







导入正则表达式模块
import re
re.match
re.match(正则表达式, 要匹配的字符串),python中match默认是从字符串第一位开始匹配(从头开始匹配)。
以指定字符串开头
# 匹配以hello开头的字符串
re.match("hello", "hello world")
# 查看匹配到的内容
print(re.match("hello", "hello world").group())
# 匹配以hello或者Hello开头的字符串
re.match(r"[hH]ello", "Hello world").group()

匹配单个数字
\d或者[0-9]匹配数字。[0-9]表示能匹配0-9之间的任意数字,包含0和9。如果写为[2-5]则表示匹配2-5之间的任意数字,包含2和5。
re.match(r"速度与激情\d", "速度与激情1")
re.match(r"速度与激情\d", "速度与激情2")
re.match(r"速度与激情[0-9]", "速度与激情3")

匹配多个数字
+表示匹配至少一个,*表示至少0个。
# \d+至少有一个数字
re.match(r"速度与激情\d+", "速度与激情12")
# \d*有或者没有数字都可以匹配
re.match(r"速度与激情\d*", "速度与激情13")
re.match(r"速度与激情\d*", "速度与激情2")
re.match(r"速度与激情\d*", "速度与激情")

匹配单个数字或者字母
\w表示匹配任意数字或者字母,注意\w不能匹配其他的字符,比如空格、=、!等。
re.match(r"速度与激情[a-zA-Z0-9]", "速度与激情2")
re.match(r"速度与激情[a-zA-Z0-9]", "速度与激情a")
re.match(r"速度与激情[a-zA-Z0-9]", "速度与激情A")
re.match(r"速度与激情\w", "速度与激情b")


匹配多个数字或者字母
+表示匹配至少一个,*表示至少0个。
re.match(r"速度与激情\w+", "速度与激情aaBB")
# 下面这种写法不能匹配到
re.match(r"速度与激情\w+", "速度与激情")

re.match(r"速度与激情\w*", "速度与激情ccDD")
re.match(r"速度与激情\w*", "速度与激情")

匹配空格或\t制表符
\s匹配空格或者\t制表符,\s+匹配一个或多个空格或者制表符。
re.match(r"速度与激情\s", "速度与激情 ")
re.match(r"速度\s激情", "速度 激情")

re.match(r"速度与激情\s+", "速度与激情 ")
re.match(r"速度与激情\s+", "速度与激情\t")

匹配任意字符
.(点)表示匹配任意字符
re.match(r"速度与激情.", "速度与激情a")
re.match(r"速度与激情.", "速度与激情1")
re.match(r"速度与激情.", "速度与激情 ")
re.match(r"速度与激情.", "速度与激情=")
re.match(r"速度与激情.", "速度与激情!")

匹配包括换行符在内的所有字符
re.S可匹配包含换行符在内的所有字符。
content = """
abc
defghi
jklmn
"""
# 匹配不上
re.match(r".*", content)
# 可以匹配包括\n在内的换行符
re.match(r".*", content, re.S)

匹配指定长度的数字或字母
\d{1,3}表示匹配1-3位长度的数字。
\d{11}表示匹配11位长度的数字。
\w{1,3}表示匹配1-3位长度的数字和字母。
\w{11}表示匹配11位长度的数字和字母。
re.match(r"速度与激情.", "速度与激情!")
re.match(r"速度与激情\d{1,3}", "速度与激情1")
re.match(r"速度与激情\d{1,3}", "速度与激情12")
re.match(r"速度与激情\d{1,3}", "速度与激情123")
# 只能匹配到速度与激情123,但是不能匹配到最后的4
re.match(r"速度与激情\d{1,3}", "速度与激情1234")

# 全部都能匹配到
re.match(r"\d{11}", "12345678901")
# 只能匹配到2之前的位置
re.match(r"\d{11}", "123456789012")
# 只能匹配到2之前的位置
re.match(r"\d{11}", "1234567890123")
# 不能匹配到
re.match(r"\d{11}", "123456789")

# 全部能匹配到
re.match(r"\w{1,3}", "abc")
# 只能匹配到d之前
re.match(r"\w{1,3}", "abcd")
# 全部能匹配到
re.match(r"\w{1,3}", "ab1")
# 不能匹配到
re.match(r"\w{6}", "ab1")
# 全部能匹配到
re.match(r"\w{6}", "ab1cd2")
# 只能匹配到3之前
re.match(r"\w{6}", "ab1cd23")

匹配0个或者1个
?表示0个或者1个。\d?表示0个或者1个数字,\w?表示0个或者1个数字或字母。
# 以下两种写法都可以全部匹配到
re.match(r"\d{3}-?\d{8}", "010-88886666")
re.match(r"\d{3}-?\d{8}", "01088886666")

re.match(r"\d{3}\w?", "010a")
re.match(r"\d{3}\w?", "010")
re.match(r"\d{3}\w?", "010abc")

匹配特殊含义的字符
正则表达式中,有一些特殊含义的字符,比如.、^、$等。在匹配这些特殊字符时,需要使用\进行转义。
# 匹配一个xxx@163.com
print(re.match(r"\w{3,7}@163\.com", "abc12@163.com").group())
匹配html标签
h_content = "<h1>hello world</h1>"
re.match(r"<\w+>.*</\w+>", h_content)
但是像上面的写法,可能也会匹配到一些不规范的标签,比如:<h1>hello world</h2>这样的标签。
规范的html标签,开始和结束都是成对出现的,比如:<a></a>,<head></head>等。我们可以使用正则表达式的分组功能,解决此问题。同组内的数据是相同的。
h_content = "<h1>hello world</h1>"
# (\w+)表示以多个字符组成的分组,\1表示正则表达式中的第一个分组
re.match(r"<(\w+)>.*</\1>", h_content)

h_content = "<body><h1>hello world</h1></body>"
# 有两对(),就是两个分组,\2表示第二个分组
re.match(r"<(\w+)><(\w+)>.*</\2></\1>", h_content)

re.search
re.search(正则表达式, 要匹配的字符串),search是在字符串中使用正则匹配,返回匹配到的第一组值。
re.search(r"\d+", "aaa123bbb456")

从头开始匹配
^表示从字符串开始位置进行匹配,python中match函数默认从头开始匹配,但是search方法需要写上此字符才可。需要注意的是,如果^出现在[]集合中,那么表示取反。
re.search(r"^\d+.*", "111abcd234")
# 以下写法不能匹配到数据,因为并不是以数字开头的
re.search(r"^\d+.*", "abcd234")

取反
[^]将 ^ 放在中括号集合中,即表示不匹配 ^ 后面的字符。
# 找到第一组小写字母
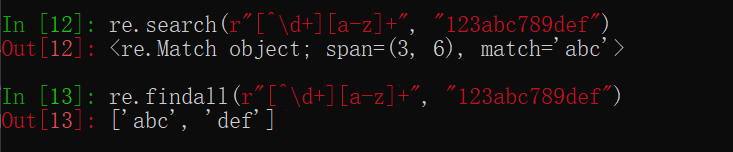
re.search(r"[^\d+][a-z]+", "123abc789def")
# 找到所有的小写字母
re.findall(r"[^\d+][a-z]+", "123abc789def")
以xx结尾
$表示以xx结尾。
# 以数字或字母开头,以.结尾
re.search(r"^\w+\.$", "123adb.")

re.findall
re.findall(正则表达式, 要匹配的字符串)。findall可以把字符串中所有符合条件的字符都取出来,并以列表的形式返回。
re.findall(r"\d+", "abcd123ghi4sdahnj7897")

或条件
|表示或者。比如:[0-9]+|[a-zA-Z]+表示匹配多个数字或者字母。
re.findall(r"[0-9]+|[a-zA-Z]+", "123ghi789")

re.sub
re.sub(正则表达式, 要替换的字符, 要匹配的字符串)。可以将匹配到的字符替换为中间指定的字符串,并以字符串的形式返回。
# 将字符串中的数字全部替换为888
re.sub("\d+", "888", "java=400, python=678, scala=999")

练习
判断变量名是否合规
# python中变量名的命名规范:以字母或者_开头,只包含数字、字母、下划线
import re
names = ["abc", "_name", "age_", "name_age", "__sex__", "_____", "a#123", "a123", "123a", "a!"]
for name in names:
mt = re.match("^[a-zA-Z_]+[a-zA-Z0-9_]*$", name)
if mt:
print("符合规范的变量名:%s" % name)
else:
print("不符合规范的变量名:%s" % name)
简单判断163邮箱地址
# 假设163邮箱的地址规范为:4-20位数字、字母、下划线+@163.com
import re
# 假设163邮箱的地址规范为:4-20位数字、字母、下划线+@163.com
email_list = [
'aaa@163.com',
'sjk_dsa123@163.com',
'dahujd%dsak@163.com',
'dsnakndnklandklnklndasklnladnkaslakldnklanklasndl@163.com',
'ahidfhaf@qq.com'
]
for email in email_list:
mt = re.match(r"^[a-zA-Z0-9_]{4,20}@163\.com", email)
if mt:
print("规范的163邮箱:%s" % email)
else:
print("不规范的163邮箱:%s" % email)















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









