具体的逻辑模型并易于向逻辑模型转换。E-R模型是概念模型最常用的表示方法。
下列关于数据库中“型”和“值”的叙述中,哪一条是错误的()
A、数据库中的型是指对某一类数据的结构和属性的描述
B、数据库的型是随时间发生不断变化的
C、数据库的型亦称为数据库的内涵
D、数据库的值是型的一个具体赋值
数据库中的型也称为数据库的内涵,是指对数据结构及其属性的描述。数据库的型是稳定的,而其值是随时间不断变化的,因为数据库中的数据在不断变更。数据库的值称为数据库的外延。
下列关于关系数据模型的叙述中,哪一条是错误的()
A、关系模型中数据的物理结构是一张二维表
B、在关系模型中,现实世界的实体以及实体间的各种联系均用关系来表示
C、插入、删除、更新是关系模型中的常用操作
D、关系操作通过关系语言实现,关系语言的特点是高度非过程化
关系模型是用二维表结构表示各类实体及实体间的联系,一个关系数据库由多张二维表组成。一个二维表就是一个关系。
本题中,对于选项A,关系模型中数据的逻辑结构是一张二维表,选项中说成了物理结构,所以选项A描述错误。所以,选项A正确。其它选项的描述均正确。
下列关于关系数据语言的叙述中,哪一条是错误的()
A、关系代数是关系操作语言的一种传统表示方式,是一种抽象的查询语言
B、元组关系演算和域关系演算属于关系演算语言
C、关系代数比关系演算具有更强的表达能力
D、SQL语言是一种重要的关系数据语言
关系代数是关系操作语言的一种传统表示方式,以集合代数为基础而发展,关系代数操作的操作对象和操作结果均为关系。关系代数、元组关系演算、域关系演算均是抽象的查询语言,三种语言在在表达能力上完全等价。所以,选项C的描述是错误的。
现有“学生-选课-课程”数据库中的三个关系如下:
S(S#,SNAME,SEX,BIRTHYEAR,DEPT),主码是S#
C(C#,CNAME,TEACHER),主码是C#
SC(S#,C#,GRADE),主码是(S#,C#)
下列关于保持数据库完整性的叙述中,哪一条是错误的()
A、向关系SC插入元组时,S#和C#都不能是空值(NULL)
B、可以任意删除关系SC中的元组
C、向任何一个关系插入元组时,必须保证关系主码值的唯一性
D、可以任意删除关系C中的元组
实体完整性规则:若属性A是关系R的主属性,则属性A不能为空。实体完整性约束是对关系的约束;每个关系必须有主码且非空;组成主码的属性都不能为空,而不仅仅是主码属性集不为空。SC为参照关系,S、C均为被参照关系,若被参照关系中的S#或C#被删除,则参照关系中元组将无意义。所以S、C中的元组均不能任意删除。
在关系代数中,从两个关系的笛卡尔积中选取它们属性间满足一定条件的元组的操作称为()
A、并
B、选择
C、自然连接
D、连接
相容性条件:两个关系具有相同的属性个数,每对相对应的属性都具有相同的域。
并:满足相容性条件,R中特有元组+S中特有元组+共有元组去重。
选择:对元组的操做,从关系R中选出满足条件表达式F的所有元组构成新的关系。
连接:从两个关系R、S的笛卡尔积中选取它们的属性间满足一定条件的元组。
等值连接:从关系R与S的笛卡尔积中选取A、B属性值相等的那些元组。
自然连接:要求两个关系中进行比较的分量必须是相同的属性组,且要在结果中去掉重复属性。
显然,本题的答案为D。
对关系模型叙述错误的是()
A、建立在严格的数学理论,集合论和谓词演算公式基础之一
B、微机DBMS绝大部分采取关系数据模型
C、用二维表表示关系模型是其一大特点
D、不具有连接操作的DBMS也可以是关系数据库管理系统
关系模型采用二维表表示实体及实体间的联系,实体间的联系是通过不同关系中的公共属性实现的,若关系DBMS没有提供连接操作,将无法完成涉及多个表之间的查询操作。所以答案为D。
Oracle数据库中的空值(NULL)相当于()
A、零(0)
B、空格
C、零长度的字符串('')
D、代表数据库中的一种特殊字符
数据库管理系统为三级模式结构提供了两层映像机制,其中模式/内模式映像提供了_____独立性。
答案:数据的物理
分析:一个数据库系统只存在一个唯一的模式/内模式映像,它定义了数据库全局逻辑结构与存储结构之间的对应关系(该映像定义通常包含在模式描述中)。当数据库的存储结构改变了(例如选用了另一种存储结构),由DBA对模式/内模式映像作相应改变,可以使模式保持不变。这体现了数据的物理独立性。
数据库管理系统中的加锁协议规定了事务的加锁时间、持锁时间和释放锁时间,其中_____协议可以完全保证并发事务数据的一致性。
答案:三级加锁
分析:三级加锁协议也称为三级封锁协议。它是为了保证正确的调度事务的并发操作,事务在对数据库对象加锁和解锁的时候必须遵守的一种规则。在运用X锁和S锁对数据库对象加锁时需要约定一些规则,例如合适申请X锁、持锁时间、何时释放等。可以称这些规则为封锁协议(Locking Protocol)。对封锁方式规定不同的规则就形成了各种不同的封锁协议。
数据定义语言(Data Definition Language,DDL):用于建立、修改和删除数据库对象,作用就是定义数据的格式和形态。例如CREATE TABLE可以建立表,ALTER TABLE语句则可对表结构进行修改,DROP TABLE语句用来删除某个表,TRUNCATE命令用来删除数据内容,需要注意的是,DDL语句会自动提交事务。在建立数据库时用户首先要使用的就是DDL语句。
按照数据库应用系统生命周期模型,系统设计阶段细分为概念设计、逻辑设计和物理设计三个步骤。
Oracle是由C语言开发的。
在Oracle数据库中,当用户进程出错,哪个后台进程负责清理它?
Oracle的进程包括后台进程、服务器进程和用户进程,后台进程是Oracle的程序,在Oracle实例启动的时候启动,用来管理数据库的读写,恢复和监视等工作,如PMON、SMON等进程。其中PMON的作用就是清理出错的用户进程,当然PMON进程还有其它的作用:
① 在进程失败后执行清除工作:
a. 回滚事务
b. 释放锁
c. 释放其他资源
② 注册数据库
③ 检测会话的空闲连接时间
Oracle常见的数据库对象有哪些?
| 对象名称 | 描述 |
| 表 | 基本的数据存储对象,以行和列的形式存在,行是记录 |
| 约束条件 | 执行数据校验,保证了数据完整性的对象 |
| 视图 | 一个或多个表数据的逻辑表示 |
| 索引 | 用于提高查询的性能 |
| 同义词 | 对象的别名 |
除此之外,还有常见的函数、存储过程、物化视图、外部表和JOB等都属于常见的数据库对象。
在Oracle数据库中,什么是索引组织表?
索引组织表简称索引表(Index-Organized Table,IOT),是把索引和一般数据列全部存储在相同位置上的表结构,是一个存储在索引结构中的表。它的特点是存储慢,读取快。索引组织表(IOT)不仅可以存储数据,还可以存储为表建立的索引。索引组织表的数据是根据主键排序后的顺序进行排列的,这样就提高了访问的速度,但是,这是由牺牲插入和更新性能为代价的(每次写入和更新后都要重新进行排序)。索引组织表的数据存储在与其关联的索引中。索引中存储的是行的实际数据,而不是ROWID,它是基于主键访问数据的。在索引组织表中,索引就是数据,数据就是索引。
在MySQL中如何有效的删除一个大表?
在Oracle中对于大表的删除可以通过先TRUNCATE + REUSE STORAGE参数,再使用DEALLOCATE逐步缩小,最后DROP掉表。在MySQL中,对于大表的删除,可以通过建立硬链接(Hard Link)的方式来删除。建立硬链接的方式如下所示:
ln big_table.ibd big_table.ibd.hdlk
建立硬链接之后就可以使用DROP TABLE删除表了,最后在OS级别删除硬链接的文件即可。
为什么通过这种方式可以快速删除呢?当多个文件名同时指向同一个INODE时,此时这个INODE的引用数N>1,删除其中任何一个文件都会很快。因为其直接的物理文件块没有被删除,只是删除了一个指针而已。当INODE的引用数N=1时,删除文件时需要把与这个文件相关的所有数据块清除,所以会比较耗时。
MySQL可以使用profile分析SQL语句的性能消耗情况。例如,查询到SQL会执行多少时间,并看出CPU、内存使用量,执行过程中系统锁及表锁的花费时间等信息。
通过have_profiling参数可以查看MySQL是否支持profile
数据模型定义子数据库中数据的组织、描述、存储和操作规范,可以分为概念模型、数据结构模型和物理模型三大类。概念模型的典型代表是()
A、实体-联系模型
B、关系模型
C、面向对象模型
D、网状模型
实体-联系模型简称E-R模型(Entity-Relationship Model),其图形称为实体-联系图(Entity-Relationship Diagram),简称ERD。当采用E-R方法进行数据库概念设计时,可以分成3步进行:首先,设计局部E-R模式,然后把各局部E-R模式综合成一个全局的E-R模式,最后对全局E-R模式进行优化,得到最终的E-R模式,即概念模式。
根据数据库应用系统生命周期模型,完成数据库关系模式设计的阶段是()
A、需求分析
B、概念设计
C、逻辑设计
D、物理设计
数据库应用系统生命周期分成七个阶段:规划、需求分析、概念设计、逻辑设计、物理设计、实现、运行和维护。其中,逻辑设计阶段的主要任务是将现实世界的概念数据模型设计成数据库的一种逻辑模式,即适应于某种特定数据库管理系统所支持的逻辑数据模式。这一步设计的结果就是所谓“逻辑数据库”。根据已经建立的概念数据模型,以及所采用的某个数据库管理系统软件的数据模型特性,按照一定的转换规则,把概念模型转换为这个数据库管理系统所能够接受的逻辑数据模型。不同的数据库管理系统提供了不同的逻辑数据模型,例如层次模型、网状模型、关系模型等。逻辑设计的目的是把概念设计阶段设计好的基本E-R图转换为与选用的具体机器上的DBMS所支持的数据模型相符合的逻辑结构(包括数据库模式和外模式)。所以,本题的答案为C。
在数据库应用系统设计过程中,属于物理设计范畴的是()
A、数据流图设计
B、实体-联系图设计
C、关系模式设计
D、索引设计
数据库结构的物理设计是指对一个给定的逻辑数据模型选取一个最适合应用环境的物理结构的过程,所谓数据库的物理结构主要指数据库在物理设备上的存储结构和存取方法。
物理设计的步骤为:
(1)设计存储记录结构,包括记录的组成、数据项的类型和长度,以及逻辑记录到存储记录的映射;
(2)确定数据存储安排;
(3)设计访问方法,为存储在物理设备上的数据提供存储和检索的能力;
(4)进行完整性和安全性的分析、设计;
(5)程序设计。
本题中,对于选项A,数据流图设计属于需求分析阶段。所以,选项A错误。
对于选项B,E-R属于概念设计阶段。所以,选项B错误。
对于选项C,关系模式设计属于逻辑设计阶段。所以,选项C错误。
对于选项D,索引的设计属于物理设计阶段。所以,选项D正确。
当多个事务并发执行时,数据库管理系统应保证一个事务的执行结果不受其它事务的干扰,事务并发执行的结果与这些事务串行执行的结果一样,这一特性被称为事务的()
A、原子性
B、一致性
C、持久性
D、隔离性
事务有4个特性,一般都称之为ACID特性,如下表所示:
| 名称 | 简介 | 举例 |
| 原子性(Atomicity) | 所谓原子性是指事务在逻辑上是不可分割的操作单元,其所有语句要么都执行,要么都撤销执行。当每个事务运行结束时,可以选择“提交”所做的数据修改,并将这些修改永久应用到数据库中。 | 假设有两个账号,A账号和B账号。A账号转给B账号100元,这里有两个动作在里面,①A账号减去100元,②B账号增加100元,这两个动作不可分割即原子性。 |
| 一致性(Consistency) | 事务是一种逻辑上的工作单元。一个事务就是一系列在逻辑上相关的操作指令的集合,用于完成一项任务,其本质是将数据库中的数据从一种一致性状态转换到另一种一致性状态,以体现现实世界中的状况变化。至于数据处于什么样的状态算是一致状态,这取决于现实生活中的业务逻辑以及具体的数据库内部实现。 | 拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。 |
| 隔离性(Isolation) | 隔离性是针对并发事务而言的,所谓并发是指数据库服务器同时处理多个事务,如果不采取专门的控制机制,那么并发事务之间可能会相互干扰,进而导致数据出现不一致或错误的状态。隔离性就是要隔离并发运行的多个事务间的相互影响。关于事务的隔离性,数据库提供了多种隔离级别,后面的章节会介绍到。 | 隔离性即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其它事务在并发地执行。 |
| 持久性(Durability) | 事务的持久性(也叫永久性)是指一旦事务提交成功,其对数据的修改是持久性的。数据更新的结果已经从内存转存到外部存储器上,此后即使发生了系统故障,已提交事务所做的数据更新也不会丢失。 | 当开发人员在使用JDBC操作数据库时,在提交事务后,提示用户事务操作完成,那么这个时候数据就已经存储在磁盘上了。即使数据库重启,该事务所做的更改操作也不会丢失。 |
存储过程是存储在数据库中的代码,具有很多优点。下列陈述中不属于存储过程优点的是()
A、可通过预编译机制提高数据操作的性能
B、可方便的按用户视图表达数据
C、可减少客户端和服务器端的网络流量
D、可实现一定的安全控制
本题中,对于选项A,存储过程在数据库中可以编译一次多次运行,因此在多次调用的时候可以减少编译的时间,从而提高效率,所以选项A的描述正确。所以,选项A错误。
对于选项B,可方便的按用户视图表达数据,这是视图的功能而不是存储过程的功能,所以选项B的描述错误。所以,选项B正确。
对于选项C,存储过程把大量用户预定义的SQL语句存放在数据库中,用户只需要通过存储过程的名字来完成调用,也就是说在调用的时候只需要把被调用的存储过程的名字以及参数通过网络传输到数据库即可,而不需要传输大量的SQL语句,因此降低了减少了网络流量,所以选项C描述正确。所以,选项C错误。
对于选项D,由于存储过程封装了SQL代码,所以可实现一定的安全控制,描述正确。所以,选项D错误。
在数据库三级模式结构中,对数据库中全部的数据逻辑结构和特征进行描述的是()
A、外模式
B、模式
C、子模式
D、内模式
不同的DBMS在体系结构上通常都具有相同的特征,即采用三级模式结构并提供二级映像功能。数据库系统三级模式结构是数据库系统内部的体系结构,数据库系统的三级模式是指外模式、模式和内模式三部分。数据库系统的模式结构图如下图所示:
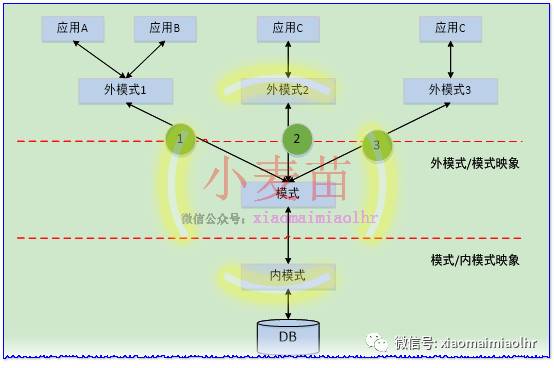
(1)外模式(External Schema)
外模式也称子模式(Subschema)或用户模式,它是数据库用户(包括应用程序员和最终用户)最终能够看见的和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。外模式面向具体的应用程序,它定义在模式之上,但独立于存储模式和存储设备。设计外模式时应充分考虑到应用的扩充性。外模式通常是模式的子集。一个数据库可以有多个外模式。外模式是保证数据库安全性的一个有力措施。
(2)模式(Schema)
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。它是数据库系统模式结构的中间层,既不涉及数据的物理存储细节和硬件环境,也与具体的应用程序、所使用的应用开发工具以及高级程序设计语言无关。模式是数据库的中心与关键,它独立于数据库的其他层次。设计数据库模式结构时应首先确定数据库的模式。模式实际上是数据库数据在逻辑级上的视图。一个数据库只有一个模式。数据库模式以某一种数据模型为基础,统一综合地考虑了所有用户的需求,并将这些需求有机地结合成一个逻辑整体。模式定义包括数据的逻辑结构定义、数据之间的联系定义以及安全性、完整性要求的定义。
(3)内模式(Internal Schema)
内模式也称存储模式(Storage Schema),一个数据库只有一个内模式,它是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。内模式依赖于它的全局逻辑结构,但独立于数据库的用户视图即外模式,也独立于具体的存储设备。例如,记录的存储方式是顺序存储、按照B树结构存储还是按HASH方法存储;索引按照什么方式组织;数据是否压缩存储,是否加密;数据的存储记录结构有何规定等。
数据库系统的三级模式是对数据的三个抽象级别,它把数据的具体组织留给DBMS管理,使用户能逻辑抽象地处理数据,而不必关心数据在计算机中的表示和存储。为了能够在内部实现这三个抽象层次的联系和转换,数据库系统在这三级模式之间提供了二级映像:外模式/模式映像和模式/内模式映像。正是这两层映像保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。
(一)外模式/模式
对于每一个外模式,数据库系统都有一个外模式/模式映像,它定义了该外模式与模式之间的对应关系(这些映像定义通常包含在各自外模式的描述中)。当模式改变时(例如增加新的关系、新的属性、改变属性的数据类型等),DBA对各个外模式/模式的映像作相应改变,可以使外模式保持不变。这体现了数据的逻辑独立性。
(二)模式/内模式
一个数据库系统存在一个唯一的模式/内模式映像,它定义了数据库全局逻辑结构与存储结构之间的对应关系(该映像定义通常包含在模式描述中)。例如,说明逻辑记录和字段在内部是如何表示的。
当数据库的存储结构改变了(例如选用了另一种存储结构),由DBA对模式/内模式映像作相应改变,可以使模式保持不变。这体现了数据的物理独立性。
三级模式和二级映像有如下的优点:
l 数据库的二级映像保证了数据库外模式的稳定性,从而从底层保证了应用程序的稳定性。
l 数据和程序之间的独立性使得数据的定义和描述可以从应用程序中分离出去。另外,由于数据的存取由DBMS管理,用户不必考虑存取路径等细节从而简化了应用程序的编制,大大减少了应用程序的维护和修改。
SQL Server 2000数据库用户的来源()
A、可以是所有SQL Server的登陆用户
B、只能是Windows身份验证的登陆用户
C、只能是SQL Server身份验证的登陆用户
D、可以是其它数据库中的用户
SQL Server 2000数据库用户可以是数据库的创建用户,也可以是Windows身份认证的登录用户。
显然,本题的答案为A。
有一个事务T要更新数据库中某表列的值,DBMS在执行T时发现更新后的值超出了该列的值定义范围,因此异常终止了T。为了保证数据的正确性及一致性,DBMS会执行下列哪个恢复操作?()
A、Undo B、介质恢复 C、进程恢复 D、Redo
回滚就是撤销当前事务中以前的数据库修改,即UNDO操作。
关于undo和redo:数据库中redo-undo的介绍
在SQL Server 2000中,若希望用户USER1具有数据库服务器上的全部权限,则应将USER1加入到下列哪个角色(D)
A、db_owner
B、public
C、db_datawriter
D、sysadmin
登录名就是可以登录该服务器的名称;服务器角色就是该登录名对该服务器具有的权限,一个服务器可以有多个角色,一个角色可以有多个登录名,就好像操作系统可以有多个登录用户。
| 固定服务器角色 | 描述 |
| sysadmin | 可以在SQL Server中执行任何操作。 |
| serveradmin | 可以设置服务器范围的配置选项,可以关闭服务器。 |
| setupadmin | 可以管理链接服务器和启动过程。 |
| securityadmin | 可以管理登录和CREATE DATABASE权限,还可以读取错误日志和更改密码。 |
| processadmin | 可以管理在SQL Server中运行的进程。 |
| dbcreator | 可以创建、更改和删除数据库。 |
| diskadmin | 可以管理磁盘文件。 |
| bulkadmin | 可以执行BULK INSERT语句。 |
| db_owner | 在数据库中有全部权限。 |
| db_accessadmin | 可以添加或删除用户ID。 |
| db_securityadmin | 可以管理全部权限、对象所有权、角色和角色成员资格。 |
| db_ddladmin | 可以发出ALL DDL,但不能发出GRANT、REVOKE或DENY语句。 |
| db_backupoperator | 可以发出 DBCC、CHECKPOINT和BACKUP语句。 |
| db_datareader | 可以选择数据库内任何用户表中的所有数据。 |
| db_datawriter | 可以更改数据库内任何用户表中的所有数据。 |
| db_denydatareader | 不能选择数据库内任何用户表中的任何数据。 |
| db_denydatawriter | 不能更改数据库内任何用户表中的任何数据。 |
在使用的过程中,一般使用sa(登录名)或Windows Administration(Windows集成验证登陆方式)登陆数据库,这种登录方式登录成功以后具有最高的服务器角色,也就是可以对服务器进行任何一种操作,而这种登录名具有的用户名是DBO(数据库默认用户,具有所有权限),但是,在使用的过程中,一般感觉不到DBO的存在,但它确实存在。一般通常创建用户名与登录名相同(如果不改变用户名称的话,那么系统会自动创建与登录名相同的用户名,这个不是强制相同的),例如创建了一个登录名称为“ds”,那么可以为该登录名“ds”在指定的数据库中添加一个同名用户,使登录名“ds”能够访问该数据库中的数据。
对于数据库管理系统,下面说法不正确的是()
A、数据库管理系统是一组软件
B、数据库管理系统负责对数据库的定义和操纵
C、数据库管理系统包括数据库
D、数据库管理系统负责对数据库的控制
数据库管理系统是位于用户和操作系统之间的一层数据管理软件,它的主要功能是数据定义,数据组织、存储和管理,数据操纵、数据库的事务管理和运行管理、数据库的建立和维护功能等
对于数据模型,下面说法不正确的是()
A、概念模型是信息世界的建模工具
B、E-R模型是一种概念模型
C、概念模型不涉及计算机的处理细节
D、关系模型是一种概念模型
关系模型是一种逻辑模型,它不属于概念模型。概念模型是用于信息世界的建模,是现实世界到信息世界的第一层抽象。
当数据对象A被事务加上排它锁,则其它事务对A()
A、加排它式封锁
B、不能再加任何类型的锁
C、可以加排它式封锁和保护式封锁
D、加保护式封锁
排它锁又称写锁(简称X锁),当事务对数据对象加了X锁后,则只允许T读取和修改该数据,其它的任何事务都不能再对它加任何类型的锁,直到事务释放了该数据对象的锁。
了解锁数据库锁分类和总结
在SQL Server 2000的某用户数据库中,设有T表,现要在T表的C1列和C2列上建立一个复合唯一聚集索引,其中C1列值重复率为20%,C2列为10%。请补全下列语句建立一个性能最优的索引: CREATE UNIQUE CLUSTERED INDEX IDX1 ON T(_____)。
答案:C2,C1
分析:应该在重复率低的列上创建聚集索引。聚簇索引也叫簇类索引,聚集索引是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的一种索引。由于聚集索引的索引页面指针指向数据页面,所以,使用聚集索引查找数据几乎总是比使用非聚集索引快。需要注意的是,由于聚集索引规定了数据在表中的物理存储顺序,所以,每张表只能创建一个聚集索引,并且创建聚集索引需要更多的存储空间,以存放该表的副本和索引中间页。本题中,C2列的重复率低,因此这个复合索引中,应该把C2列放在前面,而把C1列放在后面。
在分布式数据库系统中,涉及到多个站点的分布式查询的查询代价主要是由_____代价来衡量的。
答案:CPU和I/O
数据库应用系统功能设计包括哪两个方面?每个方面主要由哪些设计步骤组成?
数据库应用系统功能设计包括数据库事务设计和数据库应用程序设计。应用程序设计分为总体设计、概要设计、详细设计,数据库事务设计则由事务概要设计和事务详细设计组成。
数据库系统处理死锁一般采用哪两类方法?简述每类方法的基本原理。
答案:数据库处理死锁一般采用两类方法,一类是死锁预防以避免系统进入死锁状态,另一类则是允许系统进入死锁状态,然后使用死锁检测与恢复机制使系统摆脱死锁状态。如果数据库进入死锁的概率比较高,那么使用死锁预防机制的效果好些,否则使用死锁检测与恢复机制的适用性更好。死锁预防通过破坏死锁产生的必要条件来防止死锁发生。死锁检测与恢复机制由两部分组成:死锁检测与死锁恢复,死锁检测用于定期检查系统是否发生死锁,死锁恢复用于将系统从死锁中解救出来。
在Oracle中,什么是绑定变量窥探?
目标SQL若不使用绑定变量,则当具体输入值一旦发生了变化,目标SQL的SQL文本就会随之发生变化,这样Oracle就能很容易地计算出对应Selectivity和Cardinality的值,进而据此来选择执行计划。但对于使用了绑定变量的目标SQL而言,情况就完全不一样了,因为现在无论对应绑定变量的具体输入值是什么,目标SQL的SQL文本都是一模一样的。对于使用了绑定变量的目标SQL而言,Oracle可以选择如下两种方法来决定其执行计划:
l 使用绑定变量窥探(Bind Peeking)。
l 如果不使用绑定变量窥探,那么对于那些可选择率可能会随着具体输入值的不同而不同的谓词条件使用默认的可选择率(例如5%)
绑定变量窥探(Bind Peeking)是在Oracle 9i中引入的,是否启用绑定变量窥探受隐含参数“_OPTIM_PEEK_USER_BINDS”的控制,该参数的默认值是TRUE,表示在Oracle 9i及其后续的版本中,默认启用绑定变量窥探。
绑定变量窥探的优缺点如下所示:
① 优点:当绑定变量窥探被启用后,每当Oracle以硬解析的方式解析使用了绑定变量的目标SQL时,Oracle都会实际窥探(Peeking)一下对应绑定变量的具体输入值,并以这些具体输入值为标准,来决定这些使用了绑定变量的目标SQL的WHERE条件的Selectivity和Cardinality的值,并据此来选择该SQL的执行计划。需要注意的是,这里这个“窥探(Peeking)”的动作只有在硬解析的时候才会执行,当使用了绑定变量的目标SQL再次执行时(此时对应的是软解析/软软解析),即便此时对应绑定变量的具体输入值和之前硬解析时对应的值不同,Oracle也会沿用之前硬解析时所产生的解析树和执行计划,而不再重复执行上述“窥探”的动作。因为有了绑定变量窥探,所以,Oracle在计算目标SQL的WHERE条件的Selectivity和Cardinality的值时,就可以避免使用默认的可选择率,这样就有更大的可能性能得到该SQL准确的执行计划。
② 缺点:对于那些执行计划可能会随着对应绑定变量具体输入值的不同而变化的目标SQL而言一旦启用了绑定变量窥探,其执行计划就会被固定下来,至于这个固定下来的执行计划到底是什么,则完全倚赖于该SQL在硬解析时传入的对应绑定变量的具体值。这意味着一旦启用了绑定变量窥探,目标SQL在后续执行时就只会沿用之前硬解析所产生的解析树和执行计划,即使当时的执行计划和解析树并不适合于新传入的值。
关于绑定变量窥探需要注意以下几点:
(1)在Oracle llg中引入自适应游标共享后,绑定变量窥探这种不管后续传入的绑定变量的具体输入值是什么而一直沿用之前硬解析时所产生的解析树和执行计划的缺点才有所缓解。
(2)在不改变SQL语句文本的情况下,让SQL语句重新进行硬解析的方法有:①对SQL语句涉及到的对象执行DDL操作(例如COMMENT语句)。②执行DBMS_SHARED_POOL.PURGE来删除共享池中的游标。③在重新收集统计信息时指定NO_INVALIDATE=>FALSE选项。
绑定变量窥探这种不管后续传入的绑定变量的具体输入值是什么而一直沿用之前硬解析时所产生的解析树和执行计划的特性一直饱受诟病(这种状况一直到Oracle llg中引入自适应游标共享后才有所缓解),因为绑定变量窥探可能使CBO在某些情况下(对应绑定变量的某些具体输入值)所选择的执行计划并不是目标SQL在当前情形下的最优执行计划,而且它可能会带来目标SQL执行计划的突然改变,进而直接影响应用系统的性能。
绑定变量窥探的副作用在于,一旦启用(默认情况下绑定变量窥探就己经被启用),使用了绑定变量的目标SQL就只会沿用之前硬解析时所产生的解析树和执行计划,即使这种沿用完全不适合当前的情形,即根据第一次传入的值然后固化执行计划。
Oracle的外部表是什么?
外部表是指不存在于数据库中的表。通过向Oracle提供描述外部表的元数据,可以把一个操作系统文件当成一个只读的数据库表,就像这些数据存储在一个普通数据库表中一样来进行访问。外部表是对数据库表的延伸。外部表只能在Oracle 9i之后的版本来使用。
Oracle外部表用来存取数据库以外的文本文件(Text File)或Oracle专属格式文件。因此,建立外部表时不会产生段、区、数据块等存储结构,只有与表相关的定义放在数据字典中。外部表仅供查询,不能对外部表的内容进行修改(例如INSERT、UPDATE、DELETE等操作)。不能在外部表上建立索引。因为创建索引就意味着要存在对应的索引记录,而其实外部表的数据没有存储在数据库中,故在外部表上是无法建立索引的。
如果外部表采用PARALLEL的方式加载的话,那么加载的数据是无序的。所以,这种情况需要综合考虑,尤其是在使用该方式来查看告警日志文件内容的时候需要特别注意。
外部表有如下几点特性:
① 外部表的数据位于文件系统之中,并按一定格式分割。文本文件或者其它类型的表可以作为外部表。操作系统文件在数据库中的标志是通过一个逻辑目录来映射的,所以外部表需要在Oracle数据库“服务端”创建目录,这些OS文件必须放在这些目录中。
② 对外部表的访问可以通过SQL语句来完成,而不需要先将外部表中的数据装载进数据库中。
③ 外部表是只读的,因此,只能对外部表进行SELECT操作,不能对外部表执行DML(DELETE、UPDATE和INSERT等)操作,也不能创建索引,但是可以创建视图,也可以创建同义词。
④ ANALYZE语句不支持采集外部表的统计数据,应该使用DMBS_STATS包来采集外部表的统计数据。
⑤ 可以对外部表执行查询、连接和并行操作。
⑥ 外部表不支持LOB对象。
与外部表相关的几个视图如下所示:
SELECT * FROM DBA_EXTERNAL_LOCATIONS; --描述外部表的位置
SELECT * FROM DBA_EXTERNAL_TABLES;--所有的外部表
SELECT * FROM DBA_DIRECTORIES;--数据库中所有的目录对象
Oracle中如何插入或更新特殊字符“&”?
假设有如下的SQL语句:
UPDATE USERINFO SET PAGEURL = 'MYJSP?PAGE=1&PAGESIZE=10' WHERE ID='TEST';
那么,怎么处理上例中的特殊字符“&”呢?
主要有如下两种解决方法:
1)UPDATE USERINFO SET PAGEURL='MYJSP?PAGE=1'||'&'||'PAGESIZE=10' WHERE ID='TEST';
2)UPDATE USERINFO SET PAGEURL='MYJSP?PAGE=1'||CHR(38)||'PAGESIZE=10' WHERE ID='TEST';
其中“||”是连字符,&对应的ASCII码为38,因此CHR(38)用来表示“&”。PL/SQL中还可以使用SET DEFINE OFF来关闭特殊字符,还可以用SHOW DEFINE来查看有些特殊定义的字符。
rm -rf误操作删除了数据文件后如何快速恢复?
如果执行了rm -rf操作删除了所有的基于FS的数据文件,但是数据库还处于OPEN状态,那么,在这种情况下如何快速地恢复数据库呢?这里的前提条件是没有任何可用的RMAN备份、数据库冷备份等,也就是说,没有任何备份。在这种情况下可以通过系统的文件句柄号来恢复数据文件。整个恢复过程可以简单分为如下几步:
(1)找到被删除文件的文件句柄所在的目录
首先通过命令“ps -ef|grep ora_lgwr”找到LGWR的进程号。假设这里的进程号为31863,则被删除的文件句柄在/proc/31863/fd目录下。
(2)采用操作系统cp命令拷贝文件句柄到原数据库文件路径
假设这里看到的是如下的情况,被删除的文件末尾一般都有deleted标识。
[root@orclalhr fd]# ll | grep deleted
lrwx------ 1 oracle oinstall 64 May 5 14:48 256 -> /u02/app/oracle/oradata/oratest/control01.ctl (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 257 -> /u02/app/oracle/flash_recovery_area/oratest/control02.ctl (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 258 -> /u02/app/oracle/oradata/oratest/redo01.log (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 259 -> /u02/app/oracle/oradata/oratest/redo02.log (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 260 -> /u02/app/oracle/oradata/oratest/redo03.log (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 261 -> /u02/app/oracle/oradata/oratest/system01.dbf (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 262 -> /u02/app/oracle/oradata/oratest/sysaux01.dbf (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 263 -> /u02/app/oracle/oradata/oratest/undotbs01.dbf (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 264 -> /u02/app/oracle/oradata/oratest/users01.dbf (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 265 -> /u02/app/oracle/oradata/oratest/example01.dbf (deleted)
lrwx------ 1 oracle oinstall 64 May 5 14:48 266 -> /u02/app/oracle/oradata/oratest/temp01.dbf (deleted)
执行cp命令,拷贝数据文件到原路径:
cp 256 /u02/app/oracle/oradata/oratest/control01.ctl
cp 257 /u02/app/oracle/flash_recovery_area/oratest/control02.ctl
cp 258 /u02/app/oracle/oradata/oratest/redo01.log
cp 259 /u02/app/oracle/oradata/oratest/redo02.log
cp 260 /u02/app/oracle/oradata/oratest/redo03.log
cp 261 /u02/app/oracle/oradata/oratest/system01.dbf
cp 262 /u02/app/oracle/oradata/oratest/sysaux01.dbf
cp 263 /u02/app/oracle/oradata/oratest/undotbs01.dbf
cp 264 /u02/app/oracle/oradata/oratest/users01.dbf
cp 265 /u02/app/oracle/oradata/oratest/example01.dbf
cp 266 /u02/app/oracle/oradata/oratest/temp01.dbf
需要注意的是,最好使用Oracle用户去执行cp命令。如果使用root用户执行cp命令的话,那么Oracle进程是没有权限操作的。当然也可以在使用root用户拷贝完数据文件后,再执行赋权操作,命令如下所示:
[root@ora10g fd]# chown oracle.oinstall /u02/app/oracle -R
但是一定要注意,必须要等全部数据文件恢复后才可以执行chown操作。因为一旦执行了该操作,原来的ora_进程就会停止,那么就不能恢复所有的数据文件了。
(3)其它检查工作,例如数据检查、备份等
最后需要特别注意的是,当执行操作系统命令rm的时候,切记不可随意加-rf参数,就算一定要用,也要确定再三后才能执行,否则对于数据库而言,可以说是灾难性的。由于rm操作是在数据库OPEN状态下直接进行了破坏性操作,对于Redo Buffer还来不及写入Online Redo Logfile的那部分操作,肯定是会丢失的。因为通过文件句柄号恢复出来的日志文件中,并不一定包含数据库的最新变更。即便如此,本小节对于rm -rf误操作的恢复,还是有一定意义的,至少可以在没有任何备份的情况下,多了一根救命稻草来拯救数据库。最后再次强调一下,执行rm -rf后,千万不要着急地关闭数据库重启,否则在没有任何备份的情况下基本上是很难恢复数据文件的。
在Oracle中,SESSIONS和PROCESSES的关系是什么?
在数据库安装完成后,常常需要设置SESSIONS和PROCESSES的大小。其中,SESSIONS指定了一个实例中允许的会话数,即能同时登录到数据库的并发用户数。PROCESSES指定了一个实例在操作系统级别能同时运行的进程数,包括后台进程与服务器进程。由于一个后台进程可能同时对应多个会话,所以,通常SESSIONS的值是大于PROCESSES的值。
通过查找官方文档,可以知道SESSIONS参数的值在Oracle 10g和11g中是不同的,如下表所示:
| 属性 | Oracle 10g | Oracle 11gR2 |
| 参数值的类型 | Integer | Integer |
| 默认值 | Derived: (1.1 * PROCESSES) + 5 | Derived: (1.5 * PROCESSES) + 22 |
| 是否可以动态修改 | No | No |
| 范围 | 1 to 231 | 1 to 216 (即1到65536) |
| 注:在Oracle 11gR1中,该参数值和10g是一样的,修改语句为“ALTER SYSTEM SET PROCESSES|SESSIONS=200 SCOPE=SPFILE;” | ||
由于SESSIONS的值是根据PROCESSES的值计算得到的,所以,一般情况下只需要设置PROCESSES的值即可。在Oracle 11gR2以下版本中,SESSIONS大小的计算公式为:(1.1 * PROCESSES) + 5;在Oracle 11gR2中,SESSIONS大小的计算公式为:(1.5 * PROCESSES) + 22。若SESSIONS的当前值比计算值大的话,则SESSIONS的值可能保持不变;若SESSIONS的当前值比计算值小的话,则SESSIONS取计算值,即SESSIONS的值总是取MAX(当前值,计算值),但是这个也不是绝对的。
当数据库连接的并发用户已经达到SESSIONS的值时,又有新会话连接进来,就会报错“ORA-00018,"maximum number of sessions exceeded"”的错误。
当Oracle需要启动新的PROCESS,而当前的进程数又已经达到PROCESSES参数时,就会报错:“ORA-00020: maximum number of processes (2048) exceeded”。
如果数据库上连接被占用完,当新的连接过来时,那么就会在客户端产生“ORA-12519, TNS:no appropriate service handler found”的报错信息。
SQL Server的两种存储结构是什么?
SQL Server的两种存储结构是页与区间。
(1)页:用于数据存储的连续的磁盘空间块,SQL Server中数据存储的基本单位是页,磁盘I/O操作在页级执行,页的大小为8KB,每页的开头是96字节的页头,用于存储有关页的系统信息,包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元ID。
(2)区间:区是管理空间的基本单位,一个区是8个物理上连续的页(即64KB)的集合,所有页都存储在区中。SQL Server有两种类型的区:统一区和混合区。
l 统一区:由单个对象所有,区中的所有8页只能由一个对象使用。
l 混合区:最多可由8个对象共享。区中8页中的每页可以由不同对象所有,但是一页总是只能属于一个对象。
在Oracle中,当需要使用显式游标更新或删除游标中的行时,声明游标时指定的SELECT语句必须带有下边选项中的哪一个子句()
A、WHERE CURRENT OF
B、INTO
C、FOR UPDATE
D、ORDER BY
本题考察游标的特点。带有FOR UPDATE才能执行DML操作,显然,本题的答案为C。
在Oracle中,以下工具可以实现逻辑备份数据库对象或整个数据库的是哪一项()
A、SQL*Plus
B、导出实用程序
C、导入实用程序
D、SQL*Loader
逻辑备份是指使用工具exp或expdp将数据库对象的结构和数据导出到二进制文件的过程。当数据库对象被误操作而损坏后就可以使用工具imp或impdp利用备份的文件把数据对象导入到数据库中进行恢复。逻辑备份是物理备份方式的一种补充,多用于数据迁移。
Oracle数据库中,以下哪个命令可以删除整个表中的数据,并且无法回滚()
A、DROP
B、DELETE
C、TRUNCATE
D、CASCADE
DELETE、DROP和TRUNCATE的异同点如下表所示:
| 相同点 | 1、TRUNCATE和不带WHERE子句的DELETE及DROP都会删除表内的所有数据 2、DROP和TRUNCATE都是DDL语句,执行后会自动提交 3、表上的索引大小会自动进行维护 | ||||
| 不同点 | 分类 | DROP | TRUNCATE | DELETE | |
| 是否删除表结构 | 删除表结构及其表上的约束,且依赖于该表的存储过程和函数等将变为INVALID状态 | 只删除数据不删除表的定义、约束、触发器和索引 | |||
| SQL命令类型 | DDL语句,隐式提交,不能对TRUNCATE和DROP使用ROLLBACK命令 | DML语句,事务提交(COMMIT)之后才生效,可以使用ROLLBACK语句撤销未提交的事务 | |||
| 删除的数据是否放入回滚段(ROLLBACK SEGMENT) | 否 | 否 | 是 | ||
| 高水位是否下降 | 是 | 是,在宏观上表现为TRUNCATE操作后,表的大小变为初始化的大小 | 否,在宏观上表现为DELETE后表的大小并不会因此而改变,所以,在对整个表进行全表扫描时,经过TRUNCATE操作后的表比DELETE操作后的表要快得多 | ||
| 日志的产生 | 少量日志 | 少量日志 | 大量日志 | ||
| 是否可以通过闪回查询来找回数据 | 否 | 否 | 是 | ||
| 是否可以对视图进行操作 | 是 | 否 | 是 | ||
| 级联删除 | 不能DROP一个带有ENABLE外键的表 | 不能TRUNCATE一个带有ENABLE外键的表,会报错ORA-02266 | 可以DELETE一个带有ENABLE外键的表 | ||
| 执行速度 | 一般来说,DROP>TRUNCATE>DELETE,DROP和TRUNCATE由于是在底层修改了数据字典,所以,无论是大表还是小表执行都非常快,而DELETE是需要读取数据到Undo,所以,对于大表进行DELETE全表操作将会非常慢 | ||||
| 安全性 | DROP和TRUNCATE在无备份的情况下需谨慎 | ||||
| 使用方面 | 想删除部分数据行只能用DELETE且带上WHERE子句;想删除表数据及其结构则使用DROP;想保留表结构而将所有数据删除则使用TRUNCATE | ||||
| 恢复方法 | 使用回收站恢复,闪回数据库,RMAN备份、DUL工具等 | 闪回数据库,RMAN备份、DUL工具等 | 闪回查询、闪回事务、闪回版本、闪回数据库等 | ||
在非归档方式下操作的数据库禁用了()
A、归档日志
B、联机日志
C、日志写入程序
D、日志文件
Oracle数据库可以设置为归档模式或非归档模式。当数据库运行在归档模式下时,数据库会将所有的事务记录在联机日志(Online Redo Log)中。当联机日志写满时会进行归档,即形成了归档日志(Archived Log)。当数据库运行在非归档模式下时,数据库只会将事务记录在Online Redo Log中,而并不会将日志进行归档处理。
Oracle数据库有联机重做日志,这个日志是记录对数据库所做的修改,比如插入,删除,更新数据等,对这些操作都会记录在联机重做日志里。一般数据库至少要有2个联机重做日志组。当一个联机重做日志组被写满的时候,就会发生日志切换,这时联机重做日志组2成为当前使用的日志,当联机重做日志组2写满的时候,又会发生日志切换,去写联机重做日志组1,就这样反复进行。
如果数据库处于非归档模式,联机日志在切换时就会丢弃. 而在归档模式下,当发生日志切换的时候,被切换的日志会进行归档。比如,当前在使用联机重做日志1,当1写满的时候,发生日志切换,开始写联机重做日志2,这时联机重做日志1的内容会被拷贝到另外一个指定的目录下。这个目录叫做归档目录,拷贝的文件叫归档重做日志。
下列哪个参数用于确定是否要导入整个导出文件()
A、CONSTRANINTS
B、TABLES
C、FULL
D、FILE
逻辑导入工具imp或数据泵impdp中导入全库采用的是full参数。所以,本题的答案为C。
下面哪个操作不会启动触发器()
A、UPDATE
B、DELETE
C、INSERT
D、SELECT
触发器(TRIGGER)是数据库提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是由手工启动,而是由事件来触发,例如当对一个表执行操作(例如INSERT,DELETE,UPDATE等)时就会激活它。
在一个关系R中,若每个数据项都是不可再分割的,那么R一定属于()
A、第一范式
B、第二范式
C、第三范式
D、第四范式
答案:A。
在SQL Server 2000中,事务日志备份()
A、对故障还原模型没有要求
B、要求故障还原模型必须是完整的
C、要求故障还原模型必须是简单的
D、要求故障还原模型不能是简单的
要进行事务日志备份,必须将数据库的故障还原模型设置为“完全”方式或“大容量日志记录的”方式。
在SQL Server 2000中,Master是一个非常重要的系统数据库,如果Master损坏,那么将会对系统造成严重后果,因此系统管理员应该对Master进行备份。SQL Server 2000对数据库提供的备份有:_____、_____、_____。
答案:完全备份、差异备份、日志备份
在SQL Server 2000中,设U1用户在某数据库中是db_datawriter角色中的成员,则用户U1从该角色中可以获得的数据操作权限有_____、_____、_____。
答案:插入、更改、删除
分析:db_datawriter可以更改数据库中所有用户表中的数据,但不能查询。因此,U1获得了除查询以外的三项权限。
MySQL的复制原理(Replication)以及流程是什么样的?
MySQL的复制原理:Master上面事务提交时会将该事务的Binlog Events写入Binlog文件,然后Master将Binlog Events传到Slave上面,Slave应用该Binlog Events实现逻辑复制。
MySQL的复制是基于如下3个线程的交互(多线程复制里面应该是4类线程):
① Master上面的Binlog Dump线程,该线程负责将Master的Binlog Events传到Slave;
② Slave上面的I/O线程,该线程负责接收Master传过来的二进制日志(Binlog),并写入中继日志(Relay Log);
③ Slave上面的SQL线程,该线程负责读取中继日志(Relay Log)并执行;
如果是多线程复制,无论是MySQL 5.6库级别的假多线程还是MariaDB或者5.7的真正的多线程复制,SQL线程只做Coordinator,只负责把中继日志(Relay Log)中的二进制日志(Binlog)读出来然后交给Worker线程,Woker线程负责具体Binlog Events的执行。
SQL Server物理有哪三种类型的文件?
答案:SQL Server数据库文件组成如下所示:
(1)主数据文件:默认扩展名为.mdf。
(2)辅助数据文件:默认扩展名为.ndf(一个数据库可以创建多个.ndf文件)。
(3)事务日志文件:默认扩展名为.ldf(记录对数据库的所有操作,但不包含所操作的数据)。
所有的数据文件和日志文件默认位置在C:/Program Files/Microsoft SQL Server/MSSQL.n/MSSQL/Data(其中,n是标识已安装的SQL Server实例名称_实例名)。需要注意的是,应当将所有的数据和对象存储在.ndf文件中,而.mdf文件只负责存储数据目录,这样可以有效地避免访问时的磁盘争用。
在视图上不能完成的操作是()
A、更新视图
B、查询
C、在视图上定义新的表
D、在视图上定义新的视图
视图是由从数据库的基本表中选取出来的数据组成的逻辑窗口,它不同于基本表,它是一个虚拟表,其内容由查询定义。在数据库中,存放的只是视图的定义而已,而不存放数据,这些数据仍然存放在原来的基本表结构中。只有在使用视图的时候,才会执行视图的定义,从基本表中查询数据。可以更新视图,也可以在视图上定义新的视图,但是不能在视图上定义新的表。所以,本题的答案为C。
在进行备份时,不但备份数据库的数据文件,日志文件,而且还备份文件的存储位置以及数据库中的全部对象以及相关信息的备份是()
A、事务日志备份
B、差异备份
C、完全备份
D、文件和文件组备份
完全备份是将数据库中的全部信息进行备份,它是恢复的基线。在进行完全备份时,不但备份数据库的数据文件,日志文件,而且还备份文件的存储位置信息以及数据库中的全部对象以及相关信息。
下列哪种完整性中,将每一条记录定义为表中的惟一实体,即不能重复()
A、域完整性 B、引用完整性 C、实体完整性 D、其他
关系的约束条件也称为关系的数据完整性规则,是对关系的一些限制和规定,包括实体完整性、参照完整性和用户定义完整性。实体完整性:关系模型对应的是现实世界的数据实体,而关键字是实体惟一性的表现,没有关键字就没有实体,所有关键字不能是空值。这是实体存在的最基本的前提,所以,称之为实体完整性。参照完整性:参照完整性规则也可称为引用完整性规则。这条规则是对关系外部关键字的规定,要求外部关键字的取值必须是客观存在的,即不允许在一个关系中引用另一个关系中不存在的元组。用户定义完整性:由用户根据实际情况,对数据库中数据的内容所作的规定称为用户定义的完整性规则。通过这些限制数据库中接受符合完整性约束条件的数据值,不接受违反约束条件的数据,从而保证数据库的数据合理可靠。
Oracle的数据类型有哪些?
Oracle的数据类型分为标量(Scalar)类型、复合(Composite)类型、引用(Reference)类型和LOB(Large Object)类型4种类型。
因为标量类型没有内部组件,所以,它又分为四类:数值、字符、布尔和日期/时间。
复合类型也叫组合类型,它包含了能够被单独操作的内部组件,每个组件都可以单独存放值,所以,一个复合变量可以存放多个值。因为复合变量类型不是数据库中已经存在的数据类型,所以,复合变量在声明类型之前,首先要创建复合类型,复合类型创建后可以多次使用,以便定义多个复合变量。复合变量像标量变量一样也有数据类型,复合数据类型有记录(RECORD)、表(TABLE)、嵌套表(Nested TABLE)和数组(VARRAY)四种类型,其中,表、嵌套表和数组也称为集合,而集合类型(表、嵌套表和数组)在使用时必须先使用TYPE进行定义方可使用。记录是由一组相关但又不同的数据类型组成的逻辑单元。表是数据的集合,可将表中的数据作为一个整体进行引用和处理。嵌套表是表中之表。一个嵌套表是某些行的集合,它在主表中表示为其中的一列。对主表中的每一条记录,嵌套表可以包含多个行。在某种意义上,它是在一个表中存储一对多关系的一种方法。可变数组(VARRAY)存储固定数量的元素(在运行中,可以改变元素数量),使用顺序数字作下标,可以定义等价的SQL类型,可以存储在数据库中。可以用SQL进行存储和检索,但比嵌套表缺乏灵活性。
引用类型类似于指针,能够引用一个值。
LOB(Large Object)类型的值就是一个LOB定位器,能够指示出大对象的存储位置。目前Oracle支持的LOB类型具体包括四个子类型(Subtype),分别为CLOB、BLOB、NLOB和BFILE。其中,CLOB、BLOB和NLOB都是将数据保存在数据库内部,所以称为内部LOB,而BFILE类型保存的核心是文件指针,真正的文件是保存在数据库外,所以称为外部LOB。
如果处理单行单列的数据那么可以使用标量变量;如果处理单行多列数据那么可以使用PL/SQL记录;如果处理单列多行数据那么可以使用PL/SQL集合。
BOOLEAN数据类型用于定义布尔型(逻辑型)变量,其值只能为TRUE(真)、FALSE(假)或NULL(空)。需要注意的是,该数据类型是PL/SQL数据类型,不能应用于表列。
下图是在PL/SQL中可以使用的预定义类型。
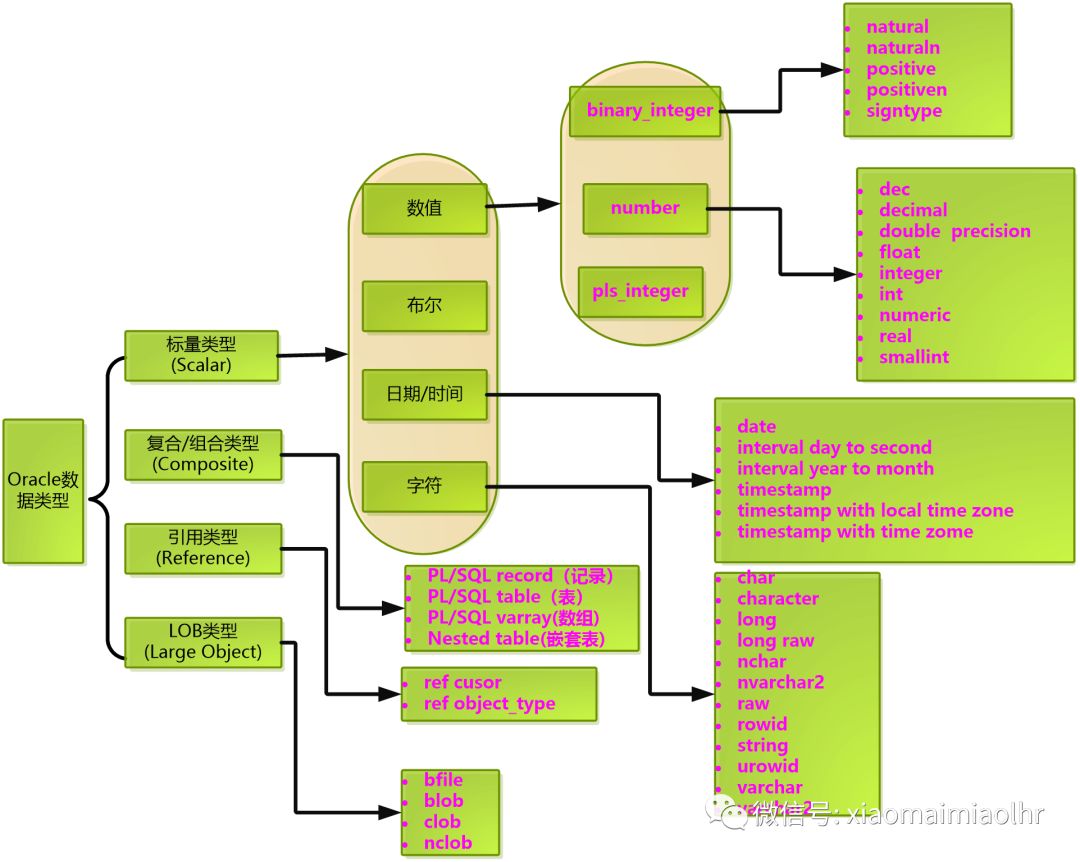
图 3-1 PL/SQL中可以使用的预定义类型
数据类型的作用在于指明存储数值时需要占据的内存空间大小和进行运算的依据。Oracle的字段数据类型如下表所示:
表 3-1 Oracle的字段数据类型
| 数据类型 | 描述 |
| VARCHAR2(size) | 可变长字符数据。VARCHAR2(n)数据类型用于定义可变长度的字符串,其中,n用于指定字符串的最大长度,n的值必须是正整数且不超过32767。 |
| CHAR(size) | 定长字符数据。CHAR(n)数据类型用于定义固定长度的字符串,其中,n用于指定字符串的最大长度,n的值必须是正整数且不超过32767。 |
| NUMBER(p,s) | 可变长数值数据。NUMBER(precision,scale)数据类型用于定义固定长度的整数和浮点数,其中,precision表示精度,用于指定数字的总位数;scale表示标度,用于指定小数点后的数字位数,默认值为0,即没有小数位数。 |
| DATE | 日期型数据。DATE数据类型用于定义日期时间类型的数据,其数据长度为固定7个字节,分别描述年、月、日、时、分、秒。 |
| LONG | 可变长字符数据,最大可达到2G。LONG数据类型在其它的数据库系统中常被称为备注类型,它主要用于存储大量的可以在稍后返回的文本内容。 |
| TIMESTAMP | TIMESTAMP数据类型也用于定义日期时间数据,但与DATE仅显示日期不同,TIMESTAMP类型数据还可以显示时间和上下午标记,如“11-9月-2007 11:09:32.213 AM”。 |
| CLOB | 字符数据,最大可达到4G。 |
| RAW和LONG RAW | 裸二进制数据。LONG RAW数据类型在其它数据库系统中常被称为大二进制类型(BLOB),它可以用来存储图形、声音视频数据,尽管关系型数据库管理系统最初不是为它们而设计的,但是多媒体数据可以存储在BLOB或LONG RAW类型的字段内。 |
| BLOB | 二进制数据,最大可达到4G。 |
| BFILE | 存储外部文件的二进制数据,最大可达到4G。 |
| ROWID | 行地址,十六进制串,表示行在所在的表中唯一的行地址,该数据类型主要用于返回ROWID伪列,常用在可以将表中的每一条记录都加以唯一标识的场合。 |
条件表达式CASE和DECODE的区别是什么?
在SQL语句中使用IF-THEN-ELSE逻辑,可以使用两种方法:CASE表达式、DECODE函数。
1、CASE表达式
SQL中CASE的使用方法具有两种格式:简单CASE函数和CASE搜索函数。
简单CASE函数使用方式如下所示:
CASE SEX
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其它' END AS "类别"
CASE搜索函数使用方式如下所示:
CASE WHEN SEX = '1' THEN '男'
WHEN SEX = '2' THEN '女'
ELSE '其它' END AS "类别"
以上两种方式可以实现相同的功能。简单CASE函数的写法相对比较简洁,但是和CASE搜索函数相比,功能方面会有些限制,例如编写判断式,下面的例子无法使用简单CASE函数来实现:
CASE WHEN SEX = '1' AND AGE>60 THEN '爷爷'
WHEN SEX = '2' AND AGE>60 THEN '奶奶'
ELSE '其它' END AS "类别"
需要注意的是,CASE函数只返回第一个符合条件的值,剩下的CASE部分将会被自动忽略。例如下面的SQL语句,永远无法得到“第二类”这个结果。
CASE WHEN COL_1 IN ( 'A', 'B') THEN '第一类'
WHEN COL_1 IN ('A') THEN '第二类'
ELSE '其它' END AS "类别"
CASE表达式可以在SQL中实现IF-THEN-ELSE型的逻辑,而不必使用PL/SQL。CASE的工作方式与DECODE类似,但推荐使用CASE,因为它与ANSI兼容。
对于CASE表达式,需要注意以下几点内容:
(1)以CASE开头,以END结尾。
(2)分支中WHEN后跟条件,THEN为显示结果。
(3)ELSE为除此之外的默认情况,类似于高级语言程序中SWITCH CASE的DEFAULT,可以不加。
(4)END AS后跟别名,也可以去掉AS。
2、DECODE函数
DECODE的语法如下所示:
DECODE(VALUE,IF1,THEN1,IF2,THEN2,IF3,THEN3,...,ELSE),表示如果VALUE等于IF1,那么DECODE函数的结果返回THEN1,...,如果不等于任何一个IF值,那么返回空。
在使用DECODE函数时,需要注意以下几点内容:
(1)Oracle在调用DECODE函数的时候,需要预先确定列的类型。
(2)确定DECODE返回值类型,是依据参数中第一个条件返回类型,之后所有的返回类型都依据第一个类型进行强制类型转换。
(3)当Oracle在第一个条件返回类型为NULL的时候,默认将其作为字符串处理。
例如,下面的例子中,DECODE函数的返回值以SAL列为标准,即为数值型,而7499的返回值为字符串,所以,会报错:
SYS@lhrdb> SELECT * FROM SCOTT.EMP M WHERE M.EMPNO IN (7369, 7499);
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ------------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 1980-12-17 00:00:00 800 20
7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600 300 30
如下的SQL语句会报错(ORA-01722: invalid number):
SELECT DECODE(M.EMPNO, 7369, M.SAL, 7499, M.JOB)
FROM SCOTT.EMP M
WHERE M.EMPNO IN (7369, 7499);
若修改为如下形式,将SAL的列变为字符串就可以正常运行了。
SELECT DECODE(M.EMPNO, 7369, M.SAL||'', 7499, M.JOB)
FROM SCOTT.EMP M
WHERE M.EMPNO IN (7369, 7499);
如何将一个数字转换为字符串并且按照指定格式显示?
在应用中,可能需要将0.007007040000转换成0.70%,或需要显示“0.00”、“1.20”等类似的数据格式,此时可以使用TO_CHAR函数来转换。这个函数可以用来将DATE或NUMBER数据类型转换成可显示的字符串,格式是TO_CHAR(number_type,format_mask),format_mask转换格式有多种,如下表所示:
| 格式 | 含义 |
| 9 | 显示数字,9表示对应的某一个指定位数的值,若值是0则忽略不显示,若指定位数没有值,则以空格表示。 |
| 0 | 显示数字,0表示对应的某一个指定位数的值,若值是0则显示为0,若指定位数没有值也显示为0。 |
| FM或fm | FM表示将显示出来的字符串定位数没有值而显示的空格清理掉,作用和ltrim类似。 |
| . | 在指定位置显示小数点。 |
| , | 在指定位置显示逗号。 |
| $ | 在数字前加美元。 |
| L | 在数字前面加本地货币符号。 |
| C | 在数字前面加国际货币符号。 |
| G | 在指定位置显示组分隔符。 |
| D | 在指定位置显示小数点符号(.)。 |
| PR | 尖括号内负值。 |
| MI | 在指明的位置的负号(如果数字 < 0)。 |
| PL | 在指明的位置的正号(如果数字 > 0)。 |
| S | 带负号的负值(使用本地化)。 |
| SG | 在指明的位置的正/负号。 |
| RN | 罗马数字(输入在 1 和 3999 之间)。 |
| TH或th | 转换成序数。 |
| V | 移动 n 位(小数) |
| EEEE | 科学记数。现在不支持。 |
需要注意的是,在NUMBER类型转换为字符串时,负数会返回前面包含负号的字符串,正数则会返回前面包含空格的字符串,除非格式模式包含MI、S、或PR元素。即LENGTH(TO_CHAR(4, '0000'))的值其实是5,所以需要使用FM格式或ltrim去掉空格。示例如下所示:
SYS@PROD1> SELECT TO_CHAR(0.00, 'FM9999999999999999990.00') A,
2 TO_CHAR(ROUND(0.007007040000, 4) * 100, 'FM99999999990.90') || '%' AS B,
3 LENGTH(TO_CHAR(4, '0000')) C,
4 LENGTH(TO_CHAR(4, 'FM0000')) C1,
5 LENGTH(LTRIM(TO_CHAR(4, '0000'))) C2
6 FROM DUAL;
A B C C1 C2
----------------------- ---------------- ---------- ---------- ----------
0.00 0.70% 5 4 4
分区表有什么优点?分区表有哪几类?如何选择用哪种类型的分区表?
当表中的数据量不断增大时,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。当对表进行分区后,在逻辑上,表仍然是一张完整的表,只是将表中的数据在物理上可能存放到多个表空间或物理文件上。当查询数据时,不至于每次都扫描整张表。Oracle可以将大表或索引分成若干个更小、更方便管理的部分,每一部分称为一个分区,这样的表称为分区表。SQL语句使用分区表比全表能提供更好的数据处理与访问的性能。即使某些分区不可用,其它分区仍然可用,这叫做分区独立性。
分区表的一些限制条件:
① 簇表不能进行分区。
② 不能分割含有LONG或LONG RAW列的表。
③ 索引组织表不能进行范围分区。
何时考虑分区?
对大表进行分区,将有益于大表操作的性能和大表的数据的维护。官方文档说通常当表的大小超过2GB,或对于OLTP系统,当表的记录超过1000万时,都应考虑对表进行分区。
分区表有什么优点?
分区表有如下的优点:
① 增强可用性:如果表的一个分区由于系统故障而不能使用,那么表的其余好的分区仍可以使用。
② 减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需要修复,可能比整个大表修复花的时间更少。
③ 维护轻松:单独管理每个分区比管理单个大表要轻松得多。
④ 均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O,改善性能。
⑤ 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快。
⑥ 分区对用户透明,最终用户感觉不到分区的存在。
有哪些类型的分区?如何选择用哪种类型的分区表?
Oracle的分区可以分为:
● 范围分区(RANGE PARTITION)
● 哈希分区(HASH PARTITION)
● 列表分区(LIST PARTITION)
● 引用分区(REFERENCE PARTITION)
● 复合分区(组合分区)
● INTERVAL分区(间隔分区)
● 系统分区
分区表性能注意事项有哪些?
在使用分区表的时候需要注意以下几方面的内容:
① 在查询分区表时尽量带上分区键过滤条件,否则可能引起全分区扫描。
② 在设计分区表时,避免数据都进入默认分区,从而导致出现默认分区超大或各个分区大小严重不均衡的情况,失去分区表的意义。
③ 需要特别注意分区表性能比普通表性能差的情况。这种情况的本质原因是,虽然分区表的分区索引比全局索引要小很多,但是由于没有扫描指定的分区,而是扫描了很多个小的索引,这些小索引的高度累计起来一般都比全局索引要高。索引的范围检索性能是由索引的高度(BLEVEL)决定的,而不是由索引的大小决定。所以,性能差异很明显
| 方法 | 主要过程 | 优点 | 缺点 | 适用情况 |
| 导出/导入方法(Export/Import Method) | 采用逻辑导出/导入,首先在源库建立分区表,然后将数据导出,导入到新建的分区表即可。 | 操作简单。 | 整个实施过程中,目标表将不能进行DML操作。 | 该方法适用于业务量较小的表。 |
| 子查询插入方法(Insert With a Subquery Method) | 采用CTAS的方式创建分区表,然后执行RENAME操作即可。 | 方法简单易用,由于采用DDL语句,不会产生Undo日志,且只会产生少量Redo日志,效率相对较高,而且建表完成后数据已经分布到各个分区中了。 | 对于数据的一致性方面需要做额外的考虑。在执行CREATE TABLE语句和RENAME T_NEW TO T(T_NEW为中间表)语句时,T表不能进行DML操作。如果要保证一致性,那么需要在执行完语句后对数据进行检查,而这个代价是比较大的。另外,在执行RENAME语句时,其它会话将不能访问T表。 | 该方法适用于修改不频繁的表,在闲时进行操作,表的数据量不宜太大。 |
| 分区交换方法(Partition Exchange Method) | 执行分区交换命令“ALTER TABLE T_NEW EXCHANGE PARTITION T1 WITH TABLE T;”交换普通表和分区表的某个特定分区。 | 只对数据字典中分区和表的定义进行了修改,没有数据的修改或复制,效率最高。如果对数据在分区中的分布没有进一步要求的话,那么实现比较简单。在执行完RENAME操作后,可以检查T_OLD(T_OLD为中间表)中是否存在数据,如果存在的话,那么直接将这些数据插入到T中,可以保证对T插入的操作不会丢失。 | 存在一致性问题,在交换分区之后到RENAME T_NEW TO T(T_NEW为中间表)之前,查询、更新和删除会出现错误或访问不到数据。如果要求数据分布到多个分区中,那么需要进行分区的SPLIT操作,会增加操作的复杂度,效率也会降低。 | 该方法适用于包含大数据量的表转到分区表中的一个分区的操作,应尽量在系统空闲时进行操作。 |
| 在线重定义方法(DBMS_REDEFINITION Method) | 使用DBMS_REDEFINITION包进行在线转换。 | 保证数据的一致性,在大部分时间内,表T都可以正常执行DML操作,只在切换的瞬间锁表,具有很高的可用性。这种方法具有很强的灵活性,对各种不同的需求都能满足。而且,可以在切换前进行相应的授权并建立各种约束,可以做到切换完成后不再需要任何额外的管理操作。 | 在实现上比其它几种方法略显复杂。 | 该方法适用于7*24系统环境。 |
NULL有哪些注意事项?
在运算时,NULL(空)值不参与运算。判断是否为NULL值只能用IS NULL或IS NOT NULL,不能用=NULL或<>NULL,有关NULL值有如下几点需要注意:
① 空值是无效的、未指定的、未知的或不可预知的值。
② 空值不是空格,也不是0。
③ 包含空值的数学表达式的值(即加减乘除等操作)都为空值NULL。
④ 对空值进行连接字符串的操作之后,返回被连接的字符串。
⑤ 用IS NULL来表示为空,用IS NOT NULL来表示不为空,除此之外没有其它的表示方法了,这一点尤为重要。
⑥ COUNT(1)、COUNT(*)、COUNT(ROWID)、COUNT(常量)、COUNT(主键)、COUNT(非空列)这几种方式统计的行数是表中所有存在的行的总数,包括值为NULL的行和非空行。所以,这几种方式的执行结果相同。通过10053事件可以看到这几种方式除了COUNT(ROWID)之外,其它最终都会转换成COUNT(*)的方式来执行。需要注意的是:这里的COUNT(1)中的“1”并不表示表中的第一列,它其实是一个表达式,可以换成任意数字或字符或表达式。
a.COUNT(允许为空列) 这种方式统计的行数不会包括字段值为NULL的行。
b.COUNT(DISTINCT 列名) 得到的结果是除去值为NULL和重复数据后的结果。
⑦ NULL在排序中默认为最大值,DESC在最前,ASC在最后,可以加上NULLS LAST来限制NULL值的显示。
⑧ 如果子查询结果中包含NULL值,那么NOT IN (NULL、AA、BB、CC)返回为空。示例如下:
SYS@lhrdb> SELECT COMM,COUNT(1) FROM SCOTT.EMP GROUP BY COMM;
COMM COUNT(1)
---------- ----------
10
1400 1
500 1
300 1
0 1
SYS@lhrdb> SELECT B.EMPNO, B.COMM FROM SCOTT.EMP B WHERE B.SAL IN (800,1600);
EMPNO COMM
---------- ----------
7369
7499 300
SYS@lhrdb> SELECT * FROM SCOTT.EMP A WHERE A.COMM NOT IN (SELECT B.COMM FROM SCOTT.EMP B WHERE B.SAL IN (800,1600)) ;
no rows selected
SYS@lhrdb> SELECT * FROM SCOTT.EMP A WHERE A.COMM NOT IN (SELECT B.COMM FROM SCOTT.EMP B WHERE B.SAL IN (800,1600) AND B.COMM IS NOT NULL ) ; --正确写法
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ------------------- ---------- ---------- ----------
7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250 500 30
7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500 0 30
7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250 1400 30
在SCOTT.EMP表,除了COMM为空和300的记录还有COMM为1400、500和0的记录。
DELETE、DROP和TRUNCATE的异同点如下表所示:
| 相同点 | 1、TRUNCATE和不带WHERE子句的DELETE及DROP都会删除表内的所有数据 2、DROP和TRUNCATE都是DDL语句,执行后会自动提交 3、表上的索引大小会自动进行维护 | |||
| 不同点 | 分类 | DROP | TRUNCATE | DELETE |
| 是否删除表结构 | 删除表结构及其表上的约束,且依赖于该表的存储过程和函数等将变为INVALID状态 | 只删除数据不删除表的定义、约束、触发器和索引 | ||
| SQL命令类型 | DDL语句,隐式提交,不能对TRUNCATE和DROP使用ROLLBACK命令 | DML语句,事务提交(COMMIT)之后才生效,可以使用ROLLBACK语句撤销未提交的事务 | ||
| 删除的数据是否放入回滚段(ROLLBACK SEGMENT) | 否 | 否 | 是 | |
| 高水位是否下降 | 是 | 是,在宏观上表现为TRUNCATE操作后,表的大小变为初始化的大小 | 否,在宏观上表现为DELETE后表的大小并不会因此而改变,所以,在对整个表进行全表扫描时,经过TRUNCATE操作后的表比DELETE操作后的表要快得多 | |
| 日志的产生 | 少量日志 | 少量日志 | 大量日志 | |
| 是否可以通过闪回查询来找回数据 | 否 | 否 | 是 | |
| 是否可以对视图进行操作 | 是 | 否 | 是 | |
| 级联删除 | 不能DROP一个带有ENABLE外键的表 | 不能TRUNCATE一个带有ENABLE外键的表,会报错ORA-02266 | 可以DELETE一个带有ENABLE外键的表 | |
| 执行速度 | 一般来说,DROP>TRUNCATE>DELETE,DROP和TRUNCATE由于是在底层修改了数据字典,所以,无论是大表还是小表执行都非常快,而DELETE是需要读取数据到Undo,所以,对于大表进行DELETE全表操作将会非常慢 | |||
| 安全性 | DROP和TRUNCATE在无备份的情况下需谨慎 | |||
| 使用方面 | 想删除部分数据行只能用DELETE且带上WHERE子句;想删除表数据及其结构则使用DROP;想保留表结构而将所有数据删除则使用TRUNCATE | |||
| 恢复方法 | 使用回收站恢复,闪回数据库,RMAN备份、DUL工具等 | 闪回数据库,RMAN备份、DUL工具等 | 闪回查询、闪回事务、闪回版本、闪回数据库等 | |
DELETE和TRUNCATE都可以用来删除表中所有的记录。但二者的不同之处主要体现在以下几个方面的内容:
(1)TRUNCATE是一个DDL语句,DELETE是DML语句。
(2)TRUNCATE将被隐式提交,不能对TRUNCATE使用ROLLBACK命令,而对DML语句可以执行ROLLBACK命令来撤销未提交的事务。
(3)TRUNCATE由于是在底层修改了数据字典,所以在各种表上无论是大表的还是小表操作都非常快。DELETE操作需要写日志,而TRUNCATE不需要写日志,所以对于大表进行DELETE全表操作非常慢。
(4)TRUNCATE将重置表的高水位线,但DELETE不会重置表的高水位线,在宏观上表现为TRUNCATE操作后,表的大小变为初始化的大小,而DELETE后表的大小并不会因此而改变,所以在对整个表进行全表扫描时,经过TRUNCATE操作后的表比DELETE操作后的表要快得多,另外需要注意的是,无论TRUNCATE还是DELETE操作,表上的索引都会自动维护。
(5)TRUNCATE操作后的表不能通过闪回特性来找回,但DELETE后的表可以通过闪回特性来找回数据。
(6)TRUNCATE不能加条件删除数据;DELETE可以加条件删除。
(7)不能TRUNCATE一个带有ENABLE外键的表,会报错ORA-02266。可以DELETE一个带有ENABLE外键的表。

















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









