说明 分区内和分区间计算规则相同的aggregateByKey。 函数签名 zeroValue:初始值,依次与分区内的数据做迭代。func:(V,V) => V:分区内和分区间的计算逻辑。 代码示例 val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]") val sc = new SparkContext(conf) val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 3), ("c", 6), ("c", 4), ("b", 3),("a", 2), ("c", 8)), 2) println("------------------分区内数据------------------") rdd.mapPartitionsWithIndex{ case (index, datas) => { println(index + "--->" + datas.mkString(",")) datas } }.collect() println("------------------分割线------------------") val resRDD: RDD[(String, Int)] = rdd.foldByKey(0)(_+_) resRDD.collect().foreach(println) sc.stop()








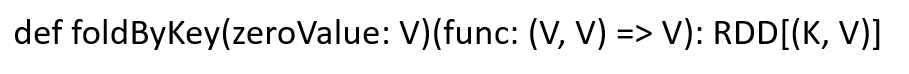















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









