






本篇文章给大家谈谈python 爬虫抓取网页数据导出excel,以及python抓取网页数据并写入txt,希望对各位有所帮助,不要忘了收藏本站喔。
Source code download: 本文相关源码
项目场景:
Python是我接触过的,相比C++、java,是一门非常简单的编程语言。
对于办公室白领,在未来是一门必须掌握的技巧,可以帮你自动化处理数据用python绘制一个笑脸。
废话少说,上干货!
本期主要给大家分享一个我工作中的一次使用,希望对你以后工作有所帮助,提高效率,解放劳动力。
问题描述:
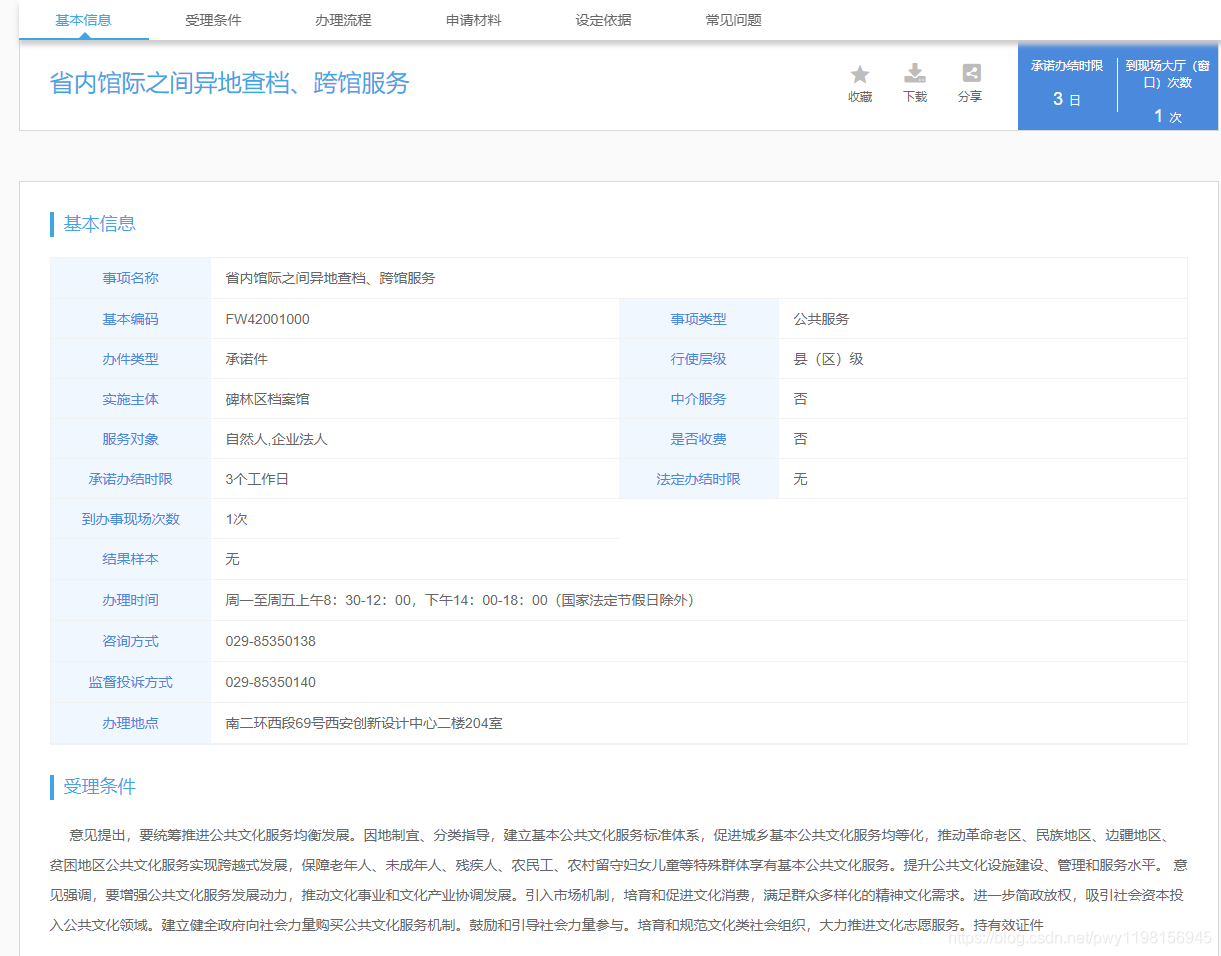
我们需要在一个网站上对网站上网页的所有的要素,进行逐一检查核对,1W多要素看的人眼花缭乱,效率慢,易出错,我们可以通过模拟http请求所有的页面,然后对页面进行解析,我这里所涉及的数据大多数是Json格式的,可以通过Json包提供的功能直接完成解析,但是如果遇到很多在网页内的数据,建议通过xml等技术定位解析(比如findElemnetByName)。
我们使用的技术有:
1.python 爬虫技术selenium和requests,selenium是个开源的框架,主要用于自动化软件测试,感兴趣的可以在github学习源码,它可以操作google,fireFox,IE浏览器执行操作,比如点击、刷新获取页面元素、执行JS等。requests模块主要是模拟浏览器对网站服务发起请求,可以设置head,body,cookie,获取执行结果,然后使用Jsoup进行解析。
2.python Excel表格处理,其中表格处理有很多模块,我们只用了其中的一个openpyxl模块。
3.http请求的分析,可以在浏览器F12查看,也可以用抓包工具fiddle抓取分析请求报数据,观察请求页面中的cookie参数,请求类型是get还是post。
4.python如何处理Json数据
5.python操作Excel方法,使用openpyxl包。
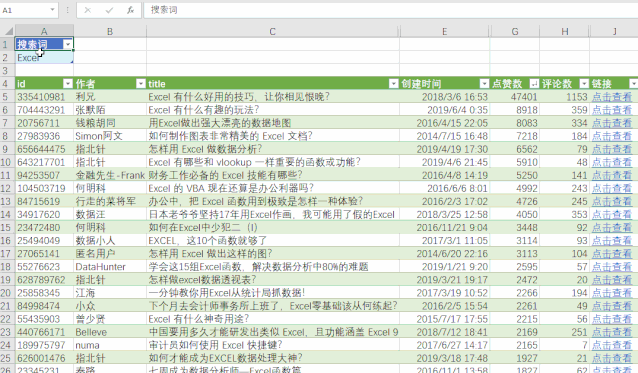
处理办法:python 在网站爬取所有要素,程序中加入判断规则,输出成Excel表格。原来3天的工作量,现在1min内搞定。

处理结果展示:



环境安装:
1.Python3安装可以参考
python3安装详细教程_檬柠wan-CSDN博客_python3安装教程
2.安装python requests openpyxl 模块,当然我最初是想用selenium操作浏览器处理的,成功了,下边代码我没有删只是注释起来了,可以作为参考。如有疑问可以call我
pip install requests
pip install openpyxl
3.fiddle工具抓包分析请求使用的参数,为后续python使用代码requests 做准备,并可以根据返回的json数据格式,操作处理数据,主要用到数据包的URL链接,请求头,body和cookie。
4.下列代码可以直接跑:
可以拓展功能,增加正则表达式过滤条件,可以调用NLP包,处理人工智能问题。
#!/usr/bin/python3
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
import sys,os
import json
import requests
import openpyxl
import locale
from openpyxl import Workbook
from openpyxl.styles import Font, colors, Alignment
def saveHtml(file_name,file_content):
with open(file_name.replace('/','_')+'.html', 'wb') as f:
f.write(file_content.encode(encoding='utf-8'))
def saveJson(file_name,file_content):
with open(file_name.replace('/','_')+'.json', 'wb') as f:
f.write(file_content.encode(encoding='utf-8'))
def funcpost(url,data):
data = {'id': 123} # POST请求需要提交的数据
data = json.dumps(data) # 有的时候data需要时json类型的
headers = {'content-type': 'application/json'} # 一种请求头,需要携带
res = rq.post(url=url, data=data, headers=deaders) # 发起请求
traget = res.json() # 将获取到的数据变成json类型
return target
#创建Excel
wb = Workbook()
#获取第一个sheet
ws = wb.active
# 将数据写入到指定的单元格
ws['A1'] = '部门名称'
ws['B1'] = "事项名称"
ws['C1'] = "基本编码"
ws['D1'] = "办理深度"
ws['E1'] = "咨询方式"
ws['F1'] = "投诉电话"
ws['G1'] = "第三方链地址"
ws['H1'] = "办事指南地址"
ws['I1'] = "办理时间"
ws['J1'] = "办理地点"
ws['K1'] = "办理条件"
ws['L1'] = "是否收费"
ws['M1'] = "承诺办结时限"
ws['N1'] = "法定办结期限"
ws['O1'] = "承诺办结时限"
ws['P1'] = "事项类型"
ws['Q1'] = "服务对象"
ws['R1'] = "设定依据"
ws['S1'] = "办理流程图片链接"
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/plain, */*',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Origin': 'http://zwfw.xa.gov.cn',
'Referer': 'http://zwfw.xa.gov.cn/zdpyc/door/',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
print('-------------------------------------------碑林区“互联网+政务”智能数据分析程序-----------------------------------')
print('---------------------------------------获取陕西政务服务网碑林区所有网上事项json数据--------------------------------')
print('-----------------------------------------正在获取中 Loading--------------------------------------------------------')
#time.sleep(2)
params={'areaCode':'610103000000',
'pageNo':'1',
'pageSize':'1000'}
r = requests.post('http://zwfw.xa.gov.cn/zdpyc/door/efficiency/users/signup/qryMatterPage', data=params,headers=headers)
r.encoding ='utf-8'
#请求网站返回数据转换为json
json_data = r.json()
print('------------------------------------------------data数据获取成功----------------------------------------------------')
saveJson('1',r.text)
print('------------------------------------------------data数据保存成功----------------------------------------------------')
print('------------------------------------------------data数据保存位置:'+os.getcwd()+'------------------')
#f = open(r"C:\Program Files (x86)\Notepad++\1.json", encoding='utf-8')
#json_data = json.load(f)
#print('这是文件中的json数据:',json_data)
print('----------------这是读取到文件数据的数据类型:', type(json_data))
print('----------------本次数据分析事项目录数量:',json_data['data']['recordsTotal'])
print('----------------本次数据分析事项小项数量:429')
print('----------------数据分析结果保存位置:'+os.getcwd())
print('----------------数据分析开始---------')
#time.sleep(5)
itemData = json_data['data']['rows']
#下边一行是调用selenium处理的,我用的是Firefox,当然大家可用chrom,IE 驱动都可以
#browser = webdriver.Firefox()
for key in itemData:
subItemListBO = key['subItemListBO']
print('-------------------------------------大项名称:'+key['itemName'] +'---------------------------------------------------')
for key2 in subItemListBO:
try:
url2 = r'http://zwfw.xa.gov.cn/zdpyc/door/item/qryItemDetailById?itemNo='+key2['itemNo']
url = r'http://zwfw.xa.gov.cn/zdpyc/door/#/home/home-hand-guide?itemNo='+key2['itemNo']+'&isShowBtn=true&acceptSource='+key2['acceptSource']+'&itemStatus=1&areaName=碑林区'
print('----办事指南地址:' + url)
params={'itemNo':key2['itemNo']}
responce = requests.post('http://zwfw.xa.gov.cn/zdpyc/door/item/qryItemDetailById', data=params,headers=headers)
responce.encoding ='utf-8'
small_data = responce.json()
print('----部门名称:',key2['implementOrgName'])
print('----事项名称:',key2['itemName'])
print('----基本编码:',key2['baseCode'])
print('----办理深度:',key2['deepnessGrade'])
print('----acceptSource:',key2['acceptSource'])
print('----咨询方式:',key2['askTel'])
print('----投诉电话:',small_data['data']['complaintAddress'])
print('----itemNo:',key2['itemNo'])
print('----第三方链地址:',key2['thirdUrl'])
#下边是selenium的操作,包括请求,返回处理
#print(url)
#browser.get(url)
#browser.refresh()
#print(browser.page_source)
#time.sleep(10)
#content = browser.page_source
#saveHtml(key2['itemName'], content)
#data = browser.find_element_by_css_selector("#pdfDom > div:nth-child(1) > div.handleGuideBaseInfo > div > div:nth-child(2) > div > p > div").text
#print('事项名称'+data)
print('----办理时间:',small_data['data']['acceptTime'])
print('----办理地点:',small_data['data']['acceptPlace'])
print('----办理条件:',small_data['data']['applicationCondition'])
print('----是否收费:',small_data['data']['isCharge'])
print('----承诺办结时限:',small_data['data']['promiseTime'])
print('----法定办结期限:',small_data['data']['lawComptime'])
print('----承诺办结时限:',small_data['data']['promiseComptime'])
print('----事项类型:',small_data['data']['itemTypeName'])
print('----服务对象:',small_data['data']['serviceObjectName'])
print('----设定依据:',small_data['data']['legalBasis'])
strContent = str(small_data['data']['legalBasis'])
###入库条件
if(len(strContent) < 180):
small_data['data']['legalBasis'] = '!!!!字数过少!!!!!' + str(len(strContent)) + small_data['data']['legalBasis']
fileUrl = small_data['data']
if (small_data['data']['itemFlowUrlBo']):
print('----办理流程图片链接:',small_data['data']['itemFlowUrlBo']['fileUrl'])
else:
print('----办理流程图片链接:','无办理流程图片')
a={}
small_data['data']['itemFlowUrlBo']=a
small_data['data']['itemFlowUrlBo']['fileUrl'] = '无办理流程图片'
#print('----事项要素:' + responce.text)
ws.append([key2['implementOrgName'], key2['itemName'], key2['baseCode'],key2['deepnessGrade'],key2['askTel'],small_data['data']['complaintAddress'],key2['thirdUrl'],url,small_data['data']['acceptTime'],small_data['data']['acceptPlace'],small_data['data']['applicationCondition'],small_data['data']['isCharge'],small_data['data']['promiseTime'],small_data['data']['lawComptime'],small_data['data']['promiseComptime'],small_data['data']['itemTypeName'],small_data['data']['serviceObjectName'],small_data['data']['legalBasis'],small_data['data']['itemFlowUrlBo']['fileUrl']])
#保存到Excel输出。
wb.save("data.xlsx")
#saveJson(key2['itemName'], responce.text)
print('----success------')
#time.sleep(10)
except Exception as e:
print(f"Unexpected error: {e}")
#time.sleep(10)















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









